




“ Apache IoTDB 如何进行多条时序数据的分析处理?本文用UDF的方式进行示例说明。”

01
—
问题
本篇我们一起来看看Apache IoTDB如何解决要解决No8提到的网友问题,如下:

简单说就是如何处理两条时间线的数值计算?上面例子是一个 “+” 加法。
02
—
数据准备
要处理多条时序数据分析问题,我们首先先建立两条时间序列,我们做一下数据准备:
启动IoTDB服务实例
我们首先源码编译Master最新代码(),并启动服务实例。如下
iotdb git:(master) mvn clean install -DskipTests......[INFO] -------------------------------------------[INFO] BUILD SUCCESS[INFO] -------------------------------------------[INFO] Total time: 02:41 min[INFO] Finished at: 2021-04-07T07:13:32+08:00[INFO] -------------------------------------------➜ iotdb git:(master) cd distribution/target/apache-iotdb-0.12.0-SNAPSHOT-server-bin/apache-iotdb-0.12.0-SNAPSHOT-server-bin/➜ apache-iotdb-0.12.0-SNAPSHOT-server-bin git:(master) sbin/start-server.sh---------------------Starting IoTDB......2021-04-07 07:33:50,636 [main] INFO o.a.i.db.service.IoTDB:93 - IoTDB has started.
启动Cli
➜ iotdb git:(master) cd distribution/target/apache-iotdb-0.12.0-SNAPSHOT-server-bin/apache-iotdb-0.12.0-SNAPSHOT-server-bin/➜ apache-iotdb-0.12.0-SNAPSHOT-server-bin git:(master) sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
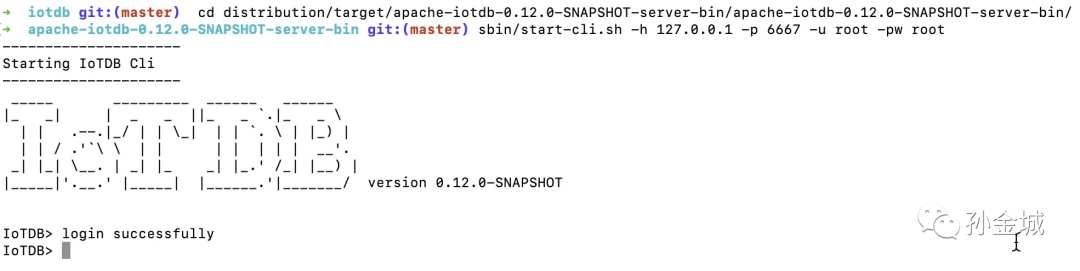
创建存储组
IoTDB> set storage group to root.lemming
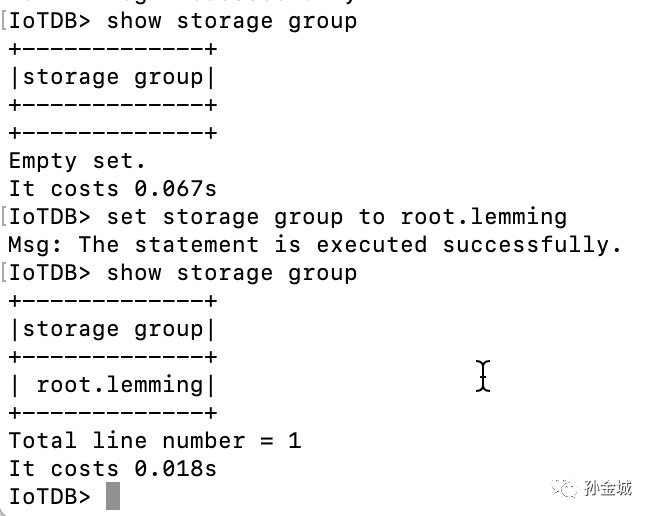
创建时间线
IoTDB> create timeseries root.lemming.device1.m1 with datatype=FLOAT,encoding=RLEIoTDB> create timeseries root.lemming.device1.m2 with datatype=FLOAT,encoding=RLE...IoTDB> show timeseries;
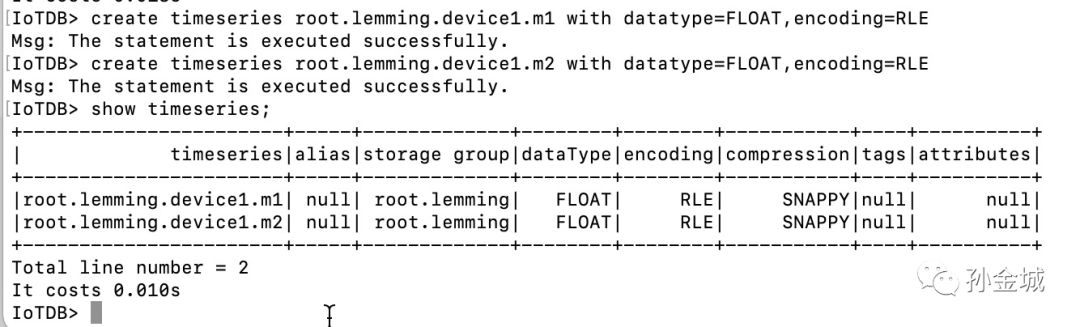
插入时间序列数据
IoTDB> insert into root.lemming.device1(timestamp,m1, m2) values(1,3333,4444)IoTDB> select * from root.lemming.device1;
看到这里,不知道大家是否发现,IoTDB虽然在存储层面是按时间序列进行列存储的,但是在API层面已经为大家抽象好来二维表结构,大家可以把多个时间序列当成一张二维度表的不同列,这个抽象大家就免去来入在InfluxDB中利用PIVOT进行行转列的需求,这样就更方便理解和对多时序数据的进行查询分析。好,那么下面我们看看如果实现 m1 + m2 这个需求。
03
—
代码数据准备
我们一个一个敲命令不如咱直接写个Java代码实例,方便反复测试,测试本篇内容,我们只需要依赖iotdb-jdbc模块,pom如下:
<dependencies><dependency><groupId>org.apache.iotdb</groupId><artifactId>iotdb-jdbc</artifactId><version>${iotdb.version}</version></dependency></dependencies>
创建存储组,时间序列和准备数据的测试代码如下:
public class No9JDBCExample {/*** 第一次运行 init(),如果一切顺利,正面环境和数据准备完成*/public static void main(String[] args) throws Exception {Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");try (Connection connection =DriverManager.getConnection("jdbc:iotdb://127.0.0.1:6667/", "root", "root");Statement statement = connection.createStatement()) {init(statement);} catch (IoTDBSQLException e) {e.printStackTrace();}}public static void init(Statement statement) throws Exception {setStorageGroup(statement);statement.execute("CREATE TIMESERIES root.lemming.device1.m1 with datatype=FLOAT,encoding=RLE");statement.execute("CREATE TIMESERIES root.lemming.device1.m2 with datatype=FLOAT,encoding=RLE");statement.execute("INSERT INTO root.lemming.device1(timestamp,m1, m2) VALUES (1,3333,4444)");ResultSet resultSet = statement.executeQuery("SELECT timestamp, m1 as m1, m2 as m2 FROM root.lemming.device1");outputResult(resultSet);}public static void setStorageGroup(Statement statement) throws Exception{try {statement.execute("SET STORAGE GROUP TO root.lemming");}catch (Exception e){statement.execute("DELETE STORAGE GROUP root.lemming");statement.execute("SET STORAGE GROUP TO root.lemming");}}private static void outputResult(ResultSet resultSet) throws SQLException {if (resultSet != null) {System.out.println("--------------------------");final ResultSetMetaData metaData = resultSet.getMetaData();final int columnCount = metaData.getColumnCount();for (int i = 0; i < columnCount; i++) {System.out.print(metaData.getColumnLabel(i + 1) + " ");}System.out.println();while (resultSet.next()) {for (int i = 1; ; i++) {System.out.print(resultSet.getString(i));if (i < columnCount) {System.out.print(", ");} else {System.out.println();break;}}}System.out.println("--------------------------\n");}}}
如果你运行得到如下结果,正面一切准备工作就绪:
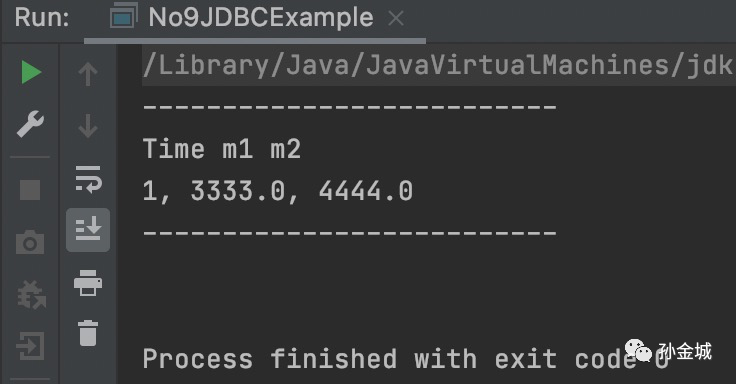
04
—
UDF解决加法
我们接下来看看Apache IoTDB如何解决加法问题,目前IoTDB提供来自定义UDF的方式解决用户自定义的操作。如果要使用UDF我们需要增加依赖如下:
<dependency><groupId>org.apache.iotdb</groupId><artifactId>iotdb-server</artifactId><version>0.12.0-SNAPSHOT</version><scope>provided</scope></dependency>
完整配置查阅:https://github.com/sunjincheng121/know_how_know_why/blob/master/khkw_iotdb/No9udf/pom.xml
添加依赖之后,我们可以实现如下UDTF(User Defined Timeseries Generating Function), 这里写一下全称,不然大家会以为是User defined Table Function。当然不可否则,UDF的接口我们还可以有改进的空间,我们就目前现状与大家简单说明,如下:
public interface UDTF extends UDF {/*** This method is mainly used to customize UDTF. In this method, the user can do the following* things:** <ul>* <li>Use UDFParameters to get the time series paths and parse key-value pair attributes* entered by the user.* <li>Set the strategy to access the original data and set the output data type in* UDTFConfigurations.* <li>Create resources, such as establishing external connections, opening files, etc.* </ul>** <p>This method is called after the UDTF is instantiated and before the beginning of the* transformation process.** @param parameters used to parse the input parameters entered by the user* @param configurations used to set the required properties in the UDTF* @throws Exception the user can throw errors if necessary*/@SuppressWarnings("squid:S112")void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception;/*** When the user specifies {@link RowByRowAccessStrategy} to access the original data in {@link* UDTFConfigurations}, this method will be called to process the transformation. In a single UDF* query, this method may be called multiple times.** @param row original input data row (aligned by time)* @param collector used to collect output data points* @throws Exception the user can throw errors if necessary* @see RowByRowAccessStrategy*/@SuppressWarnings("squid:S112")default void transform(Row row, PointCollector collector) throws Exception {}/*** When the user specifies {@link SlidingSizeWindowAccessStrategy} or {@link* SlidingTimeWindowAccessStrategy} to access the original data in {@link UDTFConfigurations},* this method will be called to process the transformation. In a single UDF query, this method* may be called multiple times.** @param rowWindow original input data window (rows inside the window are aligned by time)* @param collector used to collect output data points* @throws Exception the user can throw errors if necessary* @see SlidingSizeWindowAccessStrategy* @see SlidingTimeWindowAccessStrategy*/@SuppressWarnings("squid:S112")default void transform(RowWindow rowWindow, PointCollector collector) throws Exception {}/*** This method will be called once after all {@link UDTF#transform(Row, PointCollector) calls or* {@link UDTF#transform(RowWindow, PointCollector) calls have been executed. In a single UDF* query, this method will and will only be called once.** @param collector used to collect output data points* @throws Exception the user can throw errors if necessary*/@SuppressWarnings("squid:S112")default void terminate(PointCollector collector) throws Exception {}}
其中最核心的是transform方法,对transform的实现逻辑就是我们业务的需求逻辑,面对我们要实现 加法 的逻辑,我们的核心逻辑就是transform实现,如下:
public class AddFunc implements UDTF {......@Overridepublic void transform(Row row, PointCollector collector) throws Exception {if (row.isNull(0) || row.isNull(1)) {return;}collector.putLong(row.getTime(), (long) (extractDoubleValue(row, 0) + extractDoubleValue(row, 1) + addend));}private double extractDoubleValue(Row row, int index) {double value;switch (row.getDataType(index)) {case INT32:value = row.getInt(index);break;case INT64:value = (double) row.getLong(index);break;case FLOAT:value = row.getFloat(index);break;case DOUBLE:value = row.getDouble(index);break;default:throw new UnSupportedDataTypeException(row.getDataType(index).toString());}return value;}}
完整代码查阅:https://github.com/sunjincheng121/know_how_know_why/blob/master/khkw_iotdb/No9udf/src/main/java/org/khkw/iotdb/no9/AddFunc.java
当然开发完UDF,你还需要编写查询逻辑,如下:
public static void udf(Statement statement) {try{statement.execute("CREATE FUNCTION plus AS \"org.khkw.iotdb.no9.AddFunc\"");statement.execute("SHOW FUNCTIONS");ResultSet resultSet = statement.executeQuery("SELECT timestamp, plus(m1, m2) FROM root.lemming.device1");outputResult(resultSet);}catch (Exception e) {e.printStackTrace();}}
如上代码我们注册了名为 plus的UDF,然后plus(m1, m2)的方式实现了加法需求。当然,我们还不能直接运行udf方法,直接运行会报出找不到rg.khkw.iotdb.no9.AddFunc类,如下:

这是因为IoTDB配置udf的JAR加载需要指定JAR所在目录,我们利用 mvn clean package 生成JAR,然后再修改一下iotdb-engine.properties配置文件,如下:

我配置成为自己项目的jar所在路径了,如下:

配置完成之后,重新启动IoTDB服务实例。启动日志你会发现对UDF的加载:
➜ apache-iotdb-0.12.0-SNAPSHOT-server-bin git:(master) sbin/start-server.sh。。。。。。2021-04-07 08:17:53,398 [main] INFO o.a.i.d.q.u.s.UDFClassLoaderManager:56 - UDF lib root: /Users/jincheng/work/know_how_know_why/khkw_iotdb/No9udf/target。。。2021-04-07 12:34:11,622 [main] INFO o.a.i.d.s.t.ThriftService:125 - IoTDB: start RPC ServerService successfully, listening on ip 0.0.0.0 port 6667

确保我们自定义的UDF已经被加载之后,我们运行udf,如下:
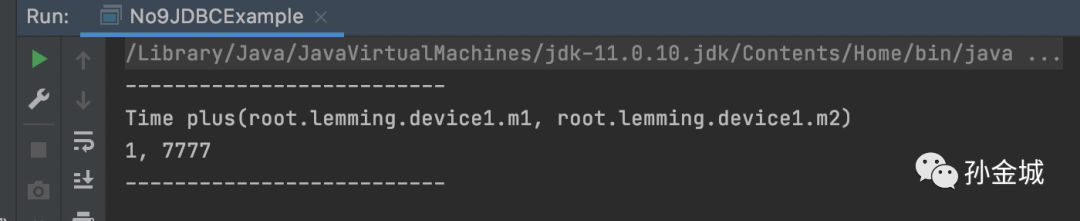
好,到目前我们利用UDF解决了加法需求,那么UDF是否可以在CLI里面使用呢?
05
—
CLI使用UDF
当然,我们可以在CLI里面使用UDF,我们启动一个CLI客户端,并用命令 SHOW FUNCTIONS 显示已有的FUNCTIONS,如下:

发现我们自定义的UDF已经在刚才运行Java程序时候注册了,我们可以删除让后在CLI在操作一遍(演示作用),如下:
IoTDB> CREATE FUNCTION plus AS "org.khkw.iotdb.no9.AddFunc"Msg: 411: Failed to register non-TEMPORARY UDF PLUS(org.khkw.iotdb.no9.AddFunc), because a non-TEMPORARY UDF PLUS(org.khkw.iotdb.no9.AddFunc) with the same function name and the class name has already been registered.IoTDB> DROP FUNCTION plusMsg: The statement is executed successfully.IoTDB> CREATE FUNCTION plus AS "org.khkw.iotdb.no9.AddFunc"Msg: The statement is executed successfully.IoTDB> SELECT timestamp, plus(m1, m2) FROM root.lemming.device1;+-----------------------------+------------------------------------------------------+| Time|plus(root.lemming.device1.m1, root.lemming.device1.m2)|+-----------------------------+------------------------------------------------------+|1970-01-01T08:00:00.001+08:00| 7777|+-----------------------------+------------------------------------------------------+Total line number = 1It costs 0.552s

OK,到这里不论是Java方式还是CLI方式我们都完成了 多时序数据联合分析的需求。
06
—
贡献社区
上面我们发现IoTDB利用UDF的方式解决加法问题,虽然是通用做法,但是我们还可以做的更好,比如直接支持 m1 + m2 这种(加/减/乘/除)的便捷运算,所以这是你贡献的好机会,社区JIRA等你take :)

https://issues.apache.org/jira/browse/IOTDB-1285
阿里招聘
时序数据库开发岗位
(P7/P8/P9)
(长期有效)

职位描述:
1. 精通Java/Scala编程
2. 精通常用数据结构和算法应用,具备良好的、精益求精的设计思维,每一个bit都是客户/技术价值。
3. 了解Hadoop/Flink/Spark等计算框架和熟悉HBase/LevelDB/RocksDB等主流NoSQL数据库,深入理解其实现原理和架构优势劣势;
4. 具备分布式系统的设计和应用的经历,能对分布式常用技术进行应用和改进者优先;
5. 有开源社区贡献,并成为Flink/Spark/Druid/OpenTSDB/InfluxDB/IoTDB等社区的Committer/PMC者优先;
6. 要具备良好的团队协作能力,良好的沟通表达能力,和对正确事情持之以恒的韧性和耐力。
来!让我看到你的简历,因为成就你的不仅仅是能力,更是雷厉风行的执行力!
