







一、 pg存储结构
在pg中,磁盘存储和内存存储的最小管理单位都是块。
保存在磁盘中的数据块称为page;内存中的数据块称为buffer;表和索引称为relation;行称为tuple。
默认情况下,pg数据块大小为8k,page是pg的最小存取单位。
1. pg数据页
数据页由页头(PageHeaderData)、数据指针数组(ItemIdData)、可使用的空闲空间(Free space)、实际数据(Items)和特殊空间(Special Space)组成。
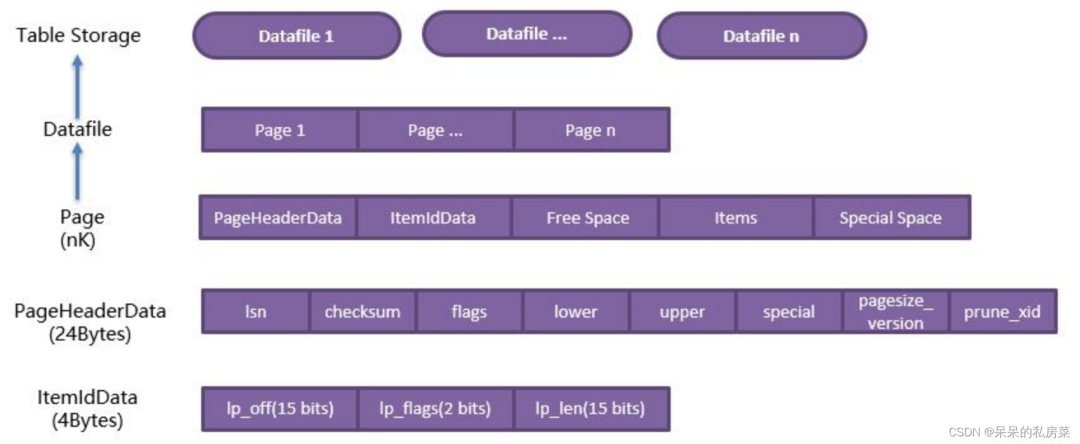
1.1 页头存储了LSN号、校验位等元数据信息,占用了24Bytes。
1.2 数据指针数组存储指向实际数据的指针。数据中的元素ItemId可理解为相应数据行在Page中的实际开始偏移。数据行指针ItemId由3部分组成,前15位为page内偏移,中间2位为标志,后面15位为长度。
1.3 空闲空间未使用可分配的空间,ItemID从空闲空间的头部开始分配,Item(数据行)从空闲空间的尾部开始分配。
1.4 实际数据未数据的行数据。
1.5 特殊空间用于存储索引访问使用的数据,不同的访问方法数据不同。
2. 页头详解
2.1 页头结构体代码
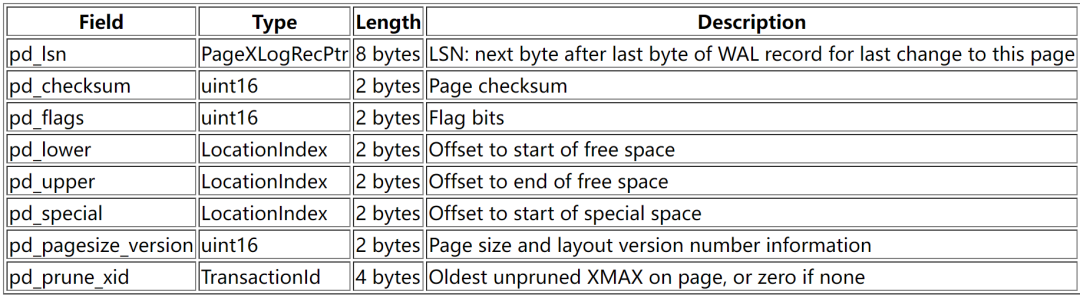
less src/include/storage/bufpage.htypedef struct PageHeaderData{/* XXX LSN is member of *any* block, not only page-organized ones */PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog* record for last change to this page */uint16 pd_checksum; /* checksum */uint16 pd_flags; /* flag bits, see below */LocationIndex pd_lower; /* offset to start of free space */LocationIndex pd_upper; /* offset to end of free space */LocationIndex pd_special; /* offset to start of special space */uint16 pd_pagesize_version;TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array */} PageHeaderData;
2.2 pg数据页存储剖析
简单介绍一下hexdump工具:
> hexdump 以 ASCII、十进制、十六进制或八进制显示文件内容。
> -s <offset>:跳过开头制定长度个字节
> -n <length>:只解析输入的指定长度个字节
psql -Upostgres-- 创建测试表和数据drop table if exists t_page;create table t_page (id int,c1 char(8),c2 varchar(16));insert into t_page values(1,'1','a');insert into t_page values(2,'2','b');insert into t_page values(3,'3','c');insert into t_page values(4,'4','d');-- 获取表对应的数据文件postgres=# select pg_relation_filepath('t_page');pg_relation_filepath----------------------base/5/16384
-- 查看表中的数据
$ hexdump -C $PGDATA/base/5/1638400000000 00 00 00 00 70 07 50 01 00 00 00 00 28 00 60 1f |....p.P.....(.`.|00000010 00 20 04 20 00 00 00 00 d8 9f 4e 00 b0 9f 4e 00 |. . ......N...N.|00000020 88 9f 4e 00 60 9f 4e 00 00 00 00 00 00 00 00 00 |..N.`.N.........|00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|*00001f60 d8 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00001f70 04 00 03 00 02 09 18 00 04 00 00 00 13 34 20 20 |.............4 |00001f80 20 20 20 20 20 05 64 00 d7 02 00 00 00 00 00 00 | .d.........|00001f90 00 00 00 00 00 00 00 00 03 00 03 00 02 09 18 00 |................|00001fa0 03 00 00 00 13 33 20 20 20 20 20 20 20 05 63 00 |.....3 .c.|00001fb0 d6 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00001fc0 02 00 03 00 02 09 18 00 02 00 00 00 13 32 20 20 |.............2 |00001fd0 20 20 20 20 20 05 62 00 d5 02 00 00 00 00 00 00 | .b.........|00001fe0 00 00 00 00 00 00 00 00 01 00 03 00 02 09 18 00 |................|00001ff0 01 00 00 00 13 31 20 20 20 20 20 20 20 05 61 00 |.....1 .a.|00002000
2.2.1 pd_lsn组成解析:
$ hexdump -C $PGDATA/base/5/16384 -s 0 -n 800000000 00 00 00 00 70 07 50 01 |....p.P.|00000008/** 数据文件的前8个bytes存储的是lsn。其中最开始的4个bytes是TimelineID,在这里是\x0000 0000组合起来LSN为0/1500770**/
2.2.2 pd_checksum(2bytes)解析
$ hexdump -C $PGDATA/base/5/16384 -s 8 -n 200000008 00 00 |..|0000000a/**checksum为\x0000**/
2.2.3 pg_flag(2bytes)
$ hexdump -C $PGDATA/base/5/16384 -s 10 -n 20000000a 00 00 |..|0000000c/**flags为\x0000**/
2.2.4 pg_lower(2bytes)
$ hexdump -C $PGDATA/base/5/16384 -s 12 -n 20000000c 28 00 |(.|0000000e/**lower为\x0028,十进制为40**/
2.2.5 pg_upper(2bytes)
hexdump -C $PGDATA/base/5/16384 -s 14 -n 20000000e 60 1f |`.|00000010/**upper为\x1f60,十进制为8032**/
2.2.6 pg_special(2bytes)
$ hexdump -C $PGDATA/base/5/16384 -s 16 -n 200000010 00 20 |. |00000012/**upper为\x2000,十进制为8192**/
2.2.7 pg_pagesize_version(2bytes)
$ hexdump -C $PGDATA/base/5/16384 -s 18 -n 200000012 04 20 |. |00000014/**pagesize_version为\x2004,十进制为8196,即版本4**/
2.2.8 pg_prune_xid(4bytes)
$ hexdump -C $PGDATA/base/5/16384 -s 20 -n 400000014 00 00 00 00 |....|00000018/**prune_xid为\x0000,即0**/
2.3 ItemIds结构体
less src/include/storage/itemid.htypedef struct ItemIdData{unsigned lp_off:15, /* offset to tuple (from start of page) */lp_flags:2, /* state of line pointer, see below */lp_len:15; /* byte length of tuple */} ItemIdData;typedef ItemIdData *ItemId;
PageHeaderData之后是ItemId数组,每个元素占用的空间是4bytes。
2.3.1 lp_off
$ hexdump -C $PGDATA/base/5/16384 -s 24 -n 200000018 d8 9f |..|0000001a/**取低15位echo $((0x9fd8 & ~$((1<<15))))8152表示第一个Item(tuple)从8152开始**/
2.3.2 lp_len
$ hexdump -C $PGDATA/base/5/16384 -s 26 -n 20000001a 4e 00 |N.|0000001c/**取高15位echo $((0x004e >> 1))39表示第一个Item(tuple)的大小为39**/
2.3.3 lp_flags
取第17-16位,01,即1
2.4 Items(tuple)结构体
每个tuple包含两部分,第一部分是tuple头部信息,第二部分是实际的数据。
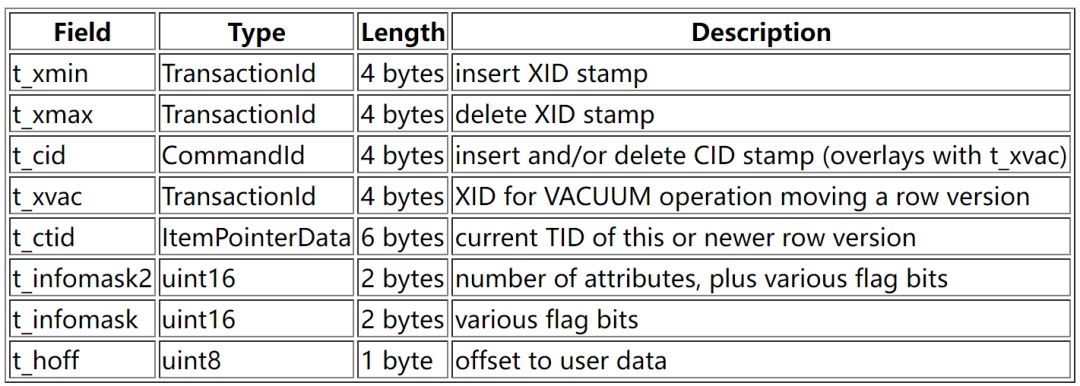
less src/include/storage/off.h/** OffsetNumber:** this is a 1-based index into the linp (ItemIdData) array in the* header of each disk page.*/typedef uint16 OffsetNumber;less src/include/storage/block.h/** BlockId:** this is a storage type for BlockNumber. in other words, this type* is used for on-disk structures (e.g., in HeapTupleData) whereas* BlockNumber is the type on which calculations are performed (e.g.,* in access method code).** there doesn't appear to be any reason to have separate types except* for the fact that BlockIds can be SHORTALIGN'd (and therefore any* structures that contains them, such as ItemPointerData, can also be* SHORTALIGN'd). this is an important consideration for reducing the* space requirements of the line pointer (ItemIdData) array on each* page and the header of each heap or index tuple, so it doesn't seem* wise to change this without good reason.*/typedef struct BlockIdData{uint16 bi_hi;uint16 bi_lo;} BlockIdData;typedef BlockIdData *BlockId; /* block identifier */less src/include/storage/itemptr.h/** ItemPointer:** This is a pointer to an item within a disk page of a known file* (for example, a cross-link from an index to its parent table).* blkid tells us which block, posid tells us which entry in the linp* (ItemIdData) array we want.** Note: because there is an item pointer in each tuple header and index* tuple header on disk, it's very important not to waste space with* structure padding bytes. The struct is designed to be six bytes long* (it contains three int16 fields) but a few compilers will pad it to* eight bytes unless coerced. We apply appropriate persuasion where* possible. If your compiler can't be made to play along, you'll waste* lots of space.*/typedef struct ItemPointerData{BlockIdData ip_blkid;OffsetNumber ip_posid;}less src/include/access/htup_details.htypedef struct HeapTupleFields{TransactionId t_xmin; /* inserting xact ID */TransactionId t_xmax; /* deleting or locking xact ID */union{CommandId t_cid; /* inserting or deleting command ID, or both */TransactionId t_xvac; /* old-style VACUUM FULL xact ID */} t_field3;} HeapTupleFields;typedef struct DatumTupleFields{int32 datum_len_; /* varlena header (do not touch directly!) */int32 datum_typmod; /* -1, or identifier of a record type */Oid datum_typeid; /* composite type OID, or RECORDOID *//** datum_typeid cannot be a domain over composite, only plain composite,* even if the datum is meant as a value of a domain-over-composite type.* This is in line with the general principle that CoerceToDomain does not* change the physical representation of the base type value.** Note: field ordering is chosen with thought that Oid might someday* widen to 64 bits.*/} DatumTupleFields;struct HeapTupleHeaderData{union{HeapTupleFields t_heap;DatumTupleFields t_datum;} t_choice;ItemPointerData t_ctid; /* current TID of this or newer tuple (or a* speculative insertion token) *//* Fields below here must match MinimalTupleData! */#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2uint16 t_infomask2; /* number of attributes + various flags */#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3uint16 t_infomask; /* various flag bits, see below */#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4uint8 t_hoff; /* sizeof header incl. bitmap, padding *//* ^ - 23 bytes - ^ */#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs *//* MORE DATA FOLLOWS AT END OF STRUCT */};
结构体展开,具体如下:
Field Type Length Offset Descriptiont_xmin TransactionId 4 bytes 0 insert XID stampt_xmax TransactionId 4 bytes 4 delete XID stampt_cid CommandId 4 bytes 8 insert and/or delete CID stamp (overlays with t_xvac)t_xvac TransactionId 4 bytes 8 XID for VACUUM operation moving a row versiont_ctid ItemPointerData 6 bytes 12 current TID of this or newer row versiont_infomask2 uint16 2 bytes 18 number of attributes, plus various flag bitst_infomask uint16 2 bytes 20 various flag bitst_hoff uint8 1 byte 22 offset to user data//注意:t_cid和t_xvac为联合体,共用存储空间
2.5 Items(tuple)存储剖析
2.5.1 t_xmin
$ hexdump -C $PGDATA/base/5/16384 -s 8152 -n 400001fd8 d5 02 00 00 |....|00001fdc$ echo $((0x000002d5))725/**第一个tuple的偏移为8152,所以从8152开始检索**/
2.5.2 t_xmax
$ hexdump -C $PGDATA/base/5/16384 -s 8156 -n 400001fdc 00 00 00 00 |....|00001fe0
2.5.3 t_cid/t_xvac
$ hexdump -C $PGDATA/base/5/16384 -s 8164 -n 600001fe4 00 00 00 00 01 00 |......|00001fea
2.5.4 t_ctid
hexdump -C $PGDATA/base/5/16384 -s 8170 -n 200001fea 03 00 |..|00001fec
2.5.5 t_infomask2
$ hexdump -C $PGDATA/base/5/16384 -s 8172 -n 200001fdc 00 00 00 00 |....|00001fe0
2.5.5 t_infomask
$ hexdump -C $PGDATA/base/5/16384 -s 8172 -n 200001fec 02 09 |..|00001fee
2.5.5 t_hoff
$ hexdump -C $PGDATA/base/5/16384 -s 8174 -n 100001fee 18 |.|00001fef$ echo $((0x18))24/**用户数据开始偏移为24,用户数据偏移为8152+24=8176**/
2.6 tuple存储剖析
上述是tuple的头部数据,接下来我们看看实际存储的数据。
tuple的总长度(lp_len)为39,计算得到数据大小为:39-24=15
$ hexdump -C $PGDATA/base/5/16384 -s 8176 -n 1500001ff0 01 00 00 00 13 31 20 20 20 20 20 20 20 05 61 |.....1 .a|00001fff/**表结构:create table t_page (id int,c1 char(8),c2 varchar(16));第1个字段为int,第2个字段为定长字符,第3个字段为变长字符。对应的数据为:id=\x00000001c1=\x133120202020202020注:字符串无需高低位切换,\x13是标志位,ASCII码31是字符'1';c2=\x0561注:字符串,第1个字节\x05是标志位,ASCII码61是字符'a'**/
3. pageinspect插件使用
pageinspect 提供了各种函数可用来快速方便的查看page中的内容。
3.1 安装指南
# 进入pg源码安装包解压目录cd contrib/pageinspectmake && make install
3.2 使用指南
psql -Upostgrespostgres=# create extension pageinspect;-- 查看page headerpostgres=# \xpostgres=# SELECT * FROM page_header(get_raw_page('t_page', 0));-[ RECORD 1 ]--------lsn | 0/1500770checksum | 0flags | 0lower | 40upper | 8032special | 8192pagesize | 8192version | 4prune_xid | 0-- 查看itempostgres=# select * from heap_page_items(get_raw_page('t_page',0));lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+----------------------------------1 | 8152 | 1 | 39 | 725 | 0 | 0 | (0,1) | 3 | 2306 | 24 | | | \x0100000013312020202020202005612 | 8112 | 1 | 39 | 726 | 0 | 0 | (0,2) | 3 | 2306 | 24 | | | \x0200000013322020202020202005623 | 8072 | 1 | 39 | 727 | 0 | 0 | (0,3) | 3 | 2306 | 24 | | | \x0300000013332020202020202005634 | 8032 | 1 | 39 | 728 | 0 | 0 | (0,4) | 3 | 2306 | 24 | | | \x040000001334202020202020200564(4 rows)-- 查看page中的raw内容postgres=# \xpostgres=# select * from get_raw_page('t_new', 0);
4. 文末总结
本文介绍postgresql页存储结构,我们可以观察到,pg为了进行实际的数据查询和mvcc等机制,添加了很多的信息去做记录,实际占用的空间比实际的数据大很多。如果使用列式存储可以有效的压缩空间。
