




译者注:如译文中有不精准或错误的地方,欢迎大家指正,互相学习
MySQL性能模式像一座有价值的数据金矿。在众多金块中,你可以从中提取,一个事务的历史报告:即执行事务所花费的时间,在其中执行了哪些查询(带有查询指标),以及查询之间的空闲时间。挖掘这些信息并非易事,但它很有趣,这篇博文展示了如何开始。

查询与事务
首先,为什么要关心事务而不是查询?毕竟,性能就是查询响应时间。虽然这是真的,并且查询响应时间是MySQL性能的北极星,但事务是与应用程序相关的工作单元。
例如,应用可能具有用于更新用户配置文件的多语句事务。从应用程序的角度来看,“更新用户配置文件”是单个逻辑事件(包含多个语句)。 因此,了解和分析该事件(事务)的响应时间非常有用。(了解它的吞吐量和其他指标也很有用,但为了简单起见,我们将坚持响应时间。) 此外,正如我们稍后将在本博客文章中看到的那样,事务响应时间不是其组成查询响应时间的总和。接下来的事件层次结构会解释其中的原因。
事件层次结构
transactions
└── statements
└── stages
└── waits
引用MySQL手册中的:
性能架构监视服务器事件。“事件”是服务器执行的任何需要时间并且已被检测以便可以收集计时信息的操作。通常,事件可以是函数调用、操作系统的等待、SQL语句执行的阶段(如解析或排序)或整个语句、语句组。
MySQL将事件组织到上面显示的层次结构中。 实际上,每个事件都是一笔交易。 事务包含语句,这些语句通常是查询,但并非总是如此。 语句具有不同的执行阶段:解析 SQL、打开表、执行等。 最后但并非最不重要的一点是,阶段会产生等待,例如等待磁盘I/O或客户端。
对事件和事件层次结构的简要介绍是高效MySQL性能第8章开头的原因:
MySQL有非事务存储引擎,如MyISAM,但InnoDB是默认和既定的规范。因此,实际上,默认情况下,每个MySQL查询都在事务中执行,甚至是单个SELECT语句。
若要检查事务,必须下降到事件层次结构及其各个表。性能模式非常庞大,因此我无法在简单的博客文章中涵盖它。最起码,可阅读以下几点:
27.9 当前和历史事件的性能架构表。
27.12 性能架构表说明
27.12.1 性能架构表参考
这三页将给你一个铺垫。
除此之外,重要的是要知道每个事件都有一个事件ID,该ID是每个线程单调递增的整数值。因此,事件表的主键通常是(thread_id, event_id)。 由于事件是按层次结构组织的,因此大多数事件表都有列end_event_id、nesting_event_id和nesting_event_type。这允许我们通过连接嵌套在给定事务事件ID下的所有事件来挖掘事务的性能模式。
我不在这篇博文中讨论如何设置或配置性能架构。 对于下面的示例,我已经使大多数仪器能够生成完整的示例,但是在繁忙的生产服务器上,如此广泛的仪器可能不是一个好主意。
检查事务
对于以下示例,我使用的是整本书中使用的表elem;您可以在https://github.com/efficient-mysql-performance/examples 下载它。
事务非常简单,如下:
BEGIN;
SELECT * FROM TABLE elem;
DELETE FROM elem WHERE id=10;
COMMIT;
我手动键入了这四个查询,这是一个重要的细节,我们将在后面看到。
但这四个查询不是重点;事务是焦点,目标是从性能架构中提取所有事件,从而在提交后重新构建整个事务。
说起来容易做起来难。
我将以两种方式介绍此示例。 首先是“原矿”:来自相关性能架构表的原始查询和输出。 像原矿一样,这些数据需要精炼才能有用。 其次是“元宝”:将原始数据提炼成相关事件的颜色编码组,以便更容易从头到尾检查事务。
Raw Ore(原矿)
事务
首先,我们提取事务(层次结构的顶部):
SELECT
thread_id, event_id, end_event_id, event_name, nesting_event_id, nesting_event_type,
ROUND(timer_wait/1000000) t
FROM
events_transactions_history
WHERE
autocommit='NO';
+-----------+----------+--------------+-------------+------------------+--------------------+---------+
| thread_id | event_id | end_event_id | event_name | NESTING_EVENT_ID | NESTING_EVENT_TYPE | t |
+-----------+----------+--------------+-------------+------------------+--------------------+---------+
| 1 | 123 | 126 | transaction | NULL | NULL | 26 |
| 54 | 233 | 281 | transaction | 229 | STATEMENT | 7729078 |
+-----------+----------+--------------+-------------+------------------+--------------------+---------+
线程ID 1是主要的MySQL线程,因此可忽略它。 我们的线程ID是54,这很重要:我们只想要嵌套事件的位置是thread_id=54。
谓词autocommit='NO’也很重要:默认情况下MySQL autocommit自动提交处于打开状态。 单项的SELECT及autocommit的启用是一个隐式事务:用户(或应用)没有显式执行BEGIN或START TRANSACTION。 因此,隐式事务通常是单个语句(查询)。 但我们真正想要检查的是显式多语句事务,就像这个例子一样。 因此,我们必须过滤autocommit='NO’的位置。
但是请注意,即使autocommit启用了,以下显式事务也是可能的,但这样做有些浪费:
BEGIN;
-- One query
COMMIT;
我说这是浪费,因为启用autocommit时,浪费了BEGIN和COMMIT两次往返。 令人惊讶的是,我看到一些ORMs正是这样做的,但这是下个月我讨论第9章“其他挑战”的主题。
在输出上向右滚动并注意t | 7729078:交易执行需要7.7秒。(查询将时间从皮秒转换为微秒。 当然,MySQL并没有缓慢地执行这四个语句中的任何一个。 正如我之前在这篇博文中所暗示的那样,事务时间是由于语句之间的空闲时间,因为我手动逐个键入查询。
事务中语句之间的空闲时间是检查事务的最重要原因之一。事务空闲时间不会显示在查询分析中,因为它不是任何查询的属性,而是查询之间的时间。 因此,尽管查询分析无法揭示它,但应用程序(和用户)将体验它。 为什么会出现事务空闲时间? 阅读高效MySQL性能第8章中的“常见问题”部分。
注意NESTING_EVENT_TYPE | STATEMENTBEGIN在输出中。这意味着事务嵌套在语句事件中/下,这与事件层次结构相矛盾。 完整的解释很复杂(并记录在MySQL手册中);简短的回答是:语句首先发生并创建事务。
end_event_id很重要,因为它允许我们有效地查询嵌套表:仅使用(thread_id, event_id)主键。 我们知道线程 ID:54。 由于每个线程的事件ID单调增加,我们知道所有嵌套事件必须在229(BEGIN是创建事务的事件)和281(事务end_event_id)之间。 现在,我们已准备好查询层次结构中的下一级:语句。
语句
然后我们提取事务中的语句:
SELECT
event_id, end_event_id, event_name, source,
ROUND(timer_wait/1000000) t,
ROUND(lock_time/1000000) lockt,
LEFT(sql_text,1000),
COALESCE(current_schema,'') db,
nesting_event_id, nesting_event_type
FROM
events_statements_history
WHERE
thread_id=54
AND event_id BETWEEN 229 and 281;
+----------+--------------+----------------------+---------------------------------+------+-------+------------------------------+------+------------------+--------------------+
| event_id | end_event_id | event_name | source | t | lockt | LEFT(sql_text,1000) | db | NESTING_EVENT_ID | NESTING_EVENT_TYPE |
+----------+--------------+----------------------+---------------------------------+------+-------+------------------------------+------+------------------+--------------------+
| 229 | 237 | statement/sql/begin | init_net_server_extension.cc:97 | 48 | 0 | begin | test | NULL | NULL |
| 239 | 258 | statement/sql/select | init_net_server_extension.cc:97 | 226 | 2 | select * from elem | test | 233 | TRANSACTION |
| 260 | 275 | statement/sql/delete | init_net_server_extension.cc:97 | 303 | 2 | delete from elem where id=10 | test | 233 | TRANSACTION |
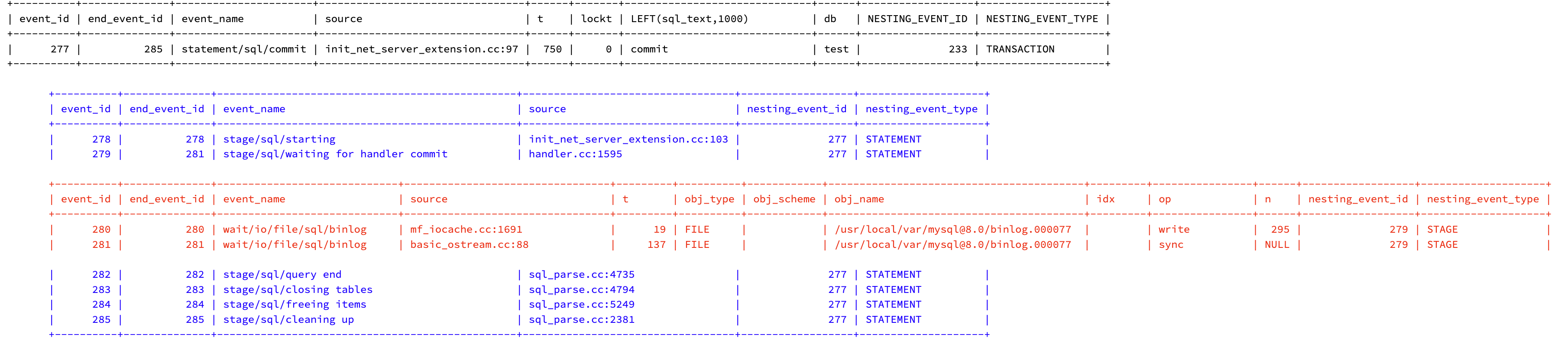
| 277 | 285 | statement/sql/commit | init_net_server_extension.cc:97 | 750 | 0 | commit | test | 233 | TRANSACTION |
+----------+--------------+----------------------+---------------------------------+------+-------+------------------------------+------+------------------+--------------------+
请注意WHERE子句:按线程ID以及开始和结束事件ID的范围,如上所述。
正如预期的那样,我们提取了事务的四个SQL语句。 输出中的列是以微秒为单位的查询执行时间。 表(tevents_statements_history)中提供了完整的查询指标范围,只是为简洁起见,此处未显示。 同样正如预期的那样,每个查询都很快:不到1毫秒。 总查询执行时间为1.3毫秒,由于语句之间的空闲时间,大大少于事务执行时间的7.7秒。
注意NESTING_EVENT_TYPE | NULl因为BEGIN启动了整个事件链,但NESTING_EVENT_TYPE | TRANSACTION对于其他语句,这与事件层次结构一致。
每个语句的结束事件ID比语句多几个事件,因为嵌套在每个语句中的是阶段。 请注意,最后一条语句(COMMIT)的结束事件ID为285,它是嵌套的阶段事件ID,大于此表上的查询中使用的BETWEEN值。在查询嵌套阶段时,我们需要使用此阶段事件ID,以确保提取所有阶段。
阶段
第三,我们提取语句中的阶段:
SELECT
event_id, end_event_id, event_name,
source,
nesting_event_id, nesting_event_type
FROM
events_stages_history
WHERE
thread_id=54
AND event_id BETWEEN 229 and 285;
+----------+--------------+------------------------------------------------+----------------------------------+------------------+--------------------+
| event_id | end_event_id | event_name | source | nesting_event_id | nesting_event_type |
+----------+--------------+------------------------------------------------+----------------------------------+------------------+--------------------+
| 230 | 230 | stage/sql/starting | init_net_server_extension.cc:103 | 229 | STATEMENT |
| 231 | 231 | stage/sql/Executing hook on transaction begin. | rpl_handler.cc:1472 | 229 | STATEMENT |
| 232 | 233 | stage/sql/starting | rpl_handler.cc:1474 | 229 | STATEMENT |
| 234 | 234 | stage/sql/query end | sql_parse.cc:4735 | 229 | STATEMENT |
| 235 | 235 | stage/sql/closing tables | sql_parse.cc:4794 | 229 | STATEMENT |
| 236 | 236 | stage/sql/freeing items | sql_parse.cc:5249 | 229 | STATEMENT |
| 237 | 237 | stage/sql/cleaning up | sql_parse.cc:2381 | 229 | STATEMENT |
| 240 | 240 | stage/sql/starting | init_net_server_extension.cc:103 | 239 | STATEMENT |
| 241 | 241 | stage/sql/checking permissions | sql_authorization.cc:2160 | 239 | STATEMENT |
| 242 | 242 | stage/sql/Opening tables | sql_base.cc:5796 | 239 | STATEMENT |
| 243 | 243 | stage/sql/init | sql_select.cc:562 | 239 | STATEMENT |
| 244 | 245 | stage/sql/System lock | lock.cc:331 | 239 | STATEMENT |
| 246 | 246 | stage/sql/optimizing | sql_optimizer.cc:296 | 239 | STATEMENT |
| 247 | 247 | stage/sql/statistics | sql_optimizer.cc:624 | 239 | STATEMENT |
| 248 | 248 | stage/sql/preparing | sql_optimizer.cc:708 | 239 | STATEMENT |
| 249 | 250 | stage/sql/executing | sql_union.cc:1198 | 239 | STATEMENT |
| 251 | 251 | stage/sql/end | sql_select.cc:595 | 239 | STATEMENT |
| 252 | 252 | stage/sql/query end | sql_parse.cc:4735 | 239 | STATEMENT |
| 253 | 253 | stage/sql/waiting for handler commit | handler.cc:1595 | 239 | STATEMENT |
| 254 | 254 | stage/sql/closing tables | sql_parse.cc:4794 | 239 | STATEMENT |
| 255 | 255 | stage/sql/freeing items | sql_parse.cc:5249 | 239 | STATEMENT |
| 256 | 257 | stage/sql/logging slow query | log.cc:1648 | 239 | STATEMENT |
| 258 | 258 | stage/sql/cleaning up | sql_parse.cc:2381 | 239 | STATEMENT |
| 261 | 261 | stage/sql/starting | init_net_server_extension.cc:103 | 260 | STATEMENT |
| 262 | 262 | stage/sql/checking permissions | sql_authorization.cc:2160 | 260 | STATEMENT |
| 263 | 263 | stage/sql/Opening tables | sql_base.cc:5796 | 260 | STATEMENT |
| 264 | 264 | stage/sql/init | sql_select.cc:562 | 260 | STATEMENT |
| 265 | 266 | stage/sql/System lock | lock.cc:331 | 260 | STATEMENT |
| 267 | 269 | stage/sql/updating | sql_delete.cc:561 | 260 | STATEMENT |
| 270 | 270 | stage/sql/end | sql_select.cc:595 | 260 | STATEMENT |
| 271 | 271 | stage/sql/query end | sql_parse.cc:4735 | 260 | STATEMENT |
| 272 | 272 | stage/sql/waiting for handler commit | handler.cc:1595 | 260 | STATEMENT |
| 273 | 273 | stage/sql/closing tables | sql_parse.cc:4794 | 260 | STATEMENT |
| 274 | 274 | stage/sql/freeing items | sql_parse.cc:5249 | 260 | STATEMENT |
| 275 | 275 | stage/sql/cleaning up | sql_parse.cc:2381 | 260 | STATEMENT |
| 278 | 278 | stage/sql/starting | init_net_server_extension.cc:103 | 277 | STATEMENT |
| 279 | 281 | stage/sql/waiting for handler commit | handler.cc:1595 | 277 | STATEMENT |
| 282 | 282 | stage/sql/query end | sql_parse.cc:4735 | 277 | STATEMENT |
| 283 | 283 | stage/sql/closing tables | sql_parse.cc:4794 | 277 | STATEMENT |
| 284 | 284 | stage/sql/freeing items | sql_parse.cc:5249 | 277 | STATEMENT |
| 285 | 285 | stage/sql/cleaning up | sql_parse.cc:2381 | 277 | STATEMENT |
+----------+--------------+------------------------------------------------+----------------------------------+------------------+--------------------+
输出是巨大的,但有一个模式:每个语句都以阶段stage/sql/starting开头,以阶段stage/sql/cleaning up结束。 滚动到输出的右侧并查看重复的nesting_event_id块:每个语句一个事件ID:

执行实际查询(SQL 语句)只是许多阶段中的一个阶段。 阶段也有执行时间,但我没有在这里包括它,因为我认为它不是特别有用。 为什么?两个原因:阶段通常不是问题;对于慢速阶段,除非是查询执行阶段,否则您无法执行任何操作,在这种情况下,您可以优化查询,而不是阶段。
等待
最后,我们提取阶段内的等待:
SELECT
event_id, end_event_id, event_name,
source,
ROUND(timer_wait/1000000) t,
COALESCE(object_type, '') obj_type,
COALESCE(object_schema,'') obj_scheme,
COALESCE(object_name,'') obj_name,
COALESCE(index_name, '') idx,
operation op,
number_of_bytes n,
nesting_event_id, nesting_event_type
FROM
events_waits_history
WHERE
thread_id=54
AND event_id BETWEEN 229 and 285;
+----------+--------------+-----------------------------+---------------------------------+---------+----------+------------+-----------------------------------------+---------+----------------+------+------------------+--------------------+
| event_id | end_event_id | event_name | source | t | obj_type | obj_scheme | obj_name | idx | op | n | nesting_event_id | nesting_event_type |
+----------+--------------+-----------------------------+---------------------------------+---------+----------+------------+-----------------------------------------+---------+----------------+------+------------------+--------------------+
| 238 | 238 | idle | init_net_server_extension.cc:67 | 2688899 | | | | | idle | NULL | NULL | NULL |
| 245 | 245 | wait/lock/table/sql/handler | handler.cc:7901 | 1 | TABLE | test | elem | PRIMARY | read external | NULL | 244 | STAGE |
| 250 | 250 | wait/io/table/sql/handler | handler.cc:2993 | 25 | TABLE | test | elem | | fetch | 10 | 249 | STAGE |
| 257 | 257 | wait/io/file/sql/slow_log | mf_iocache.cc:1691 | 35 | FILE | | /usr/local/var/mysql@8.0/slow-query.log | | write | 571 | 256 | STAGE |
| 259 | 259 | idle | init_net_server_extension.cc:67 | 3824614 | | | | | idle | NULL | NULL | NULL |
| 266 | 266 | wait/lock/table/sql/handler | handler.cc:7901 | 1 | TABLE | test | elem | PRIMARY | write external | NULL | 265 | STAGE |
| 268 | 268 | wait/io/table/sql/handler | handler.cc:3264 | 20 | TABLE | test | elem | PRIMARY | fetch | 1 | 267 | STAGE |
| 269 | 269 | wait/io/table/sql/handler | handler.cc:8027 | 32 | TABLE | test | elem | PRIMARY | delete | 1 | 267 | STAGE |
| 276 | 276 | idle | init_net_server_extension.cc:67 | 1214261 | | | | | idle | NULL | NULL | NULL |
| 280 | 280 | wait/io/file/sql/binlog | mf_iocache.cc:1691 | 19 | FILE | | /usr/local/var/mysql@8.0/binlog.000077 | | write | 295 | 279 | STAGE |
| 281 | 281 | wait/io/file/sql/binlog | basic_ostream.cc:88 | 137 | FILE | | /usr/local/var/mysql@8.0/binlog.000077 | | sync | NULL | 279 | STAGE |
+----------+--------------+-----------------------------+---------------------------------+---------+----------+------------+-----------------------------------------+---------+----------------+------+------------------+--------------------+
我喜欢MySQL手册定义等待的方式:
性能架构工具等待,这些事件需要时间。
所以等待是需要时间的事件…但是等等(双关语),不是每个事件都需要时间吗?🤔
我将等待定义为MySQL等待共享资源或客户端所花费的时间。
共享资源包括存储和网络I/O、数据锁和同步机制。 例如,所有存储 I/O 都需要非零时间。 即使是最快的存储系统也有几微秒的延迟。几乎每个数据库都有锁和同步(如互斥锁),这些锁定和同步会导致非零的等待时间来获取,尤其是在高并发负载下。
等待客户端是一个特殊的等待事件idle,如上面的输出中报告了三次。空闲事件在10.3.5 socket_instances表中描述:
套接字状态,“空闲”或“活动”。使用相应的套接字仪器跟踪活动套接字的等待时间。使用仪器idle跟踪空闲套接字的等待时间。
如果套接字正在等待来自客户端的请求,则套接字处于空闲状态。当套接字变为空闲状态时,跟踪套接字的事件行socket_instances将从“活动”状态切换到“空闲”。该值EVENT_NAME保持wait/io/socket/*不变,但仪器的时间已暂停。相反,在events_waits_current表中生成一个值为EVENT_NAME的idle事件。
当收到下一个请求时,idle事件终止,套接字实例从空闲切换到活动,套接字仪器的计时恢复。
等待通常分阶段嵌套,但空闲事件是一个例外(在输出上向右滚动)。 例如,第一个空闲事件的ID为 238,但这对应于什么? 由于事件ID单调递增(每个线程),因此此空闲事件紧跟在以事件ID 237结束的语句事件ID 229(BEGIN)之后:

请记住:我手动键入了这些查询,因此MySQL在语句之间空闲了2.7秒(t | 2688899μs),等待(客户端)。
输出中的其他等待是对共享资源的等待:两个表锁和多个磁盘 I/O 等待。 它们嵌套在阶段事件中,但沿着嵌套事件 ID 向上排列,您会发现等待是在语句中(或由语句)发生的。 例如,最后两个等待嵌套在阶段事件 ID 279 中,这些事件嵌套在语句事件 ID 277:COMMIT中。 再次回到等待中,列obj_name和op(operation简称)列出了MySQL在提交期间等待的内容:二进制日志。
关于MySQL等待事件,要了解的比我在这里介绍的要多。 这篇博文的目的只是展示如何开始挖掘事务的性能模式。 但是我会说一些关于MySQL性能的等待的事情。
不可能有零等待(或零等待时间),因为延迟是所有计算机系统的继承。 如前所述,所有存储(和网络)I/O 都需要非零时间。 因此,关于等待,目标是将等待时间尽可能减少到接近零。 这对于idle等待事件(等待客户端)尤其重要,因为它是由应用程序引起的,因此您可以直接解决。 同样,请阅读高效MySQL性能第8章中的“常见问题”部分。
在MySQL的世界里,在性能故障排除中使用等待并不像人们想象的那么普遍,特别是因为它们自12年前(2010年)发布的MySQL 5.5以来就已经可用。 相反,几乎所有你读到(或听)的关于MySQL性能的东西——包括我的书——都集中在MySQL正在做什么以及花了多长时间——主要是语句事件。 我们可以将这两种方法视为同一枚硬币的两面:执行时间与等待时间。 MySQL正在执行或等待。 但我认为这有点误导,因为当事件层次结构正确建模时,执行会导致等待:执行→等待。 (空闲等待事件是一个例外,这就是为什么它不嵌套在任何事件中的原因。 因此,如果我们首先关注等待,那么我们只能从它们身上学到很多东西,或者做很多事情来减少它们。 例如,假设性能架构显示查询在磁盘 I/O 上花费大量时间等待。 如果不考虑查询访问如此多数据的原因,实际上唯一的解决方案是通过升级存储系统来减少磁盘 I/O 延迟并提高磁盘 IOPS。 这可能会奏效,但它效率非常低,可能非常昂贵,我向你保证,没有MySQL专家会建议这种方法。 相反,正确和最有效的方法是我的书的全部内容:查询响应时间。 在此示例中,您首先查看导致磁盘 I/O 等待的语句。 也许您发现查询缺少良好的索引,或者具有不必要的ORDER BY子句,或者有无数其他原因使语句效率低下,从而导致磁盘 I/O 等待。 您几乎可以免费优化查询—比升级存储系统要容易得多。
在我看来,等待对于进行深入分析的MySQL专家或真正想要深入研究查询响应时间的勇敢的软件工程师很有用,因为等待是响应时间的一部分。 无论哪种方式,MySQL的性能都是查询响应时间。
Ingots
上一节的标题是Raw Ore,现在您可以了解原因:一个简单的四语句事务会产生大量原始输出,这些输出在模型中是分层的,但在查询时是扁平的和有点混淆的。 为了更好地可视化和理解事务,我为每个语句组合了事件,并对输出进行了颜色编码。
颜色代码:
- Statement
- Stage
- Wait
- Idle
例如,之后的SELECT和idle事件以顶部的语句事件开头。 下面是四个阶段。 每个阶段下都有相应的等待。 最后,一个idle事件:MySQL等待(客户端)键入并输入下一条语句。
单击图像以查看完整尺寸。
BEGIN和idle:

SELECT和idle:

DELETE和idle:

COMMIT
目前的技术水平
据我所知,目前还没有开源工具可以挖掘性能模式并将原始数据处理成简单有用的东西供人类使用。 MySQL sys Schema有许多使用原始性能模式数据的视图,但这仍然是非常原始的,无法表达完整的事务,如下所示。 此外,性能模式包含的数据比我在这里展示的要多得多,因此业界确实需要一个复杂的工具,可以将性能模式中的大量数据提取并提炼成黄金:深入了解MySQL性能。
但在那之前,交易报告的最新技术是复制粘贴,正如我在高效的MySQL性能第8章中所写的那样,在https://hackmysql.com/trx 上转载,并在这篇博文中进行了扩展。
原文标题:Mining the MySQL Performance Schema for Transactions
原文链接:https://hackmysql.com/post/book-8/
