




点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel


SeaTunnel CDC 支持的背景
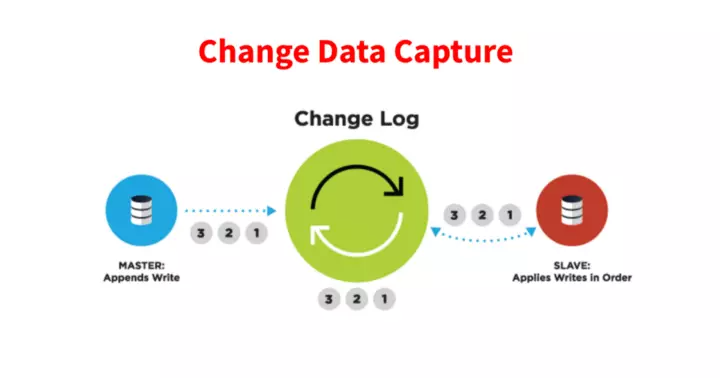
动机
支持并行读取历史数据(快速同步,亿级大表) 支持读取增量数据(CDC) 支持心跳检测(metrics、小流量表) 支持动态添加新表(更易于操作和维护)
整体设计
基
本
流
程
”
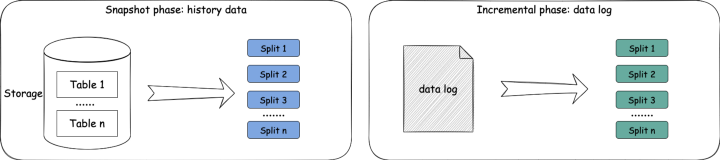
最小拆分粒度:表的主键范围数据
最小拆分粒度:一张表
快照阶段
DS
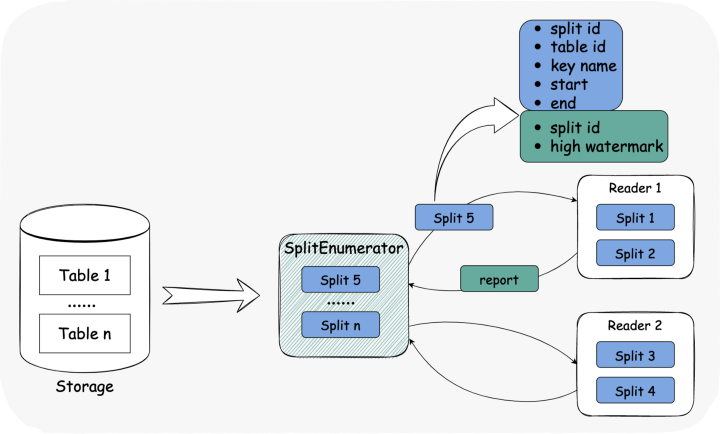
/ pseudo-code.public class SnapshotSplit implements SourceSplit {private final String splitId;private final TableId tableId;private final SeaTunnelRowType splitKeyType;private final Object splitStart;private final Object splitEnd;}
// pseudo-code.public class CompletedSnapshotSplitReportEvent implements SourceEvent {private final String splitId;private final Offset highWatermark;}
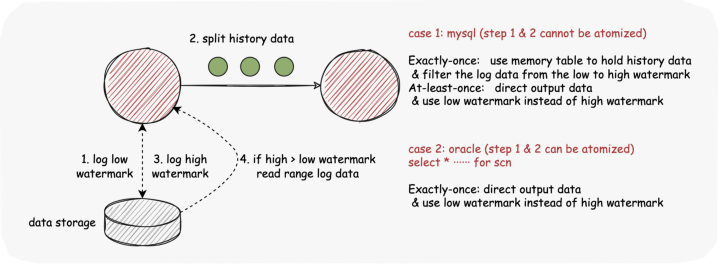
日志低水位线:读取快照数据前获取当前日志偏移量。 Read SnapshotSplit data:读取属于split 的数据范围 案例1:步骤1&2不能原子化(MySQL)
exactly-once:使用内存表保存历史数据 & 过滤日志数据从低水位线到高水位线 至少一次:直接输出数据并使用低水印而不是高水印 案例 2:步骤 1 和 2 可以原子化(Oracle) 可以使用 for scn 来保证两步的原子化 Exactly-Once:直接输出数据并使用低位线而不是高位线
step 2 案例 1 & Exactly-Once:读取快照数据后获取当前日志偏移量。 其他:使用低位线代替高位线
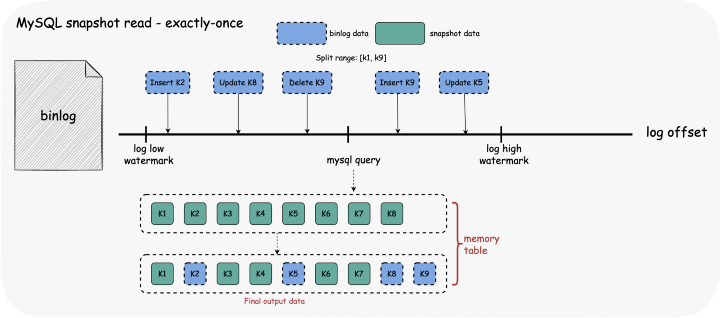
日志低水位线:读取快照数据前获取当前日志偏移量。 读取 SnapshotSplit 数据:读取属于 split 的范围数据,写入内存表。 日志高水位线:读取快照数据后获取当前日志偏移量。 读取范围日志数据:读取日志数据并写入内存表 输出内存表的数据,释放内存使用量。
增量阶段
DS
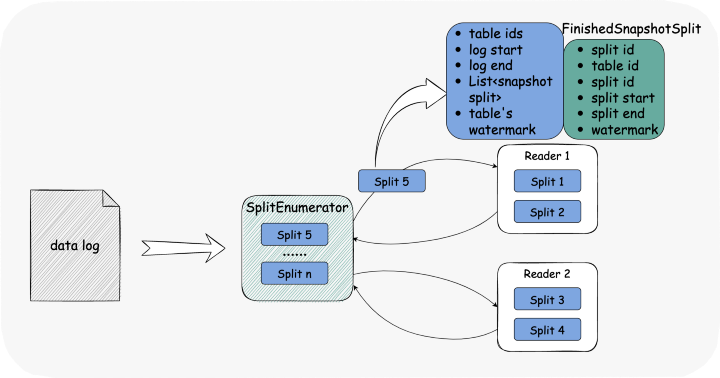
增量阶段默认只有一个 reader 工作,用户也可以配置选项指定数量(不能超过 reader 数量) 一个 reader 最多获得一个连接
// pseudo-code.public class LogSplit implements SourceSplit {private final String splitId;/*** All the tables that this log split needs to capture.*/private final List<TableId> tableIds;/*** Minimum watermark for SnapshotSplits for all tables in this LogSplit*/private final Offset startingOffset;/*** Obtained by configuration, may not end*/private final Offset endingOffset;/*** SnapshotSplit information for all tables in this LogSplit.* </br> Used to support Exactly-Once.*/private final List<CompletedSnapshotSplitInfo> completedSnapshotSplitInfos;/*** Maximum watermark in SnapshotSplits per table.* </br> Used to delete information in completedSnapshotSplitInfos, reducing state size.* </br> Used to support Exactly-Once.*/private final Map<TableId, Offset> tableWatermarks;}// pseudo-code.public class CompletedSnapshotSplitInfo implements Serializable {private final String splitId;private final TableId tableId;private final SeaTunnelRowType splitKeyType;private final Object splitStart;private final Object splitEnd;private final Offset watermark;}
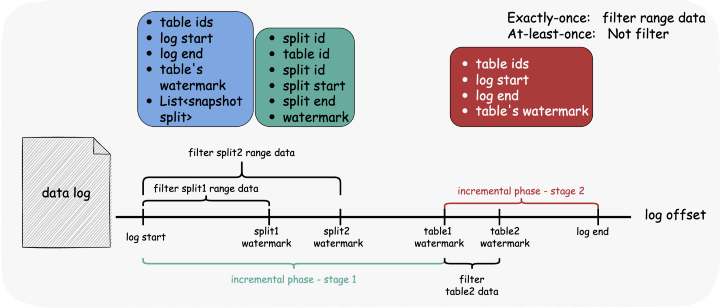
阶段 1:在水印数据之前使用 completedSnapshotSplitInfos 过滤器。 阶段2:表不再需要过滤,在 completedSnapshotSplitInfos 中删除属于该表的数据,因为后面的数据需要处理。
动态发现新表
DS
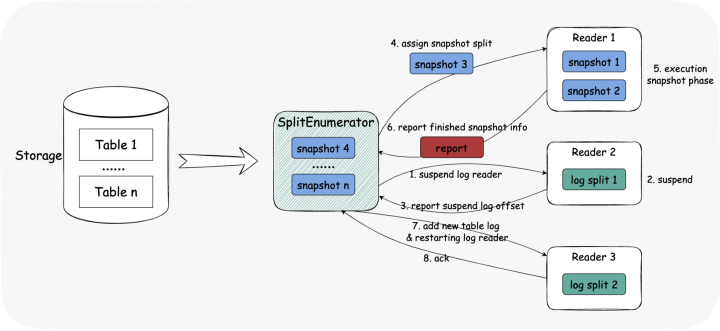
暂停 LogSplit reader。(如果有空闲的 reader,需要暂停吗?) Reader 暂停运行。 Reader 报告当前日志偏移量。(如不上报,reader 需支持 LogSplit 组合) 将 SnapshotSplit 分配给阅读器。 Reader 执行快照阶段读取。 Reader 报告所有 SnapshotSplit 水印。 为 Reader 分配一个新的 LogSplit。 Reader 再次开始增量阅读并向枚举器确认。
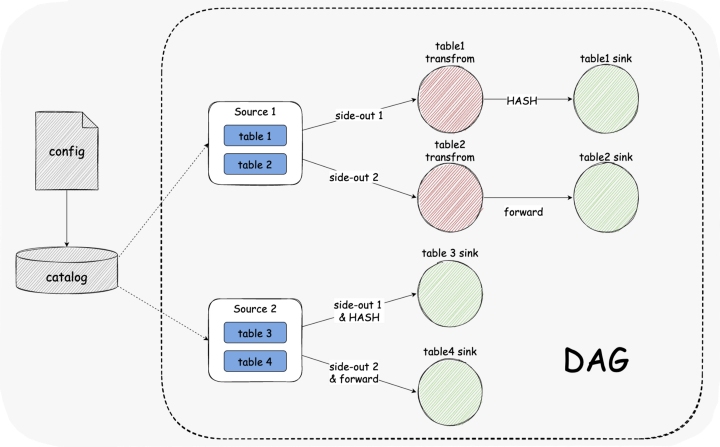
多个结构化表格
DS
优点:占用数据库连接少,减少数据库压力 缺点:在 SeaTunnel 引擎中,多个表会在一个管道中,容错的粒度会变大。
Apache SeaTunnel

往期推荐
点击“阅读原文”参与共建!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
