




Hello 大家好,我是 猿java
今天分享的内容是:新一代 Java 垃圾回收神器:ZGC。
一、ZGC定义
ZGC(The Z Garbage Collector),是一种可扩展的低延迟垃圾收集器,主要用来处理超大内存(TB 级别)的垃圾回收。ZGC 最初是 JDK 11 以一项实验性功能引入,经过几个版本的迭代,最终在 JDK 15 中被宣布为 Production Ready。
ZGC 中的"Z"代表什么含义?官方解释如下:

大概意思为:Z 它不代表任何东西,ZGC 只是一个名字。它最初受到 ZFS(文件系统)的启发或致敬,ZFS(文件系统)在首次问世时在许多方面都是革命性的。最初,ZFS 是“Zettabyte File System”的首字母缩写词,但这个意思被废弃了,后来据说它不代表任何东西。这只是一个名字。
下图为 Oracle官方对 ZGC停顿时间的描述:

二、ZGC目标
2018 年,Oracle 官方描述的 ZGC 目标为:
处理 TB 量级的堆;
GC 时间不超过 10ms;
相对于使用 G1,应用吞吐量的降低不超过 15%;

2022 年 11 月,Oracle 官方描述的 ZGC 的目标为:
低延时,亚毫秒的最大暂停时间
暂停时间不会随着堆、live-set 或 root-set 的大小而增加
处理 TB 量级的堆(可以处理 8MB-16TB 的堆);
通过官方对 ZGC 目标的描述可以看出:几年的时间内,ZGC一直在不遗余力的朝低延时前进,ZGC 垃圾回收的最大停顿时间已从 10ms 降低到亚毫秒级别,性能有了质的飞越。
三、核心技术
2018年,官方描述的 ZGC核心技术为:
Concurrent:并发
Tracing: 可追踪
Compacting:整理内存
Single generation: 单代,也就是不进行分代
Region-based:基于 Region
NUMA-aware:支持 NUMA,Non-Uniform Memory Access(非一致内存访问)
Load barriers:读屏障
Colored pointers:染色指针,一种将信息存储在指针中的技术

2022年,官方描述的 ZGC核心技术为:
Concurrent:并发
Region-based:基于 Region
Compacting:整理内存
NUMA-aware:支持 NUMA,Non-Uniform Memory Access(非一致内存访问)
Using colored pointers:使用染色指针,一种将信息存储在指针中的技术
Using load barriers:使用读屏障
比较 2018 年 和 2022 年官方对 ZGC 核心技术的描述可以发现,官方把 Single generation 这一点去掉了,熟悉 G1 的小伙伴应该知道,G1 是 Region-based 类型,每个 Region 在同一时刻只能属于一种分代,但是,一个 Region 可以在多个分代之间动态切换,因此,ZGC 从最初的不分代发展成和 G1回收器一样,也有分代。
四、ZGC原理
4.1、Region-based
Region-based:基于区域。
ZGC 和 G1 等垃圾回收器一样,也会将堆划分成很多的小分区,整个堆内存分区如下图:
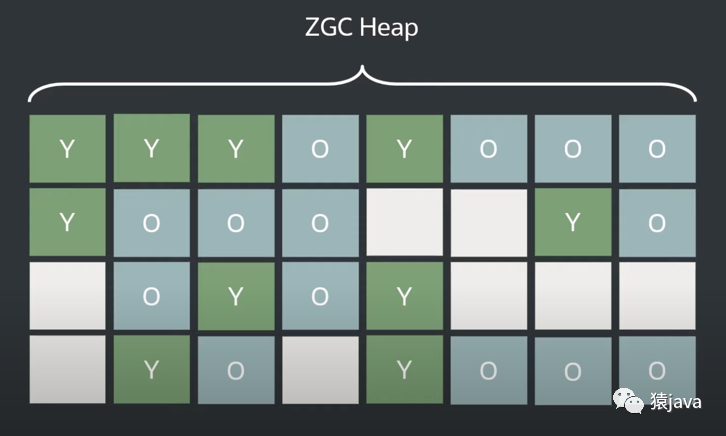
ZGC 的 Region 有小、中、大三种类型:
Small Region(小型 Region):容量固定为 2M, 存放小于 256K 的对象;
Medium Region(中型 Region):容量固定为 32M,放置大于等于 256K,并小于 4M 的对象;
Large Region(大型 Region): 容量不固定,可以动态变化,但必须为 2M 的整数倍,用于放置大于等于 4MB 的大对象;
4.2、Compacting
Compacting:整理内存。
因为 ZGC 回收器和 CMS、G1 等垃圾回收器一样,使用了"标记-复制算法",该算法会产生内存碎片,因此需要进行内存整理操作,清除内存碎片。
4.3、NUMA
NUMA,Non-Uniform Memory Access(非一致内存访问)。
最初的计算机是单核处理器,一个 CPU 访问一块内存,但是随着网络的快速发展,单核远不能满足实际需求,因此采用多核处理器技术,多 CPU 需要访问同一个内存,因为任一 CPU 对同一内存的访问速度是一致的,所以也称作一致内存访问(Uniform Memory Access, UMA),再随着网络的发展,单内存无法满足需求,因此就诞生了多内存,把 CPU 和内存集成到同一个单元,这样 CPU 就会访问离它最近的内存,提升读写效率,这种方式就是非一致内存访问。
NUMA 和 UMA 比较如下图:
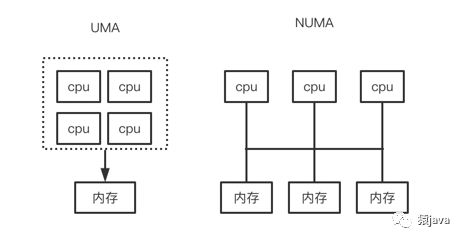
NUMA 架构在中大型系统上非常流行,是一种高性能的解决方案,ZGC 就充分利用 NUMA 架构的特征。
4.4、Colored pointers
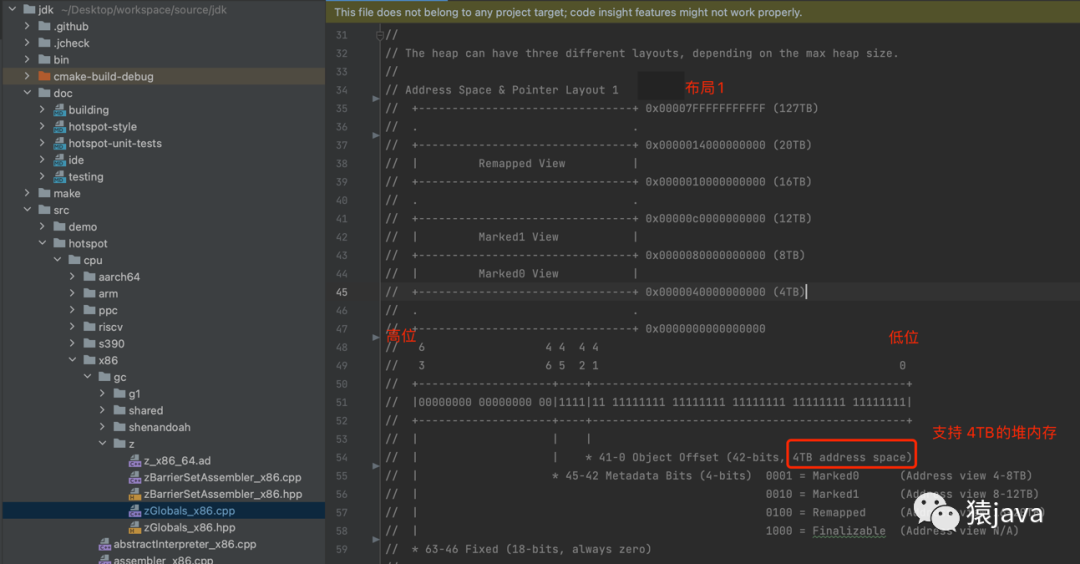
Colored pointers:染色指针,一种将数据存放在指针里的技术,JVM 是通过染色指针来标识某个对象是否需要被 GC。像 CMS,G1 这些垃圾收集器的 GC 信息都保存在对象头中,而 ZGC 的 GC 信息保存在指针中,每个对象有一个 64 位指针,参考 JDK zGlobals_x86.cpp 源码,ZGC 地址空间和指针结构有如下 3 种布局:
布局 1
[0 ~ 41] 共 42-bits,对应 4TB 的 Java 堆内存;
[42-45] 共 4-bits,对应 Metadata Bits,存放 Marked0,Marked1,Remapped,Finalizable 元数据;
[46-63] 共 18-bits,全部存放 0,预留未使用;
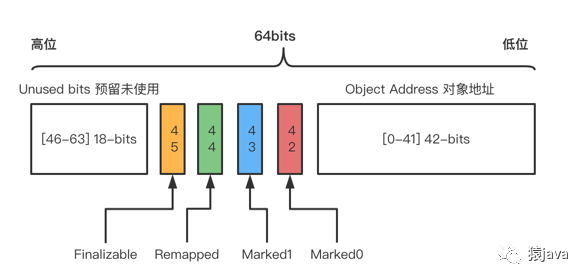
抽象成结构图如下:
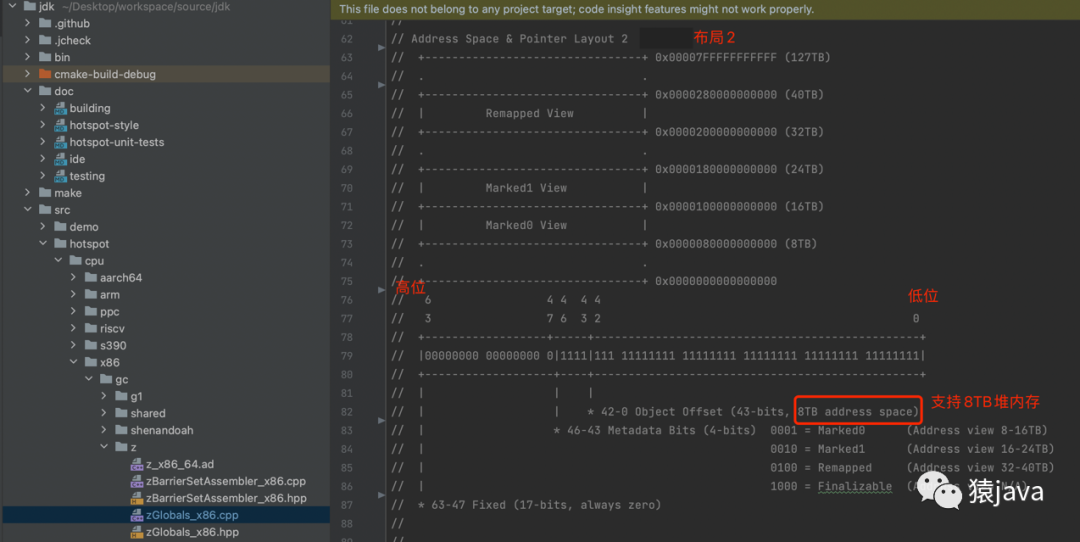
布局 2
[0 ~ 42] 共 43-bits,对应 8TB 的 Java 堆内存;
[43-46] 共 4-bits,对应 Metadata Bits,存放 Marked0,Marked1,Remapped,Finalizable 元数据;
[47-63] 共 17-bits,全部存放 0,预留未使用;
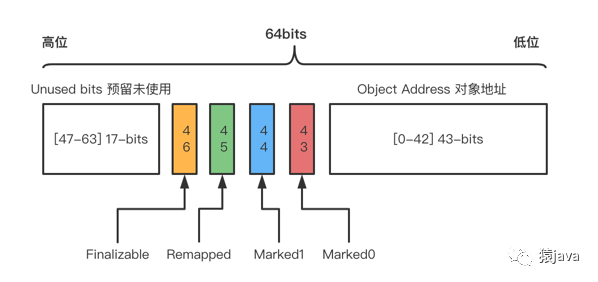
抽象成结构图如下:
布局 3
[0 ~ 43] 共 44-bits,对应 16TB 的 Java 堆内存;
[44-47] 共 4-bits,对应 Metadata Bits,存放 Marked0,Marked1,Remapped,Finalizable 元数据;
[48-63] 共 16-bits,全部存放 0,预留未使用;
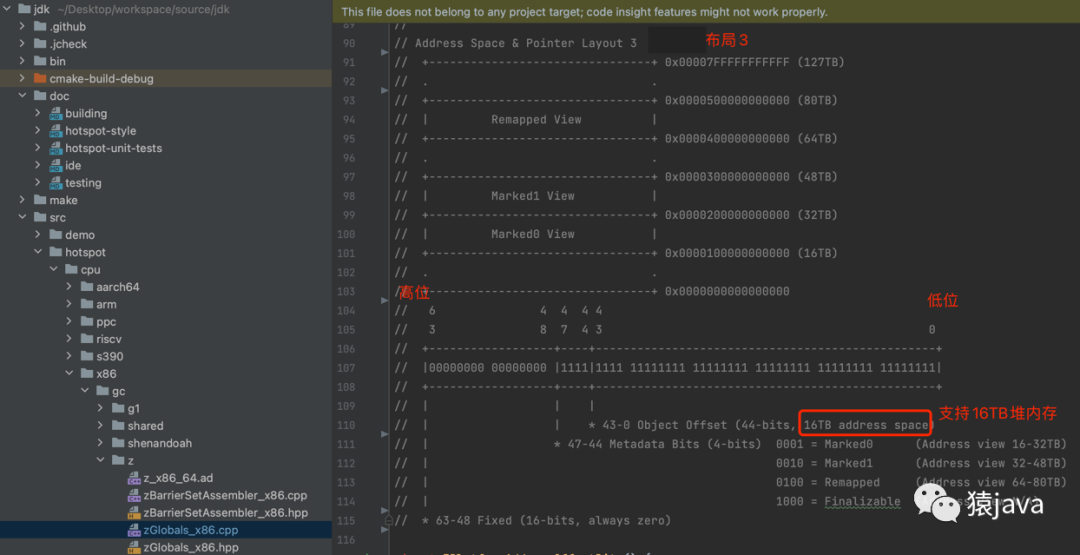
抽象成结构图如下:
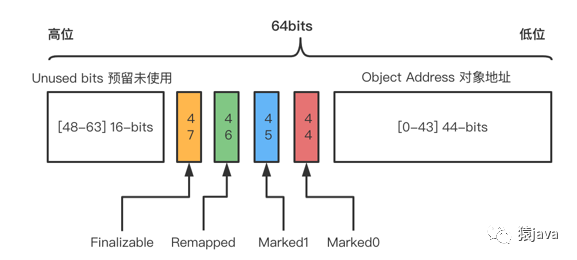
通过上面的 3 种布局,可以发现一个共性:分配 4-bits 来分别存放 Marked0,Marked1,Remapped,Finalizable 染色标记位,4 种染色标记位说明如下:
Marked0,1-bit,用于标记可到达的对象(活跃对象);
Marked1,1-bit,用于标记可到达的对象(活跃对象);
Remapped,1-bit,指向最新的并指向该对象的当前位置;
Finalizable,1-bit,标识这个对象只能通过 finalizer 才能访问;
4.5、多重视图
上述 Marked0,Marked1,Remapped 染色标记位其实代表一种地址视图,当应用程序创建对象时,首先在堆空间申请一个虚拟地址,ZGC 同时会为该对象在 Marked0、Marked1 和 Remapped 地址空间分别申请一个虚拟地址,三个虚拟地址指向同一个物理地址,并且在同一时间,三个虚拟地址有且只有一个空间有效,整个视图映射关系如下图:
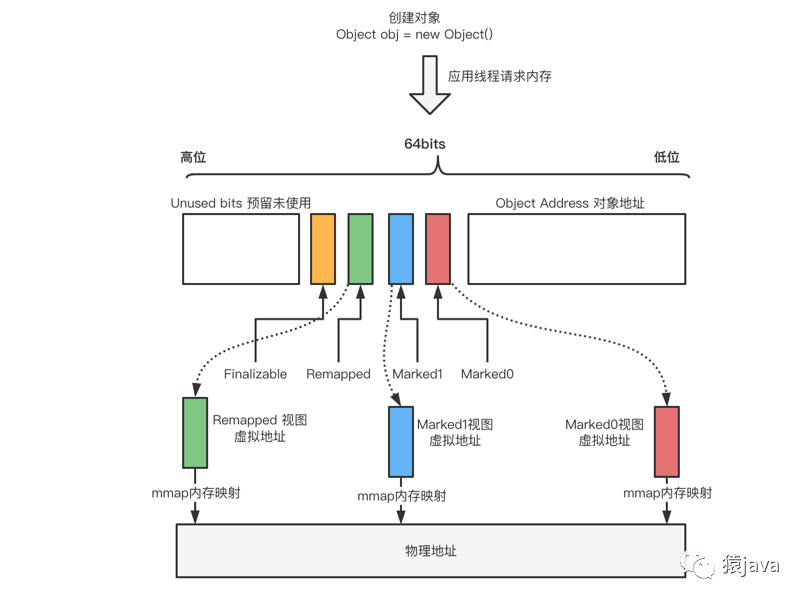
ZGC 之所以设置三个虚拟地址空间,目的是使用"虚拟空间换时间"的思想,从而降低 GC 停顿时间。三个空间的切换是由垃圾回收的不同阶段触发的,通过限定三个空间在同一时间点有且仅有一个空间有效高效的完成 GC 过程的并发操作。
4.6、Load barriers
Load barriers:读屏障,是指 JIT( just-in-time compilation 即时编译器,JVM)向应用代码注入一小段代码,当从堆中读取对象引用时,就会执行这段代码,官方说明如下:

读屏障示例:
String n = person.name; // 从堆中读取引用,需要加入屏障<Load barrier start>if (n & bad_bit_mask) {slow_path(register_for(n), address_of(person.name));}<Load barrier end>String p = n ; // 无需屏障,不是从堆中读取引用n.isEmpty() ; // 无需屏障,不是从堆中读取引用int age = person.age; // 无需屏障,不是对象引用
在读屏障示例中,JVM 注入了如下的一段读屏障代码:
if (n & bad_bit_mask) {slow_path(register_for(n), address_of(person.name));}
对应的字节码如下:
mov 0x10(%rax), %rbx // String n = person.name;test %rbx, 0x20(%r15) // Bad color?jnz slow_path // Yes -> Enter slow path and// mark/relocate/remap, adjust// 0x10(%rax) and %rbx
假如 person 对象发生移动,因此 n 和 person.name 的地址都会发生变化,当使用 n 前,需要判断 n 的染色指针是否为 good,如果为 bad color,可以得知 n 的引用地址被修改过,因此需要修正 n 和 person.name 的地址,整个过程如下图:
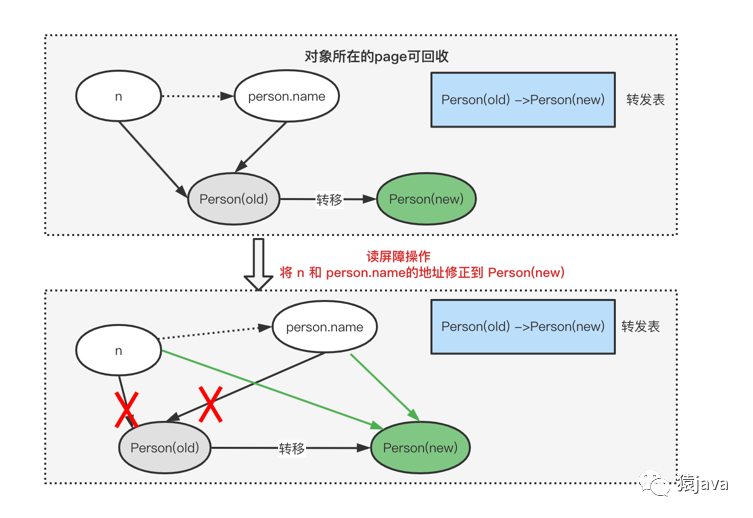
上图过程也称为"自愈",即当对象地址发生转移时,通过读屏障操作,不仅赋值的引用更改为最新值,自身引用也被修正了,整个过程看起来像自愈。
> 这里对"转移"做个解释:ZGC 是按照 Page 内存页进行垃圾回收的,也就是说当对象所在的页面需要回收时,页面里还存活的对象需要被转移到其他页。
4.7、Concurrent
Concurrent:并发,指 GC 线程和应用线程是并发执行。
和 MCS、G1 等垃圾回收器一样,ZGC 也采用了标记-复制算法,不过,ZGC 对标记-复制算法做了很大的改进,ZGC 垃圾回收周期和视图切换可以抽象成下图:
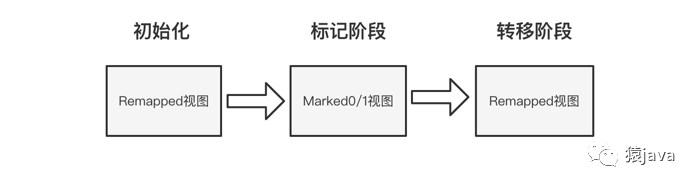
初始化阶段:ZGC 初始化之后,整个堆内存空间的地址视图被设置为 Remapped;
标记阶段:当进入标记阶段时,视图转变为 Marked0 或者 Marked1;
转移阶段:从标记阶段结束进入转移阶段时,视图再次被设置为 Remapped;
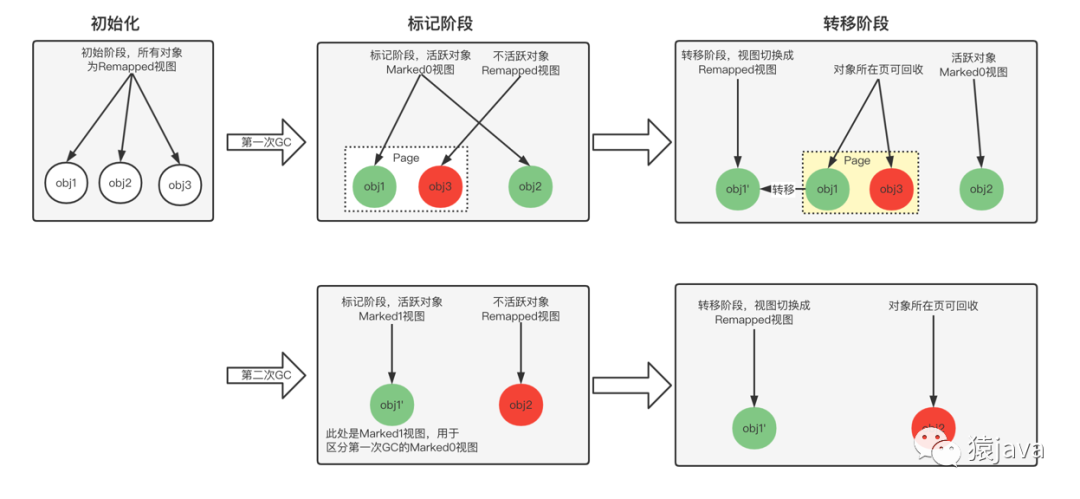
下图以 obj1,obj2,obj3 三个对象为案例对垃圾回收和视图切换进行了演示:
4.8、ZGC 全过程
ZGC 垃圾回收全过程包含:初始标记、并发标记、再标记、并发转移准备、初始转移、并发转移 6 个阶段,如下图:
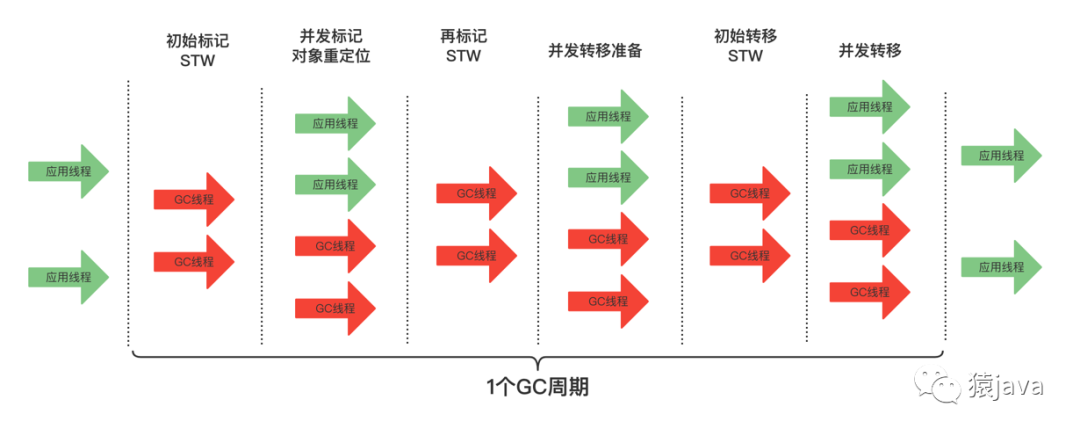
在 ZGC 全过程中,会出现 3 个 STW(Stop The World):初始标记,再标记,初始转移。尽管这 3 个阶段会 STW,但是 ZGC 对 STW 的暂停时间是有严格要求,一般是 1ms 甚至更低,下面将分别介绍各个阶段:
初始标记:这个阶段会 STW,仅标记 GC Root 直接可达的对象,压到标记栈中;
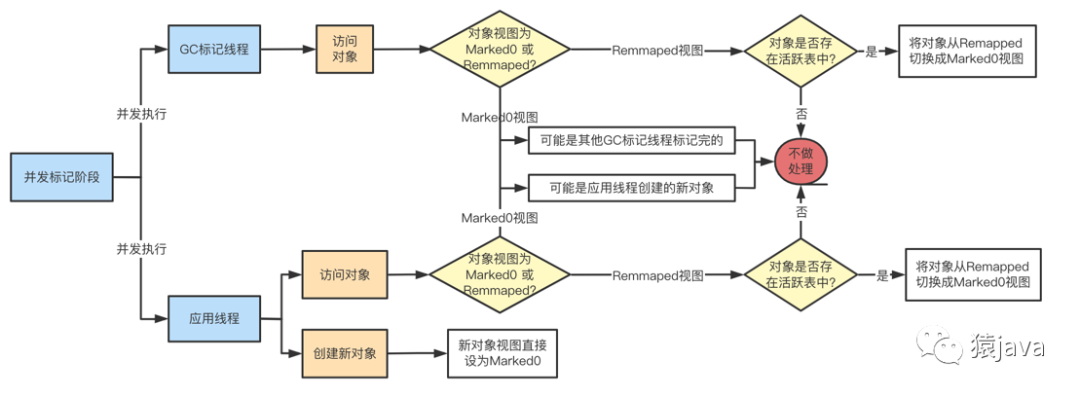
并发标记,重新定位:这个阶段,GC 线程和应用线程是并发执行的,根据初始标记的对象开始并发遍历对象图,还会统计每个 region 的存活对象的数量,具体流程如下图:
再标记:这个阶段会 STW,因为并发阶段应用线程还在运行,所以可能会修改对象的引用,导致漏标记的情况,因此,再标记阶段会标记这些漏标的对象,另外,这个阶段还会对系统字典、JVMTI、JFR、字符串表等非强根进行并行标记;
并发转移准备:为初始转移做一些前置工作;
初始转移:从 GC Root Set 集合出发,如果对象在转移的分区集合中,则在新的分区分配对象空间;
并发转移:这个阶段,GC 线程和应用线程是并发执行的,GC 线程和应用线程操作对象流程如下图:
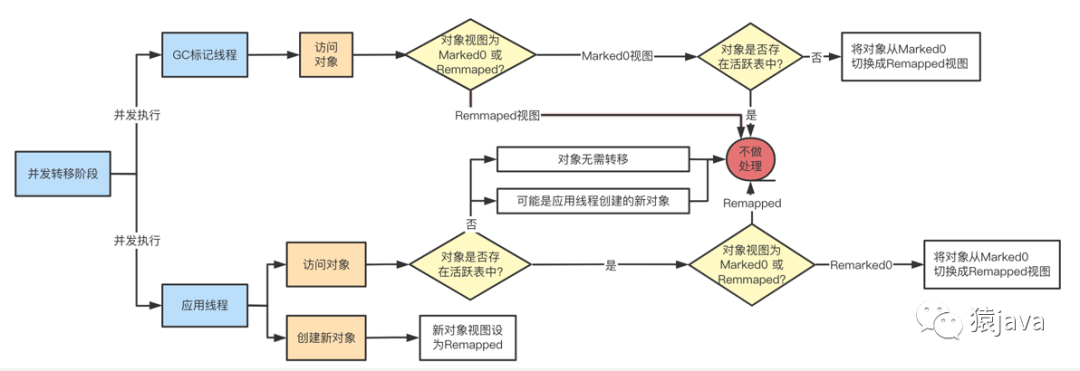
五、常见问题
为什么需要 Marked0 和 Marked1 两个标识?
简单地说是为了区别上一次标记和当前标记,因为每个 GC 周期开始时,会交换使用的 Marked 标记位,使上次 GC 周期中修正的已标记状态失效,所有引用都变成未标记。比如:GC 周期 1 使用 Marked0,则 GC 周期结束后,所有引用 Marked0 标记都会成为 01(二进制的 01 = 0);GC 周期 2 使用 Marked1,类同于周期 1,所有的 Marked 标记都会成为 10(二进制的 10 = 1)。
为什么会有 3 种内存布局?
这主要还是和 ZGC 的目标(支持 8MB-16TB 的堆)相匹配,因为 ZGC 需要支持最大 16TB Java 堆内存的垃圾回收,所以就需要用不同 bit 位数来表示,因此就出现了 3 种布局。
使用多重视图和染色指针的优点
像 CMS,G1 等垃圾回收器,GC 信息是存放在对象头中,因此每次修改对象头信息时都需要先访问内存,然后操作,而 ZGC 是把 GC 信息存放在指针的有色标记位上,修改 GC 信息时,无需任何对象访问,只需要设置地址中对应的标志位即可,因此可以加快标记和转移的速度,这也是 ZGC 在标记和转移阶段速度更快的原因。
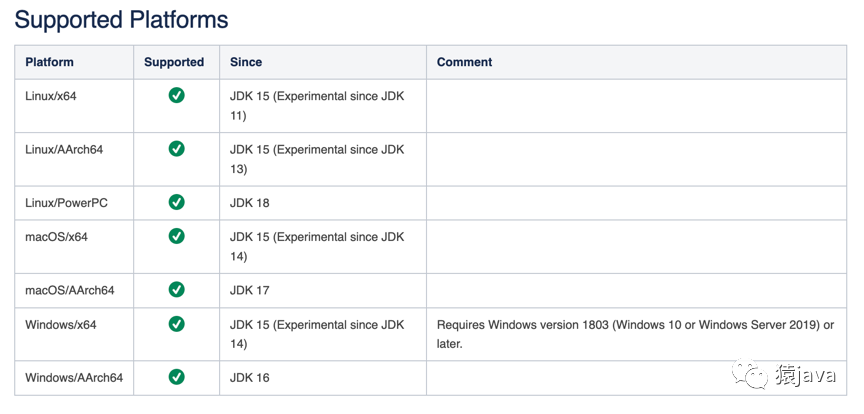
六、支持平台
下面是官方文档列举的所有支持平台:目前,ZGC 目前支持了大多数的操作系统,并且是 64 位系统。

七、重要参数
7.1、启用ZGC
-XX:+UseZGC -Xmx<size> -Xlog:gc# 或者-XX:+UseZGC -Xmx<size> -Xlog:gc*
7.2、ZGC 的 JVM选项
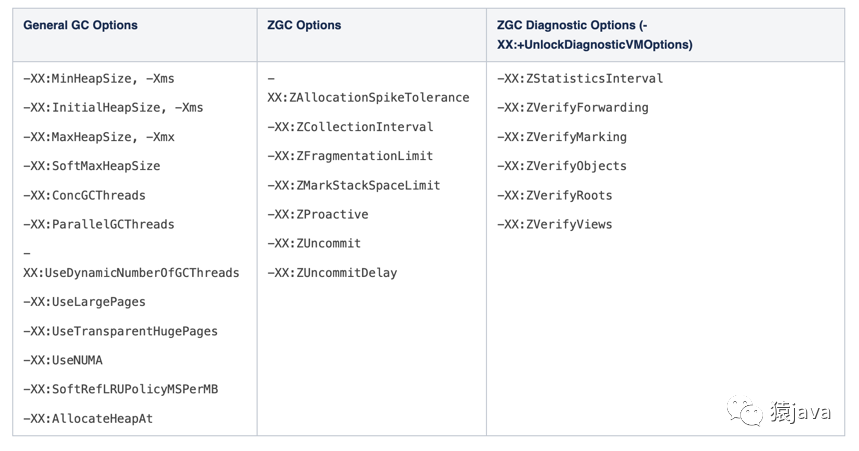
-Xms -Xmx:堆的最大内存和最小内存;
-XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize:设置 CodeCache 的大小, JIT 编译的代码都放在 CodeCache 中,一般服务 64m 或 128m;
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC:启用 ZGC 的配置;
-XX:ConcGCThreads:并发回收垃圾的线程。默认是总核数的 12.5%,8 核 CPU 默认是 1。调大后 GC 变快,但会占用程序运行时的 CPU 资源,吞吐会受到影响;
-XX:ParallelGCThreads:STW 阶段使用线程数,默认是总核数的 60%。-XX:ZCollectionInterval:ZGC 发生的最小时间间隔,单位秒;
-XX:ZAllocationSpikeTolerance:ZGC 触发自适应算法的修正系数,默认 2,数值越大,越早的触发 ZGC;
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive:是否启用主动回收,默认开启,这里的配置表示关闭;
-Xlog:设置 GC 日志中的内容、格式、位置以及每个日志的大小;
八、ZGC 发展
ZGC 最初是作为 JDK 11 中的一项实验性功能引入的,并在 JDK 15 中被宣布为 Production Ready
从 不支持类卸载 到 支持类卸载
从仅支持个别系统到支持多个平台
从不支持指针压缩,到支持压缩类指针
JDK 16 支持并发线程堆栈扫描
......
ZGC 随着 JDK 发展的更改日志如下:
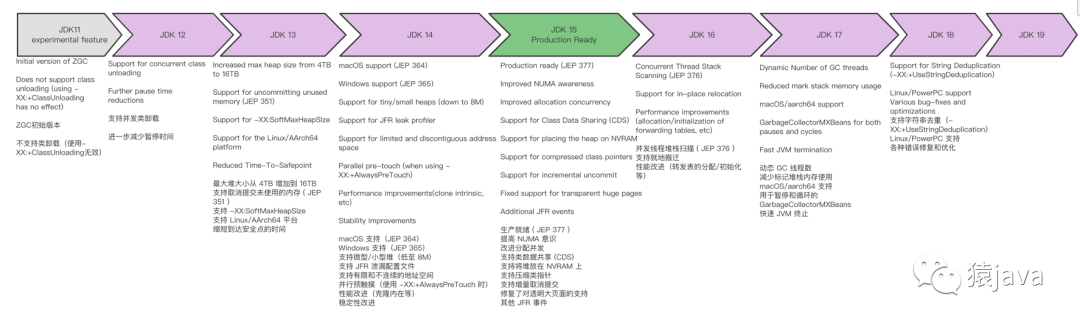
通过 ZGC 的发展可以看出:GC 垃圾回收器已经越来越智能化,GC 会自适应各种情况自动优化。
九、总结
ZGC 是一个可扩展的低延迟垃圾收集器,能够处理 TB 级别堆内存的垃圾回收;
ZGC 垃圾回收过程几乎全是并发,实际 STW 停顿时间极短;
ZGC 相对于 CMS,G1 这些垃圾回收器,最大的技术区别点是染色指针、读屏障、内存多重映射;
ZGC 和 Shenandoah、G1 一样,采用基于 Region 的堆内存分布;
对吞吐量优先的场景,ZGC 可能并不适合;
ZGC 将对象存活信息存储在染色指针中,而传统垃圾回收器将对象存活信息放在对象头中;
尽管目前大多数互联网公司,主流使用 jdk 8、jdk 11,垃圾回收器使用的是 ParNew + CMS 组合或 G1,但是,作为技术人员还是建议保持对新技术的热情;
十、鸣谢
文章总结不易,看到这里的小伙伴,感谢帮忙点赞,在读,或者转发给更多的好友,我将为你呈现更多的干货, 欢迎关注公众号:猿 java
猿java精彩文章推荐:
肝了一周,这下彻底把 MySQL的锁搞懂了
深度剖析IO多路复用机制
