




Cypher语言
In的使用
首先我们建立两个对象,名字分别是Ally和billy.
create (a:Person{name:'Ally'}) ,(b:Person{name:'billy'})
如图所示。
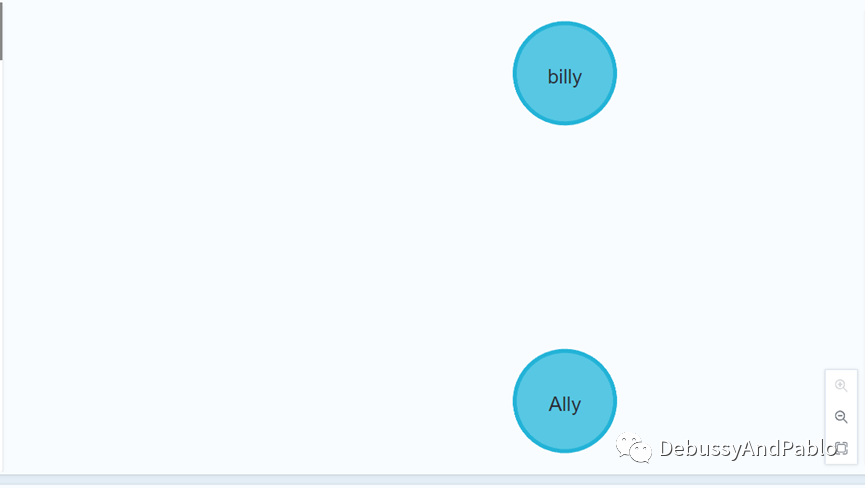
接着,我们使用IN找出数据库名为billy和Ally的对象,并且将他们的年龄都设为40岁。
match (n:Person) where n.name in ['Ally','billy'] set n.age=40 return n
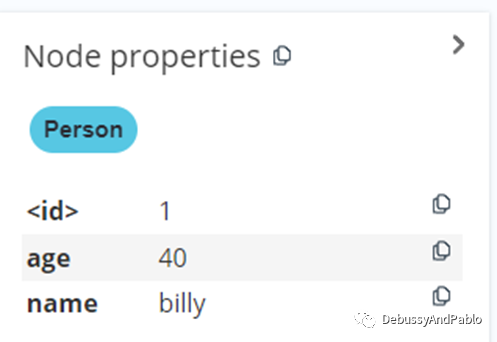
如图可见,billy和Ally被添加了Label-age,并且设置值为40.
我们为Person:name Person:age分别建立一个索引.
create index on :Person(name)
create index on :Person(age)
索引的作用在于提高查询速度,但是在数据写入中会减慢速度,所以索引一般只加在经常需要搜索的列上,不要加在写多读少的列上。这要求了用户在对数据库有一定的把控和熟悉程度。在查询时,neo4j会自动使用索引,语句会自动调用索引。当然我们其实是可以看到建立的索引的,此处需要这个语句。
call db.schema.visualization
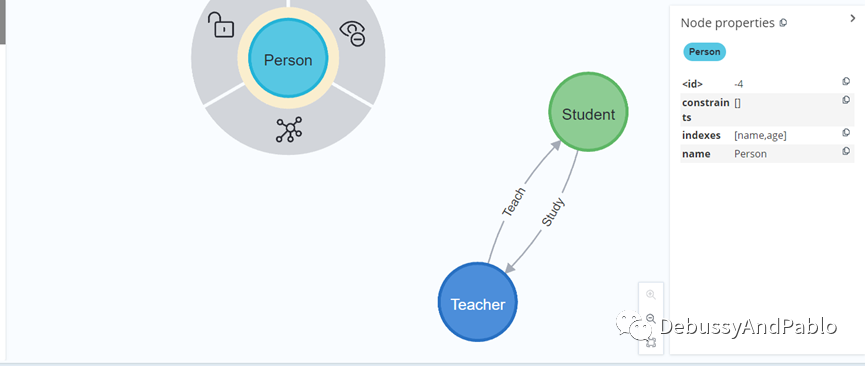
选择Person这个节点,我们可以看到里面包含了name,age两个index。
使用语句进行查询功能,当然我们无法看到这其中索引是否参与了。
在此基础之上,我们再建立一定的约束。
为:Person(name)建立一个独特的约束,禁止在Label person中出现同名的数据。但是因为之前我们建立了index,无法创建约束。所以只能先删除index再建立约束。
drop index on :Person(name)
create constraint on (n:Person) assert n.name is unique
我们再试着建立一个名为Ally的对象,看是否能够成功。
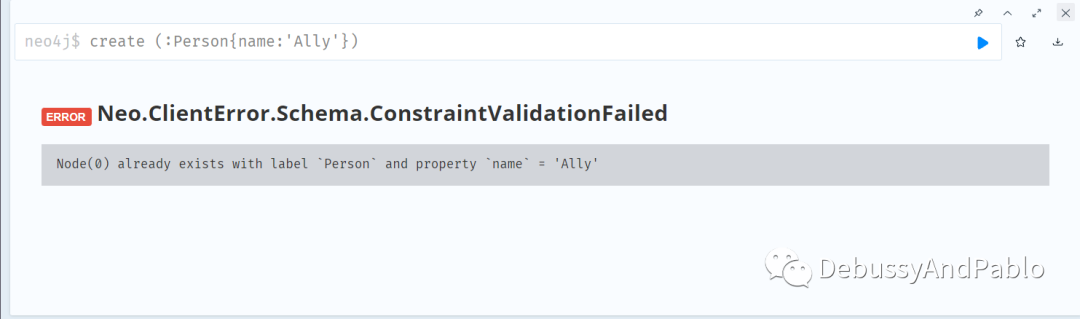
提示已经存在,代表我们建立的约束起到了作用。
接下来,我们学习一下Distinct的用法。首先我们刚建立的约束删除掉,因为distinct一般用在查询中,过滤掉重复数据。
为了使用distinct,我们再create一个名为Ally的人
create (:Person{name:"Ally"})
我们再查询Person的所有数据,再用distinct查询一次,查看是否有不同。
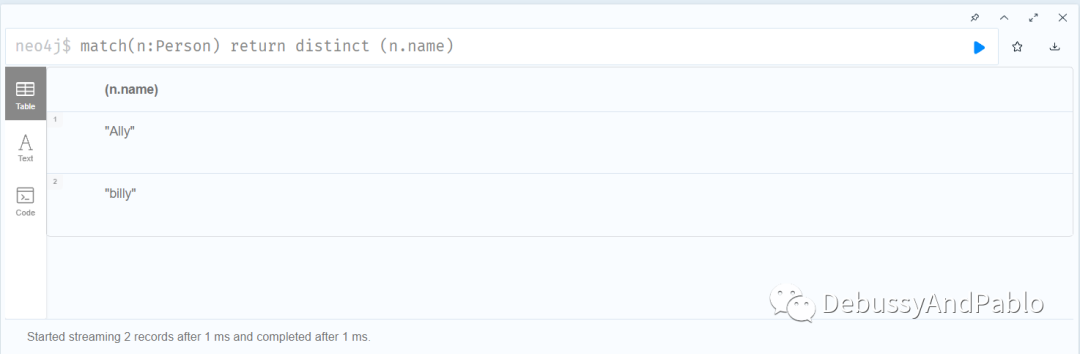
只展示了两个结果,但其实我们是有2个Ally,所以distinct是起作用的。
下面我们再学习Aggregation函数。比较重要的有以下几个:Count,Max,Min,Sum,AVG
match(n:Person) return sum(n.age)
以此语句,我们将Person中所有age属性的值全部累加起来。
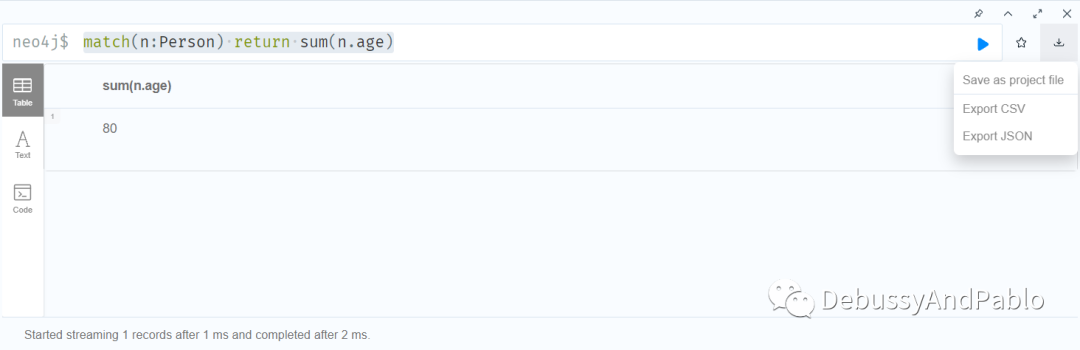
Ally和billy我们设置下都是40岁,所以与我们预期的想法是相符合的。其他函数也是大同小异。
NEO4j基本操作就大概是这些了,马上下班了,回家就开香槟。
Let's fucking goooooooooooo
