





本文基于 Curve 块存储v1.2.4版本,将 Curve 部署在 nvme 磁盘上,对比 Ceph 在同样环境下的性能,让大家对 Curve 在 nvme 环境下的性能有直观的了解。
测试从一下几个方面来测试,主要分为单卷测试和多卷测试:
单卷 4k 随机写测试
采用不同的 iodepth 从1,4,16,64,128,256测试单卷场景在不同 io 深度下的性能;
单卷 512k 顺序写测试
采用不同的 iodepth 从1,4,16,64,128,256测试单卷场景在不同 io 深度下的性能;
单卷 4k 随机读测试
采用不同的 iodepth 从1,4,16,64,128,256测试单卷场景在不同 io 深度下的性能;
单卷 512k 顺序读测试
多卷 4k 随机写测试
多卷 512k 顺序写测试
多卷 4k 随机读测试
多卷 512k 顺序读测试
采用三个 client 节点,每个节点五个卷,打满后端瓶颈的情况下,对比 Curve 块存储和 Ceph 的后端性能;
Curve 是云原生计算基金会 (CNCF) Sandbox 项目,是网易主导自研和开源的高性能、易运维、云原生的分布式存储系统,由块存储 CurveBS 和文件系统 CurveFS 两部分组成。
本次测试采用浪潮服务器 SA5112M6,磁盘采用三个节点每个节点八块浪潮 INSPUR-NS8610G1U320 nvme 进行测试,该 nvme ssd 具有极高的性能 (实测单盘性能 4k 随机写 IOPS 高达 240k,512k 顺序写极限带宽 3440MiB/s)。目前使用 Curve 集群测试下来,尚不能完全发挥该 nvme 盘的性能(CPU与网卡瓶颈),见下文测试结果。具体环境信息如下:
版本和软件配置信息:
| 版本信息 | Curve 块存储 | Ceph |
| 版本 | v1.2.4 | v16.2.9 |
| 副本数 | 3 | 3 |
| 故障域 | 故障域 | 故障域 |
| pg/copyset数量 | 每块盘 1个chunkserver, 每chunkserver 100个copyset | 每块盘 4个osd, 每osd 100个pg |
Curve 块存储
1
[global] 2
ioengine=cbd 3
rw=randwrite 4
bs=4k 5
iodepth=128 6
group_reporting 7
numjobs=1 8
runtime=300 9
size=1024G 10
11
[vol00] 12
cbd=/test0
Ceph
1
[global] 2
ioengine=rbd 3
clientname=admin 4
pool=rbd 5
rw=randwrite 6
bs=4k 7
iodepth=128 8
group_reporting 9
numjobs=1 10
runtime=300 11
size=1024G 12
13
[vol00] 14
rbdname=vol00
特别的,Curve 端的测试采用 Curve cbd engine,我们 fork 了axboe/fio 并对接 Curve client sdk 即 curve cbd engine,该仓库在 opencurve/fio②。
此外,Curve 块存储支持条带化卷,因此我们还测试了 Curve 使用条带情况下的性能,其中的条带卷参数和条带化卷创建命令如下:
curve create --filename /test0 --length 1024 --user test --stripeUnit 65536 --stripeCount 64
另外,对于单卷和多卷读的测试,在进行读之前,需要对卷进行一遍预写,将卷写满,否则测试数据将因为 client 直接返回 0 而导致性能不准,这一操作 Curve参考脚本如下:
sudo ./fio_ --ioengine=cbd --cbd=/test0 --size=1024G --bs=1M --direct=1 --group_reporting --time_based --rw=write --iodepth=512 --numjobs=1 -name=fu
单卷测试
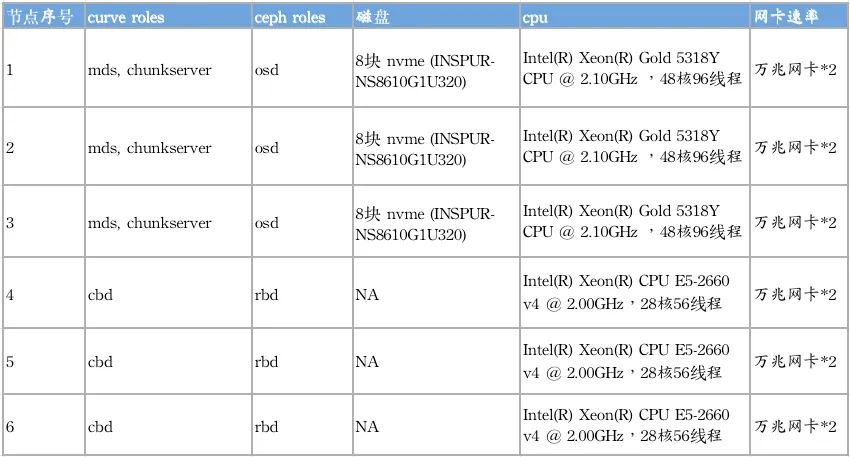
单卷 4k 随机写测试:
| 场景 | Ceph | Curve | Curve strip |
QD 1 | IOPS=1000, BW=4000KiB/s, lat=996.87usec | IOPS=2321, BW=9285KiB/s, lat=428.92usec | IOPS=2009, BW=8037KiB/s, lat=494.42usec |
| QD 4 | IOPS=4317, BW=16.9MiB/s, lat=924.40usec | IOPS=8669, BW=33.9MiB/s, lat=458.39usec | IOPS=8584, BW=33.5MiB/s, lat=462.64usec |
| QD 16 | IOPS=18.1k, BW=70.7MiB/s, lat=882.09usec | IOPS=34.7k, BW=136MiB/s, lat=458.78usec | IOPS=38.2k, BW=149MiB/s, lat=418.33usec |
| QD 64 | IOPS=53.7k, BW=210MiB/s, lat=1190.28usec | IOPS=108k, BW=422MiB/s, lat=585.26usec | IOPS=117k, BW=456MiB/s, lat=542.19usec |
| QD 128 | IOPS=72.1k, BW=282MiB/s, lat=1774.42usec | IOPS=163k, BW=636MiB/s, lat=766.66usec | IOPS=182k, BW=712MiB/s, lat=684.20usec |
| QD 256 | IOPS=78.1k, BW=305MiB/s, lat=3277.41usec | IOPS=207k, BW=810MiB/s, lat=1169.62usec | IOPS=249k, BW=974MiB/s, lat=984.96usec |
对比 Curve 与 Ceph的单卷小 IO 随机写性能来看,Curve 的性能远优于于Ceph 的性能(QD256时,达到约319%);
从 QD1 的时延来看 Curve 的单路时延仅 Ceph 的50%。
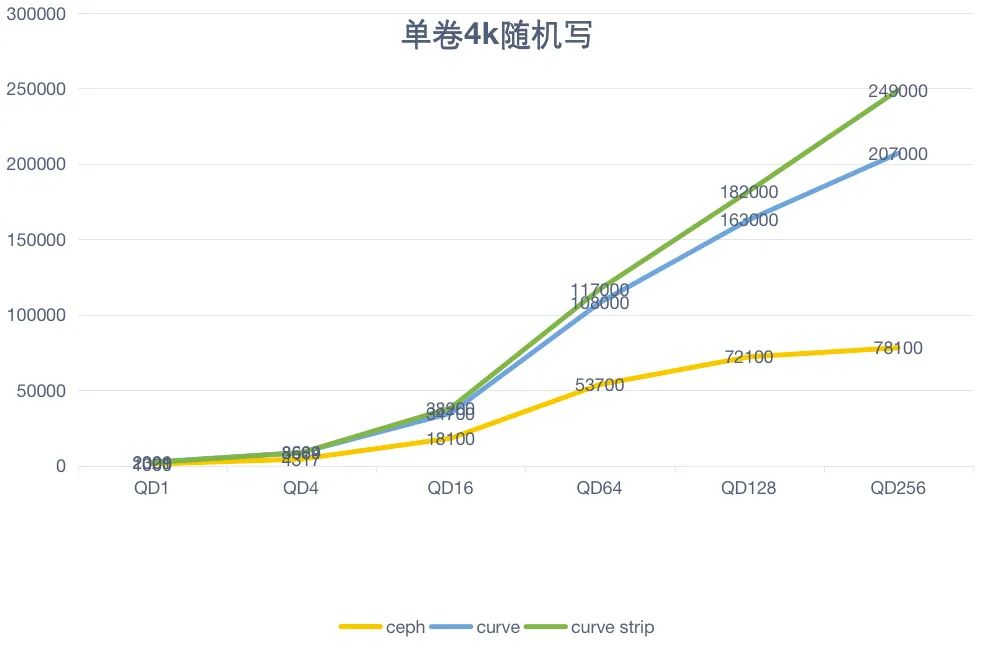
单卷 512K 顺序写测试:
| 场景 | Ceph | Curve | Curve strip |
QD 1 | IOPS=364, BW=182MiB/s, lat=2739.13usec | IOPS=323, BW=162MiB/s, lat=3090.33usec | IOPS=662, BW=331MiB/s, lat=1507.51usec |
QD 4 | IOPS=641, BW=321MiB/s, lat=6.23msec | IOPS=620, BW=310MiB/s, lat=6440.37usec | IOPS=2014, BW=1007MiB/s, lat=1982.36usec |
QD 16 | IOPS=1173, BW=587MiB/s, lat=13.63msec | IOPS=984, BW=492MiB/s, lat=16.25msec | IOPS=2496, BW=1248MiB/s, lat=6401.58usec |
QD 64 | IOPS=2176, BW=1088MiB/s, lat=29.40msec | IOPS=2069, BW=1035MiB/s, lat=30.92msec | IOPS=2554, BW=1277MiB/s, lat=25038.46usec |
QD 128 | IOPS=2881, BW=1441MiB/s, lat=44.41msec | IOPS=2433, BW=1217MiB/s, lat=52.60msec | IOPS=2712, BW=1356MiB/s, lat=47180.80usec |
Curve 在单卷大 IO 顺序写的场景下,具有和 Ceph 相当的性能;
特别地,当 Curve 采用条带化卷之后,可以显著的改善Curve大IO顺序写场景下的性能;
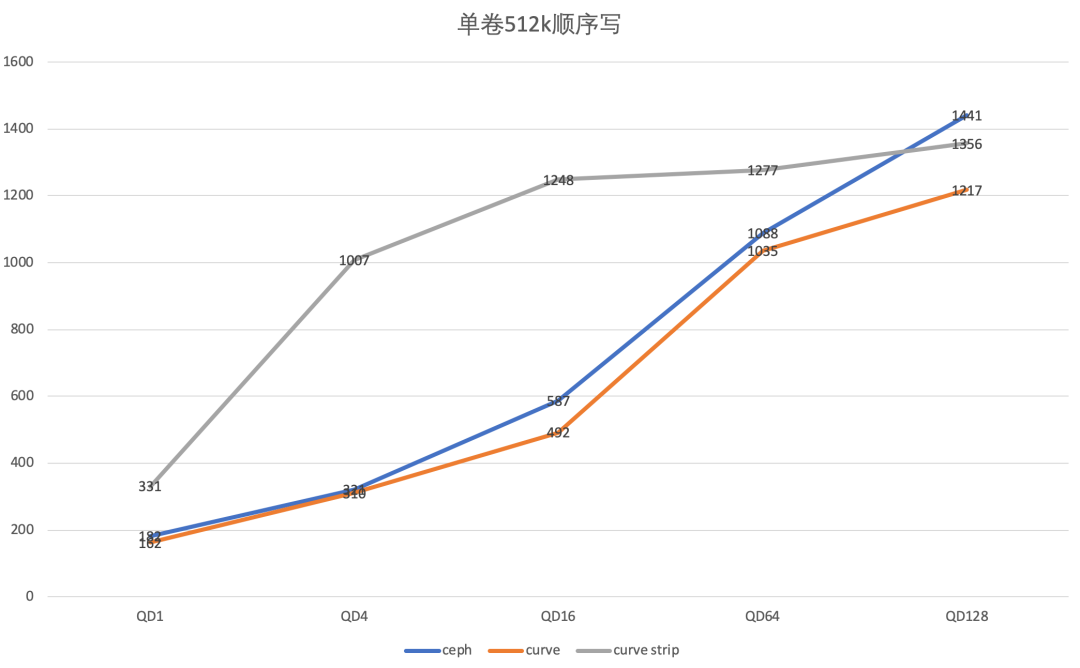
| 场景 | Ceph | Curve | Curve strip |
QD 1 | IOPS=2037, BW=8150KiB/s, lat=487.87usec | IOPS=2431, BW=9725KiB/s, lat=408.19usec | IOPS=2589, BW=10.1MiB/s, lat=382.94usec |
QD 4 | IOPS=12.8k, BW=49.9MiB/s, lat=311.56usec | IOPS=14.7k, BW=57.5MiB/s, lat=268.90usec | IOPS=15.6k, BW=61.0MiB/s, lat=255.32usec |
QD 16 | IOPS=59.8k, BW=234MiB/s, lat=266.66usec | IOPS=66.5k, BW=260MiB/s, lat=237.38usec | IOPS=64.1k, BW=251MiB/s, lat=248.35usec |
QD 64 | IOPS=102k, BW=400MiB/s, lat=624.32usec | IOPS=193k, BW=755MiB/s, lat=319.45usec | IOPS=186k, BW=728MiB/s, lat=332.42usec |
QD 128 | IOPS=117k, BW=456MiB/s, lat=1096.71usec | IOPS=295k, BW=1153MiB/s, lat=397.94usec | IOPS=287k, BW=1120MiB/s, lat=414.80usec |
QD 256 | IOPS=130k, BW=507MiB/s, lat=1972.56usec | IOPS=346k, BW=1352MiB/s, lat=608.82usec | IOPS=345k, BW=1348MiB/s, lat=619.54usec |
Curve相比于ceph在单卷小IO随机读的场景下,具有明显优于ceph的性能(QD256时,达到266%)
| 场景 | Ceph | Curve | Curve strip |
QD 1 | IOPS=803, BW=402MiB/s, lat=1242.86usec | IOPS=887, BW=444MiB/s, lat=1123.94usec | IOPS=1026, BW=513MiB/s, lat=971.74usec |
QD 4 | IOPS=1797, BW=899MiB/s, lat=2223.36usec | IOPS=1670, BW=835MiB/s, lat=2392.38usec | IOPS=3147, BW=1574MiB/s, lat=1269.30usec |
QD 16 | IOPS=2915, BW=1458MiB/s, lat=5486.64usec | IOPS=2274, BW=1137MiB/s, lat=7031.62usec | IOPS=3553, BW=1777MiB/s, lat=4501.20usec |
QD 64 | IOPS=3772, BW=1886MiB/s, lat=16962.46usec | IOPS=3331, BW=1666MiB/s, lat=19206.90usec | IOPS=3190, BW=1595MiB/s, lat=20060.72usec |
QD 128 | IOPS=4058, BW=2029MiB/s, lat=31538.63usec | IOPS=3641, BW=1821MiB/s, lat=35152.30usec | IOPS=3585, BW=1793MiB/s, lat=35700.42usec |
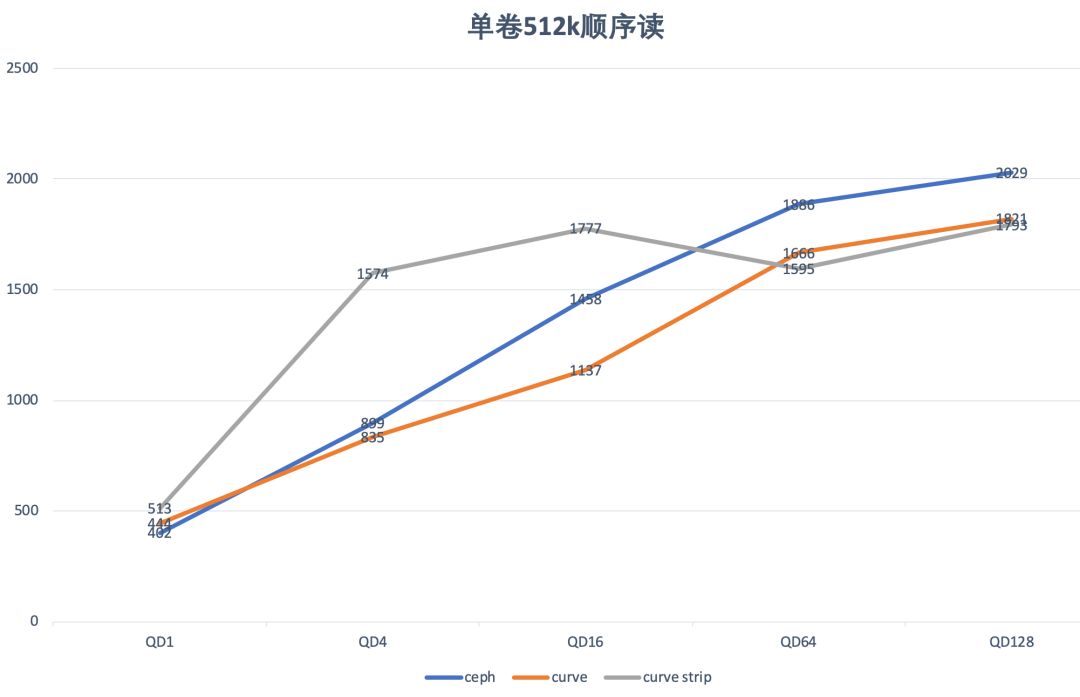
在单卷大IO顺序读的场景下,Curve与cpeh性能相当,同样时延条带化之后,Curve的大IO顺序读场景下的带宽有明显改善。
多卷测试
| 项目 | Ceph | Curve |
| 压力 | 3个client节点, 每个节点5个卷, iodepth=128, jobs=5 后端cpu到达瓶颈 | 3个client节点, 每个节点5个卷, iodepth=128,jobs=1 后端cpu到达瓶颈 |
client 1 | IOPS=60.3k, BW=236MiB/s, lat=52941.41usec | IOPS=93.6k, BW=365MiB/s, lat=6834.90usec |
client 2 | IOPS=59.6k, BW=233MiB/s, lat=53602.44usec | IOPS=102k, BW=400MiB/s, lat=6252.65usec |
client 3 | IOPS=61.6k, BW=240MiB/s, lat=51957.89usec | IOPS=104k, BW=404MiB/s, lat=6178.87usec |
总 IOPS | 60.3k + 59.6k + 61.6k = 181.5k | 93.6k + 102k + 104k = 299.6k |
| 项目 | Ceph | Curve |
| 压力 | 3个client节点, 每个节点5个卷, iodepth=128, jobs=5 网卡带宽到达瓶颈 | 3个client节点, 每个节点5个卷, iodepth=128,jobs=1 网卡带宽到达瓶颈 |
client 1 | IOPS=174k, BW=678MiB/s, lat=18397.87usec | IOPS=174k, BW=681MiB/s, lat=3664.51usec |
client 2 | IOPS=181k, BW=707MiB/s, lat=17671.66usec | IOPS=175k, BW=683MiB/s, lat=3654,34usec |
client 3 | IOPS=182k, BW=711MiB/s, lat=17563.53usec | IOPS=165k, BW=643MiB/s, lat=3881.90usec |
总 IOPS | 174k + 181k +182k = 537k | 174k + 175k + 165k = 514k |
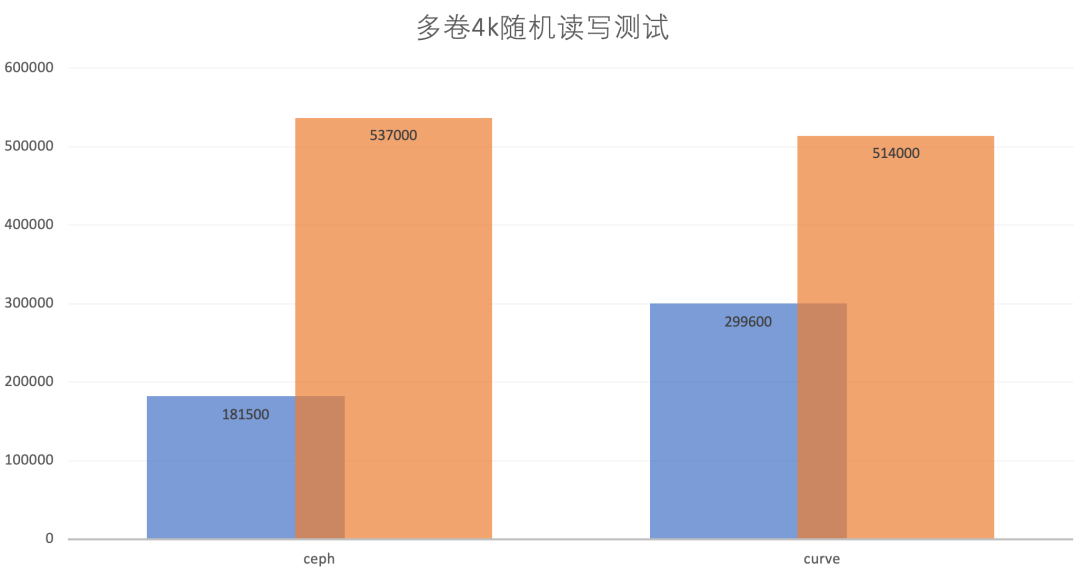
从多卷小IO的随机读写测试来看:
小 IO 随机写 Ceph 比 Curve 先到达 CPU 性能瓶颈,因此 Curve 更能发挥后端的性能,总体性能方面,IOPS 也比 Ceph 好约165%;
小 IO 随机读 Ceph 也比 Curve 先到达网卡的瓶颈,在对 Ceph 继续增加压力(jobs加到5)之后,两者后端性能相当,总的来说,Curve 的性能应当也是好于 Ceph。
| 项目 | Ceph | Curve |
| 压力 | 3个client节点, 每个节点5个卷, iodepth=128, jobs=1 网卡带宽到达瓶颈 | 3个client节点, 每个节点5个卷, iodepth=128,jobs=1 网卡带宽到达瓶颈 |
client 1 | IOPS=1342, BW=671MiB/s, lat=476.29msec | IOPS=1116, BW=558MiB/s, lat=572.66msec |
client 2 | IOPS=1469, BW=735MiB/s, lat=435.39msec | IOPS=1189, BW=595MiB/s, lat=537.78msec |
client 3 | IOPS=1446, BW=723MiB/s, lat=442.27msec | IOPS=971, BW=486MiB/s, lat=658.50msec |
总 IOPS | (671+735+723)MiB/s = 2129MiB/s | (558+595+486)MiB/s = 1639MiB/s |
| 项目 | Ceph | Curve |
| 压力 | 3个client节点, 每个节点5个卷, iodepth=128, jobs=1 网卡带宽到达瓶颈 | 3个client节点, 每个节点5个卷, iodepth=128,jobs=1 网卡带宽到达瓶颈 |
client 1 | IOPS=1430, BW=715MiB/s, lat=446189.58usec | IOPS=1315, BW=658MiB/s, lat=486020.15usec |
client 2 | IOPS=1410, BW=705MiB/s, lat=453272.51usec | IOPS=1340, BW=652MiB/s, lat=490656.79usec |
client 3 | IOPS=1447, BW=724MiB/s, lat=441968.15usec | IOPS=1315, BW=658MiB/s, lat=486358.49usec |
总 IOPS | (715+705+724)MiB/s = 2144MiB/s | (658+652+658)MiB/s = 1968MiB/s |
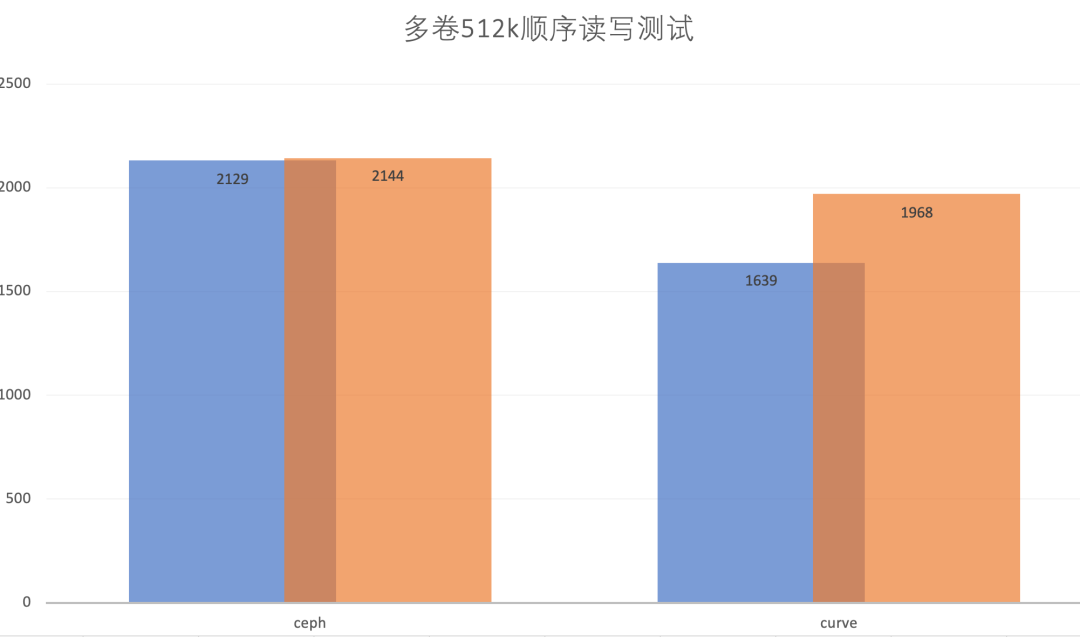
从多卷大IO的顺序读写来看,Curve 和 Ceph 的性能基本相当。
后记
上述测试中,无论是 Curve 还是 Ceph 均不能完全发挥 nvme ssd 的性能。目前 Ceph 已经支持使用 spdk 访问 nvme ssd,性能也有较大提升。Curve 支持spdk 的版本正在开发中,待相关版本发布后,再与 Ceph 的 spdk 版本对比,敬请期待。
<原创作者:许超杰,Curve Contributor>

关于 Curve
Curve 亦可作为云存储中间件使用 S3 兼容的对象存储作为数据存储引擎,为公有云用户提供高性价比的共享文件存储。
GitHub:https://github.com/opencurve/curve 官网:https://opencurve.io/ 用户论坛:https://ask.opencurve.io/ 微信群:请扫描添加或搜索群助手微信号 OpenCurve_bot 
