本期的几个问答如下:
- 备份被卡住的原因
- 为什么pg_is_in_backup()函数消失了
- 通俗理解backend_xid和backend_xmin
- 多行查询优雅的使用COPY
- 非UTF-8编码的数据库生成随机汉字示例
- pg_surgery插件的用途
Q1. 使用pg_basebackup工具或者调用pg_start_backup函数时,好像被卡住,这是什么原因?
问题描述
使用pg_basebackup工具进行基础备份或者调用pg_start_backup备份开始函数后,好像立刻被阻塞住了。或者是说为什么基础备份需要执行的checkpoint较慢,而手工在数据库发起checkpoint能很快执行完成。
问题解答
因为基础备份需要伴随一次checkpoint操作,默认的spread模式会等待定期的checkpoint调度完成,这可能会需要较长的时间(受checkpoint_completion_target以及max_wal_size配置的影响),好处是减少checkpoint带来的大量刷脏,从而减少抖动。
坏处是checkpoint操作被拉长。当我们想要快速完成备份,则可以使用fast模式立即执行checkpoint,全速刷脏。好处是快,坏处是如果脏页特别多,可能会有大量IO影响其他会话性能。
pg_basebackup可以使用"–checkpoint=fast",pg_start_backup函数可以使用fast=true来快速完成尽快完成checkpoint操作。
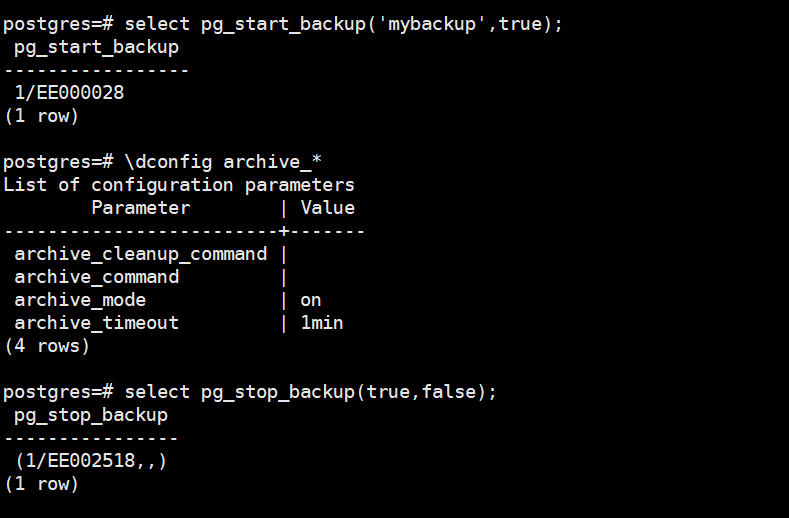
还有一个相关问题是当我们打开了归档archive_mode=on,但归档命令没有配置正确,例如archive_command配置为空,则调用备份结束函数会一直提示如下告警信息:
NOTICE: base backup done, waiting for required WAL segments to be archived
WARNING: still waiting for all required WAL segments to be archived (60 seconds elapsed)
HINT: Check that your archive_command is executing properly. You can safely cancel this backup, but the database backup will not be usable without all the WAL segments.
...
将archive_command配置正确或关闭归档即可,下面是归档配置正确后正常的输出。

不过即使archive_mode设置为on,归档命令没有配置正确,我们也可以在备份结束函数里设置wait_for_archive为false来完成备份,测试截图如下:
Q2. repmgr执行switchover时为什么提示pg_is_in_backup()函数不存在?
问题描述
使用repmgr 5.3.1对PG 15执行switchover时提示pg_is_in_backup()函数不存在,错误截图如下:
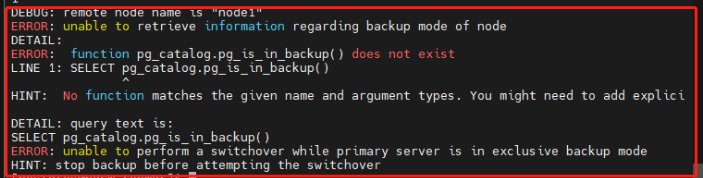
问题解答
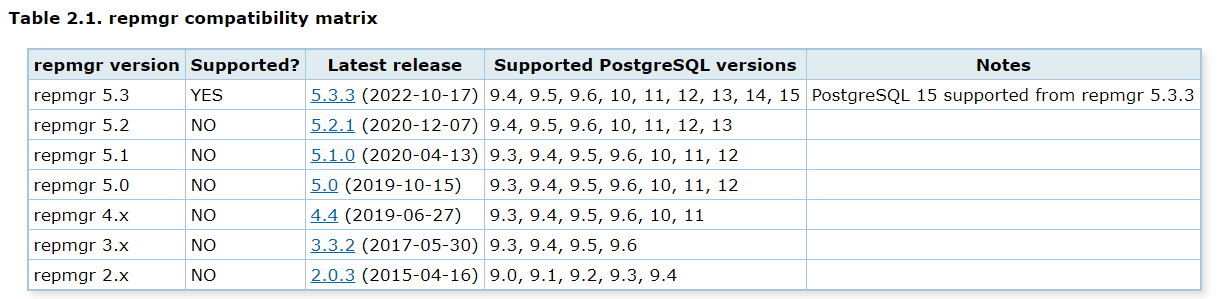
从PG 15开始,与排他性备份模式相关的pg_is_in_backup()函数已经被废弃删除了。我们查看repmgr对PG的版本支持情况可以看到repmgr 5.3.3开始支持PG 15。
Q3. pg_stat_activity视图backend_xid和backend_xmin有啥区别?
问题描述
pg_stat_activity视图的backend_xid和backend_xmin官方文档的解释看不明白,如何用大白话解释。
问题解答
从名称的差异来体会:
- backend_xid表示是当前获取到的事务ID,只有查询语句实际对数据库有修改操作时事务管理器才分配生成。
- backend_xmin与事务快照相关,借助事务快照,PG可以确定元组可见性,生产环境应主要关注backend_xmin。
事务快照形式:
xmin:xmax:xip_list
- xmin: “visible since”,活动事务的最旧事务ID。
- xmax: “visible until”,活动事务的最新事务ID。
- xip_list: 所有活动事务ID列表。
Q4. 多行查询如何在COPY中优雅的使用
问题描述
使用元命令\copy处理较长的复杂查询语句生成的结果集时,要么我们借助临时表,要么我们需要对多行语句进行编辑,调整到一行,这件事非常头疼的!
问题解答
其实我们还有这种方式:
postgres=# copy (
select *
from foo
where id<300
) to stdout with csv header \g foo.csv
COPY 5
- 虽然\copy不支持多行查询,但copy支持。
- copy结果除了输出到文件也可输出到标准输出stdout
- 使用\g将标准输出的内容写入到本地文件
结合这三点,可以优雅的处理多行查询。
Q5. 非UTF-8编码的数据库如何生成随机汉字?
问题描述
在UTF-8编码的数据库里可以使用chr函数基于unicode码来随机生成汉字:
postgres=# select chr(int4(random()*20901)+19968);
chr
-----
盾
(1 row)
而非UTF-8编码的数据库则不能使用chr函数。
问题解答
例如在euc_cn编码的环境下我可以根据GBK的区位码规则封装如下函数来生成随机汉字:
create or replace function chr_euc_cn()
returns text
as $function$
declare
hight_pos text;
low_pos text;
begin
hight_pos = to_hex((176+random()*71)::int4);
low_pos = to_hex((161+random()*93)::int4);
return convert_from(decode(hight_pos||low_pos, 'hex'), 'euc_cn');
end;
$function$ language plpgsql;
测试结果如下:
db_chinese=# select chr_euc_cn();
chr_euc_cn
------------
茏
(1 row)
db_chinese=# select chr_euc_cn();
chr_euc_cn
------------
括
(1 row)
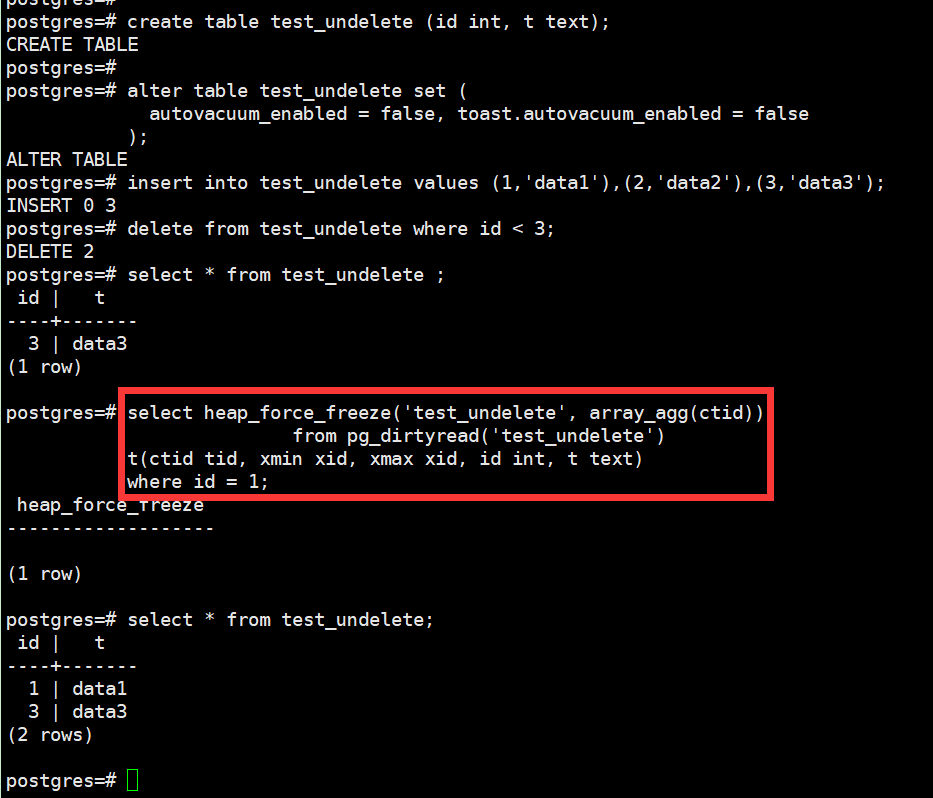
Q6. PG 14的pg_surgery插件有什么用途?
有客户想了解PG 14有什么新增的扩展插件,有什么用途。查看了一下官方文档及资料,先总结了一张最新的各版本新增插件图。
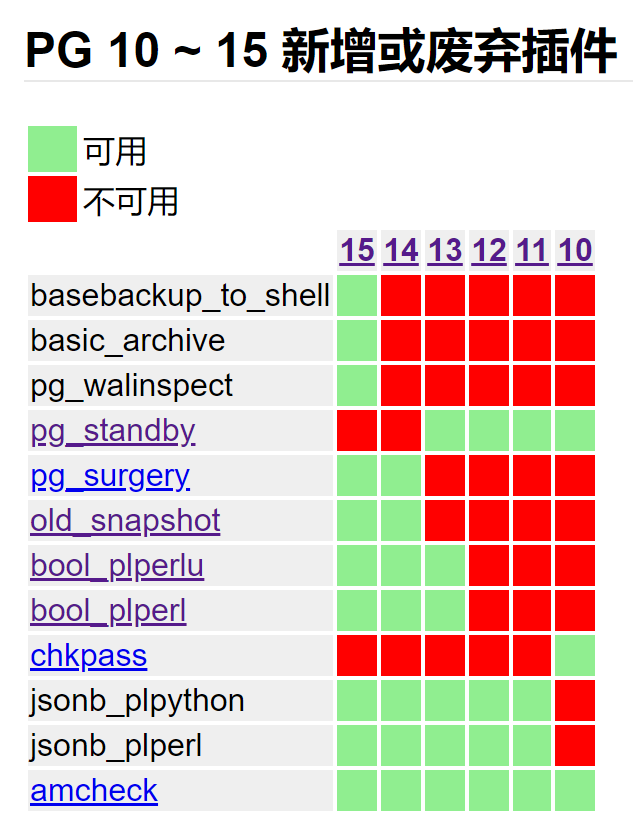
关注到pg_surgery可以与pg_dirtyread很好的搭配起来恢复delete的数据。
下面是参考示例: