





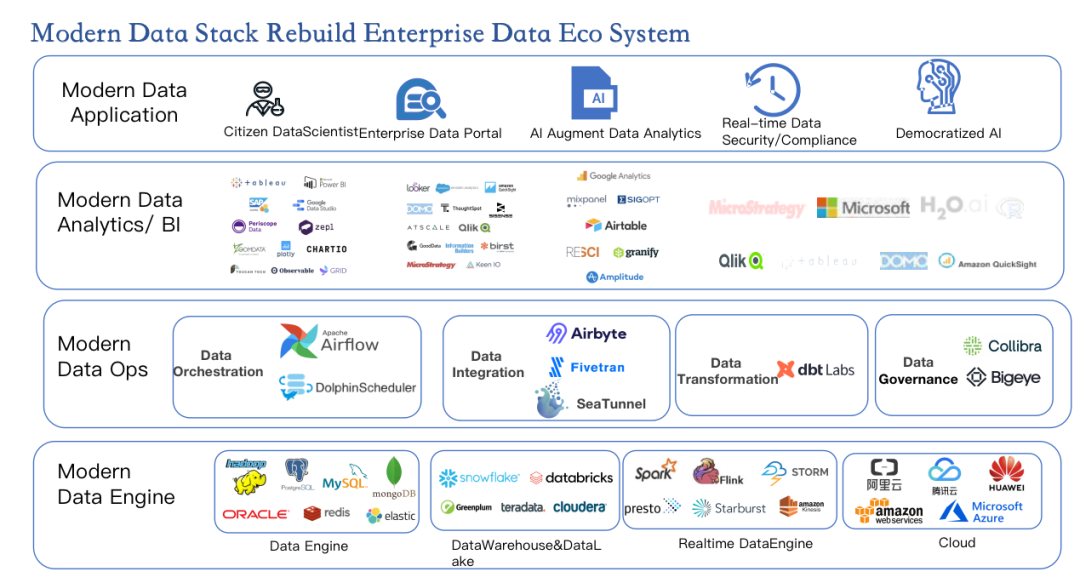
现代数据堆栈重构了企业数据生态系统。Hadoop、Snowflake、数据库、数据湖等数据引擎和Flink、Spark Streaming、Amazon kinesis等实时数据引擎和云服务支持数据处理,配合大量BI工具和数据应用,可以构建企业的大数据平台。

01
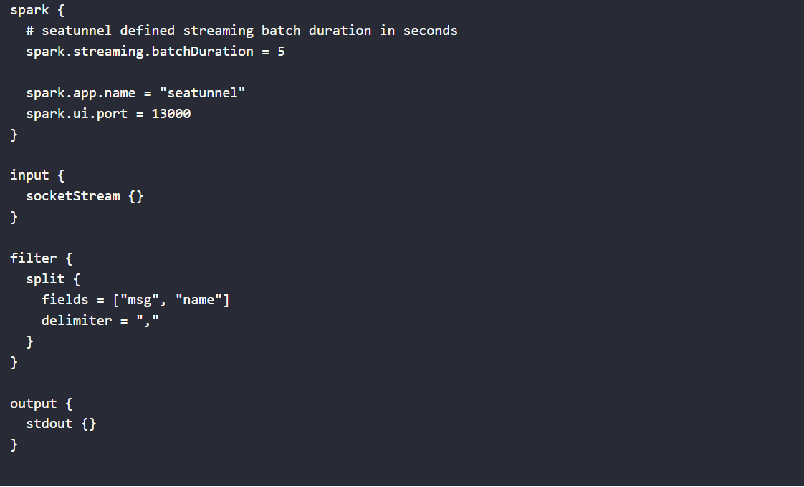
Apache SeaTunnel
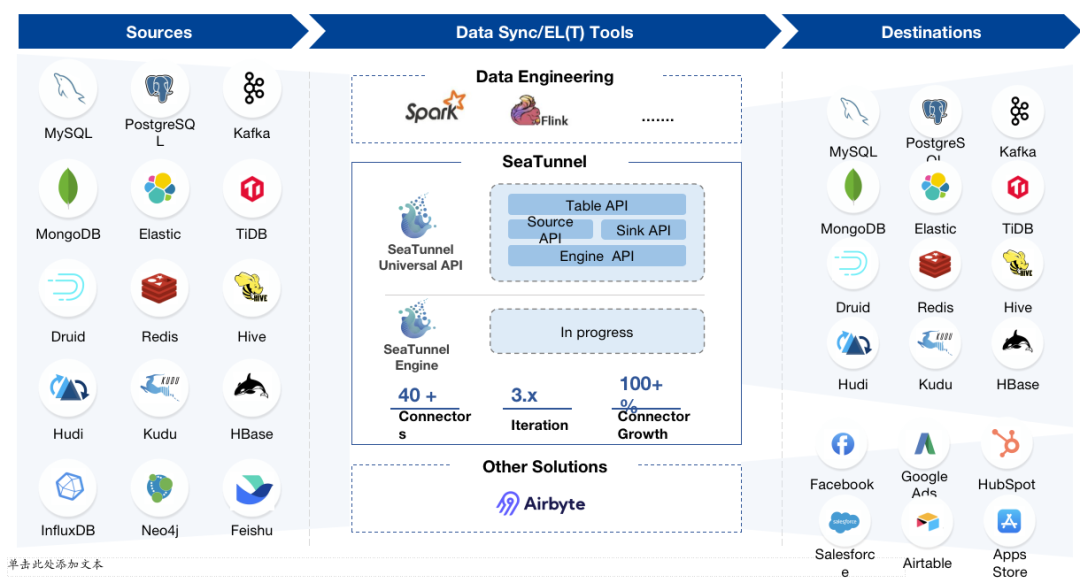

多种数据来源
批量加载数据和CDC冲突的问题
技术堆栈复杂
数据质量和监控
管理和维护困难


02
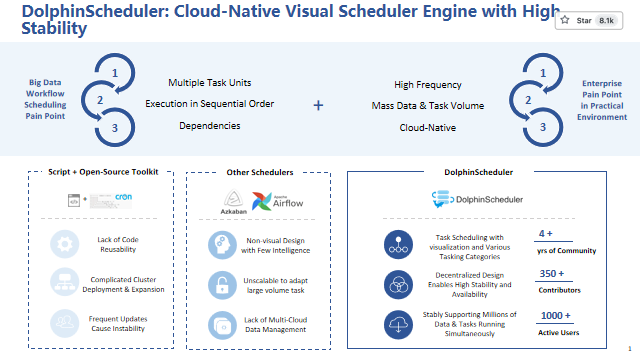
Apache DolphinScheduler
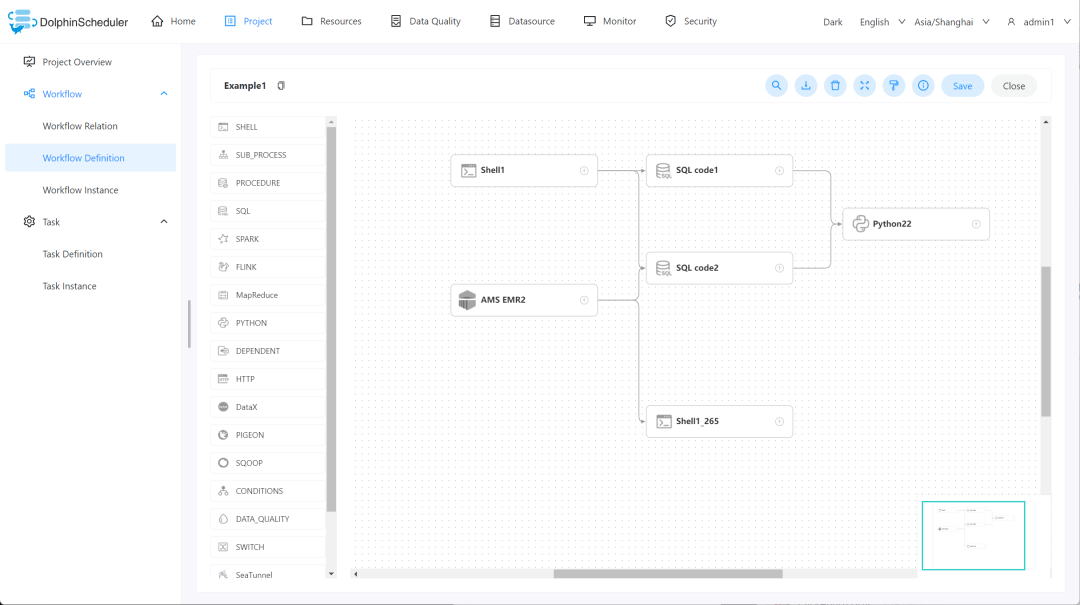
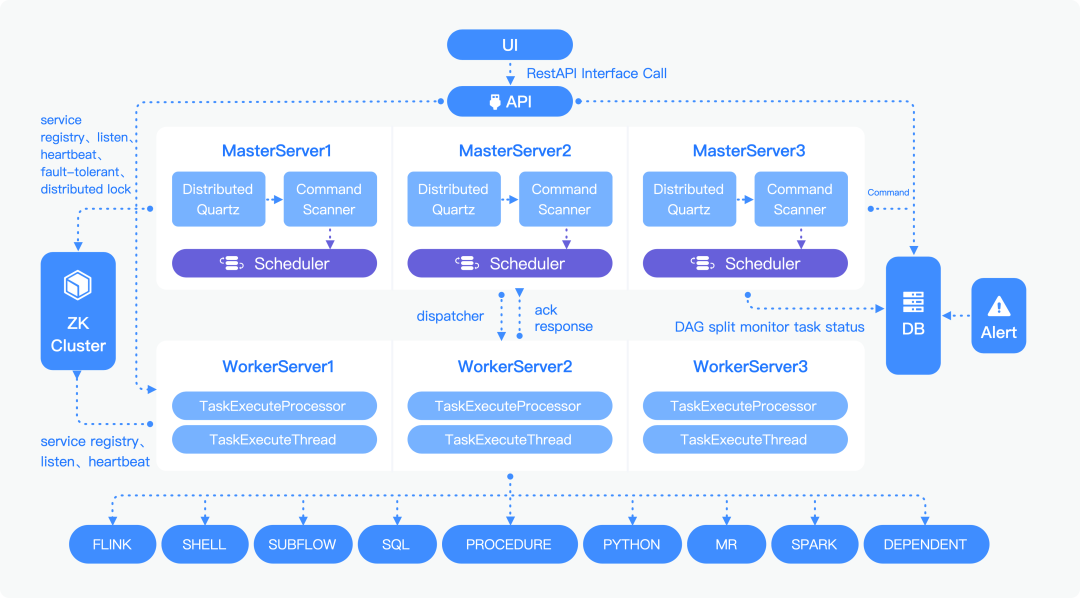

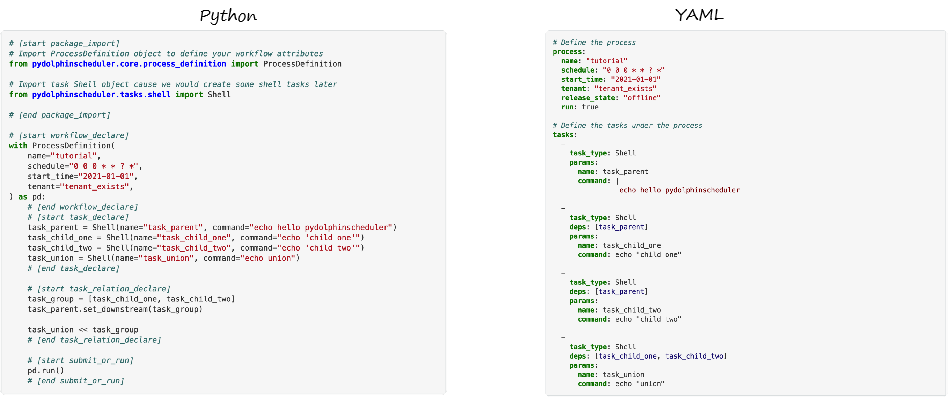
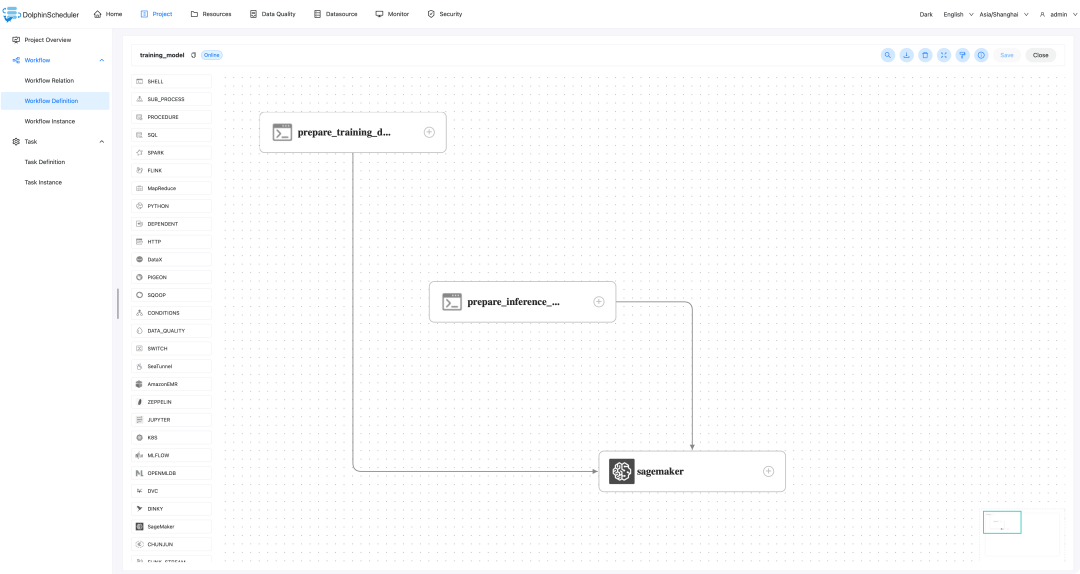
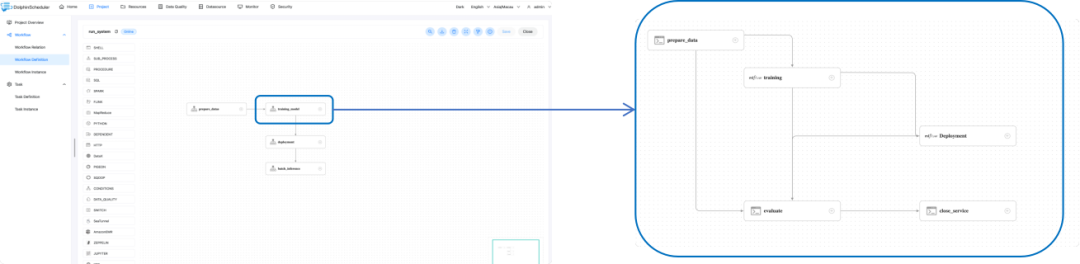
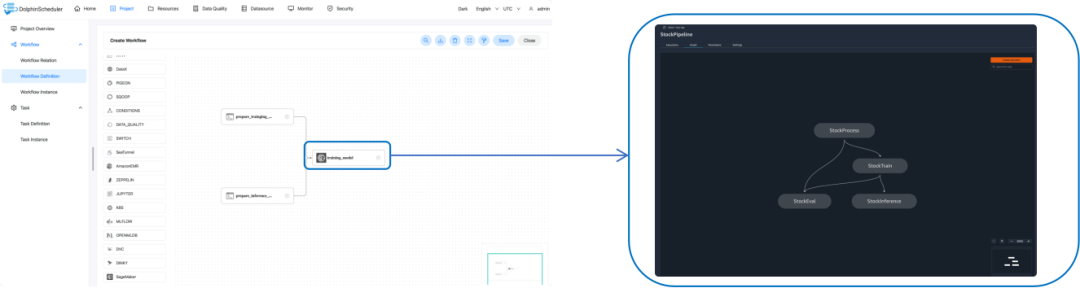



Apache SeaTunnel

往期推荐
点击“阅读原文”参与活动!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
