




各位新朋友~记得先点蓝字关注我哦~
关于distcp,熟悉Hadoop的人都知道,这是一个用于大规模集群内部和集群之间拷贝数据的工具。
了解distcp
概述:
它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告的生产。他把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。
语法:
hadoop distcp hdfs://namenode1:port/source hdfs://namenode2:port/destination
将namenode1上的/source目录下的文件复制到namenode2上/destination目录下。
多个数据源
hadoop distcp hdfs://namenode:port/source1 hdfs://namenode:port/source2 hdfs://namenode:port/destination
将多个数据源保存在一个文件中,并使用-f输出
hadoop distcp -f hdfs://namenode:port/srclist hdfs://namenode:port/destination
用法:

上述只描述了部分常用的参数,更多详细的参数查看distcp官网
https://hadoop.apache.org/docs/current/hadoop-distcp/DistCp.html
注意:
如果另一个客户端仍在写入源文件,则复制可能会失败。在HDFS上尝试覆盖正在目标位置写入的文件也将失败。如果在复制之前(移出)了源文件,则复制将失败,并带有FileNotFoundException。
在HA中配置distcp
可是今天小编遇到一个问题,客户的环境是HA,如果按照上述ip:8020的方法也是可以的,但是需要找到作为Active的节点,否则会报错误:
[root@dest01 ~]# hadoop distcp -p hdfs://src01:8020/tmp/hive/drcc hdfs://dest/tmp22/03/21 20:05:13 INFO tools.DistCp: Input Options: DistCpOptions{atomicCommit=false, syncFolder=false, deleteMissing=false, ignoreFailures=false, overwrite=false, append=false, useDiff=false, useRdiff=false, fromSnapshot=null, toSnapshot=null, skipCRC=false, blocking=true, numListstatusThreads=0, maxMaps=20, mapBandwidth=0.0, copyStrategy='uniformsize', preserveStatus=[REPLICATION, BLOCKSIZE, USER, GROUP, PERMISSION, CHECKSUMTYPE, TIMES], atomicWorkPath=null, logPath=null, sourceFileListing=null, sourcePaths=[hdfs://src01:8020/tmp/hive/drcc], targetPath=hdfs://dest/tmp, filtersFile='null', blocksPerChunk=0, copyBufferSize=8192, verboseLog=false}, sourcePaths=[hdfs://src01:8020/tmp/hive/drcc], targetPathExists=true, preserveRawXattrsfalse22/03/21 20:05:13 INFO client.RMProxy: Connecting to ResourceManager at dest01/192.168.2.200:803222/03/21 20:05:13 ERROR tools.DistCp: Exception encounteredorg.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
上述报错中明显写出在standby状态下不支持read。
因此我们需要将语法中的IP:8020改成nameservice,他会自动去寻找作为active的节点
配置HA集群
修改hdfs-site.xml文件或者在网页上修改。
dfs.nameservices = HAA, HAB
In cluster A:dfs.internal.nameservices = HAA
In cluster B:dfs.internal.nameservices = HAB
In cluster Adfs.ha.namenodes.HAB = nn1,nn2
In cluster Bdfs.ha.namenodes.HAA = nn1,nn2
In Cluster A:dfs.namenode.rpc-address.HAB.nn1 =:8020
dfs.namenode.rpc-address.HAB.nn2 =:8020
In Cluster B:dfs.namenode.rpc-address.HAA.nn1 =:8020
dfs.namenode.rpc-address.HAA.nn2 =:8020
In cluster A:dfs.client.failover.proxy.provider. HAB = org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
In cluster B:dfs.client.failover.proxy.provider. HAA = org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
示例:
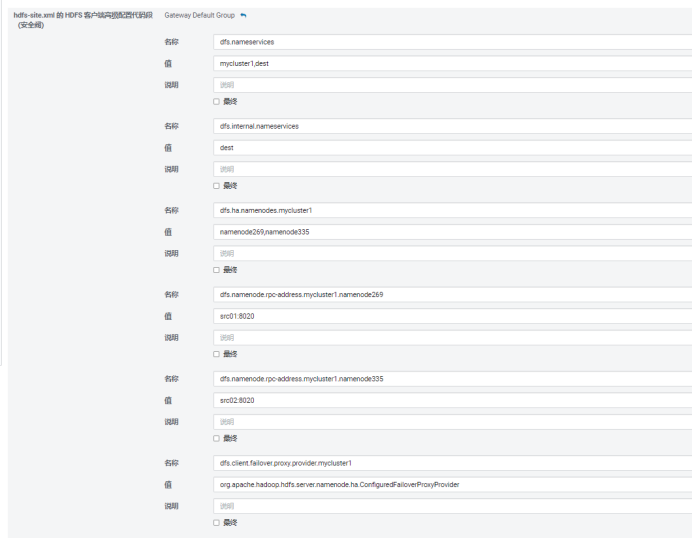
当然上述配置完成后需要重启hdfs服务,若生产端无法重启,那么我们只需要配置目标端的参数并重启。
语法:
hadoop distcp hdfs://HAA/tmp/testDistcp hdfs://HAB/tmp/
[root@dest01 ~]# hadoop distcp -p hdfs://mycluster1/tmp/hive/drcc hdfs://dest/tmp……22/03/21 19:50:11 INFO mapreduce.Job: Running job: job_1647863205255_000122/03/21 19:50:20 INFO mapreduce.Job: Job job_1647863205255_0001 running in uber mode : false22/03/21 19:50:20 INFO mapreduce.Job: map 0% reduce 0%22/03/21 19:50:27 INFO mapreduce.Job: map 33% reduce 0%22/03/21 19:50:28 INFO mapreduce.Job: map 100% reduce 0%22/03/21 19:50:29 INFO mapreduce.Job: Job job_1647863205255_0001 completed successfully22/03/21 19:50:29 INFO mapreduce.Job: Counters: 38File System CountersFILE: Number of bytes read=0FILE: Number of bytes written=682062FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=2846HDFS: Number of bytes written=8HDFS: Number of read operations=48HDFS: Number of large read operations=0HDFS: Number of write operations=16HDFS: Number of bytes read erasure-coded=0Job CountersLaunched map tasks=3Other local map tasks=3Total time spent by all maps in occupied slots (ms)=17300Total time spent by all reduces in occupied slots (ms)=0Total time spent by all map tasks (ms)=17300Total vcore-milliseconds taken by all map tasks=17300Total megabyte-milliseconds taken by all map tasks=17715200Map-Reduce FrameworkMap input records=7Map output records=0Input split bytes=348Spilled Records=0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=215CPU time spent (ms)=1560Physical memory (bytes) snapshot=800432128Virtual memory (bytes) snapshot=7767953408Total committed heap usage (bytes)=1414004736Peak Map Physical memory (bytes)=283295744Peak Map Virtual memory (bytes)=2591727616File Input Format CountersBytes Read=2490File Output Format CountersBytes Written=0DistCp CountersBandwidth in Btyes=8Bytes Copied=8Bytes Expected=8Files Copied=1DIR_COPY=6
关于distcp额外知识
1、在HDFS不通版本之间复制
两种不同的Hadoop版本之间进行复制(2.X和3.X),通常使用webhdfsfiles系统。与以前的hftpfiles不同,由于webhdfs可以用于读取和写入操作,所以DistCp可以在源和目标集群上运行(HftpFileSystem。这是一个只读文件系统,所以DistCp必须运行在目标端集群上,Hadoop3.x 已经对其废弃使用,使用webhdfs替代)。
hadoop distcp -update -skipcrccheck -m 50 \webhdfs://10.90.48.127:50070/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/day=20210701 \webhdfs://10.90.50.54:9870/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/day=20210701
2、安全复制
使用swebhdfs://命令来使用SSL保护webhdfs
3、mapreduce和他的副作用
除非指定-overwrite,否则在重新执行时由先前映射成功复制的文件将被标记为“已跳过”。
如果映射失败mapreduce.map.maxattempts次,则其余映射任务将被杀死(除非设置了-i)。
如果将mapreduce.map.speculative设置为final和true,则副本的结果不确定。
4、distcp和对象存储
DistCp可与对象存储(例如Amazon S3,Azure WASB和OpenStack Swift)一起使用。
先决条件
1)对象存储实现的JAR及其所有依赖项都位于类路径上。
2)JAR自动注册其捆绑的文件系统客户端,否则可能需要修改配置以声明实现文件系统架构的类。ASF自己的所有对象存储客户端都是自注册的。
3)对象存储访问凭据必须在群集配置中可用,或者在所有群集主机中都可用。
DistCp可用于上传数据
hadoop distcp -direct hdfs://nn1:8020/datasets/set1 s3a://bucket/datasets/set1
下载数据
hadoop distcp s3a://bucket/generated/results hdfs://nn1:8020/results
美创是国内领先的数据库服务提供商。服务团队拥有PG ACED 1名、Oracle&PG ACE 3人、DSI智库专家5名、DSMM测评师7名、OCM 20余人、数十名Oracle OCP、MySQL OCP、TDSQL TCP、OceanBase OBCP、TiDB PTCP、达梦 DCP、人大金仓、红帽RHCA、中间件weblogic、tuxedo、CISP-DSG、CISSP、CDGA、CDPSE、CZTP、CDSP等认证人员,著有《DBA攻坚指南:左手Oracle,右手MySQL》,《Oracle数据库性能优化方法和最佳实践》,《Oracle内核技术揭秘》,《Oracle DBA实战攻略》等多本数据库书籍。运维各类数据库合计5000余套,精通Oracle、MySQL、SQLServer、DB2、PostgreSQL、MongoDB、Redis、TDSQL、OceanBase、达梦、人大金仓等主流商业和开源数据库。美创拥有完善的运维体系和人员培养体系,并同时提供超融合、私有云整体服务解决方案、数据安全咨询及运营服务方案等,已为金融、政府、企业、能源等多个行业的客户提供量身定制的各类服务,赢得了客户的高度赞誉和广泛认可。

