




参考信息:
一.文章示例图采至云和恩墨oracle aced 侯圣文老师于2017年7月29日培训演讲所用ppt及展示图。
二.安装指导文档(中文)可以自行参考以下url
http://hadoop.apache.org/docs/r1.0.4/cn/index.html
注:版本比较老,目前中文版书籍比较多,中文doc大家已经不再更新。
三.不错的中文资料
http://www.yiibai.com/hadoop/introto-flume-and-sqoop.html
四.http://www.cnblogs.com/chamie/p/4737423.html
http://blog.csdn.net/u010270403/article/details/51648462
Hapdoop基本概念图
Hadoop早期解决方案
Hadoop由来

Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
Hadoop的发音是 [hædu:p]。
Hadoop是基于google的研究成果发展而来。分布式存储基于2003年,google发布的GFS(google file system),分布式运算基于2004年,google发布的map reduce论文。
最后,我们假定一个场景,对10T文件进行grep检索。
传统方式:会消耗大量时间
Hadoop方式:每台服务器计算自己的数据,将所有结果集传输到发起请求的节点,节点对所有结果集再次运算,并行可以节约大量时间。
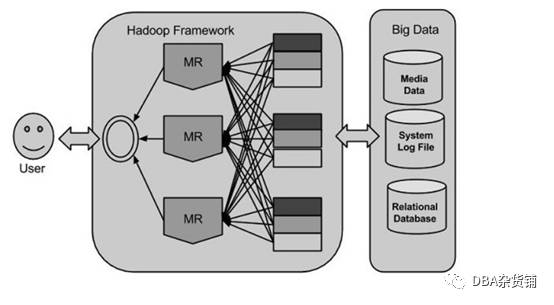
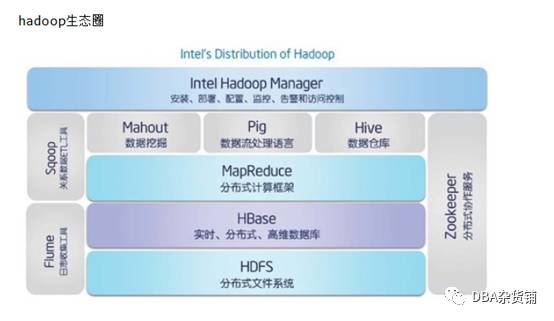
Hadoop生态系统与大数据
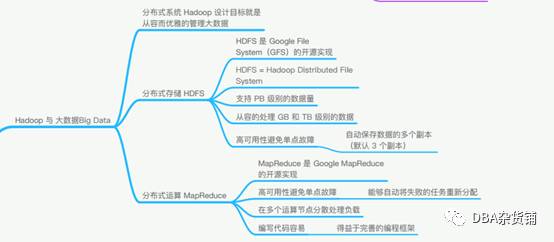
HDFS(分布式存储)
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。
MAPREDUCE(分布式运算)
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 通常会把输入的数据集切分为若干独立的数据块,由map任务(task)以完全并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,Map/Reduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
Map/Reduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(jobconfiguration)。然后,Hadoop的 job client提交作业(jar包/可执行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给job-client。
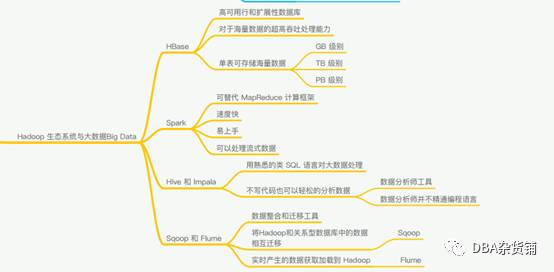
Hbase
HDFS作文存储文件系统,无法直接进行修改操作,HBase正是为此而出现。
HBase是一个面向列的数据库,一个NoSql的数据库,运行在HDFS之上,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。
Spark
简单点,我们可以把Spark理解成自动添加cache的MapReduce就可以了。
Hive和Impala
简单而说,如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReducejobs就可以用Hive代替.
Sqoop和Flume
Apache Sqoop(SQL到Hadoop)被设计为支持批量从结构化数据存储导入数据到HDFS,如关系数据库,企业级数据仓库和NoSQL系统。相当于,hadoop与其他数据库之间的数据交换(导入和导出)。
Apache Flume 用于移动大规模批量流数据到 HDFS 系统,从Web服务器收集当前日志文件数据到HDFS聚集用于分析。
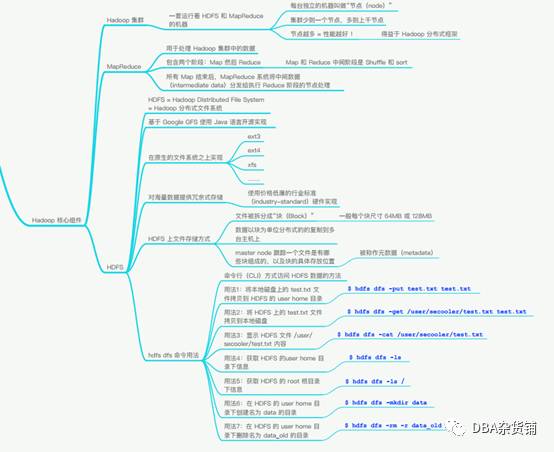
Hadoop核心组件
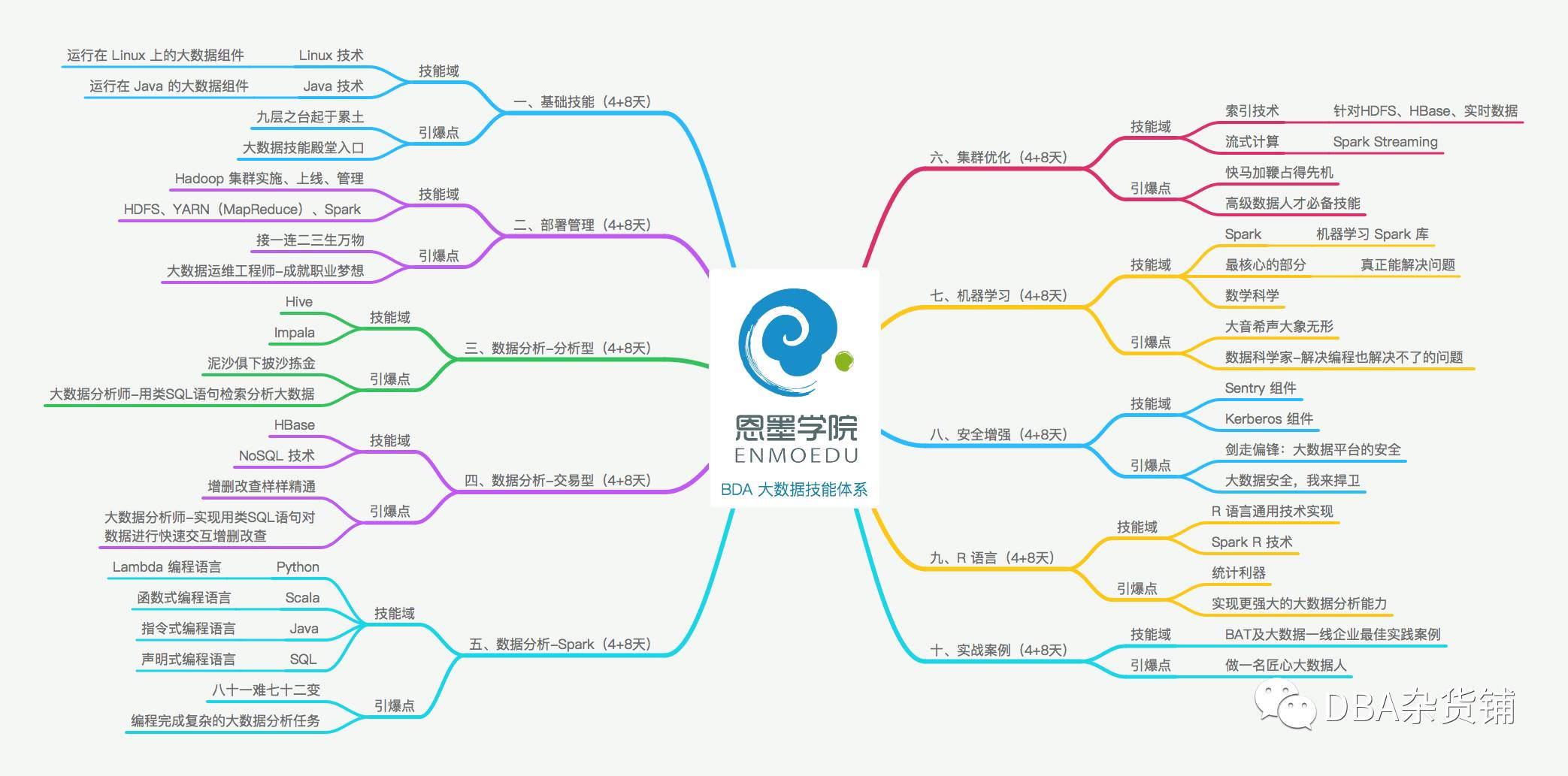
培训体系(学习体系)
职业发展方向
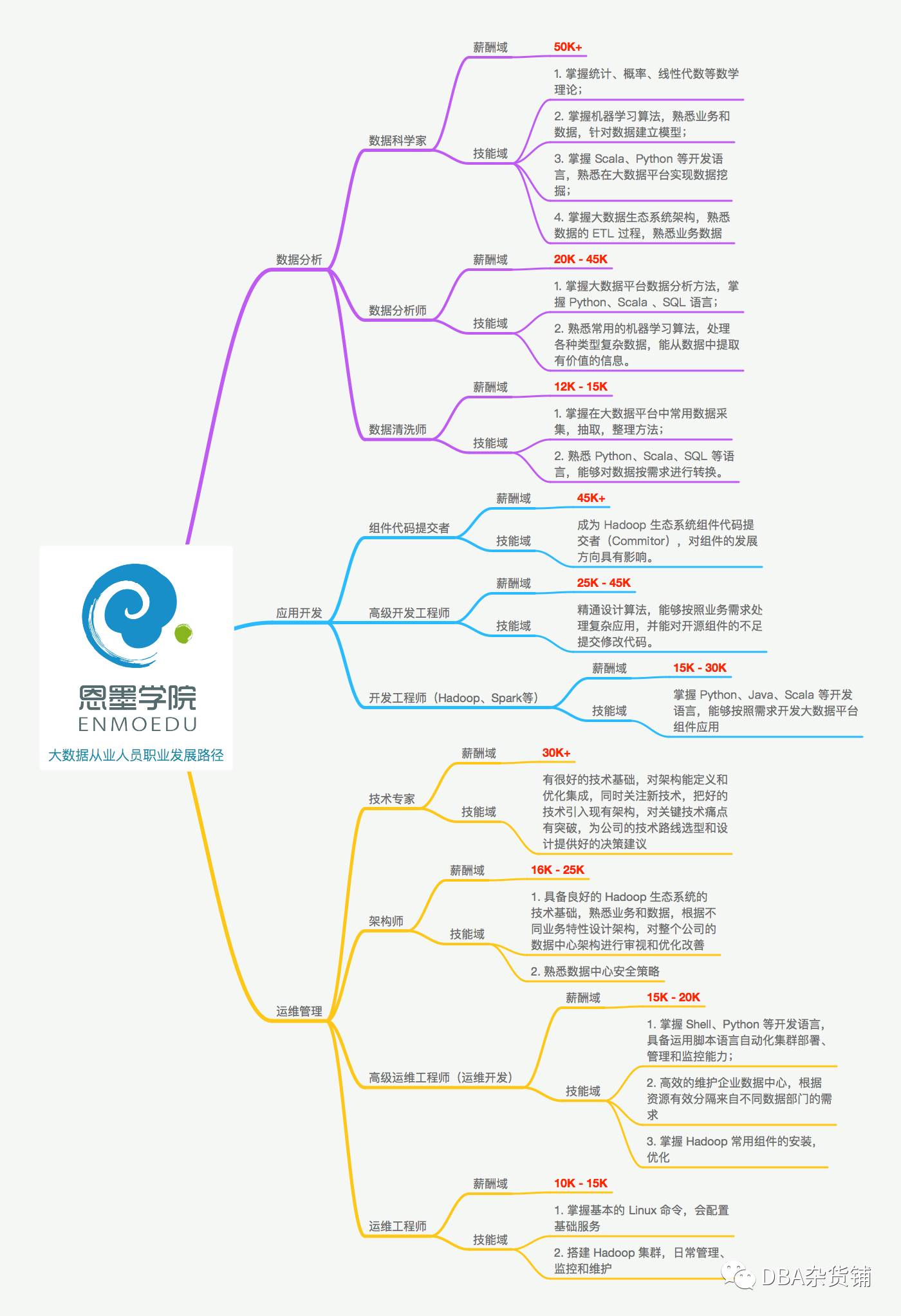
这个收入。。。。好像没有这么光明。。。。
