排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
鲸品堂|基于端到端的实时计算加速技术
鲸品堂|基于端到端的实时计算加速技术
浩鲸科技
2022-01-17
76
随着时间的流失,数据的业务价值会迅速降低,因此数据在发生后必须尽快对其进行计算和处理。这对信息的高时效性和可操作性要求越来越高,也要求软件系统能够在更短的时间内处理更多的数据。
对软件系统来说要“分秒必争”,对用户来说要“多快好省”。
“快”的同义词是“实时”,于是就有了“实时数据”、“实时计算”、“实时数据存储”。
实时应用场景
企业经营数据实时大屏看板、金融风险实时风控、实时营销推荐等各行各业的实时业务场景越来越丰富,实时场景中参与计算的数据量逐渐增多,实时的业务规则逐渐丰富,应用场景也已经从当初单一的流式数据计算类型发展到如今的批流一体化计算、批流接合计算等多种类型的场景。
典型的业务场景有:实时查看公司经营大盘,实时核心日报,比如项目实时进展相关、经营业绩相关、人员工作动态情况相关、项目实时故障相关,都有一个核心的实时看板。
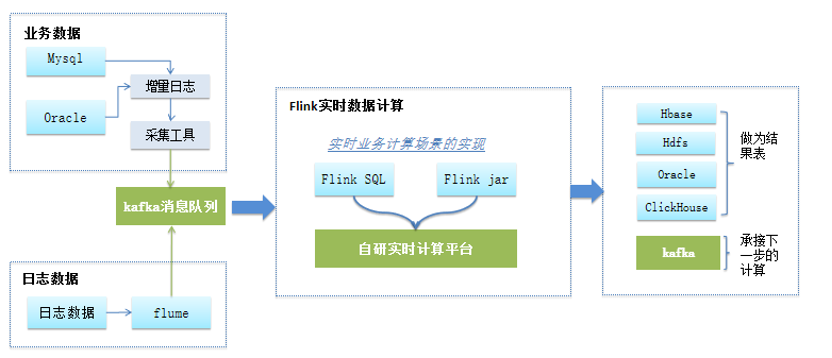
典型的实时计算流程
性能影响点
从上图可以看出实时计算由四端组成:源端数据
(业务数据、日志数据)
、消息中间件、实时计算、目标端
(hbase、hdfs等)
,其中每一端的实时处理能力,都将影响到整个实时计算的性能。通常一般的流式作业,只针对实时数据处理,使用flink计算可以完全满足秒级的性能要求,但实时计算业务都会有一个数据加工的过程,在加工过程中会比较频繁地访问离线的数据,此时如果处理不好,会极大地影响到实时计算端到端的性能,主要存在以下缺陷:
1)造成对离线数据库的访问压力,影响离线数据库自身的业务,直接影响到实时计算的性能;
2)不同的离线数据库差异,难以保障读取大表数据记录可秒级响应的能力,导致实时计算延迟,造成大量实时数据堆积的现象;
3)完全读取内存数据时,离线库表变动的数据无法及时同步到内存,导致数据计算错误;
4)对接多个不同介质的数据源时,数据格式不统一,无形中增加了研发成本以及实现的复杂度,在计算过程也增加了解析的复杂度,影响计算性能。
综上所述,实时计算急需提供一款端到端解决复杂实时计算场景的实时计算工具,真正地解决实时数据市场的这些难题和困境。
01
解困之道
为提升复杂业务逻辑的实时计算性能,加强数据端到端的计算的实效性,通过设计分布式动态表来桥接,其优势主要有:
1) 实时同步不同介质的库表数据,保障参与计算的数据完整性与正确性;
2) 标准化不同介质的库表数据和实时计算的接口,减少实时计算过程中对离线库表的频繁访问,很好地保护了离线库的稳定性;
3) 通过近次内存存储介质,分布式存储数据,可存储的大表数据,提升数据访问的性能。
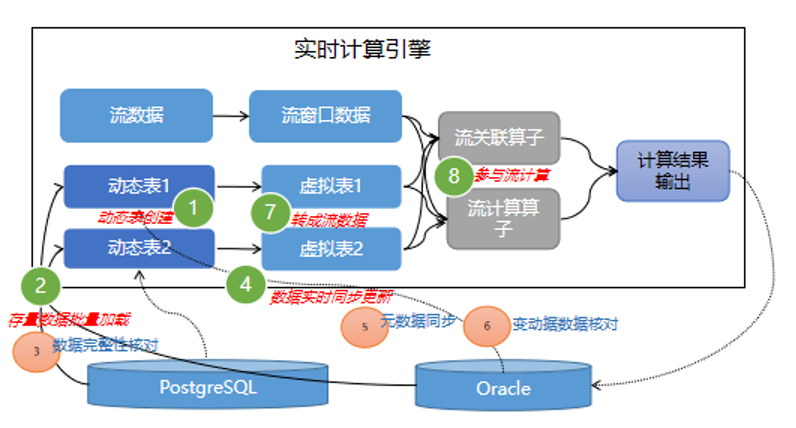
下图介绍实现的过程:
通过动态表实现实时计算端到端的计算性能
搭建一个分布式存储动态表数据的组件,实现对多源数据库类型的数据统一管理与存储,同时为实时计算提供标准的数据接入方式,满足实时任务高效的读写性能、支持分布式扩缩容存储,满足亿级大表的存储需求,提供方便简易的sql操作支撑,可快速接入与使用分布式动态表管理组件。
02
关键技术实现
构建分布式动态表存储空间
RocksDB
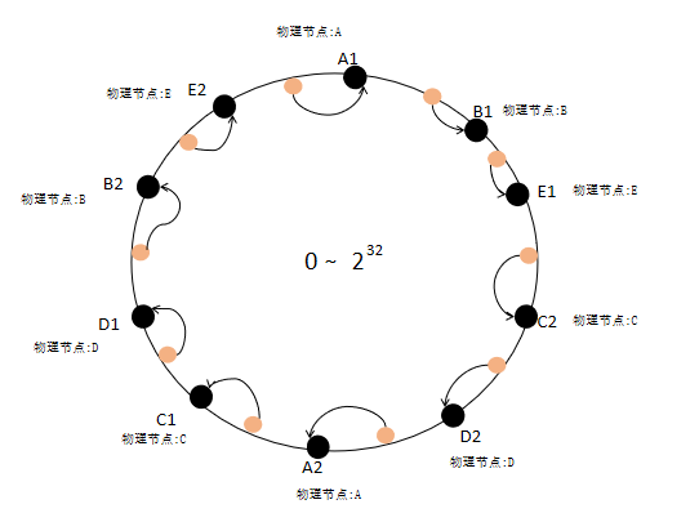
是单节点存储引擎,具备良好高效的存储性能,可满足实时计算数据存储与计算的秒级性能要求,利用 RocksDB 存储引擎良好的性能,通过虚拟节点一致性哈希算法分布均衡存储,结合简易的SQL来高效读写数据,设计并实现一个能够提供高效、稳定和可靠的持久化存储服务的分布式动态表管理组件。
分布式动态表管理组件的核心是要实现分布式存储,通过虚拟节点的一致性哈希算法来实现数据的分布均衡存储,均衡存储主要解决:
1)分布均匀,即每个存储节点上的数据量尽可能相近;
2)负载均衡,即每个存储节点上的请求量尽可能相近;
3)扩缩容时产生的数据迁移尽可能少。
虚拟节点的一致性哈希算法的意义在于:当增加或者删除节点时,只影响变动节点临近的一个或两个节点,哈希表的其他部分保持不变,某种程度上可以理解为:一致性哈希的哈希函数与节点数无关。虚拟节点主要将整个哈希空间抽象成为一个虚拟圆环,假设哈希函数的值空间为 0 − (2^32 − 1),即 32 位无符号整数,此值可以根据实际部署规模调整,默认为:1024(虚拟节点总数M)。
高效导入分布式动态表数据
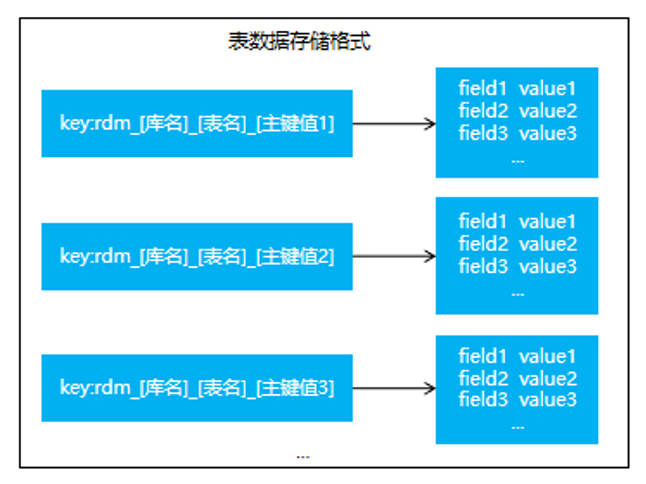
分布式动态表管理组件是一种高效的缓存,具备内存数据库、响应快的特点,支持数据的持久化,将内存中的数据保存在磁盘中,其速度远超数据库,性能极高,能读的速度可达110000次/s,写的速度可达81000次/s。
数据读取时从内存中获取库表的元数据信息,包括主键、索引、属性
如连接等信息
,然后通过Reader插件连接数据源读取解析相应的数据,缓存存储格式如下:
实时更新分布式动态表数据
针对源端库表中发生的INSERT(新增数据)、UPDATE(更新数据)、DELETE(删除数据)操作时,实时同步数据到分布式动态表中,以保障数据的即时性:
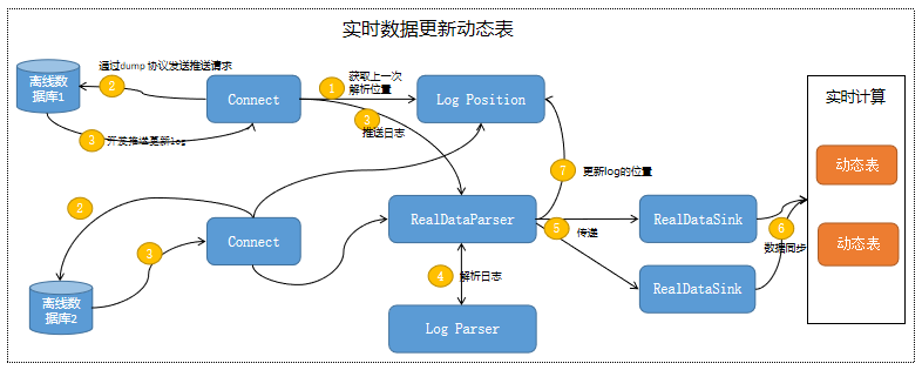
如上实现对离线库表数据的实时拉取与同步的流程,实现的步骤:
1) 离线数据开始推送INSERT、UPDATE、DELETE的更新Log数据;
2) RealDataParser接收到的log数据,根据日志类型调用相应的日志解析器,通过log parser进行协议解析,补充一些特定信息,补充字段名字、字段类型、主键信息、索引信息等,解析完成后数据通过库表与主键的hash等略分发到相应的RealDataSink模块;
3) RealDataSink实现数据的数据存储,是一个事务性的阻塞操作,直到存储成功。
实现流数据与动态表的计算
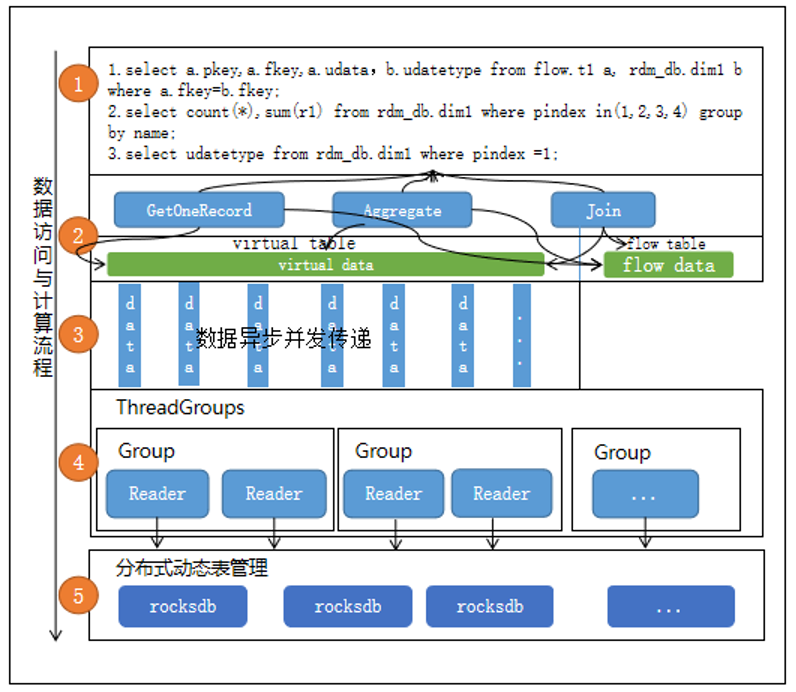
Flink是最适合的低时延的数据处理(Data Processing),且具备高并发处理数据,兼具可靠性等特性,利用Flink的能力接合高效动态分布式表,实现复杂的实时计算场景,主要通过下面的步骤实现流数据与动态表的计算,解决复杂业务逻辑的实时计算秒级要求。
步骤1:利用flink sql的现有能力,可直接读取动态表的数据,上图第1步列出的3条sql语句分别代表关联计算、聚合计算、取值等;
步骤2:同样利用flink的现有能力,对动态表(virtual table)的数据(virtual data)与流表(flow table)的数(flow data)据进行各种类型的计算,如关联(join)、聚合(Aggregate)、取值(GetOneRecord)等计算;
步骤3:按需加载动态表的数据,解析sql,拆分出动态表部分的sql,可以转换api形式如hmget(key*、f1、f2),然后预判取数的形式(单条数据、多条固定数据量的记录、关联查询的记录等)计算将要生成的取数记录数来切分取数的任务,将取数据的语句的任务切分成多个小的子任务,并发执行。
03
成效
充分利用当前优秀的开源技术的组合,通过优化修改开源组件,在适当的环节巧妙利用技术分步分层加载大表数据,按需加载大表数据,有效将大表按需拆分解成小表,同时利用内存的高效特性,提供大表存储数据组件,标准化多源库表数据的结构,提升了实时计算的性能,有效地解决实时业务对存量大表的计算性能问题;利用批量与推送协议的方式同步源端的数据,消除对源端库表造成访问的压力,可以满足大部分实时流与离线数据结合计算的业务场景要求,拓宽了实时计算能支持的业务范围,很好地解决了实时计算结合外部数据源大表下的复杂业务逻辑的实时计算要求。
例如业务场景:客户办理业务时过程中实时判断当前客户是否欠费。
客户在办理业务时,都想有一个好的体验效果,因此要求业务办理的各环节都需要快速响应,所以对客户是否欠费的判断需要在秒级内响应,考虑可以处理千万级别的客户数,技术组件采用
ES
来存储客户数据,ES可以满足大并发大数据量下数据的秒级查询性能要求;客户的实时消费的变更数据存储在Oracle数据库中,此部分数据会实时增量同步到kafka,再经过实时计算后更新ES中的客户状态数据,实时计算实现逻辑如下:
1) 根据客户编码读取Oracle库表的客户当前费用信息;
2) 计算的结果是否大于0来判断是否欠费;
3) 并将结果信息更新到Oracle与ES中。
针对以上计算场景,实现步骤如下:
1)创建分布式动态表客户信息表;
2)初始化加载分布式动态表客户信息表(亿级);
3)配置源表与分布式动态表的实时数据同步任务;
4)通过sql实现实时业务逻辑开发:
Select 客户名称、证件有效期、当前费用、是否欠费......from rdm_xxtel.custinfo(动态表中的客户信息表) where 客户编码=?
5)接合流数据接入与上述的4)的动态表数据进行计算判断:
计算:费用=客户.当前费用-流.消费费用
如果:费用小于0表示客户当前欠费,更新结果到ES与Oracle表中;
说明:此案例用到动态表中的数据参与实时计算过程,如上面4、5步,均需要根据存量系统的客户信息表来判断业务逻辑。
在没有使用动态表前,并发任务增加多时会实时读取Oracle的中数据,并创建过多的Oracle的连接数,会对Oracle正常的业务受理造成不少的压力,同时无法完成秒级计算的同步数据到ES的能力。
使用动态表后,将原来需要并发多实时任务对Oracle的数据库表,全部转移到读到动态表的数据,不管多少任务对Oracle的连接都保持1个,极大的减少读写Oracle的压力,保障了业务系统正常运行;由于数据采用近内存的存储与计算,流计算与离线计算接合计算时可达到了秒级计算的效果,满足了业务的实时性要求,极大的提升了实时计算的能力。
端到端
分布式存储
分布式技术
分布式部署
动态
文章转载自
浩鲸科技
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨