排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
从架构上看OB与TIDB擅长的业务领域
从架构上看OB与TIDB擅长的业务领域
杨建荣的学习笔记
2022-11-22
715
这两年分布式数据库比较火,金融行业客户上数据库产品的时候,大多数都选择了分布式数据库。实际上并不是说集中式数据库不能承担金融的核心业务,因为对于大多数银行业务来说,目前的集中式数据库完全是能够承担其负载的,实际上邮储银行等银行业选择了openGauss作为核心系统的数据库。很多银行选择分布式数据库,最主要的还是考虑了高可用的问题。因此目前很多国产集中式数据库也在准备推出类似ORACLE RAC的组件,从而补上集中式数据库在关键业务运行环境中的一个短板。
实际上集中式数据库与分布式数据库在不同场景上是各有胜场的。在我们以前进行的一项测试中,对于一些核心业务表,如果设计了多个二级索引。对于集中式数据库,二级索引对于数据并发写入和修改的影响并不大,而对于分布式数据库,影响就很大了。这主要是因为分布式数据库的全局索引维护成本因为多节点与网络延时的存在而被放大了。因此一些交易在分布式数据库上的延时要略高于在集中式数据库上。分布式数据库因为可以横向扩展,能够承受更高并发的交易量,并不能降低单个交易的延时。今年年初的时候,有一家商业银行曾经和我讨论过,他们想拆掉RAC,改为HA架构,从而降低核心交易延时中GES/GCS带来的负面影响。和分布式数据库一样,RAC可以提高总的交易并发量,而当系统没有瓶颈的时候,并不能提高单个交易的性能。
对于分布式数据库也是如此,不同架构的优缺点十分明显,某些分布式数据库存在某方面的缺陷是因为架构问题,是较难解决的,因此了解某个分布式数据库属于哪种架构,有哪些优点和缺点十分重要。让你的应用特点与分布式数据库架构的优点相吻合,才是你的最佳选择。今天我们用当前最热门的国产分布式数据库TiDB和OceanBase来做一个分析,因为这两种代码自主率都比较高的分布式关系型数据库正好分别采用了两种不同的架构。
分布式数据计算最主要有两种形式,一种是分区SHARDING,一种是全局一致性HASH,根据这种分布式数据计算的种类不同,衍生出存算分离和存算一体这两种分布式数据库架构。进一步再分出一系列子类别,比如对等模式,代理模式,外挂模式等。
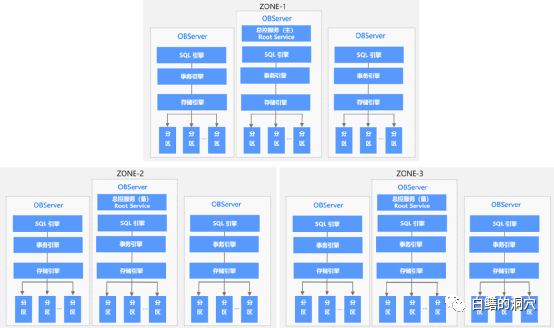
存算一体SHARDING模式的分布式数据库最为典型的是Oceanbase。下面是OB的架构图:
每个Observer是一个计算存储一体化的独立服务,带有SQL引擎,事务引擎和存储引擎,并存储一部分分片数据(分区)。OB采用的是对等模式,客户端连接到任何一个OBSERVER都可以全功能使用数据库。OBSERVER会自动产生分布式执行计划,并将算子分发到其他参与协同计算的OBSERVER上,完成分布式计算。管理整个集群的RootService只在部分Observer中存在,并全局只有一个是主的,其他都是备的。实际上每个OBSERVER就组成了一个完整的数据库子集,如果所有的数据都存储于一个OBSERVER上,我们的访问方式类似于一个集中式数据库。
这种架构下的数据分区采用了高可用,一个数据写入主副本(Leader)后会自动同步到N个备副本,OB采用Paxos分区选举算法来实现高可用。其备副本可以用于只读或者弱一致性读(当副本数据存在延迟时),从而更为充分的利用多副本的资源。实际上不同的分布数据库的主备副本的使用方式存在较大的差异,有些分布式数据库的备副本平时是不能提供读写的,只能用于高可用。
大家看到这里,可能觉得OB的架构不错,各种问题都考虑的比较周到了。不过还是那句话,没有完美的分布式数据库架构,SHARDING存储需要分布在各个SHARDING分区中的分区表要有一个SHARDING KEY,根据SHARDING KEY来做分片处理。SHARDING模式虽然应对一般的数据库操作是没问题了,不过如果一条复杂的查询语句中没有关于SHARDING KEY的过滤条件,那么就没办法根据SHARDING KEY去做分区裁剪,必须把这个算子分发到集群中存储这张表的分区的所有OBSERVER上,这种情况被称为SHARDING数据库的读放大。
另外一方面,在OB数据库中创建一张表的时候需要考虑采用哪种模式,是创建为分区表还是普通的表,如果创建表的时候不指定是分区表,那么这张表只会被创建在一个OBSERVER中,无法在集群内多节点横向扩展。另外如果有多张表要进行JOIN,如果要JOIN的数据分别属于不同的OBSERVER管理,那么这种JOIN是跨网络的,其性能也会受到一定的影响。为了解决这个问题,OB提供了TABLE GROUP的功能,可以让分区属性类似的分区表或者经常JOIN的单表的数据存放在相同的OBSERVER中,从而避免上面所说的多表JOIN的性能问题。这种模式对于数据库用户来说似乎变得麻烦了,不过就像开车一样,如果要能够发挥出车辆的最大性能,手动模式可能是最好的。
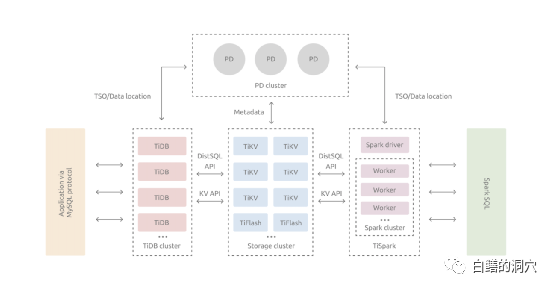
既然存算一体的SHARDING模式有这种缺陷,那么能不能采用存算分离的方案呢?大家来看TIDB的架构:
TIDB是采用完全的存算分离的,计算引擎TIDB和存储引擎TIKV是分离的,因此TIDB不存在存算一体的SHARDING分布式数据库的这种读放大的问题。似乎TIDB要技高一筹,完美的解决了OB等SHARDING数据库的问题,不过事实上没有那么简单。
首先是那就是计算节点的本地缓冲问题。因为大型分布式计算环境下实施缓冲区融合成本极高,因此每个TIDB节点只能有本地缓冲,不能有全局缓冲。因此在TIDB的SQL引擎上是没有全局DB CACHE的,TIDB的数据缓冲只能建立在TIKV和TIFLASH上。SQL引擎->DB CACHE->存储路径->数据存储介质这种传统数据库的数据读取模式变成了SQL引擎->本地局部缓冲->存储路径(网络)->存储节点缓冲->存储介质这种模式。这种模式对于一些小型的需要超低延时的OLTP业务并不友好。为了解决这个问题,采用此类架构的数据库系统,就必须采用更快的存储介质和低延时的网络架构,从而解决缺乏全局DB CACHE支持的问题。当然这个问题也并不是不能解决的,通过更为细致的算子下推,采用类似ORACLE的SMART SCAN等技术,可以解决大部分问题。
存算分离也是一个双刃剑,消除大多数SHARDING方式存储数据的弊端也是有代价的。所有的读写操作都必须经过网络,不像OB那样,如果是本地数据读写不需要经过网络。因此每个单一的读写操作,TiDB都必须承受网络延时的放大。不过TiDB的这种延时放大是稳定的,不会像OB那样,同一条SQL,时快时慢(经过网络肯定要比读取本地数据慢一些)。
TiDB的完全存算分离的架构,很好的解决了Sharding架构的读放大问题,这种架构避免了不必要的读放大,但是也让数据读写的平均延时因网络而受到了一定的影响,得失之间也是有所取舍的。TiDB也在通过计算引擎的优化来减少其负面影响。比如对于不变更的历史数据,TiDB也引入了计算节点本地读缓冲机制来提升性能,同时通过算子尽可能早的向TiKV和TiFlash下推来利用分布式数据库的并发能力来提升性能。
另外很重要的一点是TiDB的存算分离架构用增加网络延时的性能牺牲换来了用户使用的简化,我们基本上可以像使用集中式数据库一样来使用TiDB,建表的时候想建分区表就建分区表,想建普通表就建普通表。全局索引,本地索引也和集中式数据库一样简单。这对于一些应用水平不高的用户来说是十分重要的。因为大部分分布式数据库上的性能问题并不是数据库本身的问题引起的,而是因为应用开发商不合理的设计数据结构,以及不合理的表分区与数据分布引起的。
因为采用截然不同的架构,OB和TiDB在不同的应用场景下的表现会有所不同。对于一些简单的小交易为主的业务来说,因为OB数据库的SHARDING架构,受益于各级缓冲,在这些小交易的延时方面,可能OB较为有优势。而对于一些经常有大型写事务的场景,因为TiDB可以从计算节点更加快速的下推算子而比OB更有优势,而OB必须将算子分解到各个OBSERVER上,交给OBSERVER再往下写数据,其效率肯定是有所损失的。
一些大型的表扫描和多表关联查询也是如此,因为两种不同的架构,在性能上也会表现的不同。当执行计划类似的情况下,TiDB的分布式执行计划被分解的粒度更细,并直接下推到TiKV和TiFlash上,而OB需要将算子分别推送给其他OBSERVER,再由OBSERVER下推,在交互上也多了一层。这是架构的差异导致的直接差异,享受好处的同时肯定也需要承受一些缺陷。
实际上对于复杂的查询,起决定因素的还是CBO优化器的水平,作为两个国产分布式数据库的头部企业,在这方面大家各有胜场。实际上并不是某一条SQL某个数据库胜过其他竞品,就说明这个数据库的优化器做的比竞品好。就像前几天我在测试一条OB4的SQL的执行计划时,发现其已经完成了对一个复杂HASH JOIN的自动改写,因此执行效率远高于基于PG优化器改造的国产数据库。我的比较仅仅是针对这条SQL而已,并不说明OB的SQL引擎就一定比其他数据库好。实际上优化器都是在不断的应用中发现问题,不断的打补丁打出来的。Oracle的优化器就是在几十年的不断补丁中优化出来的,我们的国产数据库也必然需要经过这样的过程。我想只要发现了我上回实验的那个问题,有实力的国产数据库厂商很快就能解决那个问题。
正是因为上面的原因,因此如果你的企业应用十分复杂,数据量十分大。那么在你从类似OB/TiDB这样不同架构的分布式数据库中做选择的时候,一定要把你比较复杂的SQL拿出来做些测试,再来完成你的选择。因为对于大多数应用来说,这些分布式数据库在架构上的缺陷还是不会造成太大的影响的,而如果某些SQL因为执行计划无法优化而导致你必须改写应用就比较麻烦了。
分布式数据库与应用的对比实际上是十分复杂的,今天我们仅仅从存算分离的架构上做了一些简单的分析。实际上还有很多问题没有涉及,比如说资源管理、多租户、HTAP等特性。因为架构不同,数据库对不同类型的应用支持是会略有不同的。不过实际上对于大多数应用来说,这些差异并不是不可逾越的鸿沟,并不是某种应用必须选择某个数据库产品才能跑起来。数据库选型只是一次选择,如何用好一个数据库产品,是需要长期积累的,不同数据库厂商的售后支持能力,服务客户的态度,第三方服务能力可能是数据库选择的更重要的考虑因素。
分区表
tidb
应用架构
分布式数据库
架构
文章转载自
杨建荣的学习笔记
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨