




“ 管理者不承担创造知识的任务,他的任务是有效地运用知识。——卡斯特”
在很久以前的上一篇文章中,我们简述了什么是知识图谱。那么,今天我们将延续前述内容,进一步讲解如何对知识图谱进行存储。
01
—
知识存储和管理——知识图谱的第一步
或许你会感到疑惑,在大多数教材和文章中,学习知识图谱的第一步大多是“构建”(我们有一堆文本,希望从文本(主要是文本,当然也可以有其他形式的数据)中抽取出有价值的实体、关系、属性等,这就是知识图谱的构建)。
但是,按照难易顺序来说,知识的存储和管理比较“新手友好”。并且,现实世界以及实际项目操作过程中,有太多的结构化数据,也就是已经被处理好的数据。比如中文通用百科知识图谱CN-DBpedia(http://kw.fudan.edu.cn/cndbpedia/search/#)包含了大量已经抽取好的实体、关系等,是可以拿过来用的。因此,先学习如何对知识进行存储,无疑有助于快速入门。
02
—
文本文档——简单有效
自盘古开天辟地以来,文本文档就已被广泛使用。——鲁迅
尽管存储知识图谱的方式多种多样,包括:关系数据库、图数据库等等,但是,最简单直接的还是文本文档,也就是我们俗称的txt文件。
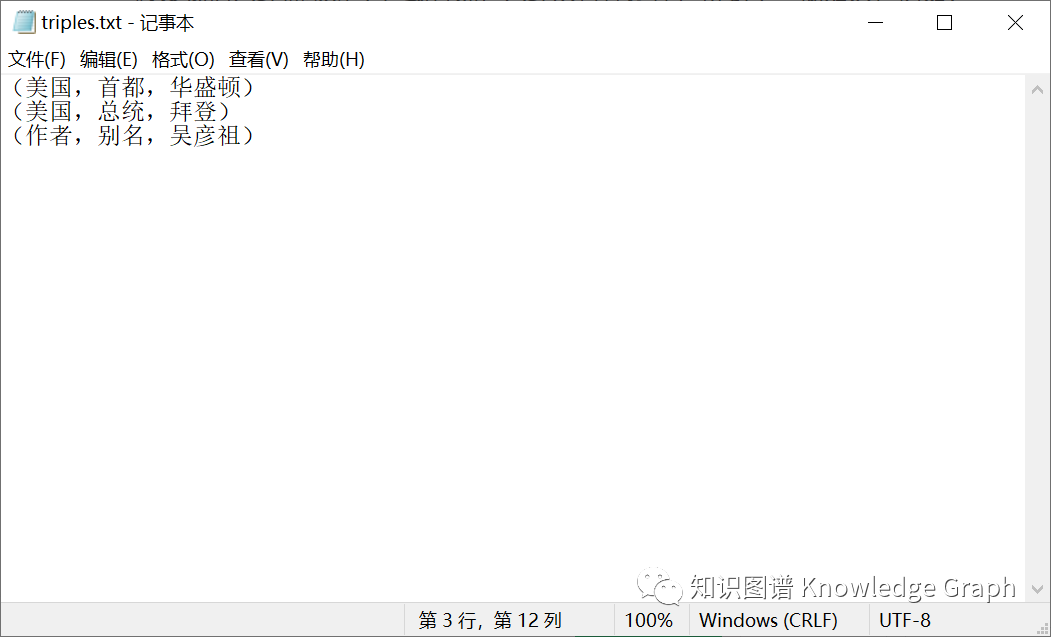
假设我们已经抽取好了,或者说,已经从各种途径,得到了一批知识,例如:(美国,首都,华盛顿)、(美国,总统,拜登)。我们以这两条知识为例,来讲解如何用文本文档进行存储。
首先,需要知道的是,一条知识“(美国,首都,华盛顿)”被称为一个“三元组”(这是一个专有名词,英文叫做triple),『美国』被称作“头实体”,『华盛顿』被称作“尾实体”,『首都』被称作“关系”。
【tips:有的论文中也把头实体称作“主语”,把尾实体称作“宾语”,把关系称作“谓词”。】
如果我们想把这两个三元组存储到文本文档中,最直接的想法就是,新建一个文本文档,一行存储一条知识:
完结。
不,还没结束。
当我们想继续存储(美国,首任总统,华盛顿)这条知识的时候,会出现指称歧义(一词多义)的问题。也就是说,华盛顿到底是一个城市,还是一个人?或者,还会出现指代不明(一义多词)的问题,比如“美国”和“美利坚合众国”都指美国。
所以,我们仅仅用词语来指代某个实体,一般是不准确的。并且,当知识的数量太多,词语所占据的存储空间太多。那么应该怎么做呢?
一般,会再新建两个文本文档:


也就是说,我们为每个实体和关系,都分配了一个独一无二的编号。自然而然,存储三元组的文档,其内容就变成了:

这样,之前我们所遇到的一词多义、一义多词、存储空间过大的问题,就得到了缓解。事实上,现如今很多论文所公开的源码,他们就是这样存储知识的。
文本文档的优点显而易见,既容易操作,也不会遇到软件的版本问题,也不需要学习复杂的软件操作技术。因此,建议在『科研』过程中,可以尝试以文本文档来进行存储。
既然用文本文档存储知识如此方便快捷,而科研之外却少见呢?
设想一下,一开始我们收集到的知识比较少,文本文档足以应付。但当知识的数量越来越多,triples.txt(也就是存储三元组的文件)越来越臃肿。如果想要检索其中的某条知识,需要把整个文档从硬盘中读取出来放到内存中,再自行撰写查询的代码,其效率十分低下。可见,当知识数量达到一定规模,文本文档已经难以满足需求。
这个时候,我们自然而然会想到:能不能用大学期间学到的SQL Server或MySQL来对知识进行存储和管理呢?可以!
03
—
关系数据库——成熟可靠
我大学的时候也曾选修过SQL Server。——鲁迅
这里我假设读者至少听说过“关系数据库”,如果真的不清楚什么是关系数据库,可以简单理解,就是用来存储数据的软件工具。软件里面用来存储数据的一张张“表格”有点类似于一个又一个的“Excel”文件。但是,不同于“Excel”表格,关系数据库有成熟的存储体系,自带比较高效率的增、删、改、查等操作。
【我的电脑没有安装SQL Server等关系数据库,写这篇文章的时候也实在懒得去安装,所以关系数据库到底长什么样子,不清楚的读者还请自行查询相关资料。】
在“图数据库”尚未普及前,用关系数据库来存储和管理知识是很常见的。
还是以前面我们讲解“文本文档”时,所提及的几条三元组为例:(美国,首都,华盛顿(地名))、(美国,总统,拜登)、(美国,首任总统,华盛顿(人名))。脑海中蹦出的第一个想法,就是完全可以借鉴文本文档存储的思路,在关系数据库中新建一张表格,表格中的每一行都是一条知识:
| 头实体 | 关系 | 尾实体 |
| 美国 | 首都 | 华盛顿(地名) |
| 美国 | 总统 | 拜登 |
| 美国 | 首任总统 | 华盛顿(人名) |
| ... | ... | ... |
| 华盛顿(人名) | 出生日期 | 1732年 |
| 华盛顿(人名) | 逝世日期 | 1799年 |
| 海顿 | 出生日期 | 1732年 |
| 海顿 | 逝世日期 | 1809年 |
这样,一条条的三元组就被存储到关系数据库中了。实在是简单快捷。
假设我们又收集到了几条知识,即(华盛顿(人名),出生日期,1732年)、(华盛顿(人名),逝世日期,1799年)、(海顿,出生日期,1732年)、(海顿,逝世日期,1809年)。
下面,我们想要检索“谁”的“出生日期”是1732年,并且逝世日期是1799年,应该怎么检索呢?用SQL查询来描述就是:
SELECT t1.头实体FROM 表名 AS t1, 表名 AS t2WHEREt1.头实体 = t2.头实体AND t1.关系='出生日期' AND t1.尾实体='1732年'AND t2.关系='逝世日期' AND t2.尾实体='1799年'
如果查询语句没写错的话,上述SQL查询会告诉我们,出生日期为1732年并且逝世日期为1799年的人是华盛顿。
可以发现,想要进行一些稍微复杂的查询操作,需要进行“自连接”操作(自连接用大白话来描述就是说,同一张表在一条查询语句中被检索了很多遍)。当这张表存储的三元组越来越多,或进行更多跳的查询时,其性能会十分低下。可见,这种存储形式虽然简单,却并非最佳选择。
那么,有没有其他方案呢?有!上面的这种存储形式,一般被称作“三元组表”。下面,我们介绍一个更帅的形式:“水平表”。不要被名字吓到或迷惑,直接来看存储方式:
| 头实体 | 首都 | 总统 | 首任总统 | 出生日期 | 逝世日期 |
| 美国 | 华盛顿(地名) | 拜登 | 华盛顿(人名) | ||
| 华盛顿(人名) | 1732年 | 1799年 | |||
| 海顿 | 1732年 | 1809年 |
可以发现,表头变成了“关系”。每一行的第一个“格子”,存储的是“头实体”,后面跟着和头实体具有某个关系的“尾实体”。这样的话,有多少“关系”,这张表就有多少列。同样,有多少“头实体”,这张表就有多少行。
如果想要在这张表里,查询“谁”的“出生日期”是1732年,并且逝世日期是1799年,应该怎么做呢?用SQL查询来描述就是:
SELECT 头实体FROM 表名WHERE 出生日期='1732年'AND 逝世日期='1799年'
可以发现,这条查询不需要“自连接”,其查询效率可以得到一定程度的提升。
不过,这种存储方式的缺点也非常明显,一是看起来不够直观;二是表格中会存在大量空白,毕竟“美国”没有“出生日期”和“逝世日期”;三是表的列数取决于“关系”的数量,当出现新的“关系”时,需要更改表的结构,当“关系”的种类过多时,可能会超出数据库所允许的上限。此外,还有其他缺点,不再罗列和赘述。
那么,有没有更好的用关系数据库存储知识的方案呢?有,比如“属性表”、“垂直划分”、“六重索引”等等。这些存储方式都存在或多或少的问题,但在数据量不大,增删改查等操作不太复杂时,也不失为优秀的方案。毕竟关系数据库已经发展了几十年,无论是操作便捷度还是查询效率,都具有相当的优势。
相较于“文本文档”式的存储方式,“关系数据库”在查询时,无需将整张表读取到内存中,并且拥有成熟的查询语句。但是,文本文档简单易用,在知识库构建初期不失为一种好的存储手段。具体采用哪种存储方式,需要结合现实场景进行选择。
当知识的数量不多时,关系数据库在存储知识时还算是游刃有余。然而,随着知识被收集得越来越多,查询效率会变得低下。为了提升查询效率,又需要设计相当复杂的表结构。因此,关系数据库在应付海量知识存储时,开始变得难堪大用。
有没有专门的工具,用来存储和管理知识,并且查询效率不会受到知识数量的影响呢?有!那就是『图数据库』!

04
—
图数据库——术业专攻
我的服务器里有两个图数据库,一个是Neo4j,另一个也是Neo4j。——鲁迅
不同于关系数据库,图数据库是一种“非关系型数据库”(NoSQL)。非关系型数据库普遍普遍具有非常高的读写性能,尤其在大数据量下,同样表现优秀。没错,图数据库也同样具有这些优点。
图数据库是专门被设计用来存储和管理“图”的。上一篇文章中,我们提到过,知识图谱本身就是“图”,社交网络也是“图”,只要是“图”结构,都可以选择用图数据库来存储和管理。
常见的图数据库包括:Neo4j、OrientDB、HugeGraph等等。这里我们仅介绍Neo4j。为什么只介绍它?一方面,Neo4j是当前最流行的图数据库,另一方面,其他图数据库我也不会用(TnT)。
具体的安装方式,网上教程很多,这里不花费篇幅讲解。安装以后的管理界面大概是这样的:
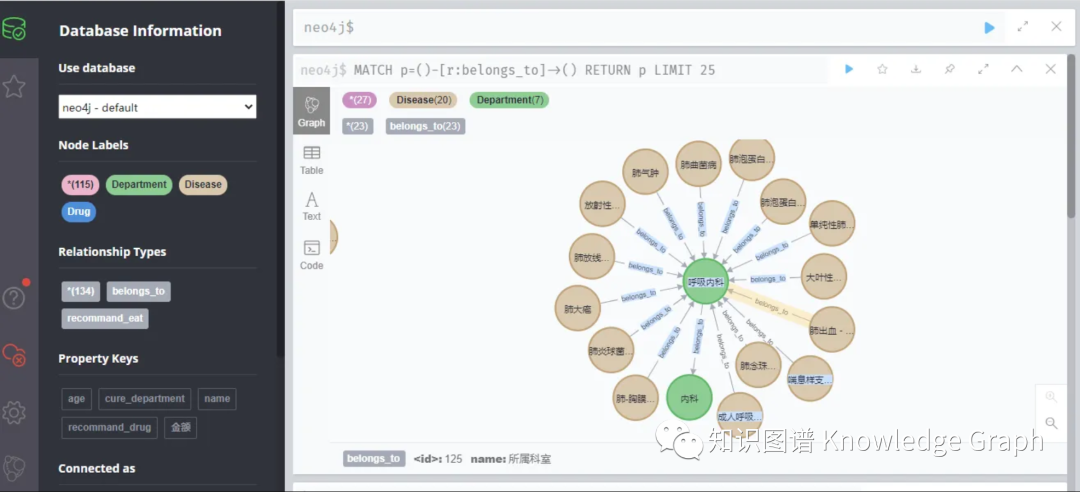
可以看出来,Neo4j对于知识的展示方式十分直观。类似于SQL Server等关系数据库,Neo4j也有其专用的操作语言“Cypher”,需要花费一定时间专门去学习。但值得开心的是:

Python中有专门用于操作Neo4j的工具包:py2neo。安装起来也很简单:
pip install py2neo
那么,在Python中,如何进行知识的存储和管理呢?假设读者已经根据网上的教程,安装完毕Neo4j。接下来,可以借助Python进行知识的存储和管理:
from py2neo import Graph, Node, Relationship # 导入必要的工具包graph = Graph( # 连接到Neo4j图数据库"http://localhost:7474", # 地址,默认的端口号一般是7474username="neo4j", # 用户名,默认的用户名和密码是neo4j,也可以自行修改password="neo4j" # 密码,记得修改成自己的用户名和密码)
此时,我们已经创建好了指向Neo4j数据库的一条连接,下面,我们想要存储两个三元组(美国,首都,华盛顿)、(美国,总统,拜登),我们可以采用如下代码:
# 首先创建三个实体,实体在“图”中,是以“节点”的形式呈现,因此用Nodenode_1 = Node(label = "国家", name = "美国") # 创建一个节点,也就是一个“实体”,节点的类型是国家,节点的名字是美国node_2 = Node(label = "城市", name = "华盛顿")node_3 = Node(label = "人名", name = "拜登")# 这个时候,我们只是在python中创建了三个实体,neo4j此时还没有获得这三个实体的信息,所以需要用create真正存储到neo4j中graph.create(node_1) # 把上面创建的三个实体,存储到neo4j中graph.create(node_2)graph.create(node_3)# 接下来,创建实体之间的关系node_1_2_node_2 = Relationship(node_1, '首都', node_2) # 美国 指向 华盛顿 的关系是 首都node_1_2_node_3 = Relationship(node_1, '总统', node_3) # 美国 指向 拜登 的关系是 总统test_graph.create(node_1_2_node_2) # 存储到neo4j中test_graph.create(node_1_2_node_3)
当然,py2neo也可以直接执行Cypher操作语言,读者可以寻找相关材料进行学习。Neo4j具体的底层存储结构暂时不需要深入了解,对于初学者来说,只需要学会使用即可。
那么,Neo4j有没有缺点呢?有。Neo4j无法做到真正意义上的分布式,也就是说,一般情况下,我们没有办法把文件分放在多个存储服务器。因此,当知识的规模十分庞大时,Neo4j的性能也难以满足需求。但是瑕不掩瑜,对于大多数企业来说,需要存储和管理的知识的数量往往小于数十亿的规模,所以Neo4j仍然是优秀选择。
