




文 | 小铁
01
客户突然打过来,“我们的服务器宕机了,赶快先远程上来看看,马上派人半小时内到现场,赶快出个书面说明...”
产品组,运维,开发,架构师,DBA,测试,存储集成... 纷纷拧成一股绳,这就是我们所处的时代。
有人疑惑了,为什么宕机后,我们的app,web都好好的,没有感知到异常呀? 这就是我们能够支撑这个时代的产品的原因,比如在券商界,银行界大放异彩的Oracle RAC集群。

02
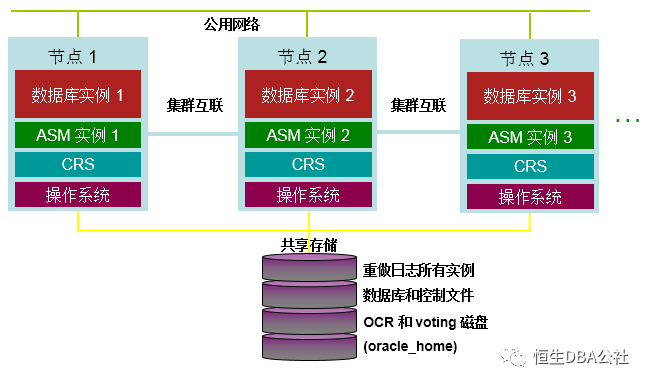
什么是Oracle RAC集群?
真正应用集群,简称Oracle RAC ,是Oracle的并行集群,位于不同服务器系统的Oracle实例同时访问同一个Oracle数据库,节点之间通过私有网络进行通信,所有的控制文件、联机日志和数据文件存放在共享的设备上,能够被集群中的所有节点同时读写 。
RAC的优点是什么?
高可用性和负载均衡,一台机器宕机不影响应用访问数据库。
高可用性的基础就是Failover。它是指在集群中任意一个节点的故障都不会影响用户的使用,连接到故障节点的用户会被转移到健康的节点,对于用户而言,几乎是感受不到这种切换。
实际应用中,failover实现的方式是什么?
Client-Side TAF:连接建立以后,应用系统运行过程中,如果某个实例发生故障,连接到这个实例上的用户会被自动迁移到其他的健康实例上。对于应用程序而言,这个迁移过程是透明的,不需要用户的介入,当然,这种透明要是有引导的,因为用户的未提交事务会回滚。 相对与Client-Side Connect Time Failover的用户程序中断(抛出连接错误,用户必须重启应用程序),TAF这种方式在提高HA上有了很大的进步。

TAF是如何配置的?
在客户端的tnsnames.ora中添加FAILOVER_MODE配置项
kfhsdb1 =
(DESCRIPTION =
(ADDRESS_LIST =
(address = (protocol = tcp)(host = kfhs-vip1)(port = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = hsdb)
(INSTANCE_NAME = hsdb1)
(failover_mode =
(backup = kfhsdb2)
(type = select)
(method = preconnect)
)
)
)
kfhsdb2 =
(DESCRIPTION =
(ADDRESS_LIST =
(address = (protocol = tcp)(host = kfhs-vip2)(port = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = hsdb)
(INSTANCE_NAME = hsdb2)
(failover_mode =
(backup = kfhsdb1)
(type = select)
(method = preconnect)
)
)
)
failover_mode选项的4个子条目的含义是什么?
METHOD: 用户定义何时创建到其实例的连接,有BASIC 和PRECONNECT 两种可选值。
BASIC: 是指在感知到节点故障时才创建到其他实例的连接。
PRECONNECT:是在最初建立连接时就同时建立到所有实例的连接,当发生故障时,立刻就可以切换到其他链路上。
TYPE: 用于定义发生故障时对完成的SQL 语句如何处理,
其中有2种类型:session 和select
这两种方式对于未提交的事务都会自动回滚,区别在于对select 语句的处理,对于select,用户正在执行的select语句会被转移到新的实例上,在新的节点上继续返回后续结果集,而已经返回的记录集则抛弃。
DELAY 和 RETRIES: 这2个参数分别代表重试间隔时间和重试次数
我们使用两段式Client-Side TAF的原因是什么?
避免cache fusion,而且对应用来说,要用分用户的方式,精确的知道跑在哪个节点。
预连接隐藏的故障点什么?
某个节点的预连接,当库被重启或者做过切换后,这时候预连接是已经失效了的,是无法再次切换的,这个时候我们需要做的是收市后,或者没有跑业务的时候,所有节点实例重启,生产新的预连接会话。
03
高可用切换场景预想?
场景1:
实例宕掉(数据库所在的服务器会主动通知中间件去断开tcp连接)
这种情况下:
如果中间件正在等待数据库返回结果,能直接感知到中断的信号,直接触发连接切换, 完成切换
如果中间件当前的连接是空闲的,没有干任何事情,当前是没有办法知道的,必须依赖下一笔数据库请求或者keepalive机制去检测连接断开,由下一笔业务请求来触发切换,
如果中间件此时正在发起业务请求的话,就能立刻感知到连接断开,完成连接切换
场景2:
机器重启或者网络不通,(oracle 会发生vip漂移)
断电,重启,或者应用服务器跟数据库服务器网络不通的情况下,将出现问题的那台机器的vip就会漂到正常的那台机子上。
这种情况下:
如果中间件正在等待数据库返回结果,此时是没有办法感知到的,因为中间件与数据库的连接已经中断,中间件必须依赖keepalive机制检测到连接断开,从而完成连接切换
如果中间件当前的连接是空闲的,同类别1,空闲连接,需要下一笔业务请求,或者keepalive机制触发
如果中间件此时正在发起业务请求的话,即异常发生后,中间件再发起业务请求的话,也是能立刻感知到连接断开的,因为vip已经漂到正常的节点上去,但是此时是没有应用在的,当业务请求发出去,可能在网络层面是正常的,但应用层会报一个连接中断的信号,所以应用层是能感知到连接中断的,完成连接切换
这里还要考虑2种情形:
数据库能感知到本身的异常,而且中间件与数据库的预连接是正常的情况下,此时是能够完成切换的
中间件与数据库的预连接出现问题或者机器hang住了,但是网络还是正常的,自己本身没有完成切换,所以应用是没有办法切换的。
04
如何验证高可用切换?
无应用场景测试:
场景1:拔掉节点1(或者2)所有的心跳线:
结果:节点1正常,节点2VIP漂到节点1,节点2实例down掉,漂移时间30s
场景2:节点1上建立多个会话,拔掉节点2的所有心跳线
结果:节点1正常,持有2个VIP;节点2down掉
场景3:拔掉节点1的所有外网网线:
结果:节点1VIP漂到节点2;节点1实例无VIP继续运行;节点2实例持有两个VIP,漂移时间10s
场景4:拔掉节点2的所有外网网线:
结果:节点2VIP漂到节点1;节点2实例无VIP继续运行;节点1实例持有两个VIP,漂移时间15s
场景5:同时拔节点1所有的心跳线和外网网线:
结果:节点2down掉,无VIP;节点1实例运行,无VIP
场景6:同时拔节点2所有的心跳线和外网网线:
结果:节点2down掉,无VIP;节点1实例运行,持有两个VIP
场景7:节点1(或者节点2)实例宕掉:
结果:VIP不会发生漂移,节点1实例offline。
场景8:节点1机器重启:
答:节点2正常,并持有2个VIP;
场景9:节点2机器重启:
答:节点1正常,并持有2个VIP;
带应用场景测试:
测试重点:
关注中间件在不同场景下,发生异常的时候,是如何发生转换的
Ø 正常启动后,每个中间件发送一笔查询请求
Ø 执行对应的异常操作(拔线,断电,实例关闭等等)
Ø 每个中间件发送一笔委托请求
其中:
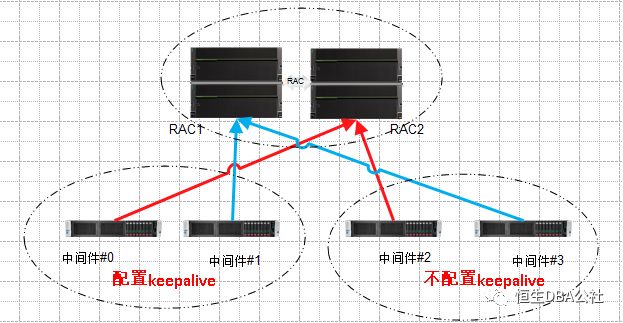
中间件#0,2连接节点1,中间件#1,3连接节点2
中间件#0,1配置了keepalive,中间件#2,3不配置keepalive
知识点:
keepalive参数设置(这里统一用缺省值,实际大小根据具体场景设置):
tcp_keepalive_intvl (integer; default: 75)
The number of seconds between TCP keep-alive probes
发送两个TCP keepalive探测数据包的间隔时间
tcp_keepalive_probes (integer; default: 9)
The maximum number of TCP keep-alive probes to send before giving up and killing the connection if no response is obtained from the other end.
发送TCP keepalive探测数据包的最大数量,如果发送9个keepalive探测包后对端仍然没有响应,就关掉这个连接
tcp_keepalive_time (integer; default: 7200)
The number of seconds a connection needs to be idle before TCP begins sending out keep-alive probes.
一个连接需要TCP开始发送keepalive探测数据包之前的空闲时间
上面的设置具体是什么意思?
TCP keepalive的超时设为7200秒,并有9次重发,每次间隔75秒。
因此,你的应用程序7425秒(7200 + 75 + 75 + 75)后检测到TCP断开
tcp重传参数设置:
tcp_retries2 (integer; default: 15)
The maximum number of times a TCP packet is retransmitted in established state before giving up.
Tcp连接成功以后,重传的报文发给对方,如果对方没有任何响应,最多重传15次,这个参数可以大大减少线程返回的时间
场景1:节点1实例宕掉
tcp连接:所有中间件跟节点1的tcp连接全部断开
查询:所有中间件查询正常返回
委托:因为中间件#1和中间件#3连接的是1节点,所以报错ORA-25408,说明这个时候已经发生切换了。其他中间件正常
小结:实例宕掉,应用是能够切换的,但预连接(被连接的对象)中断的话,应用本身是无法感知的,所以无法切换
场景2:节点1机器重启
tcp连接:中间件#0和中间件#1跟节点1的TCP连接全部断开(因为配置了keepalive机制,不需要业务来触发连接中断)
中间件#2跟节点1的TCP连接全部正常(因为中间件#2连接的是rac2,在rac1上没有业务)
中间件#3跟节点1只断开一个TCP连接(因为委托发到了节点1上,且没有配置keepalive,只能等新的业务触发才能断开连接)
查询:中间件#0、中间件#1和中间件#2正常返回
中间件#3没有返回,对应的proc线程(业务处理线程)卡住
委托:中间件#1和中间件#3报错ORA-25408,其他中间件正常
小结:委托返回时间约30s,没有keepalive机制是无法感知到的
场景3:拔掉节点1的心跳线
tcp连接:所有中间件跟节点2的TCP连接全部断开
查询:所有中间件正常返回
委托:中间件#0和中间件#2报错ORA-25408,其他中间件正常
小结:委托返回时间27秒
场景4:拔掉所有节点1的外网网线
tcp连接:中间件#0和中间件#1跟节点1的TCP连接全部断开(keepalive机制),中间件#2跟节点1的TCP连接全部正常,(因为中间件#2连的是节点2,在节点1上没有业务触发),中间件#3跟节点1只断开一个TCP连接(没有keepalive,通过下一笔应用来触发)
查询:中间件#0和中间件#1的查询,只返回了列信息,没有具体数据,中间件#2和中间件#3没有返回,对应的proc线程卡住
委托:中间件#0报错ORA-25408,其他中间件没有返回,对应的proc线程卡住
小结:委托返回时间6秒
场景5:同时拔节点1的心跳线和外网网线
tcp连接:中间件#0跟节点1的TCP连接全部断开,中间件#1跟节点1只剩1个TCP连接没断开(虽然配置了keepalive机制,但是委托请求已经发出去了,通信上已经有了这个操作,操作系统不会发心跳报文,但是对方ip又不通,导致线程被卡住,连接不会被中断),中间件#2和中间件#3跟节点1的TCP连接全部正常。
查询:中间件#0、中间件#1和中间件#2正常返回,中间件#3没有返回,对应的proc线程卡住
委托:中间件#1和中间件#3报错ORA-25408,其他中间件正常
小结:中间件#0委托的proc线程返回时间90s,中间件#1、中间件#2和中间件#3委托的proc线程返回时间是16分钟,(即tcp设置的超时重传的时间)
场景6:同时拔节点1的心跳线和外网网线(中间件#0和中间件#1配置net.ipv4.tcp_retries2 = 6)
tcp连接:中间件#0和中间件#1跟节点1的TCP连接全部断开
中间件#2和中间件#3和节点1的TCP连接全部正常。
查询:中间件#0和中间件#1的查询,只返回了列信息,没有具体数据,中间件#2和中间件#3没有返回,对应的proc线程卡住
委托:中间件#0报错ORA-25408,中间件#1报错ORA-03113,连接中断(加了retries参数后报的这个错),其他中间件没有返回,对应的proc线程卡住
注:
这里配置的这个参数可以大大减少proc线程返回的时间,6次就是30s
原理就是:Tcp连接成功以后,重传的报文发给对方,如果对方没有任何响应,最多重传的次数,如果达到重传的次数,还没有响应,就把应用断开,此时应用就能快速感知,否则操作系统就一直在重传。
小结:中间件#0委托的proc线程返回时间90s,中间件#1委托的proc线程返回时间是30s,中间件#2和中间件#3委托的proc线程返回时间是16分钟。
05
对此,我们能得到什么启发?
1. 一般情况下,中间件层面没有做特殊处理的话,中间件的切换建立在数据库切换的基础上,
2. 中间件所在的机器建议配置keepalive,否则发生rac切换时,正在等待数据库结果的连接无法正常完成切换
3. 中间件所在的机器建议配置net.ipv4.tcp_retries2,达到tcp最大重传次数后,就断开中间件, 减少proc线程返回的时间
不想走丢的话,请关注公众号 恒生DBA公社:hs_dba

