




作者:稀饭
1、交互式处理
交互式处理是指操作人员和系统之间存在交互作用的信息处理方式。在大数据领域,交互式计算(处理)引擎是针对大数据具备交互式分析能力的分布式计算引擎,它常用于OLAP(联机分析处理)场景。相比批处理引擎(MapReduce或Hive),对数据处理性能要求更高。为了实现高性能数据处理,交互式计算引擎通常采用MPP架构,并充分使用内存加速。
2、交互式查询引擎分类
(1)ROLAP
基于关系型数据库OLAP实现。它以关系数据库为核心,以关系型结构进行多维数据的表示和存储,将多维结构划分为事实表和维度表两类。ROLAP的最大好处是可以实时地从源头数据中获得最新数据的更新,以保持数据实时性,缺点在于运算效率比较低,用户等待的响应时间比较长。
(2)MOLAP
基于多维数据组织的OLAP实现。它以多维数据组织方式为核心,使用多维数组存储数据。多维数据在存储系统中形成“数据立方体”的结构,该结构是经过高度优化的,可以最大程度地提高查询性能。MOLAP的优势在于借助数据多维预处理显著提高了运算效率,主要的缺陷在于占用存储空间大和数据更新有一定的滞后。
(3)HOLAP
基于混合数据组织的OLAP实现。用户可以根据自己的业务需求,选择哪些模型采用ROLAP,哪些采用MOLAP。一般来说,将不常用或需要灵活定义的分析使用ROLAP的方式,而常用、常规模型采用MOLAP实现。
3、Impala简介
由Cloudera公司研发,其最初的设计动机是充分结合传统数据库与大数据系统Hadoop的优势,构建一个全新的、支持SQL与多租户、并具备良好灵活性和扩展性的高性能查询引擎。
4、Impala进行查询的优势
(1)Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想,采用了全服务进程的设计架构,所有计算均在预先启动的一组服务中进行,可支持更高的并发,同时省掉不必要的shuffle、sort等开销;
(2)Impala采用全内存实现,不需要把中间结果写入磁盘,省掉了大量I/O开销;
(3)Impala充分利用本地读(而非远程网络读),尽可能地将数据和计算分配在同一台机器,减少了网络开销。
5、Impala基本架构
Impala采用对等式架构,所有角色之间是对等的,没有主从之分。Impala主要由三类服务组件构成:
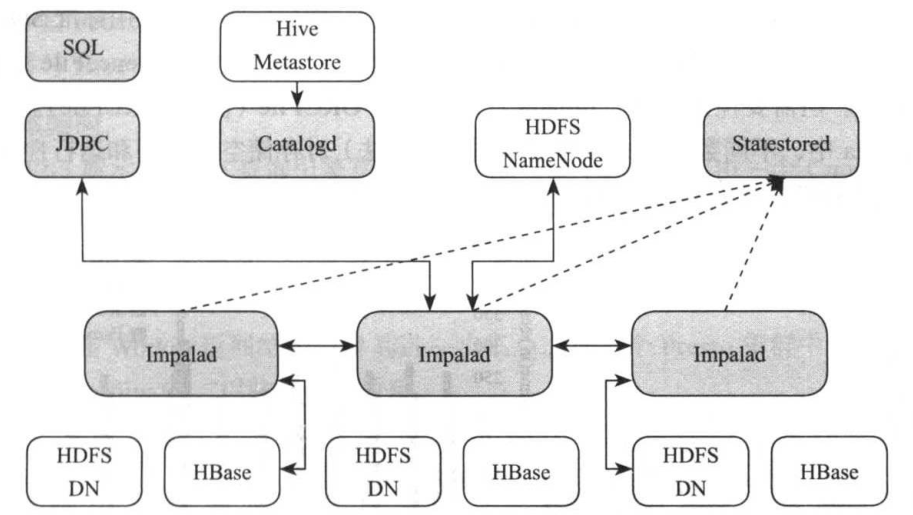
(1)Catalogd。元信息管理服务。它从hive metastore中同步表信息,并将任何元信息的改变通过catalogd广播给各个Impalad服务;
(2)Statestored。状态管理服务器。元数据订阅-发布服务,它是单一实例(存放单点故障问题),将集群元数据传播到所有的Impalad进程;
(3)Impalad。同时承担协调者和执行者双重角色。首先,对于某一查询,作为协调者,接收客户端查询请求并对其进行词法分析、语法分析,生成逻辑查询计划以及物理查询计划,之后将各个执行片段调度到Impalad上执行。其次,接收从其他Impalad发过来的单个执行片段,利用本地资源处理这些片段,并进一步将查询结果返回给协调者。
6、Impala与传统关系型数据库的区别
(1)由于HDFS存储系统自身的限制,Impala目前不支持面向单行的update和delete操作,而只支持按批插入和删除;
(2)数据加载速度快,运行时会进行类型校验;
(3)不支持事务。
广告区↓

