




11_PostgreSQL checkpoint详解
什么是checkpoint
由于WAL结构的引入,PAGE的最新版本在内存中,变更记录存储在WAL,当os crash时,需要应用从db上次启动后的所有WAL进行一致性恢复,数据库是企业最核心的数字资产,对稳定性要求极高,数月/年都不会重启,所以以上实现机制存在以下问题: 问题一、os crash时,需要应用从db上次启动后的所有WAL进行一致性恢复,恢复时间较长,即RTO(Recovery Time Objective)较大。 问题二、由于数据库数月/年都不会重启,从上次启动后所产生的WAL文件可能非常多,占用OS层存储的资源较多。为了解决以上两个问题,引入了checkpoint机制,定期/特定事件触发执行: 问题一(解决方案)、在WAL中记录一个事务时间点,在该时间点之前所有dirty page(脏块/变更page)都进行落盘操作,由于dirty page已经落盘,OS crash时,只需要应用checkpoint之后的WAL进行一致性恢复。 问题二(解决方案)、只需要应用checkpoint之后的WAL进行一致性恢复,该时间点之前的所有WAL文件可以被数据库删除或重复利用。
官方文档解释如下,

checkpoint触发条件
/*
* OR-able request flag bits for checkpoints. The "cause" bits are used only
* for logging purposes. Note: the flags must be defined so that it's
* sensible to OR together request flags arising from different requestors.
*/
/* These directly affect the behavior of CreateCheckPoint and subsidiaries */
#define CHECKPOINT_IS_SHUTDOWN 0x0001 /* Checkpoint is for shutdown */
#define CHECKPOINT_END_OF_RECOVERY 0x0002 /* Like shutdown checkpoint, but
* issued at end of WAL recovery */
#define CHECKPOINT_IMMEDIATE 0x0004 /* Do it without delays */
#define CHECKPOINT_FORCE 0x0008 /* Force even if no activity */
#define CHECKPOINT_FLUSH_ALL 0x0010 /* Flush all pages, including those
* belonging to unlogged tables */
/* These are important to RequestCheckpoint */
#define CHECKPOINT_WAIT 0x0020 /* Wait for completion */
#define CHECKPOINT_REQUESTED 0x0040 /* Checkpoint request has been made */
/* These indicate the cause of a checkpoint request */
#define CHECKPOINT_CAUSE_XLOG 0x0080 /* XLOG consumption */
#define CHECKPOINT_CAUSE_TIME 0x0100 /* Elapsed time */
/*
* Flag bits for the record being inserted, set using XLogSetRecordFlags().
*/
#define XLOG_INCLUDE_ORIGIN 0x01 /* include the replication origin */
#define XLOG_MARK_UNIMPORTANT 0x02 /* record not important for durability */
在server log中记录checkpoint信息
#当log_checkpoints=on时,pglog会记录checkpoint过程。
官方解释:
log_checkpoints (boolean)
Causes checkpoints and restartpoints to be logged in the server log. Some statistics are included in the log messages, including the number of buffers written and the time spent writing them. This parameter can only be set in the postgresql.conf file or on the server command line. The default is on.
checkpoint触发条件模拟
模拟CHECKPOINT_IS_SHUTDOWN
postgres=# create table t1(a1 varchar); postgres=# insert into t1 select n from generate_series(1,10000) as n; postgres=# \q [postgres@pgsql ~]$ pg_ctl stop -m fast

模拟CHECKPOINT_END_OF_RECOVERY
postgres=# insert into t1 select n from generate_series(1,10000) as n; postgres=# \q [postgres@pgsql ~]$ pg_ctl stop -m immediate [postgres@pgsql ~]$ pg_ctl start
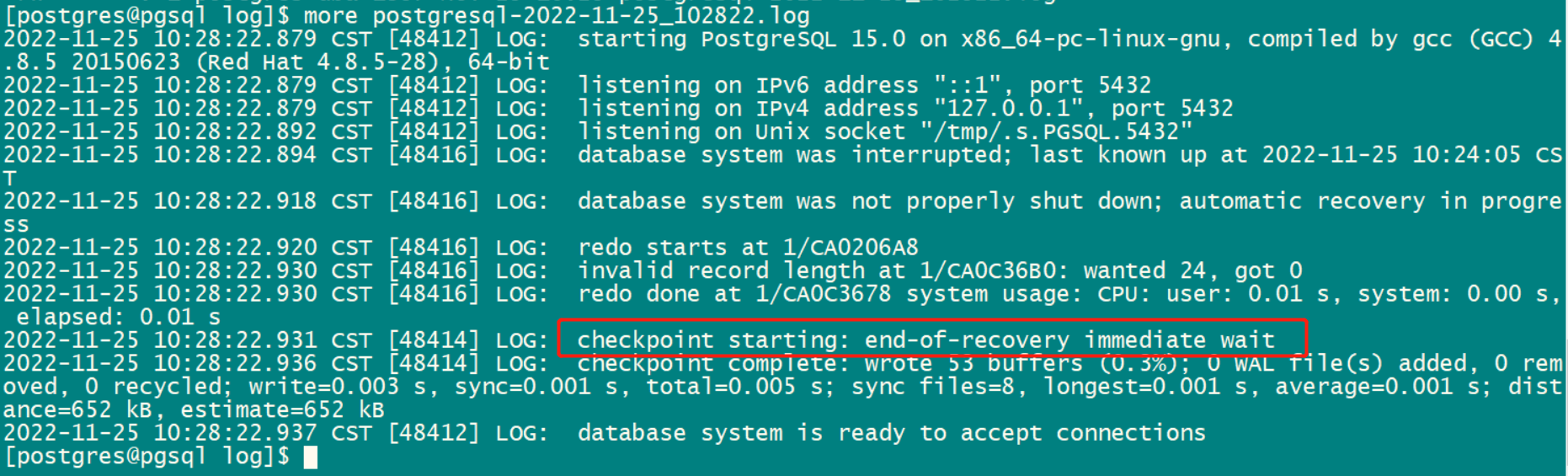
模拟手工执行checkpoint
postgres=# insert into t1 select n from generate_series(1,10000) as n; postgres=# checkpoint; postgres=# checkpoint; postgres=# checkpoint;

checkpoint_timeout参数解析及测试
参数解释
checkpoint_timeout (integer) Maximum time between automatic WAL checkpoints. If this value is specified without units, it is taken as seconds. The valid range is between 30 seconds and one day. The default is five minutes (5min). Increasing this parameter can increase the amount of time needed for crash recovery. This parameter can only be set in the postgresql.conf file or on the server command line.
参数修改及测试
postgres=# show checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1 row)
postgres=# alter system set checkpoint_timeout = 60;
ALTER SYSTEM
postgres=# select pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
postgres=# show checkpoint_timeout;
checkpoint_timeout
--------------------
1min
(1 row)
postgres=# insert into t1 values(99999999);
### wait 5分钟
postgres=# insert into t1 values(99999999);
#### server log
2022-11-25 20:11:13.951 CST [48455] LOG: checkpoint starting: time
2022-11-25 20:11:14.057 CST [48455] LOG: checkpoint complete: wrote 2 buffers (0.0%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.101 s, sync=0.001 s, total=0.106 s; sync files=2, longest=0.001 s, average=0.001 s; distance=4 kB, estimate=511 kB
2022-11-25 20:15:13.084 CST [48455] LOG: checkpoint starting: time
2022-11-25 20:15:13.191 CST [48455] LOG: checkpoint complete: wrote 2 buffers (0.0%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.104 s, sync=0.001 s, total=0.107 s; sync files=2, longest=0.001 s, average=0.001 s; distance=4 kB, estimate=460 kB
### 小结:
checkpoint_timeout触发的检查点不是强制检查点,没有活动事务时,不执行checkpoint操作。
为什么非强制且没有活动事务时,checkpoint不记录日志
### ./src/backend/access/transam/xlog.c: 6379
/*
* If this isn't a shutdown or forced checkpoint, and if there has been no
* WAL activity requiring a checkpoint, skip it. The idea here is to
* avoid inserting duplicate checkpoints when the system is idle.
*/
if ((flags & (CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_END_OF_RECOVERY |
CHECKPOINT_FORCE)) == 0)
{
if (last_important_lsn == ControlFile->checkPoint)
{
WALInsertLockRelease();
END_CRIT_SECTION();
ereport(DEBUG1,
(errmsg_internal("checkpoint skipped because system is idle")));
return;
}
}
### ./src/backend/access/transam/xlog.c: 6456
/*
* If enabled, log checkpoint start. We postpone this until now so as not
* to log anything if we decided to skip the checkpoint.
*/
if (log_checkpoints)
LogCheckpointStart(flags, false);
先刷dirty page还是先记录checkpoint信息到WAL
### ./src/backend/access/transam/xlog.c: 6548
CheckPointGuts(checkPoint.redo, flags); <-- Flush all data in shared memory to disk, and fsync
### ./src/backend/access/transam/xlog.c: 6574
/*
* Now insert the checkpoint record into XLOG.
*/
XLogBeginInsert();
XLogRegisterData((char *) (&checkPoint), sizeof(checkPoint));
recptr = XLogInsert(RM_XLOG_ID,
shutdown ? XLOG_CHECKPOINT_SHUTDOWN :
XLOG_CHECKPOINT_ONLINE);
XLogFlush(recptr); <-- Now insert the checkpoint record into XLOG.
跟踪checkpoint执行函数
### session:1
[postgres@pgsql pgdata]$ ps -ef|grep postgres
postgres 48453 1 0 18:37 ? 00:00:00 /u01/pg15/pgsql/bin/postgres
postgres 48454 48453 0 18:37 ? 00:00:00 postgres: logger
postgres 48455 48453 0 18:37 ? 00:00:00 postgres: checkpointer
postgres 48456 48453 0 18:37 ? 00:00:00 postgres: background writer
postgres 48458 48453 0 18:37 ? 00:00:00 postgres: walwriter
postgres 48459 48453 0 18:37 ? 00:00:00 postgres: autovacuum launcher
postgres 48460 48453 0 18:37 ? 00:00:00 postgres: logical replication launcher
[postgres@pgsql pgdata]$ psql
psql (15.0)
Type "help" for help.
postgres=# insert into t1 values(99999999);
INSERT 0 1
postgres=#
### session:2
[root@pgsql ~]# stap pg_func.stp > stap.out
### session:1
postgres=# checkpoint;
CHECKPOINT
postgres=#
### session:2
[root@pgsql ~]# cat stap.out |grep 48455|egrep -i 'checkpoint'
48455 postgres: ReqCheckpointHandler
48455 postgres: HandleCheckpointerInterrupts
48455 postgres: CreateCheckPoint <-- 创建检查点函数
48455 postgres: SyncPreCheckpoint
48455 postgres: LogCheckpointStart
48455 postgres: update_checkpoint_display
48455 postgres: CheckPointGuts
48455 postgres: CheckPointRelationMap
48455 postgres: CheckPointReplicationSlots
48455 postgres: CheckPointSnapBuild
48455 postgres: CheckPointLogicalRewriteHeap
48455 postgres: CheckPointReplicationOrigin
48455 postgres: CheckPointCLOG
48455 postgres: CheckPointCommitTs
48455 postgres: CheckPointSUBTRANS
48455 postgres: CheckPointMultiXact
48455 postgres: CheckPointPredicate
48455 postgres: CheckPointBuffers
48455 postgres: sort_checkpoint_bufferids
48455 postgres: CheckpointWriteDelay
48455 postgres: CheckPointTwoPhase
48455 postgres: SyncPostCheckpoint
48455 postgres: UpdateCheckPointDistanceEstimate
48455 postgres: LogCheckpointEnd
48455 postgres: update_checkpoint_display
48455 postgres: HandleCheckpointerInterrupts
48455 postgres: pgstat_report_checkpointer
[root@pgsql ~]#
CreateCheckPoint注释
### ./postgresql-15.0/src/backend/access/transam/xlog.c
/*
* Perform a checkpoint --- either during shutdown, or on-the-fly
*
* flags is a bitwise OR of the following:
* CHECKPOINT_IS_SHUTDOWN: checkpoint is for database shutdown.
* CHECKPOINT_END_OF_RECOVERY: checkpoint is for end of WAL recovery.
* CHECKPOINT_IMMEDIATE: finish the checkpoint ASAP,
* ignoring checkpoint_completion_target parameter.
* CHECKPOINT_FORCE: force a checkpoint even if no XLOG activity has occurred
* since the last one (implied by CHECKPOINT_IS_SHUTDOWN or
* CHECKPOINT_END_OF_RECOVERY).
* CHECKPOINT_FLUSH_ALL: also flush buffers of unlogged tables.
*
* Note: flags contains other bits, of interest here only for logging purposes.
* In particular note that this routine is synchronous and does not pay
* attention to CHECKPOINT_WAIT.
*
* If !shutdown then we are writing an online checkpoint. This is a very special
* kind of operation and WAL record because the checkpoint action occurs over
* a period of time yet logically occurs at just a single LSN. The logical
* position of the WAL record (redo ptr) is the same or earlier than the
* physical position. When we replay WAL we locate the checkpoint via its
* physical position then read the redo ptr and actually start replay at the
* earlier logical position. Note that we don't write *anything* to WAL at
* the logical position, so that location could be any other kind of WAL record.
* All of this mechanism allows us to continue working while we checkpoint.
* As a result, timing of actions is critical here and be careful to note that
* this function will likely take minutes to execute on a busy system.
*/
void
CreateCheckPoint(int flags)
{
checkpoint做了哪些操作
初始化CheckpointStats
/*
* Prepare to accumulate statistics.
*
* Note: because it is possible for log_checkpoints to change while a
* checkpoint proceeds, we always accumulate stats, even if
* log_checkpoints is currently off.
*/
MemSet(&CheckpointStats, 0, sizeof(CheckpointStats));
CheckpointStats.ckpt_start_t = GetCurrentTimestamp();
初始化CheckPoint XLOG records
/* Begin filling in the checkpoint WAL record */
MemSet(&checkPoint, 0, sizeof(checkPoint));
checkPoint.time = (pg_time_t) time(NULL);
checkpoint skipped机制
### 如果不是shutdown/forced checkpoint,并且没有WAL写入,则return不执行后续操作。
/*
* If this isn't a shutdown or forced checkpoint, and if there has been no
* WAL activity requiring a checkpoint, skip it. The idea here is to
* avoid inserting duplicate checkpoints when the system is idle.
*/
if ((flags & (CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_END_OF_RECOVERY |
CHECKPOINT_FORCE)) == 0)
{
if (last_important_lsn == ControlFile->checkPoint)
{
WALInsertLockRelease();
END_CRIT_SECTION();
ereport(DEBUG1,
(errmsg_internal("checkpoint skipped because system is idle")));
return;
}
}
log checkpoint start
/*
* If enabled, log checkpoint start. We postpone this until now so as not
* to log anything if we decided to skip the checkpoint.
*/
if (log_checkpoints)
LogCheckpointStart(flags, false);
flush dirty page
/*
* Flush all data in shared memory to disk, and fsync
*
* This is the common code shared between regular checkpoints and
* recovery restartpoints.
*/
static void
CheckPointGuts(XLogRecPtr checkPointRedo, int flags)
{
CheckPointRelationMap();
CheckPointReplicationSlots();
CheckPointSnapBuild();
CheckPointLogicalRewriteHeap();
CheckPointReplicationOrigin();
/* Write out all dirty data in SLRUs and the main buffer pool */
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_START(flags);
CheckpointStats.ckpt_write_t = GetCurrentTimestamp();
CheckPointCLOG();
CheckPointCommitTs();
CheckPointSUBTRANS();
CheckPointMultiXact();
CheckPointPredicate();
CheckPointBuffers(flags);
/* Perform all queued up fsyncs */
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_SYNC_START();
CheckpointStats.ckpt_sync_t = GetCurrentTimestamp();
ProcessSyncRequests();
CheckpointStats.ckpt_sync_end_t = GetCurrentTimestamp();
TRACE_POSTGRESQL_BUFFER_CHECKPOINT_DONE();
/* We deliberately delay 2PC checkpointing as long as possible */
CheckPointTwoPhase(checkPointRedo);
}
写入WAL checkpoint信息
/*
* Now insert the checkpoint record into XLOG.
*/
XLogBeginInsert();
XLogRegisterData((char *) (&checkPoint), sizeof(checkPoint));
recptr = XLogInsert(RM_XLOG_ID,
shutdown ? XLOG_CHECKPOINT_SHUTDOWN :
XLOG_CHECKPOINT_ONLINE);
XLogFlush(recptr);
更新控制文件及内存信息
/*
* Update the control file.
*/
LWLockAcquire(ControlFileLock, LW_EXCLUSIVE);
if (shutdown)
ControlFile->state = DB_SHUTDOWNED;
ControlFile->checkPoint = ProcLastRecPtr;
ControlFile->checkPointCopy = checkPoint;
/* crash recovery should always recover to the end of WAL */
ControlFile->minRecoveryPoint = InvalidXLogRecPtr;
ControlFile->minRecoveryPointTLI = 0;
/*
* Persist unloggedLSN value. It's reset on crash recovery, so this goes
* unused on non-shutdown checkpoints, but seems useful to store it always
* for debugging purposes.
*/
SpinLockAcquire(&XLogCtl->ulsn_lck);
ControlFile->unloggedLSN = XLogCtl->unloggedLSN;
SpinLockRelease(&XLogCtl->ulsn_lck);
UpdateControlFile();
LWLockRelease(ControlFileLock);
/* Update shared-memory copy of checkpoint XID/epoch */
SpinLockAcquire(&XLogCtl->info_lck);
XLogCtl->ckptFullXid = checkPoint.nextXid;
SpinLockRelease(&XLogCtl->info_lck);
WAL删除/增加
/*
* Let smgr do post-checkpoint cleanup (eg, deleting old files).
*/
SyncPostCheckpoint();
/*
* Update the average distance between checkpoints if the prior checkpoint
* exists.
*/
if (PriorRedoPtr != InvalidXLogRecPtr)
UpdateCheckPointDistanceEstimate(RedoRecPtr - PriorRedoPtr);
/*
* Delete old log files, those no longer needed for last checkpoint to
* prevent the disk holding the xlog from growing full.
*/
XLByteToSeg(RedoRecPtr, _logSegNo, wal_segment_size);
KeepLogSeg(recptr, &_logSegNo);
if (InvalidateObsoleteReplicationSlots(_logSegNo))
{
/*
* Some slots have been invalidated; recalculate the old-segment
* horizon, starting again from RedoRecPtr.
*/
XLByteToSeg(RedoRecPtr, _logSegNo, wal_segment_size);
KeepLogSeg(recptr, &_logSegNo);
}
_logSegNo--;
RemoveOldXlogFiles(_logSegNo, RedoRecPtr, recptr,
checkPoint.ThisTimeLineID);
/*
* Make more log segments if needed. (Do this after recycling old log
* segments, since that may supply some of the needed files.)
*/
if (!shutdown)
PreallocXlogFiles(recptr, checkPoint.ThisTimeLineID);
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
