




 点亮 ⭐️ Star · 照亮开源之路
点亮 ⭐️ Star · 照亮开源之路
一、简介
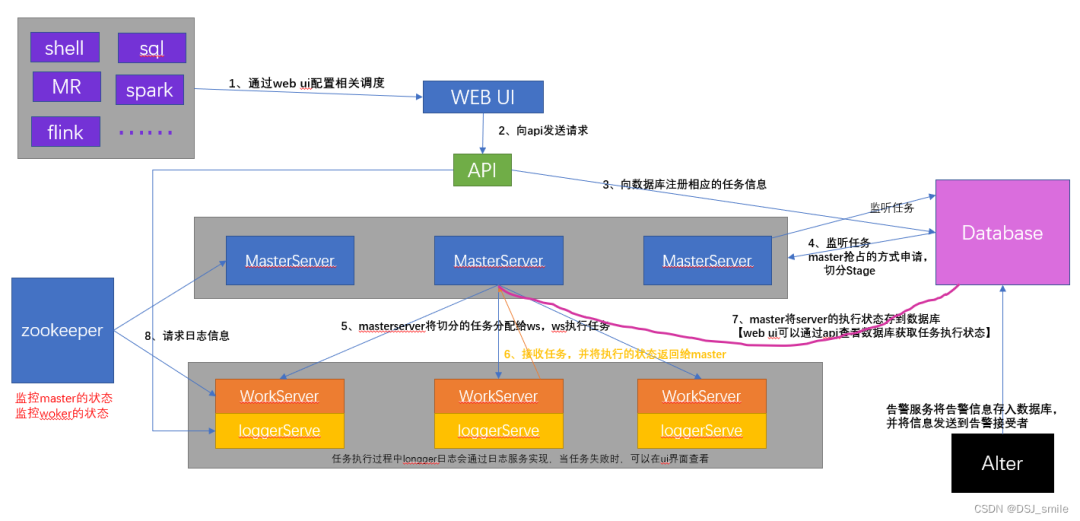
二、架构
【MasterServer】:采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态。
三、安装
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。
sudo yum install -y psmisc
tar -zxvf apache-dolphinscheduler-2.0.5-bin
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
--增加用户权限
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
flush privileges; --刷新生效
vim conf/config/install_config.conf
--需要修改的配置文件内容
ips="hadoop1,hadoop2,hadoop3"
# 将要部署任一 DolphinScheduler 服务的服务器主机名或 ip 列表
masters="hadoop1"
# master 所在主机名列表,必须是 ips 的子集
workers="hadoop1:default,hadoop2:default,hadoop3:default"
# worker主机名及队列,此处的 ip 必须在 ips 列表中
alertServer="hadoop1"
# 告警服务所在服务器主机名
apiServers="hadoop102"
# api服务所在服务器主机名
# pythonGatewayServers="ds1"
# 不需要的配置项,可以保留默认值,也可以用 # 注释
installPath="/opt/module/dolphinscheduler"
# DS 安装路径,如果不存在会创建
deployUser="kele"
# 部署用户,任务执行服务是以 sudo -u {linux-user} 切换不同 Linux 用户的方式来实现多租户运行作业,因此该用户必须有免密的 sudo 权限。
javaHome="/opt/module/jdk1.8.0_212"
# JAVA_HOME 路径
# 注意:数据库相关配置的 value 必须加引号,否则配置无法生效
DATABASE_TYPE="mysql" # 数据库类型
SPRING_DATASOURCE_URL="jdbc:mysql://hadoop1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
# 数据库 URL
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
# 数据库用户名
SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
# 数据库密码
registryPluginName="zookeeper"
# 注册中心插件名称,DS 通过注册中心来确保集群配置的一致性
registryServers="hadoop1:2181,hadoop2:2181,hadoop3:2181"
# 注册中心地址,即 Zookeeper 集群的地址
registryNamespace="dolphinscheduler"
# DS 在 Zookeeper 的结点名称
resourceStorageType="HDFS"
# 资源存储类型
resourceUploadPath="/dolphinscheduler"
# 资源上传路径
defaultFS="hdfs://hadoop1:8020"
# 默认文件系统
resourceManagerHttpAddressPort="8088"
# yarn RM http 访问端口
yarnHaIps=
# Yarn RM 高可用 ip,若未启用 RM 高可用,则将该值置空
singleYarnIp="hadoop2"
# Yarn RM 主机名,若启用了 HA 或未启用 RM,保留默认值
hdfsRootUser="kele"
# 拥有 HDFS 根目录操作权限的用户
cp /opt/software/mysql-connector-java-8.0.16.jar lib/
script/create-dolphinscheduler.sh
./install.sh
http://hadoop1:12345/dolphinscheduler
./bin/start-all.sh
./bin/stop-all.sh
./bin/dolphinscheduler-daemon.sh start master-server
./bin/dolphinscheduler-daemon.sh stop master-server
./bin/dolphinscheduler-daemon.sh start worker-server
./bin/dolphinscheduler-daemon.sh stop worker-server
./bin/dolphinscheduler-daemon.sh start api-server
./bin/dolphinscheduler-daemon.sh stop api-server
./bin/dolphinscheduler-daemon.sh start logger-server
./bin/dolphinscheduler-daemon.sh stop logger-server
./bin/dolphinscheduler-daemon.sh start alert-server
./bin/dolphinscheduler-daemon.sh stop alert-server
四、Quick Start
如果你对小海豚感兴趣,喜欢看视频的伙伴可以参考手把手教你如何《快速上手 Apache DolphinScheduler 教程》

管理员用户登录
地址:http://localhost:12345/dolphinscheduler/ui
用户名/密码:admin/dolphinscheduler123
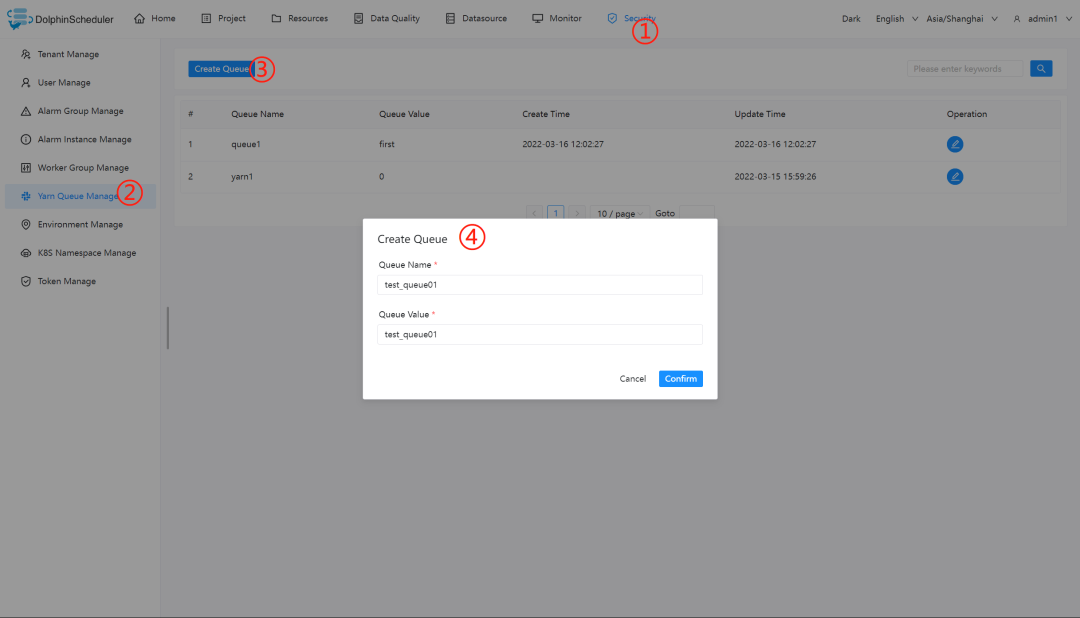
创建队列
创建租户
创建普通用户
创建告警组实例
创建告警组
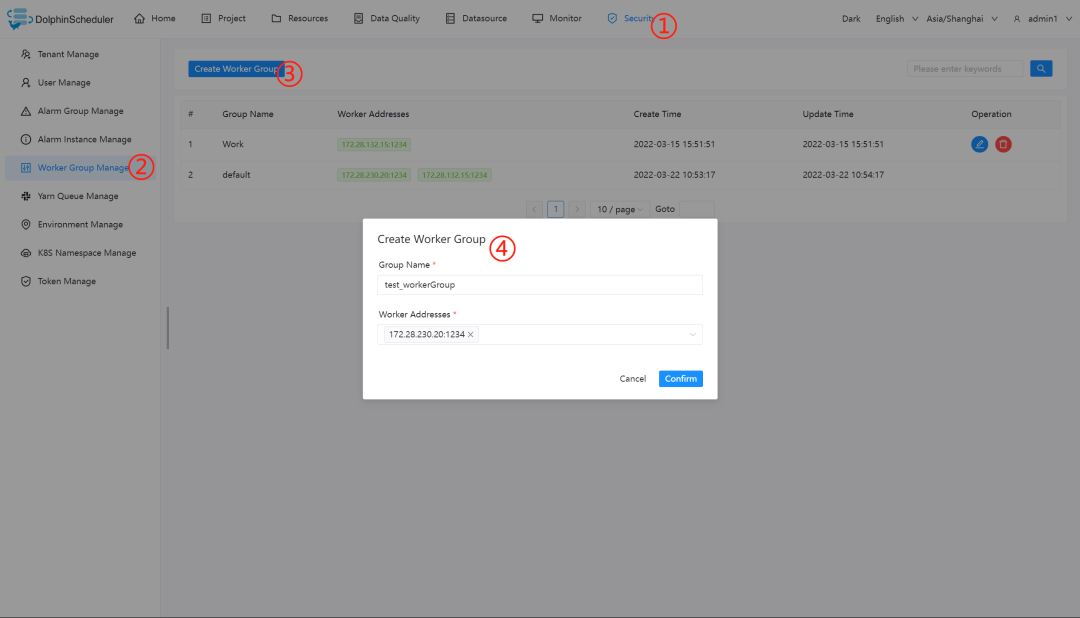
创建 Worker 分组
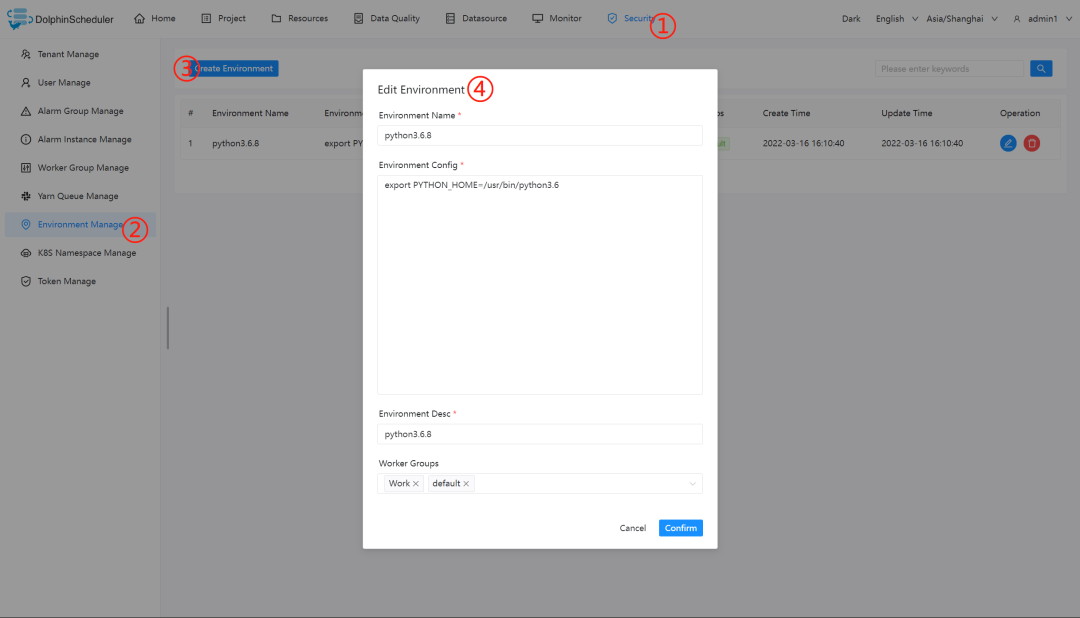
创建环境
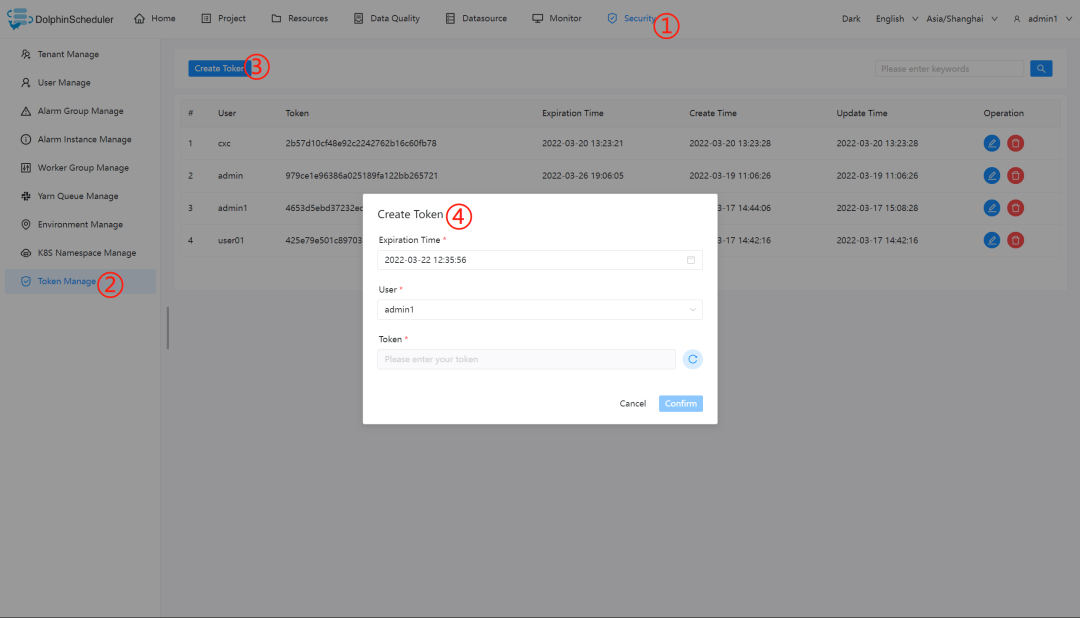
创建 Token 令牌
使用普通用户登录
点击右上角用户名“退出”,重新使用普通用户登录。
项目管理->创建项目->点击项目名称
点击工作流定义->创建工作流定义->上线工作流定义
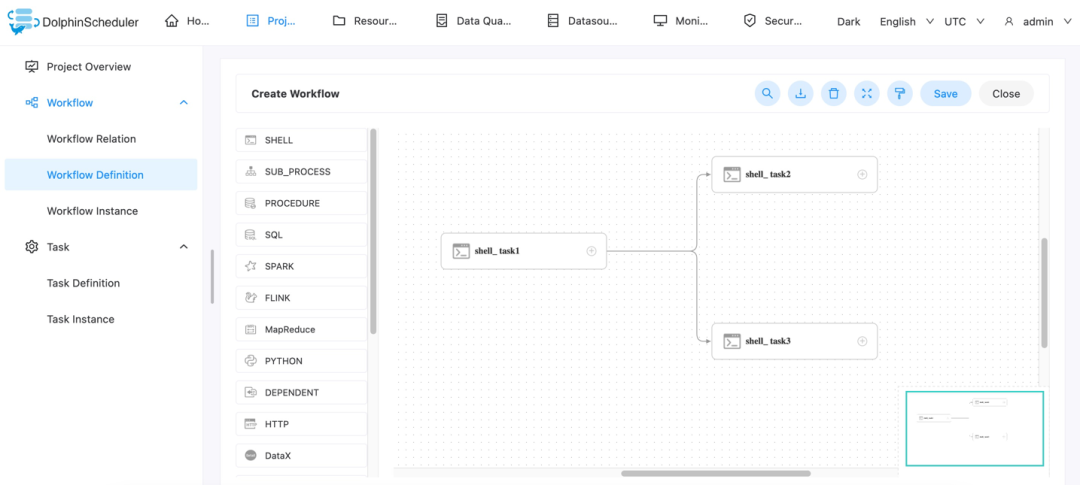
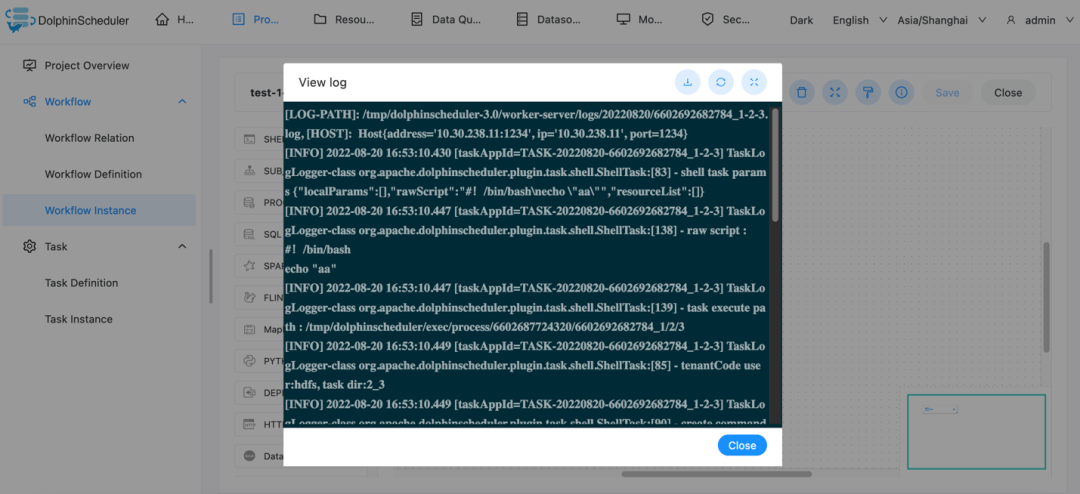
运行工作流定义->点击工作流实例->点击工作流实例名称->双击任务节点->查看任务执行日志
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。

☞Workflow as code+SageMaker, DolphinScheduler的机器学习选股系统新玩法
☞Apache DolphinScheduler 3.1.0 版本发布,覆盖机器学习工作流全流程!
☞突破单点瓶颈、挑战海量离线任务,Apache Dolphinscheduler在生鲜电商领域的落地实践
☞挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
☞收藏假期干货:Apache DolphinScheduler源码分析系列(超详细)
☞Apache Dolphin Scheduler 3.0.1 发布,对核心及UI相关进行优化
☞自动更新选股模型,实时监控,基于 Apache DolphinSchedule 打造机器学习智能选股系统
☞开源大数据 Studio 应用开发: Apache Dolphinscheduler + Notebook

