




01.
背景
在经过多轮的优化后,采用缓存技术提升查询性能,采用数据库分库的方式提升写入性能。但数据库写入操作仍然是较为明显的性能瓶颈。如何进一步降低数据库阻塞对系统性能的影响成为工单系统首先考虑的内容,通过异步写入数据库的方式可以有效的降低对数据库的写入效率的依赖,进一步提升系统性能。
02.
异步持久化
数据架构
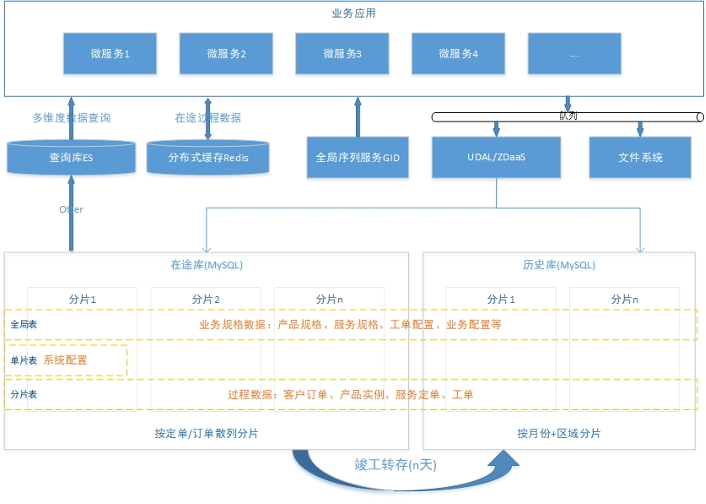
系统配置数据:主要包括数据字典、人员权限等,在数据库中使用单片表存储。在应用启动时批量加载到JVM本地缓存中。
业务规格数据:主要包括产品模型、定单规则、工单规则、模板等,在数据库由于与实例表存在关联关系,因此使用全局表存储。在应用启动时批量加载到JVM本地缓存中。
过程实例数据:主要包括定单、工单等相关信息,在数据库中分为在途库与历史库。在途库:以定单为单位,按定单标识散列分片;历史库:按月分+区域进行分片。
查询库:工单系统需要使用定单监控、工单监控、待办任务等列表查询,使用关系型数据库查询时难以避免跨库的情况,因此使用ES实现查询库解决多纬度列表查询问题。利用Otter等数据同步组件,采用侦听Mysql binlog的方式实现数据准实时同步。
文件系统:存储系统间交互报文、附件等。
全局序列:用于提供序列服务。
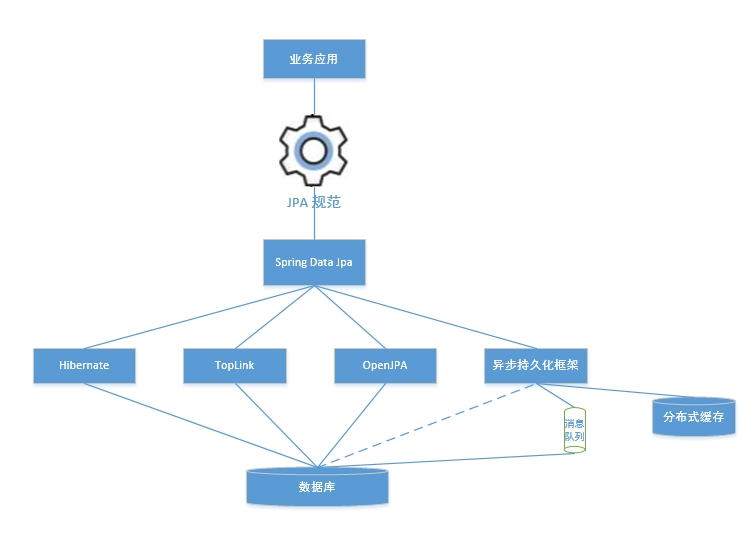
异步持久化框架

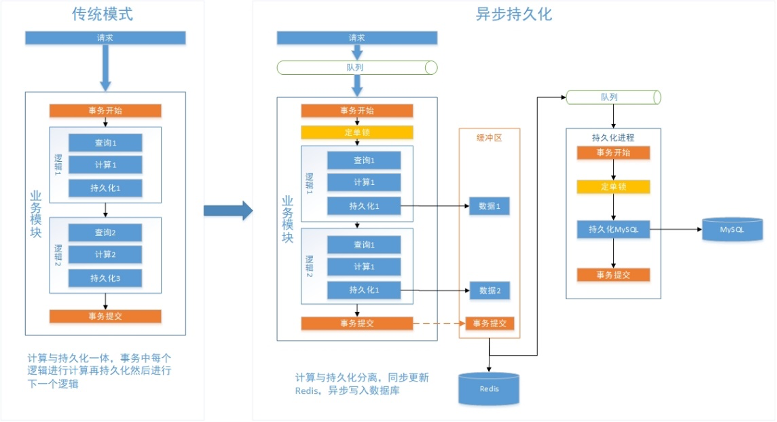
配置数据,通过JVM本地缓存查询,如果数据不存在再通过数据库查询。
实例数据,通过分布式缓存查询,如果数据不存在再通过数据库查询。
在业务逻辑请求写入数据时,异步持久化框架只将数据写入当前线程的缓冲存,并不真正操作数据库。
提交事务时,框架负责将数据分别写入分布式缓存供下游模块使用,再写入队列。
持久化进程侦听消息队列,真正完成数据写入。
分片计算
获取定单序列,记为 ${定单序列}
根据分片数量计算分片标识,分片标识(4位) = ${定单序列} mod ${分片数量}
定单标识 = ${定单序列} + 分片标识
获取工单序列,记为 ${工单序列}
通过定单获取分片标识,分片标识 = ${定单标识}后4位
工单标识 = ${工单序列} + 分片标识
低代码入侵
事务控制
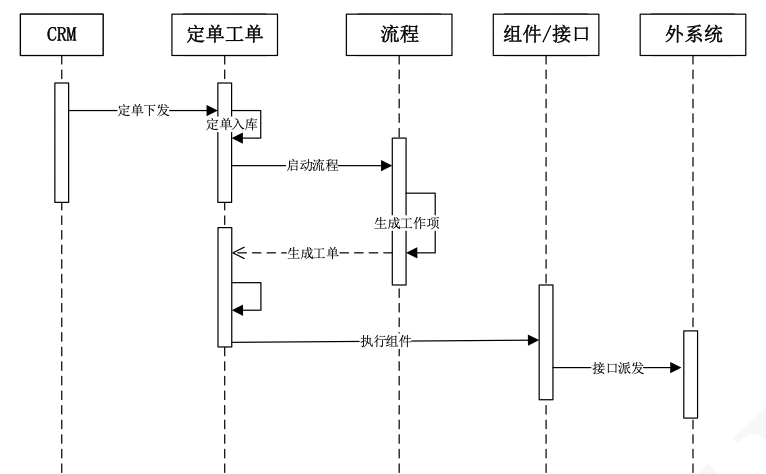
长事务拆分:在单体应用改造为微服务架构时,一般将会按业务能力将应用拆分为多个微服务,以开通系统举例主要分为定单工单、接口、流程微服务。最典型场景为定单入库与回单场景,如下图所示为定单接收入库场景。在过程中涉及多个微服务的同步调用,很容易对系统稳定性造成不良影响。因此采用消息驱动的方式对事务进行拆分。
数据库及缓存操作:数据库及缓存操作,指通过上述消息驱动完成拆分的各业务单元内部多次操作数据库与缓存。系统需要对当前过程做严格的事务控制。
每条消息需要有一个唯一标识
写入队列的同时,记录消息日志,此消息日志为可解析的文本文件
消费时需要在缓存中记录消费记录
消费时需要在缓存中进行记录比对,以确认是否已经进行消费去重
对于消息日志,需要定时进行比对稽核补偿
利用队列的顺序消息,实现顺序控制。由于对性能影响较大,因此并未采用。
将存在更新要求的库表增加变更记录表,因此可以将更新操作改为新增操作,实现最终一致性。具备高性能高扩展性的优点,但增加了代码复杂度(尤其是查询)。目前主要应用于对性能与扩展性要求较高的场景,如移动业务与停复机业务支撑。
消息分发时指定队列,使同一定单的信息在同一线程中进行处理。优点是性能较高代码量代,缺点为扩容时需要变更分布配置。目前主要用于固网业务支撑中。
数据查询
查询配置数据:通过JVM本地缓存查询,本地缓存无法查询时,查询数据库。
根据标识查询定单数据:根据定单标识查询定单、工单标识查询工单等,通过分布式缓存查询。缓存查询不到时查询数据库。此时根据分片算法中,根据标识的后4位为分片标识,直接路由到相应分片查询。
多纬度查询:通过利用搜索引擎实现的查询完成。
数据库扩容
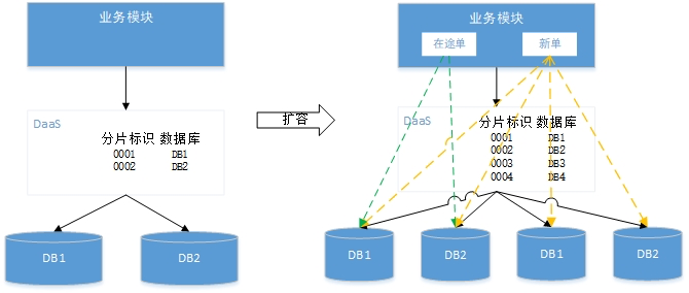
写入数据,定单以2取模,其它数据直接取定单分片标识;
查询数据,取标识的后4位作为分片标识路由到数据库分片。
在途定单新生成数据时,直接所定定单标识的后4位作为分片标识。因此原在途定单在哪个分片,其生成的后续数据都在哪个分片;
新生成定单时,以分片数量4进行取模,平均分配到4个数据库分片中;
数据查询时,无论在途单还是新定单,都可以从标识取后4位进行路由。
03.
实践与收益
目前OSS工单产品,以编排中心、服务开通、激活为代表全面实现异步持久化。极大的降低了系统对于数据库的依赖,在同等硬件条件下性能提升20倍以上。各省项目定单处理能力由原来以几百每分钟,提升到几千每分钟。
