




前言
近年来,复杂多跳逻辑查询(complex multi-hop logical queries)成为了知识图谱领域的一个热点问题。基于子图匹配等的普通逻辑查询方法只能处理知识图谱中已观测到的实体和边。但真实世界中的知识图谱是不完整的,在处理不完整知识图谱的复杂逻辑查询时,普通逻辑查询方法不能处理缺失的信息,即遇到未观测到的中间实体或关系时,就无法查询到正确的答案。随着知识图谱嵌入方法的不断发展,复杂多跳逻辑推理基于知识嵌入技术,对查询过程中间缺失的实体或者关系进行推理补全,并给出最终的查询结果。
问题简介
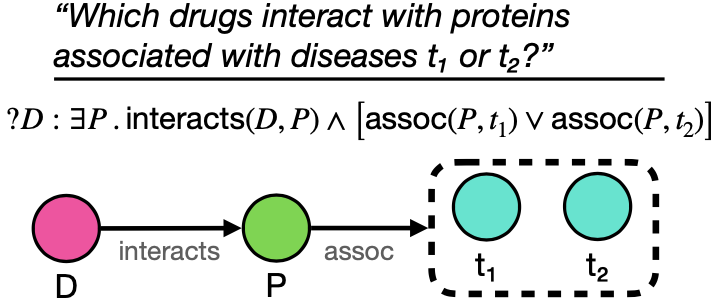
一阶逻辑查询(First-Order Logical Queries)就是由conjunctions (∧), disjunctions (∨), existential quantifiers (∃)构成的逻辑语句。例如图中的问题 “Which drugs interact with proteins associated with diseases t1 or t2” 可以被表达为逻辑语句“?D : ∃P.interacts(D, P ) ∧ [assoc(P, t1) ∨ assoc(P, t2)]”和下图查询图的形式
受到知识图谱嵌入(Knowledge Graph Embedding, KGE)方法的启发,很多工作都将查询与知识图谱中的实体嵌入到同一空间,将距离查询最近的实体作为该查询的答案。根据查询和实体嵌入形式不同,复杂逻辑嵌入查询的代表性方法主要有以下两类:
嵌入空间中的形状:例如点(GQE)、超长方形(Query2Box,NewLook)、超扇形(ConE); 嵌入空间中的分布:例如高斯分布(PERM)、Beta分布(BetaE)等。
今天介绍的三篇工作跳出了上述定义嵌入形式的思路,将预训练和序列模型应用到了复杂逻辑查询当中。
文章一

首先,将每个一阶逻辑表达式表达为析取范式(Disjunctive Normal Form, DNF),例如

文章框架主要由两部分构成:
对每个原子查询(atomic query)p(s,o),神经链接预测因子(Neural link predictor)定义一个打分函数,预测每个实体对s和o之间有关系r的可能性。文章选取了两种神经链接预测因子:ComplEx和DisMult。
对完整逻辑查询,引入三角范数,对查询中的每个原子查询用t-norms和其对偶形式t-conorm聚合这些分数,例如对于每个DNF形式表达的逻辑查询
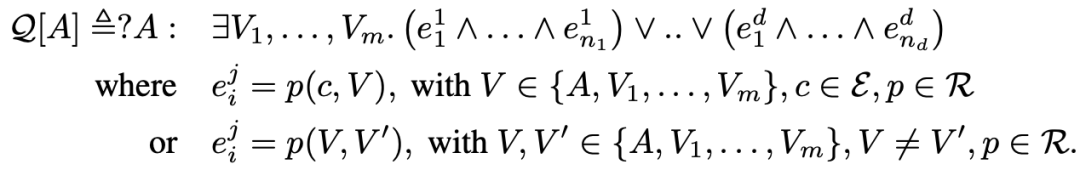
都可以通过三角范数,将其表达为一个分数最大化的连续优化问题
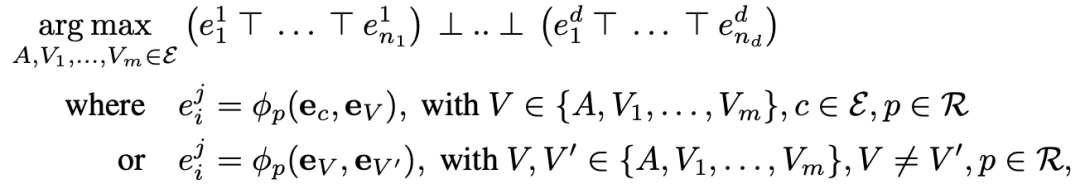
优化部分,文章采用了两种优化方式:一是连续优化方式(continuous optimization),使用像Adam那种基于梯度的方法,直接寻找与查询答案嵌入最匹配的实体;二是组合优化方式(Combinatorial optimization),使用类似beam search一样的贪婪搜索方法,通过遍历查询的依赖图,选取神经连接预测因子打分最高的k个实体对中间变量进行替换,直到用实体替换答案变量,最终选取使查询分数最大化的答案实体。例如:

与问题介绍中介绍的GQE和Query2Box等方法不同,文章提出的Complex Query Decomposition (CQD)方法只需要使用原子查询对模型进行训练,不需要对不同形式的query进行采样,大大降低了训练所需的数据量。
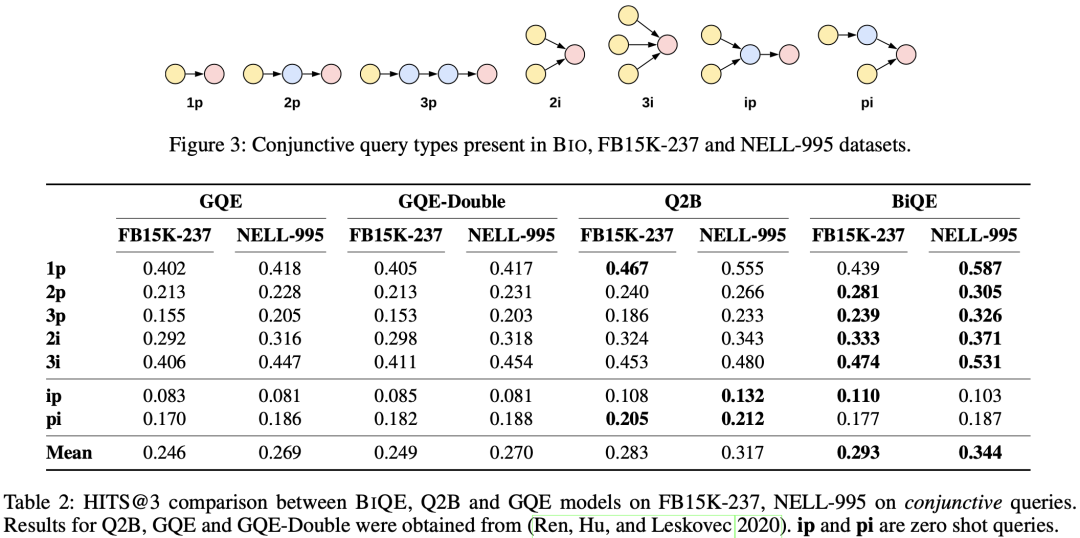
文章采用以下9种查询形式测试模型的性能

query
在三个数据集的所有查询形式下,文章提出的CQD模型均有较大的性能提升。
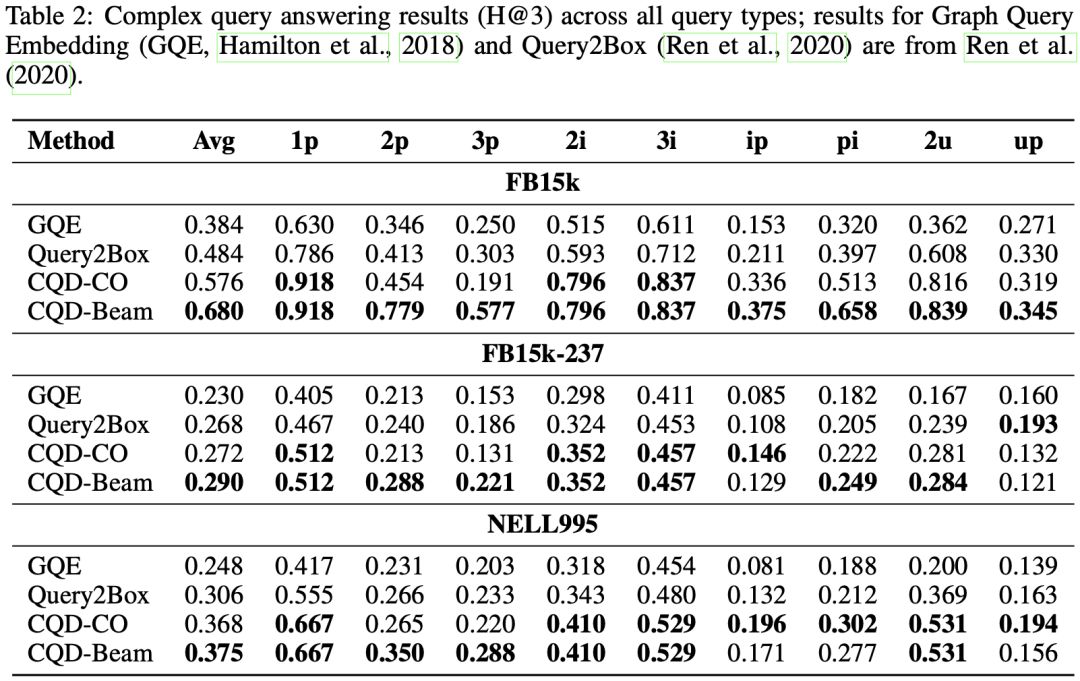
结果
文章二

文章提出了BiQE模型,引入序列化模型Transformer解决一阶复杂逻辑查询中的合取查询问题。
对于逻辑查询的依赖图(一般为有向无环图),文章模型首先将查询的依赖图表示为一个序列。具体来说,将依赖图中的每一个锚节点(已知实体)到每一个汇聚节点(答案实体)的路径作为一个子序列,依赖图中的所有序列组合为一个查询的完整序列。其中,未知的结点视为一个MASK,如图:
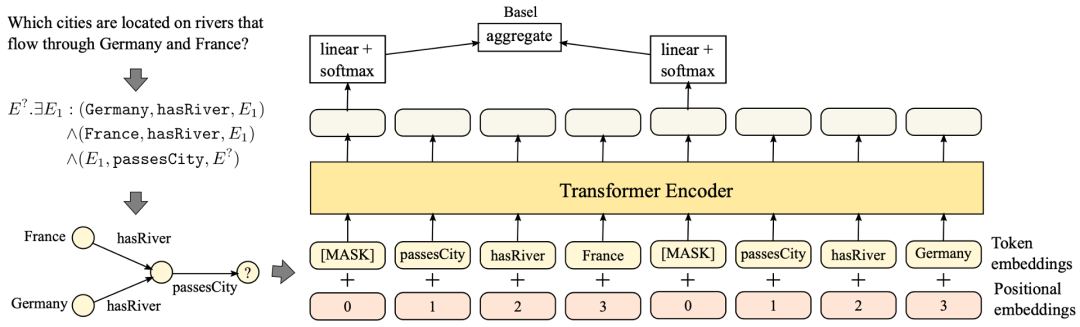
对于一幅依赖图,假设锚节点为m个,汇聚节点有n个,则存在的序列数为mn个。文章将叶子结点到顶点的一条路径视为一个序列,并对路径上的每个节点加入位置编码规则,将每个从锚节点到汇聚节点的序列作为输入,当两个序列中要输出的MASK指向同一个节点时,则使用聚合机制来聚合两个输出的信息。
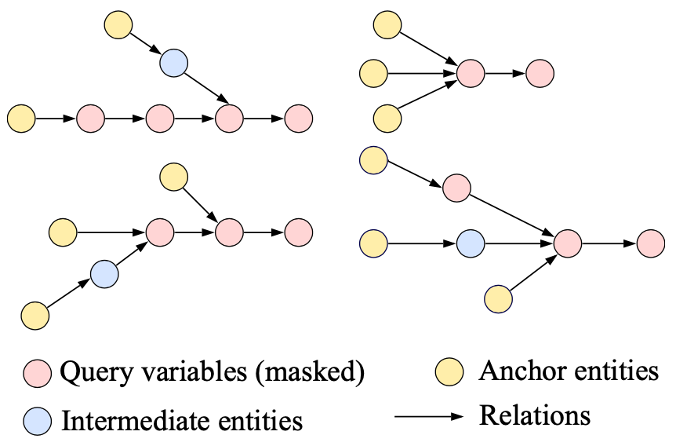
在训练过程中,BiQE模型采样了三元组、路径和有向无环图(如下图所示)作为训练数据
在如下7种只包含合取操作的逻辑查询上测试,在多数查询形式下,该模型都取得了最好效果。
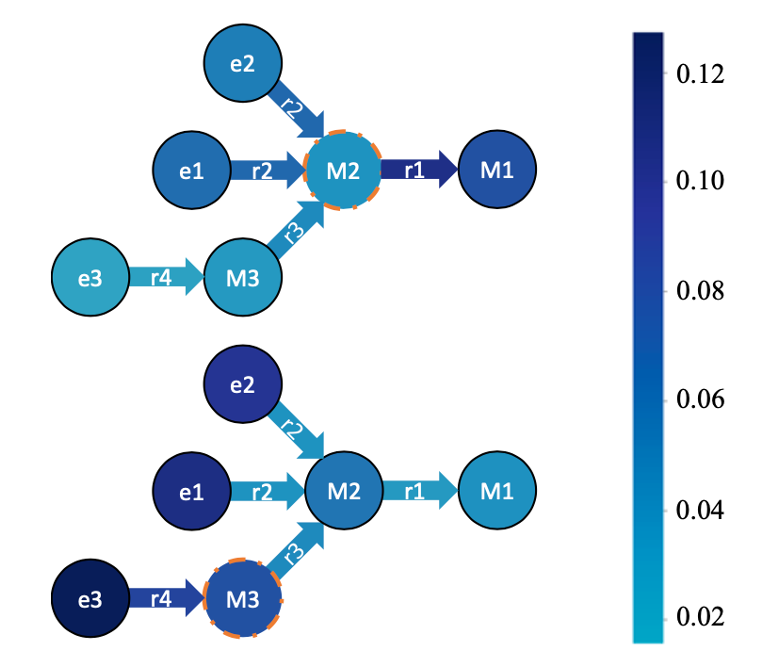
文章认为,Transformer中的注意力机制是带来性能提升的关键因素。如下查询图给出了BiQE模型学习到的中间节点M2和M3与其他节点或关系之间的注意力权重。上图中M2与关系r1、答案实体M1的注意力权重都很高,侧面说明了将M2和M1可以同时被优化;下图中M3与并不是其邻居的节点e3、e1有很高的注意力权重,说明注意力的学习不依赖于连边,说明了BiQE可以学习到更加丰富的关系。
文章三

文章提出了kgTransformer模型,将知识图谱带有属性的关系转换为关系节点,同时将复杂逻辑查询问题看作一个预测mask的问题,通过两阶段预训练对模型进行训练。
kgTransformer解决的核心问题是如何把图表示为序列,使用Transformer进行预训练与微调。在通过随机游走对知识图谱进行采样时,文章将关系连边作为一个关系节点放入随机游走序列中,该关系的头尾实体用有向边与关系节点连接。
kgTransformer的结构与传统Transformer类似,在encoding阶段,通过Multi-HeadAttention计算节点邻居的重要程度,并通过FFN层来进行变换得到最终输出。由于FFN的权重可以看做输入间的重要性关系,但节点间关系是稀疏的。因此,文章定义了多个FFN来模型专家投票的机制(Mix-of-Expert,MoE)。在训练时,通过门控网络(Gatingnetwork)选择权重最大的2个FFN,以保证训练过程中的时间不过长;预测时,将所有的 FFN 结果求和作为最终输出。
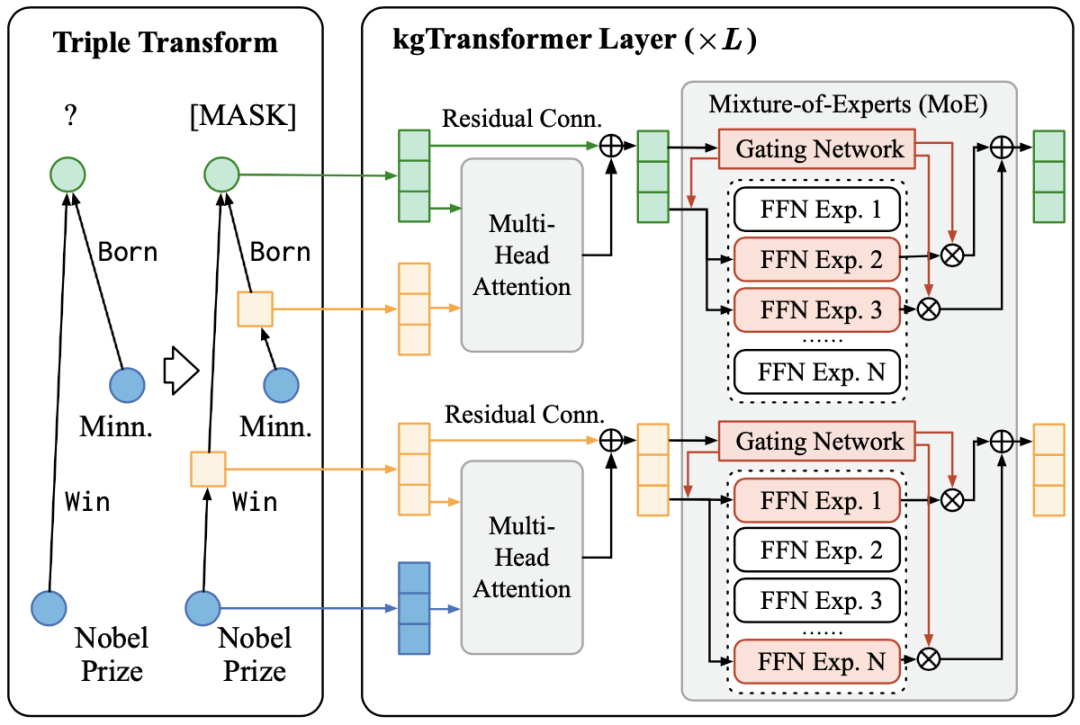
接下来是模型的预训练与微调过程。
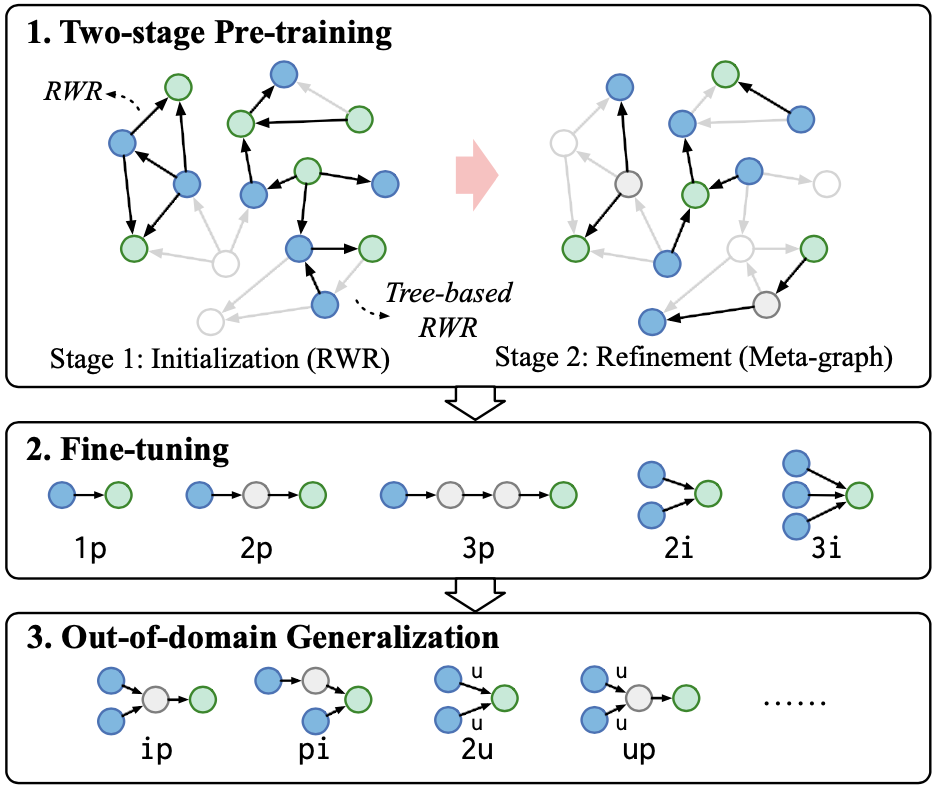
模型预训练分为了两个阶段:第一阶段,利用随机游走采样子图,对模型初始化;第二阶段,使用预先定义好的一些更稀疏的meta-graph结构继续预训练。预训练阶段最小化损失函数如下:
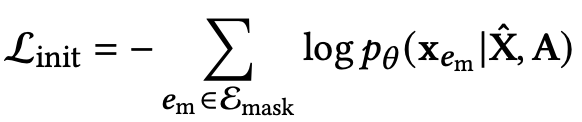
微调阶段使用目标查询形式对模型进行微调,使结果更贴近需要解决的任务。微调阶段损失函数如下:
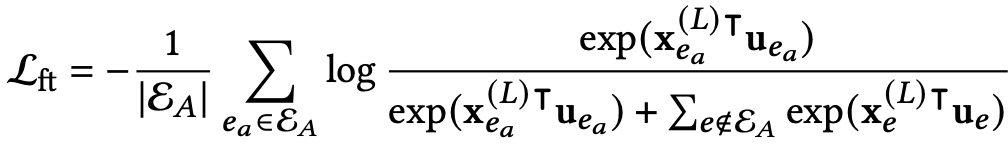
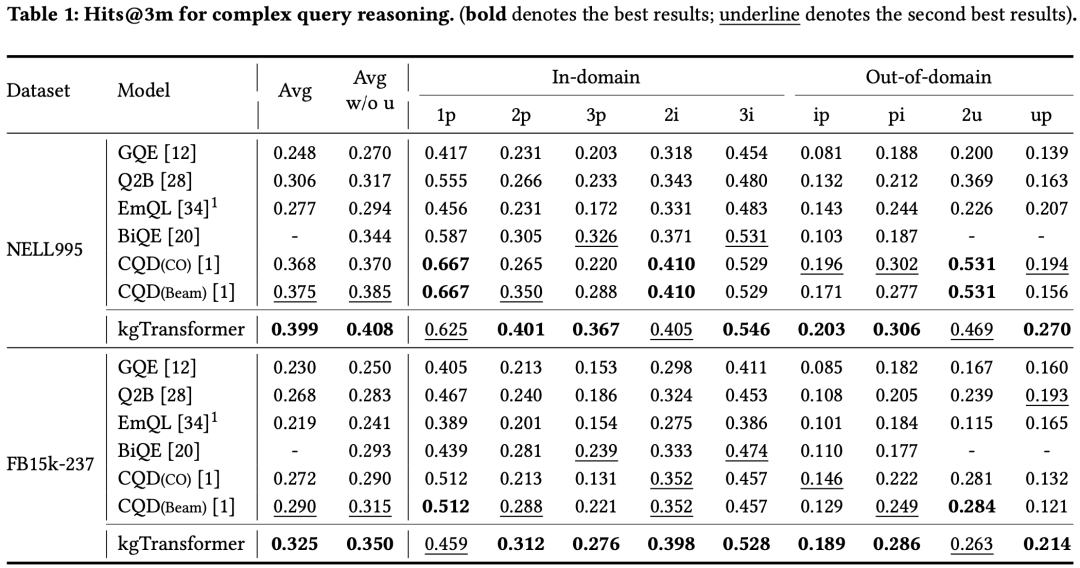
文章在两个数据集上测试了9个查询类型,其中In-domain为微调阶段用于训练的查询类型,Out-domain为微调阶段未使用的查询类型。模型在所有查询类型下均为最优或次优效果。
总结
不完整知识图谱的复杂逻辑查询问题是近几年的研究热门问题。代表性工作通常将查询图与实体嵌入到同一空间中的超形状,来匹配与查询最相近的答案实体。本文介绍了不同于代表性工作的领域最新进展。第一篇文章CQD模型隐式表达了一种预训练的思路,在只使用原子查询进行训练的情况下,依然对查询语句有很好的预测效果;第二篇文章BiQE提出了一种序列化的解决思路,并将Transformer模型应用于知识图谱的逻辑查询问题当中;第三篇文章kgTransformer是预训练模型与Transformer模型的紧密结合,相较于CQD,kgTransformer的预训练过程更加贴合实际任务。
参考文献
[1] Erik Arakelyan, Daniel Daza, Pasquale Minervini, et al. 2021. Complex Query Answering with Neural Link Predictors. In ICLR.
[2] Kotnis B, Lawrence C, Niepert M. 2021. Answering complex queries in knowledge graphs with bidirectional sequence encoders. In AAAI.
[3] Xiao Liu, Shiyu Zhao, Kai Su, et al. 2022. Mask and Reason: Pre-Training Knowledge Graph Transformers for Complex Logical Queries. In SIGKDD.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

