




NoSQL优势
全称:Not Only SQL 不仅仅是数据库
海量的扩展能力 读写高性能 与关系型数据库(RDBMS)相辅相成
NoSQL产品
键值存储型(Key-Value) Redis/Codis
列存储型 HBase
Hbase数据分析用的比较多
图形(Graph)数据库
Neo4j知识图片用的较多
文档型 MongoDB
MongoDB概念
举例:描述人
关系型数据库
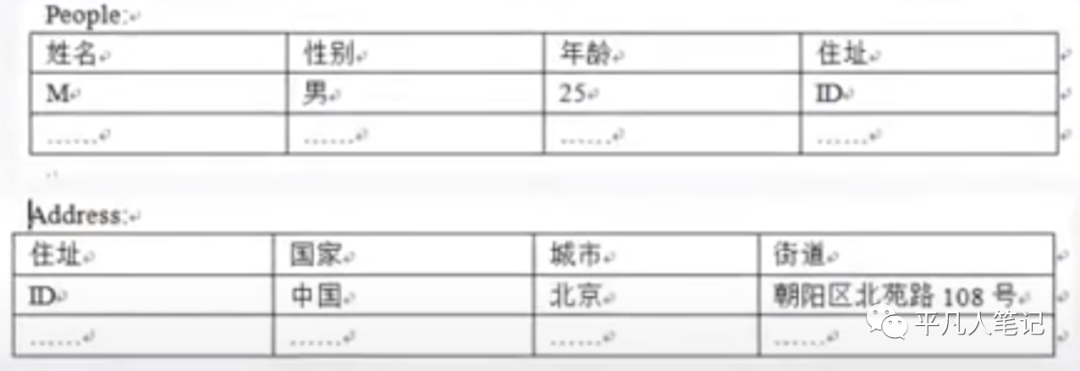
MongoDB

MongoDB特性
可扩展(scalable) 高性能(high-performance) 开源(open source) NoSQL database C++语言编写 Document-Oriented Storage Full Index Support Replication & High Availability Auto-Sharding Rich Querying Updates Map/Reduce GridFS 存储二进制文件
MongoDB稳定性
如何解决数据丢失
恢复日志(journal)

写关注

写入大多数节点
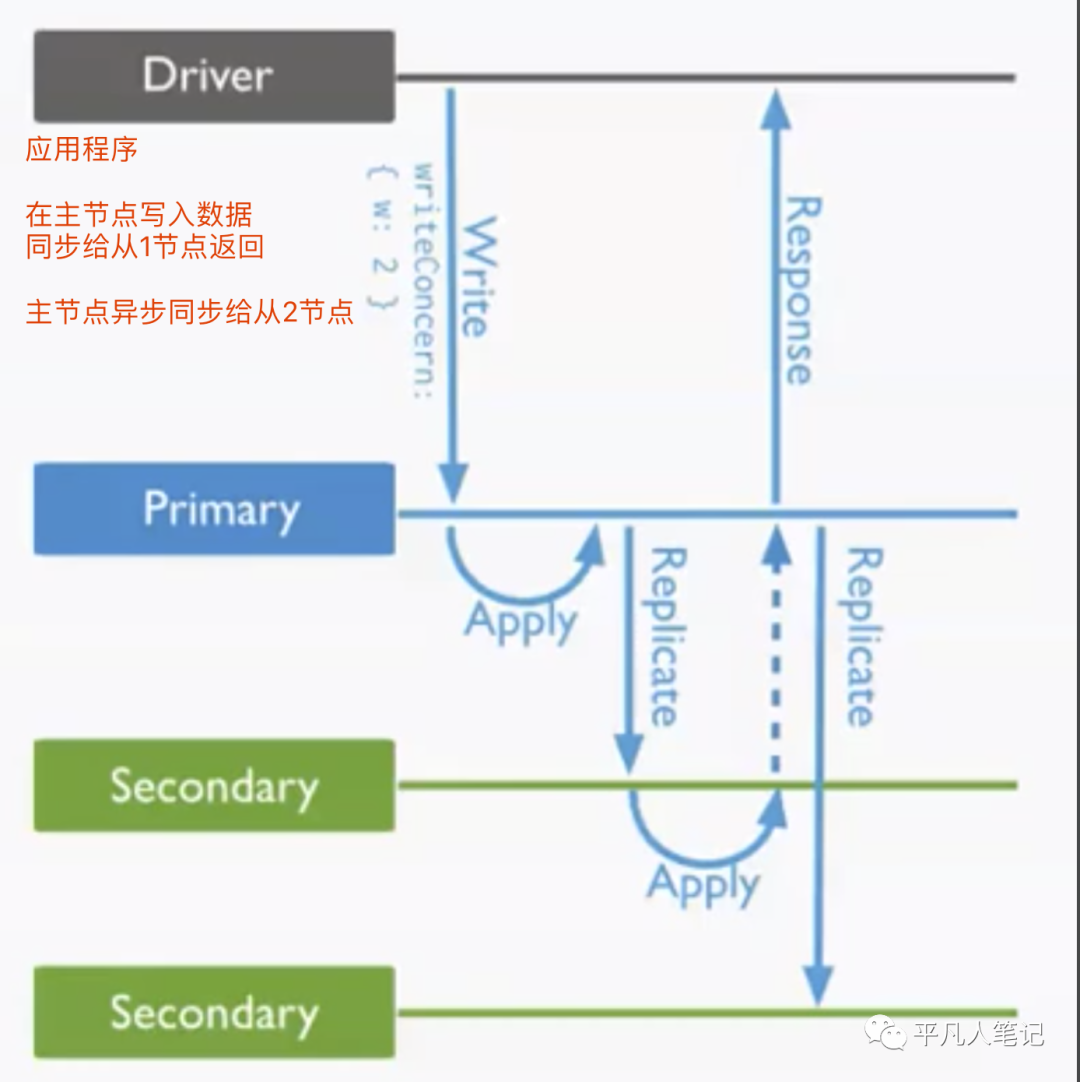
MongoDB高可用
核心业务SLASLA 99.99%以上怎么做到的?
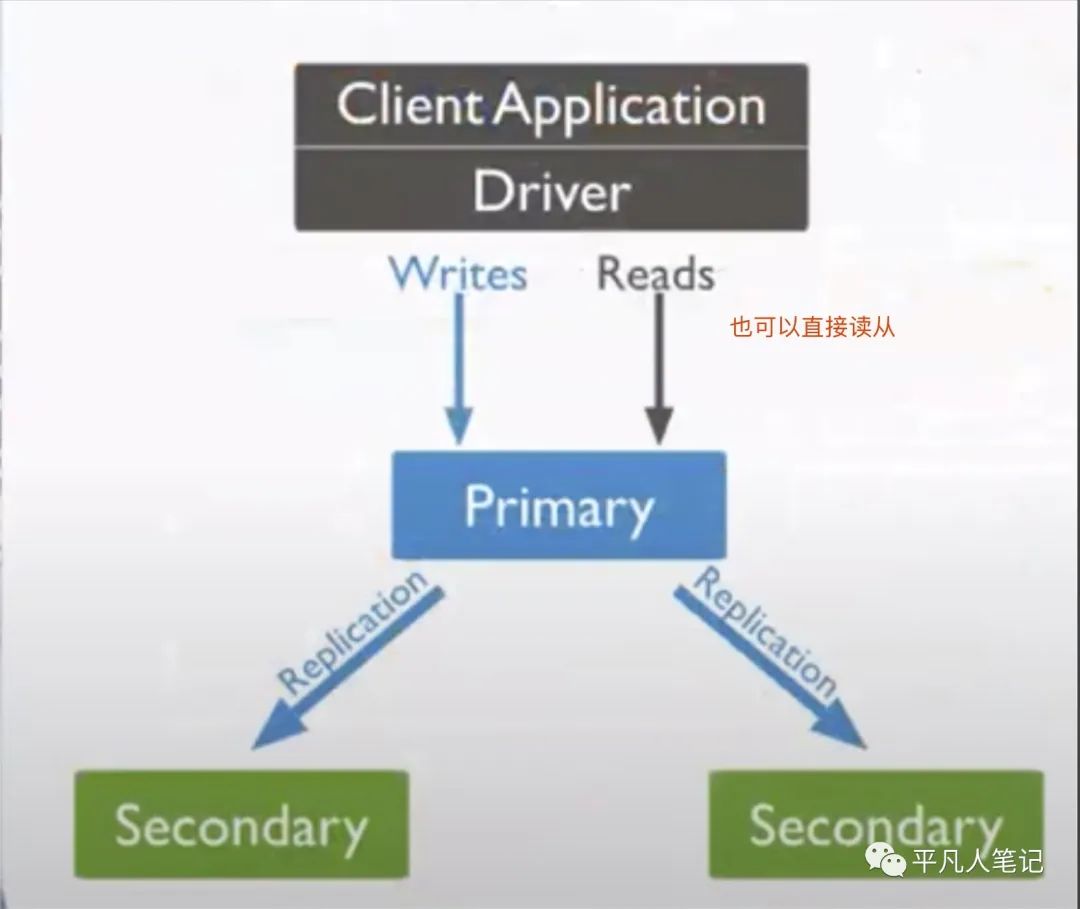
MongoDB 副本集(replica set)
数据多分冗余 跨交换机部署 更快的选举方式(参考raft协议)
架构
主从复制+高可用方案
分片
架构
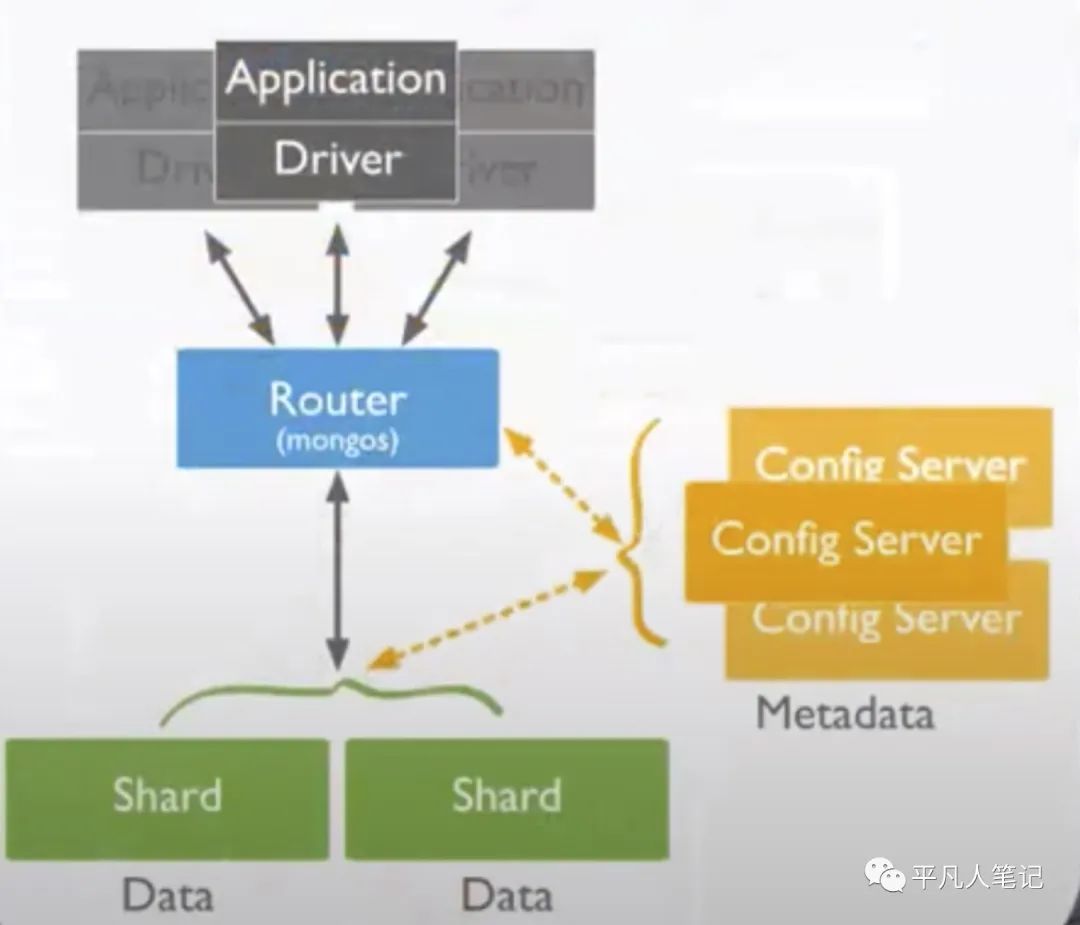
1、对业务方来说没有分库分表的概念
不管数据量多大 对业务方来说都是单库单表
对于关系型数据库来说比如Myql有分库分表的概念
比如1T数据 MongoDB分2个片 每一个片存储500G数据
2、Router可以有很多台
3、分片信息存储在config server中
4、一个分片就是一个副本集(replica set)
5、Router先访问config server获取分片信息,Router再访问分片集(replica set)
表的分片(MongoDB Collection)
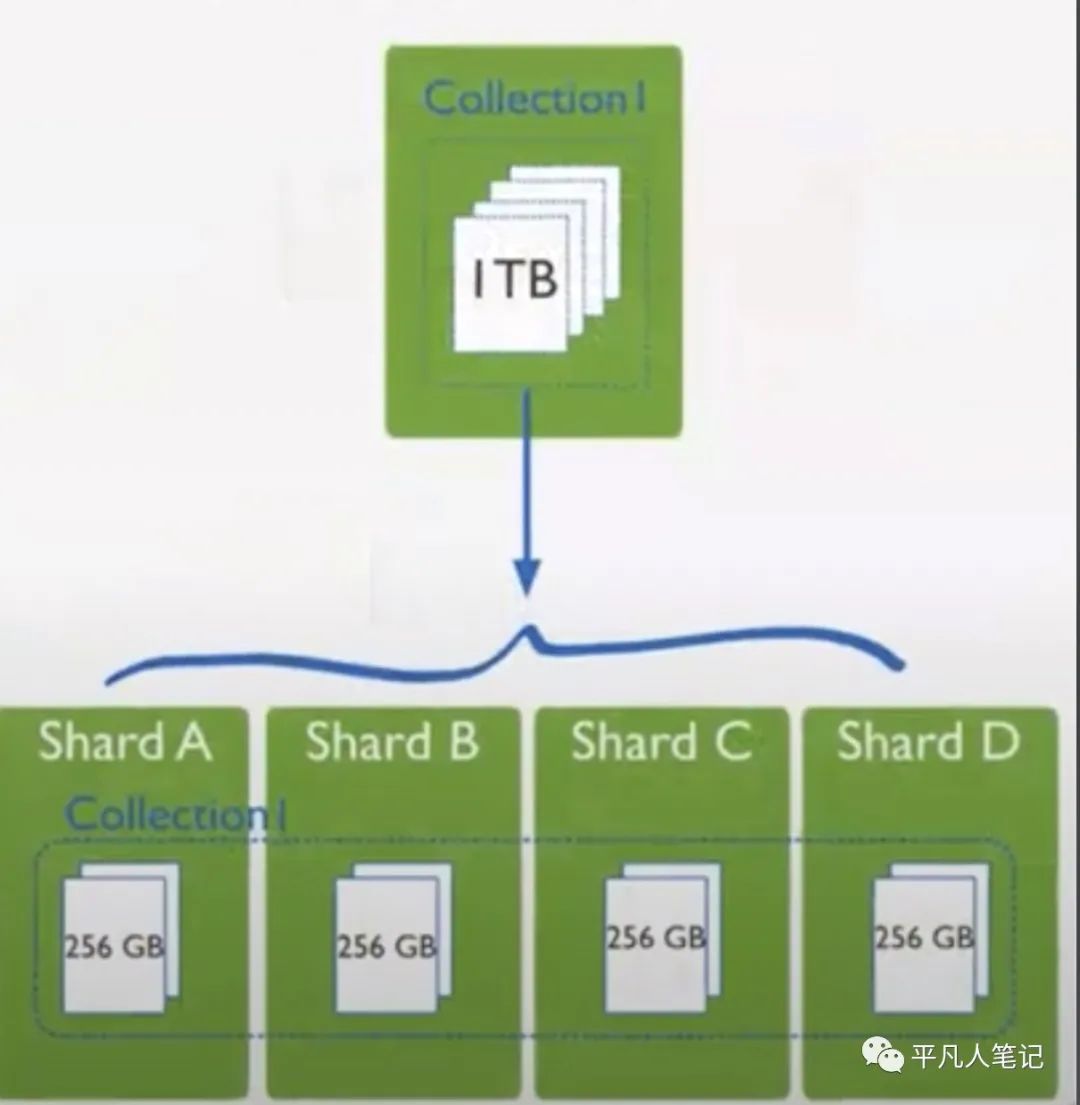
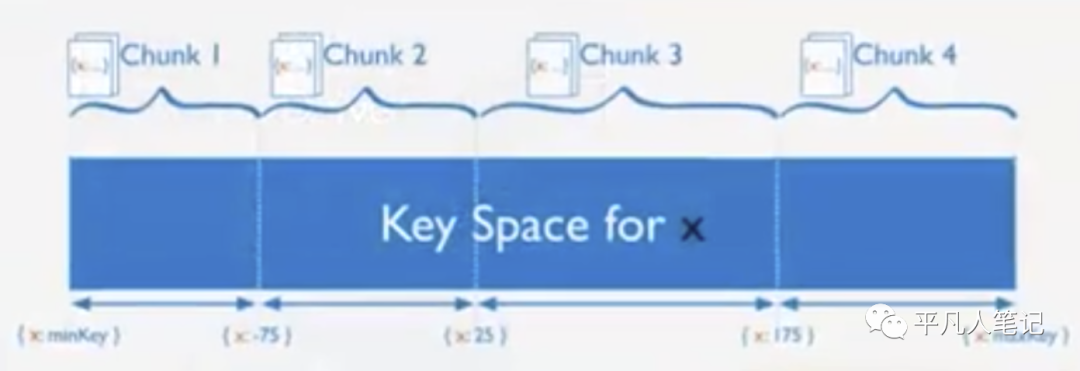
分片规则
Sharding Range-based
基于范围分片 用的较多
Mysql B+ Tree本质也是Range-based
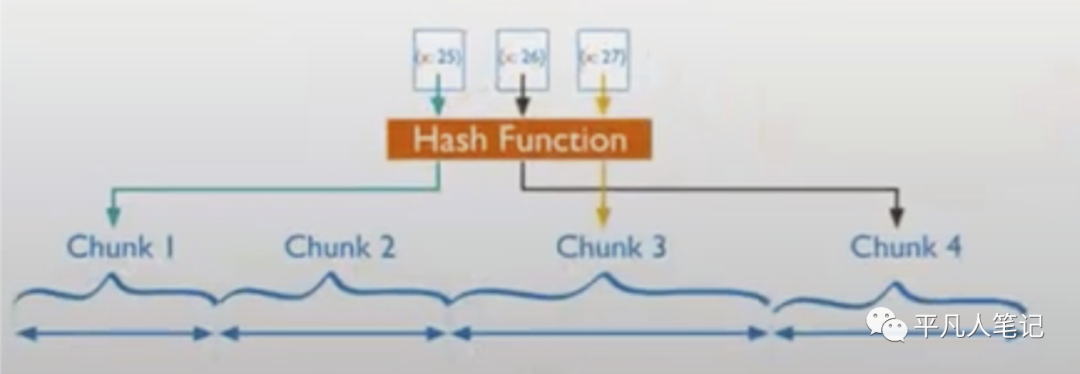
Sharding Hash-based
取模分片
Java HashMap是Hash-based
查询速度比较快
不支持范围查询
对于数据库来说 不支持范围查询肯定不合适
分片集群架构
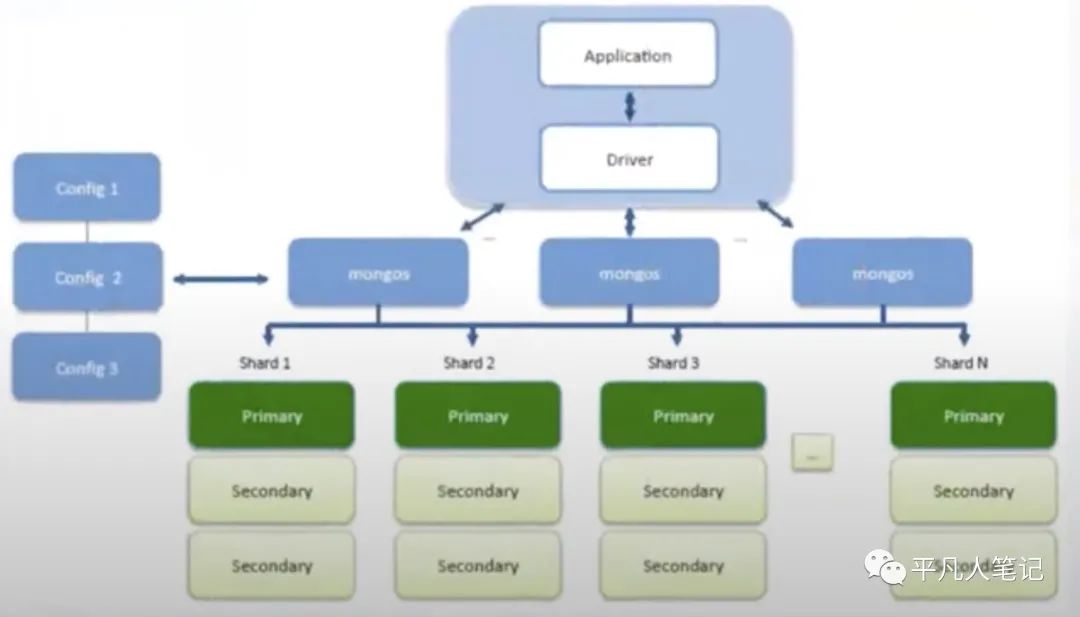
1、3个配置节点、3个路由节点(mongos)都是stateless(无状态的即数据都一样)
2、每个分片就是一个replica set(一主两从) 一个分片3台机器
3、cnofig和mongos也可以混合部署在一个sharding上
应用场景

1、位置即GPS或LBS
2、中小公司用它没有问题 量大肯定不行
3、非交易相关的都可以用
a、事务支持的比较弱
b、mongodb 4.0已经支持事务 并且支持跨行事务
可扩展存储

1、最早的操作引擎是MMAP 支持表级锁 也是操作系统自带的一种机制
缺点就是内存利用率不高
2、WireTigger支持行级锁
文档设计

_id 全局唯一标识 表粒度
不填写默认生成一个12字节的objectid
占用空间比较大
一般用业务主键比如uid等代替掉 否则和自增主键一样 无意义
_id默认生成规则(不推荐)

1、collection是表级
2、a、1位16进制占4个字节即4个bytes 代表一个字符串
b、一个字节占2位即2个字符串
c、_id 一共有12个字节即24个字符串
3、可读性很差 占空间比较大
_id推荐生成规则

1、uint64_t 其实就是long类型 占8个字节
2、objectid是默认类型也是是整型、long类型、浮点型
Free Shcama
意味着重复的Schema、All Schema

如何应对

字段名选取

字段名简化了 如何保证可读性

MongoDB数据量限制
MongoDB限制每一个doc(文档)最大16MB
数据较少场景
考试成绩、个人信息

数据较多场景
三国杀和武将牌
常规引用关联

内嵌文档
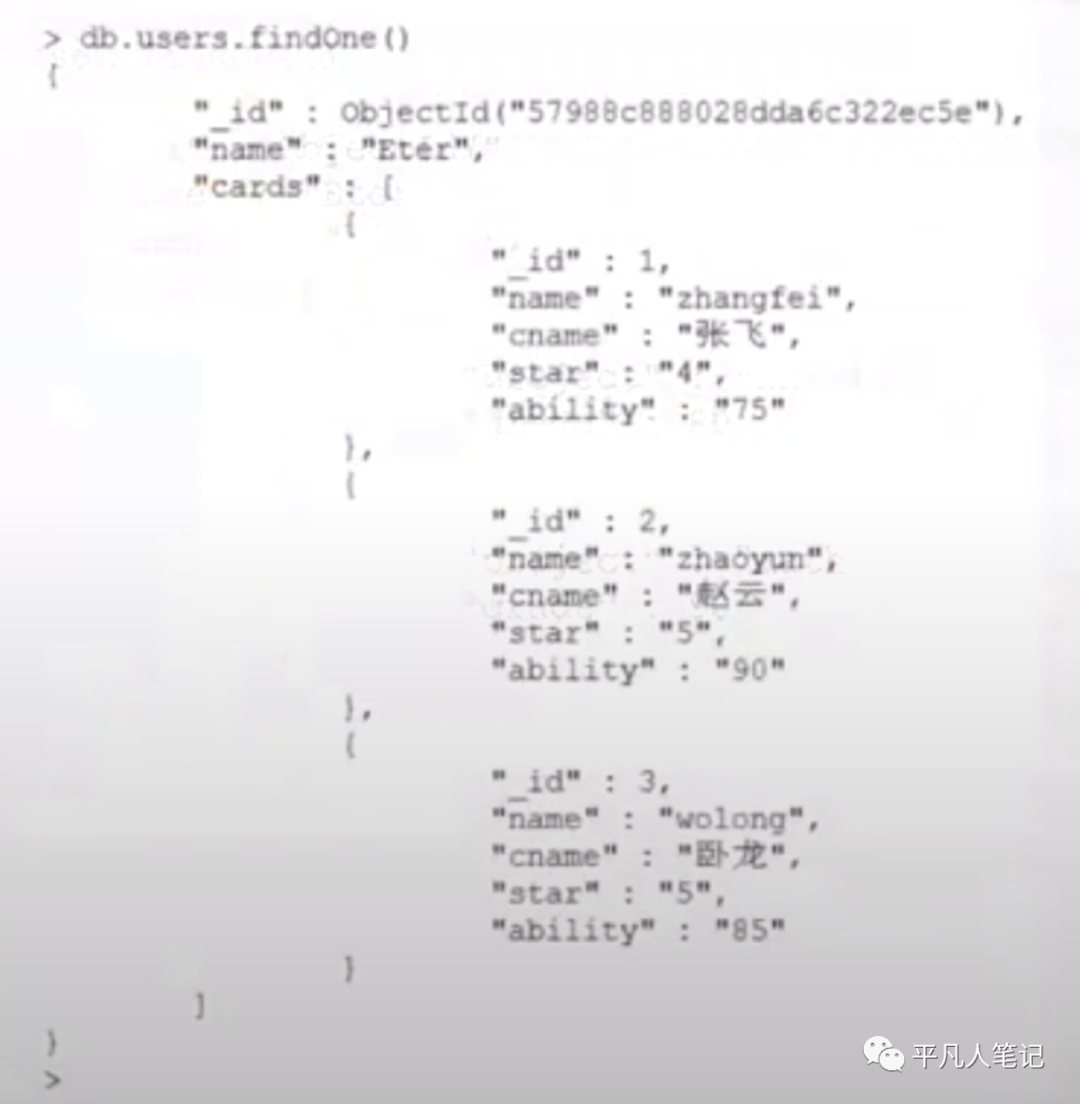
日志场景引用更有效 Host&Log
机器和日志不能用内嵌 只能用引用
锁机制
悲观锁
悲观锁并发控制
使用写锁来保护资源不被同时访问 读写操作为互斥操作
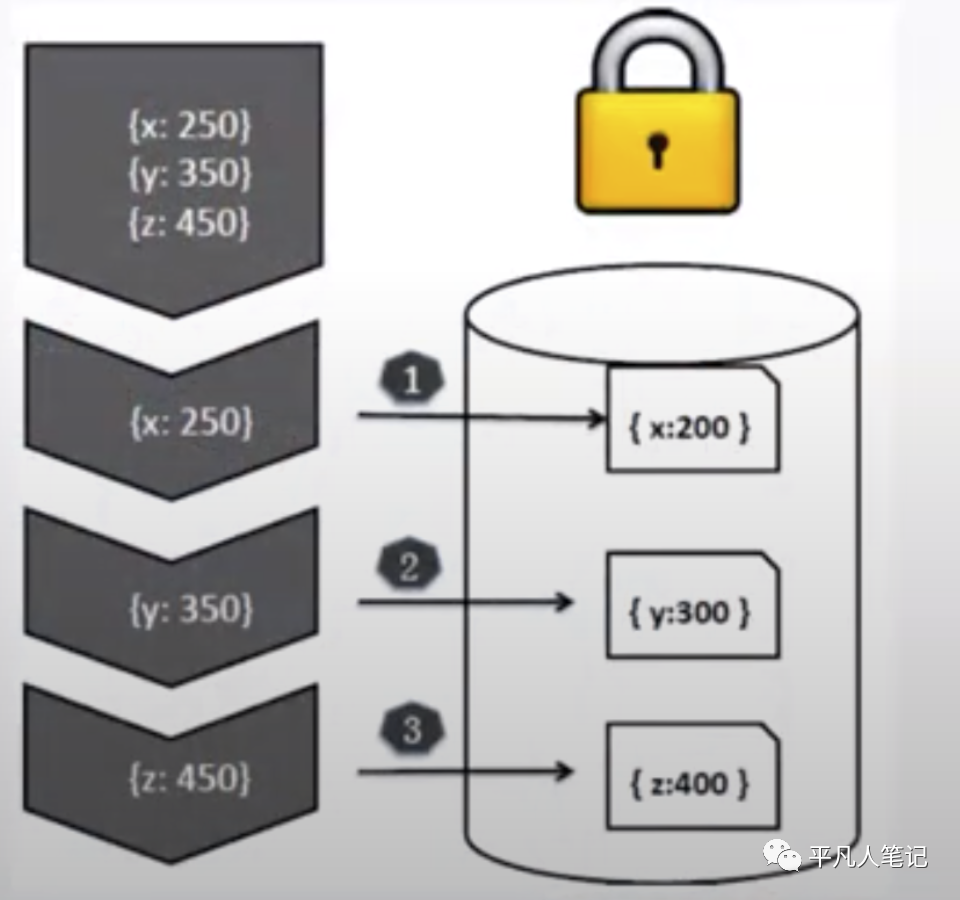
悲观锁范围
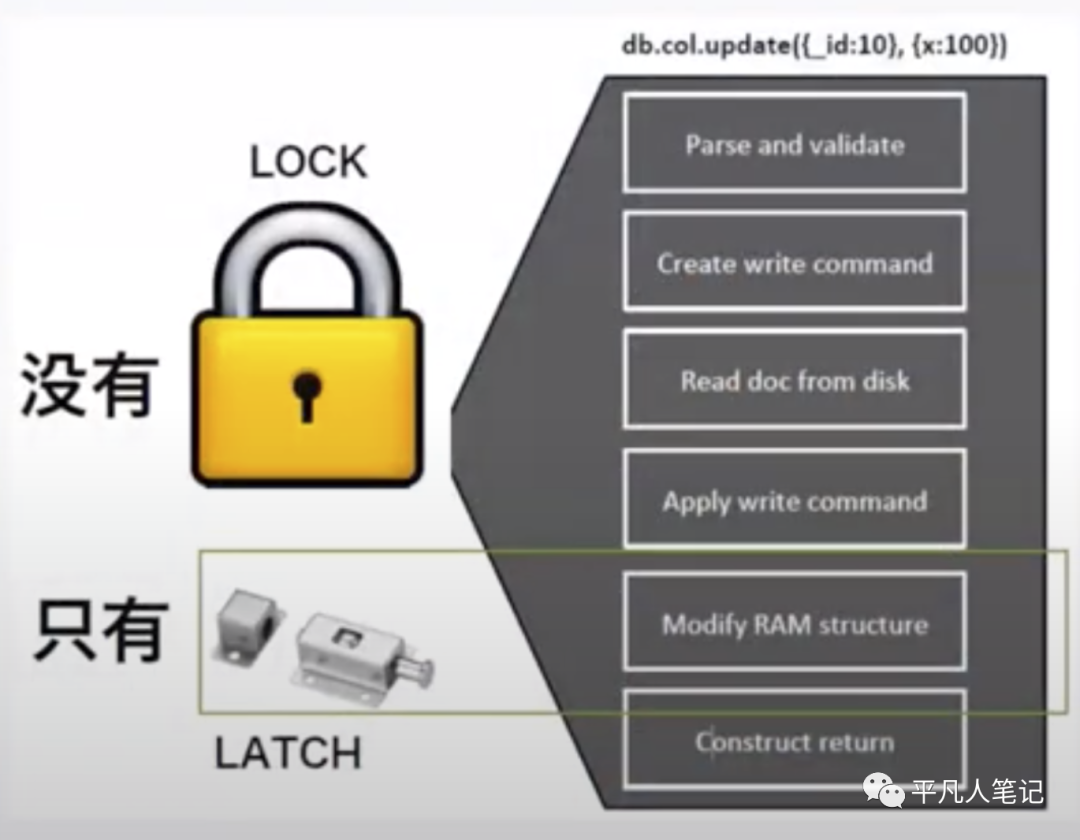
1、sql解析
2、创建一个写命令
3、从磁盘中读文档 把数据读取到内存
4、针对内存数据执行写命令
5、对内存结构做修改(仅在这一步加锁)
6、返回结果
乐观锁
MongoDB 3.0 WT MVCC机制
乐观派 lock-free并发控制
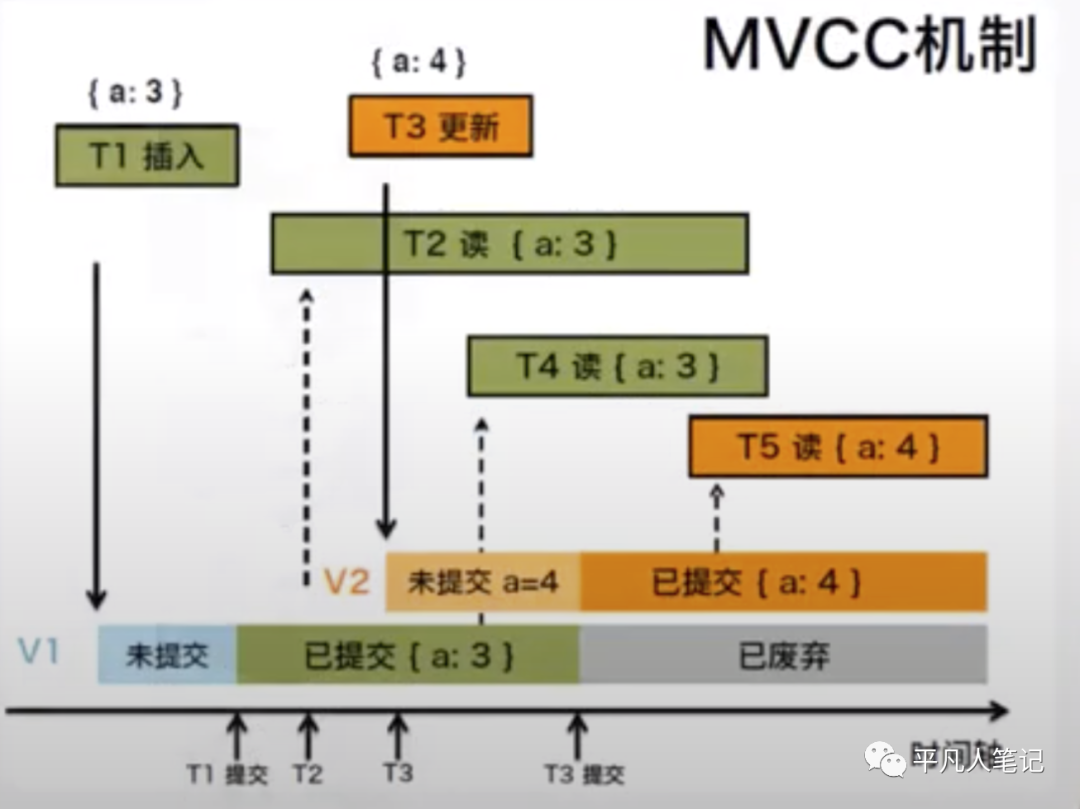
乐观锁意义

压缩算法
Snappy

Zlib(常用)

遇到的坑及解决方案
大量删除数据及解决方案
背景

解决方案

大量数据碎片(空洞)及解决方案
背景

大量删除数据 产生内存碎片

数据删除完之后 会留下很多空洞 不会马上回收
早期用的MMAP
空洞数据也会加载到内存中去
比如64G内存 大量空洞数据 有效数据仅占内存10G
解决方案

碎片整理方案
线上数据压缩

收缩数据库

具体数据收缩步骤

压缩效果对比
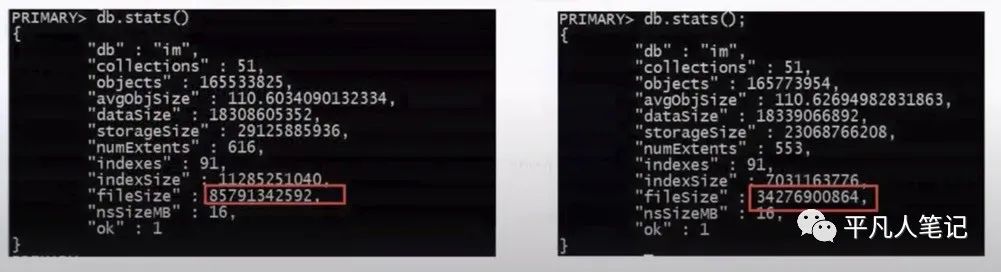
搜索前85G 压缩后34G 节省了51G内存 大大提升了性能
上述步骤大致流程
1、把从库 rm -rf *
2、重启从库
3、从主库重新同步一份 从库上面完全没有碎片
4、主库上执行stepDown 主库变成从库 从库变成主库
5、删掉从库 重启 再同步 同步完了 从库就变成新的了
(删除之后同步数据 碎片数据不会同步)
注:
a、一主二从 主库降权 数据最新的从库会提升为主
b、主从同步之间丢失的数据 业务系统通过补偿机制保存MongoDB
文章转载自平凡人笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
