




call db.index.fulltext.listAvailableAnalyzers
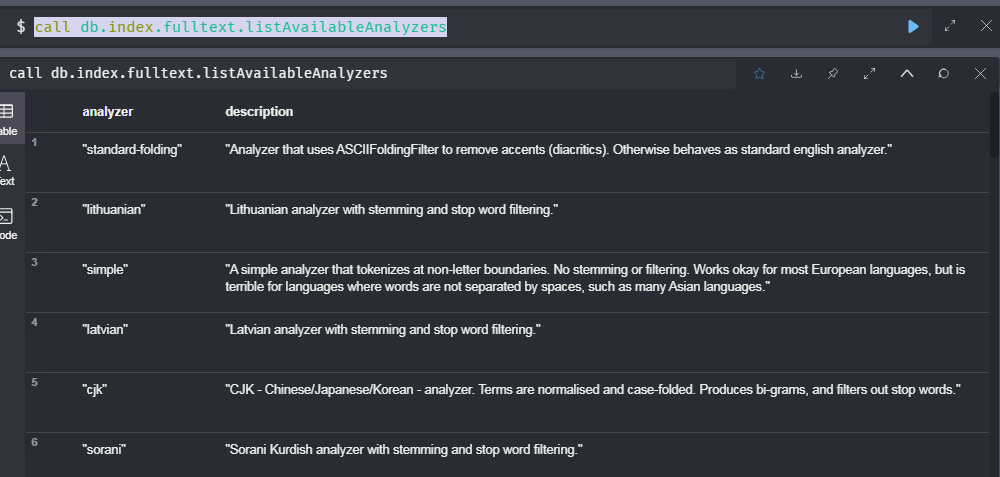
查到很多系统自带的分词器,其中有一个是“cjk”是针对中国,日本,韩国做的分词器,所以说是支持中文分词的。所以可以这样建索引,像下边指定analyzer的类型为“cjk”就指定的分词器的类型。
CALL db.index.fulltext.createNodeIndex("companyFullIndex",["CompanyEntry"],["name"], { analyzer: "cjk"}
第二种:通过第三方库来创建全文索引
https://github.com/crazyyanchao/ongdb-lab-apoc
dbms.security.procedures.unrestricted=apoc.*,zdr.*
安装好后执行,如果不报错,表示安装成功。初次会失败!
RETURN zdr.apoc.hello("你好") as greeting
运行函数zdr.index.iKAnalyzer会报莫名其妙的错误,经过测试需要继续从https://github.com/crazyyanchao/neo4j-graph-plugin下载neo4j-graph-plugin-master.zip文件,解压缩后取出其中的dic目录拷贝到neo4j根目录下,否则一直运行失败,因为他需要找分词文件目录,和java中引用IK分词一样。dic目录下的分词文件user_defined.dic可以添加自定义的分词。如果想修改用户自定义词典的位置,可以修改配置文件:
vim dic/dic-cfg/IKAnalyzer.cfg.xml
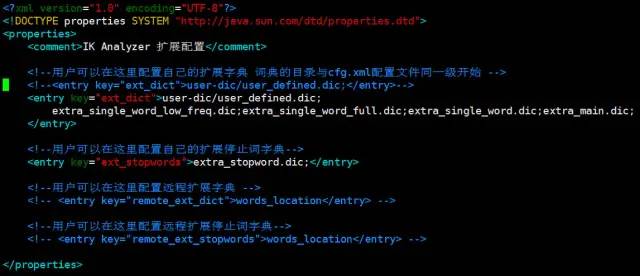
以上配置好了之后创建中文索引,CompanyFullIndex是索引名称,CompanyEntry是节点。
CALL zdr.index.addChineseFulltextIndex('CompanyFullIndex', ["name"], 'CompanyEntry') YIELD message RETURN message
这里的语法和系统库里的稍微参数位置不一样,其他逻辑都是一样的。查询的方法如下。
CALL zdr.index.chineseFulltextIndexSearch('CompanyFullIndex', 'name:测试~') YIELD node RETURN node
第三种:通过创建java代码,自己配置索引类型(这种没试过,因为我是用spring data neo4j框架)
@Overridepublic void createAddressNodeFullTextIndex () {try (Transaction tx = graphDBService.beginTx()) {IndexManager index = graphDBService.index();Index<Node> addressNodeFullTextIndex =index.forNodes( "addressNodeFullTextIndex", MapUtil.stringMap(IndexManager.PROVIDER, "lucene", "analyzer", IKAnalyzer.class.getName()));ResourceIterator<Node> nodes = graphDBService.findNodes(DynamicLabel.label( "AddressNode"));while (nodes.hasNext()) {Node node = nodes.next();//对text字段新建全文索引Object text = node.getProperty( "text", null);addressNodeFullTextIndex.add(node, "text", text);}tx.success();}
public class AddressNodeNeoDaoTest {@AutowiredGraphDatabaseService graphDBService;@Testpublic void test_selectAddressNodeByFullTextIndex() {try (Transaction tx = graphDBService.beginTx()) {IndexManager index = graphDBService.index();Index<Node> addressNodeFullTextIndex = index.forNodes("addressNodeFullTextIndex" ,MapUtil. stringMap(IndexManager.PROVIDER, "lucene", "analyzer" , IKAnalyzer.class.getName()));IndexHits<Node> foundNodes = addressNodeFullTextIndex.query("text" , "苏州 教育 公司" );for (Node node : foundNodes) {AddressNode entity = JsonUtil.ConvertMap2POJO(node.getAllProperties(), AddressNode. class, false, true);System. out.println(entity.getAll地址实全称());}tx.success();}}
- 本期完 -
 ,我会及时回复。由于微信限制了公众号留言功能,有问题你可以直接发公众号聊天,我会在下期文章末尾解答你的问题。
,我会及时回复。由于微信限制了公众号留言功能,有问题你可以直接发公众号聊天,我会在下期文章末尾解答你的问题。为方便看最新内容,记得关注哦 !
! 
文章转载自Neo4j权威指南,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
