2022年末将至,本文将分为如下六个部分对日常遇到的一些问题进行归纳整理:
- Part A:故障问题处理
- Part B:日常运维相关
- Part C:流复制相关
- Part D:性能优化相关
- Part E:新特性相关
- Part F:第三方工具
Q-A001. 使用pg_basebackup工具或者调用pg_start_backup函数时,好像被卡住,这是什么原因?
问题描述
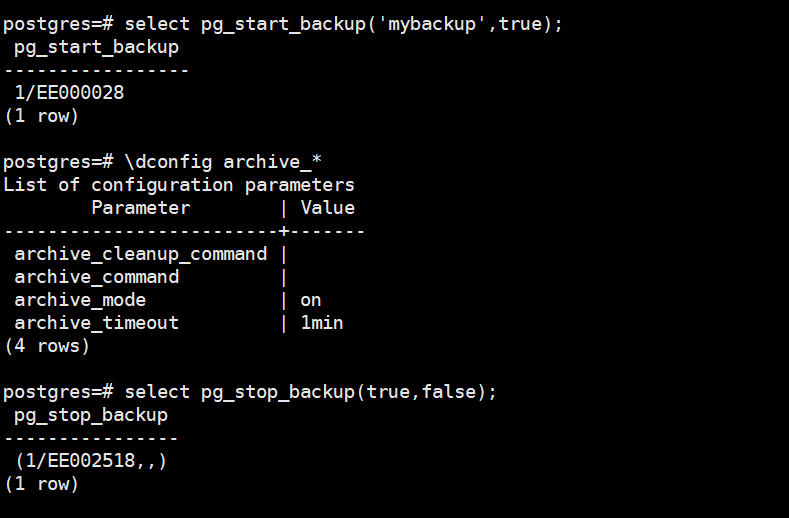
使用pg_basebackup工具进行基础备份或者调用pg_start_backup备份开始函数后,好像立刻被阻塞住了。或者是说为什么基础备份需要执行的checkpoint较慢,而手工在数据库发起checkpoint能很快执行完成。
问题解答
基础备份需要伴随一次checkpoint操作,默认的spread模式会等待定期的checkpoint调度完成,这可能会需要较长的时间(受checkpoint_completion_target以及max_wal_size配置的影响),好处是减少checkpoint带来的大量刷脏,从而减少抖动。坏处是checkpoint操作被拉长。当我们想要快速完成备份,则可以使用fast模式立即执行checkpoint,全速刷脏。好处是快,坏处是如果脏页特别多,可能会有大量IO影响其他会话性能。
pg_basebackup可以使用"–checkpoint=fast",pg_start_backup函数可以使用fast=true来快速完成checkpoint操作。
还有一个相关问题是当我们打开了归档archive_mode=on,但归档命令没有配置正确,例如archive_command配置为空,则调用备份结束函数会一直提示如下告警信息:
NOTICE: base backup done, waiting for required WAL segments to be archived
WARNING: still waiting for all required WAL segments to be archived (60 seconds elapsed)
HINT: Check that your archive_command is executing properly. You can safely cancel this backup, but the database backup will not be usable without all the WAL segments.
...
将archive_command配置正确或关闭归档即可,下面是归档配置正确后正常的输出。

不过即使archive_mode设置为on,归档命令没有配置正确,我们也可以在备份结束函数里设置wait_for_archive为false来完成备份,测试截图如下:
Q-A002. 数据库日志频繁记录“incomplete startup packet”
问题描述
PostgreSQL 10主备同步进程出现故障,观察主库错误日志信息看,有大量的“incomplete startup packet”信息,以及磁盘空间不足的提示。
问题解答
频繁的客户端连接使用了不规范的消息格式导致数据库服务器大量记录“incomplete startup packet”到日志文件,引起磁盘空间写满。
详细分析及建议可以参考:预防客户端bad connection连接
Q-A003. 数据库日志告警"oldest xmin is far in the pass"
问题描述
数据库日志中大量出现"oldest xmin is far in the pass"的告警信息,是什么原因引起呢?
问题解答
经过排查分析得知数据库中存在失效的逻辑复制槽,导致autovacuum不能及时回收旧事务,致使WAL日志占据的磁盘空间越来越大。大量的warning事件也引起数据库日志文件迅速增长,日志占据的磁盘空间也越来越大。
解决方案:与业务确认复制槽使用情况,如需继续使用,需要立即进行修复。如确认不再使用,及时使用pg_drop_replication_slot函数删除。
Q-A004. 统计信息收集进程没有正常启动
问题描述
数据库日志观察到如下关键信息:
disabling statistics collector for lack of working socket
问题解答
请检查/etc/hosts配置文件,参考案例:<<故障:autovacuum和stats collector进程未正常启动>>
Q-A005. 统计信息收集进程偶尔失去反应,是否影响数据库的写入或数据损坏?
问题描述
PostgreSQL 15之前的版本数据库日志偶尔或者较频繁可以观察到如下的日志:
LOG: using stale statistics instead of current ones because stats collector is not responding
这是否正常,会影响数据库写入或导致数据损坏呢?
问题解答
不会影响数据库数据写入的完整性,这只是意味着统计信息收集进程反应不够快,可能是IO负载较高,通过修改stats_temp_directory参数指向一个单独的目录分区可以解决这个问题。
Q-A006. 数据库升级到PG 14之后,为什么很多应用软件连接失败?
问题描述
已经遇到过几次客户反馈PG数据库连接失败的问题,为什么只有升级到14,而其他版本没有出现呢?
问题解答
如果我们有关注14的新特性变化可以知道SCRAM-SHA-256现在已经是客户端认证的默认方式了,在此之前一直是MD5。其实从PG 10开始就已经支持SCRAM-SHA-256,只不过默认方式还是MD5,并且伴随PG 10的发布,配套的客户端驱动也有更新支持。
随着PG 15已经发布第二个小版本,越来越多客户开始使用PG 14,升级之后记得首先检查客户端驱动是否已更新支持SCRAM-SHA-256。
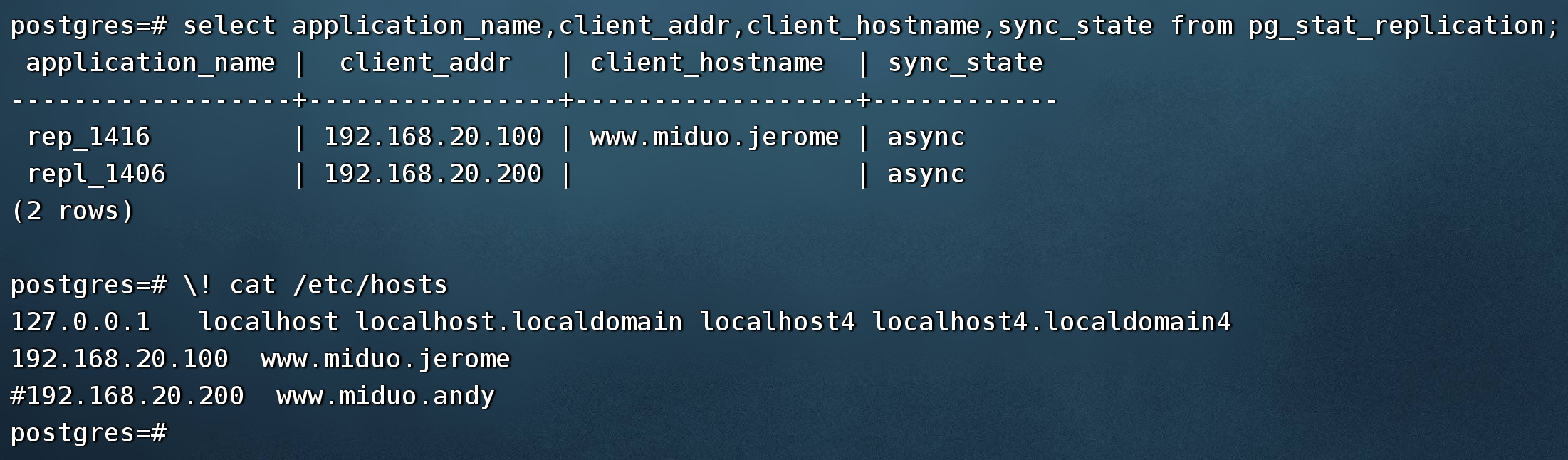
Q-A007. pg_stat_replication.client_hostname字段为什么没显示值?
问题描述
在主备环境下,打开了数据库参数log_hostname=on,备库操作系统也设置了hosts条目,但是主库查询pg_stat_replication系统视图client_hostname字段确没有显示值。
问题解答
数据库里显示hostname,除了打开log_hostname参数,备库的hostname也需要在主库的操作系统层进行设置。
示例如下:模拟两个备库,分别在主库节点100和节点200,主库只配置了节点100的hostname,节点200的被注释,那节点100能正常显示hostname,节点200则不能。
Q-B001. 如何修改客户端编码为GBK?
问题描述
一些场景下,如何永久将client_encoding由默认的UTF8修改为GBK?试过使用alter user … set client_encoding或者alter database…set client_encoding都不生效。
问题解答
参考官方文档的这段描述
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
使用环境变量PGCLIENTENCODING可以解决:
export PGCLIENTENCODING='GBK'
也可以再psql连接串进行设置
$ psql "dbname=postgres client_encoding=GBK"
Q-B002. 非UTF-8编码的数据库如何生成随机汉字?
问题描述
在UTF-8编码的数据库里可以使用chr函数基于unicode码来随机生成汉字:
postgres=# select chr(int4(random()*20901)+19968);
chr
-----
盾
(1 row)
而非UTF-8编码的数据库则不能使用chr函数。
问题解答
例如在euc_cn编码的环境下我可以根据GBK的区位码规则封装如下函数来生成随机汉字:
create or replace function chr_euc_cn()
returns text
as $function$
declare
hight_pos text;
low_pos text;
begin
hight_pos = to_hex((176+random()*71)::int4);
low_pos = to_hex((161+random()*93)::int4);
return convert_from(decode(hight_pos||low_pos, 'hex'), 'euc_cn');
end;
$function$ language plpgsql;
测试结果如下:
db_chinese=# select chr_euc_cn();
chr_euc_cn
------------
茏
(1 row)
db_chinese=# select chr_euc_cn();
chr_euc_cn
------------
括
(1 row)
Q-B003. 多行查询如何在COPY中优雅的使用
问题描述
使用元命令\copy处理较长的复杂查询语句生成的结果集时,要么我们借助临时表,要么我们需要对多行语句进行编辑,调整到一行,这是一件非常头疼的事儿!
问题解答
其实我们还有这种方式:
postgres=# copy (
select *
from foo
where id<300
) to stdout with csv header \g foo.csv
COPY 5
- 虽然\copy不支持多行查询,但copy支持。
- copy结果除了输出到文件也可输出到标准输出stdout
- 使用\g将标准输出的内容写入到本地文件
结合这三点,可以优雅的处理多行查询。
Q-B004. PG里如何自动记录行版本的修改时间?
问题描述
从DB2或MySQL迁移时会遇到ROW CHANGE TIMESTAMP或ON UPDATE CURRENT_TIMESTAMP的问题,在PG里如何实现呢?
问题解答
DB2或MySQL自动记录数据行修改的时间在PG里没有直接对应的特性,一种方式是通过触发器去实现的,另外一种方式是借助存储列的功能:
create table test1(
id int primary key,
info text,
crt_time timestamp not null default now(),
mod_time timestamp GENERATED ALWAYS AS (wrapper_im_now(id,info)) stored
);
上面wrapper_im_now函数的定义如下:
CREATE OR REPLACE FUNCTION public.wrapper_im_now(VARIADIC "any")
RETURNS timestamp with time zone
LANGUAGE internal
IMMUTABLE PARALLEL SAFE STRICT
AS $function$now$function$;
test1表info字段修改会触发自动更新存储列mod_time,如果还有其它字段希望触发,可以直接添加到wrapper_im_now函数的参数列表里。
PG里存储列和生成列示例可扩展阅读这篇文章:
<<PostgreSQL标识列及存储列示例>>
Q-B005. PSQL如何自适应查询结果集?
问题描述
Oracle的SQL Plus操作都习惯先使用col name for来进行查询预设置,PG里是否有对应的设置呢?
问题解答
SQL Plus对应到PSQL,比较常见的方式是使用扩展模式竖排显示:
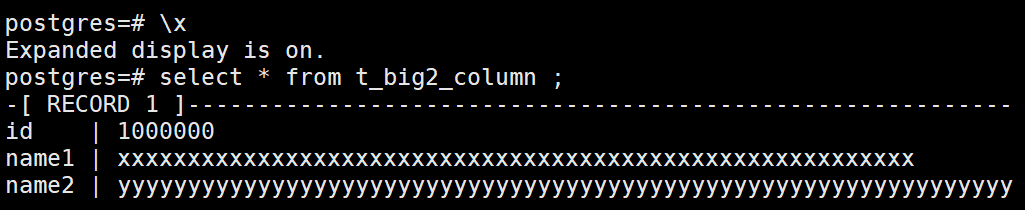
另外一种方式,直接用表名单列显示整行数据:

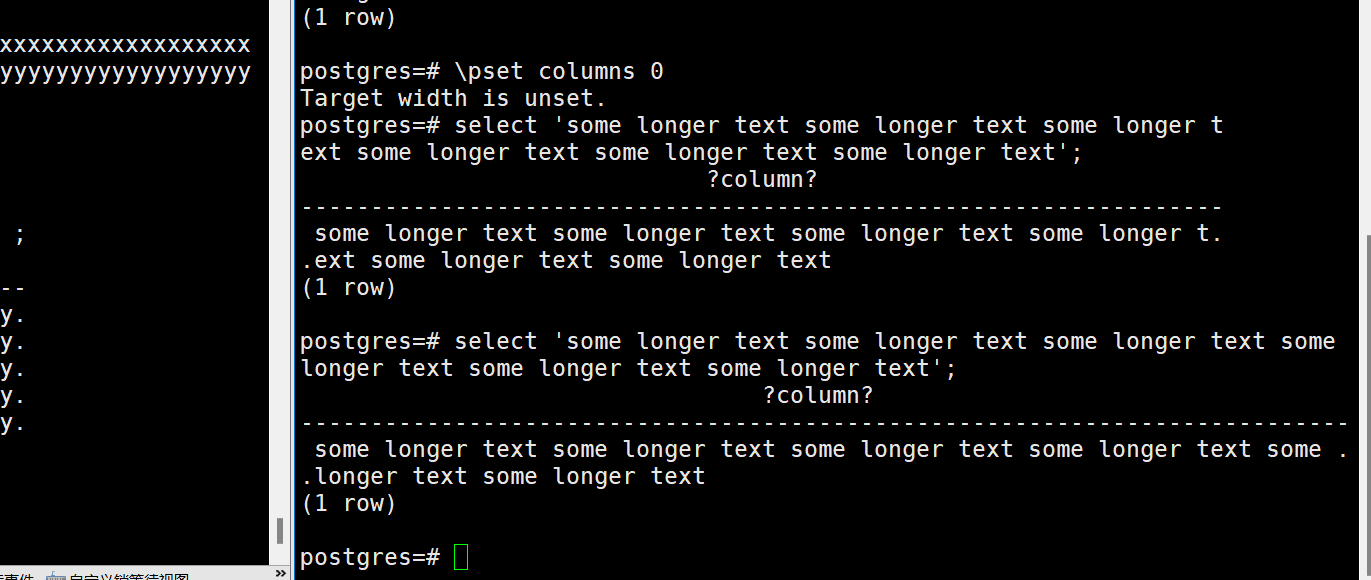
第三种方式,查看\pset相关参数,可以使用下面的两条命令来处理
\pset format wrapped
\pset columns 0
format在wrapped模式下设置columns,columns设置为0,可根据屏幕宽度自动调整,效果如下:
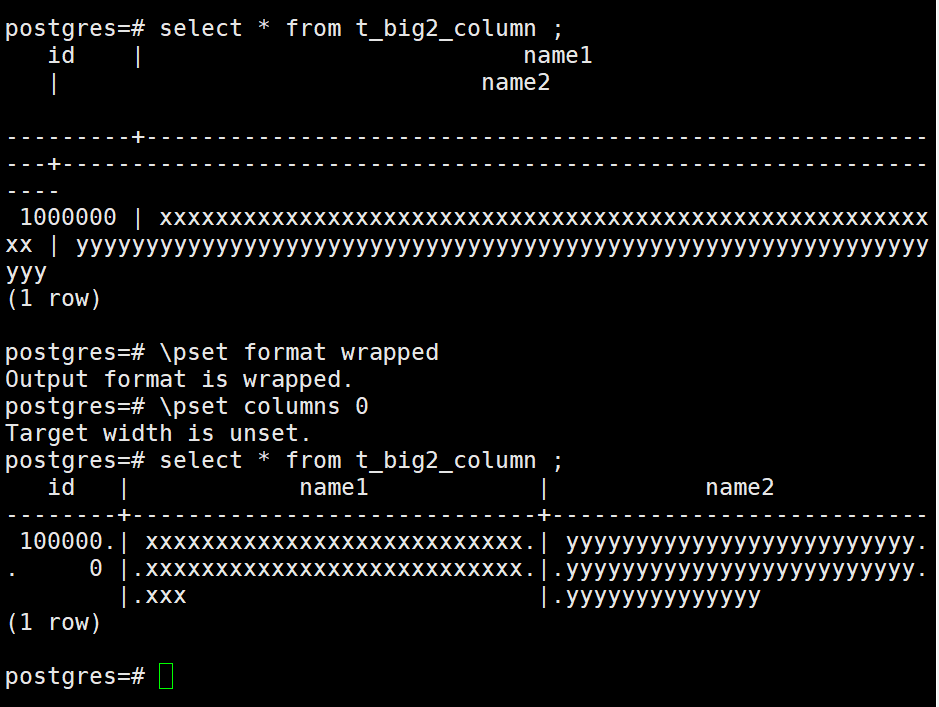
下面的图是拖动窗口之后的自适配效果:
Q-B006. PSQL里查询结果如何美化输出格式?
问题描述
看到有的PG文章里显示的PSQL查询结果比较美观:
搜索了一下,可能使用了下面的这个插件
https://postgres.cz/wiki/Pretty_borders_in_psql
不过这个插件现在下载不了。
问题解答
查看相关文档,使用下面两个设置。
\pset linestyle unicode
\pset border 2
对比下面默认的输出格式,上面的效果还是更美观一些。
Q-B007. PSQL连接串如何设置search_path?
问题描述
使用shell脚本中在程序中调用psql,希望使用psql的连接串修改查询路径,让脚本创建的表都存放到设置的模式下。
问题解答
查看libpq的接口文档
https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-PARAMKEYWORDS
发现不能直接设置该参数,但是可以通过options进行设置:
[postgres@pg ~]$ psql "dbname=postgres options=-csearch_path=public"
psql (15.1)
Type "help" for help.
postgres=# show search_path;
search_path
-------------
public
(1 row)
Q-B008. 如何获取序列的当前值?
问题描述
首次获取序列的值需要先调用nextval来获取值,跨session不能使用currval来调用当前值,难道必须使用nextval推进才能正常获取吗?
问题解答
PG 10中添加了pg_sequences视图,便于获取序列的动态信息,可以通过last_value来获取当前值。
postgres=# select last_value from pg_sequences
where sequencename='s2_id_seq';
last_value
------------
1
(1 row)
也可以把序列当成表一样直接查last_value
postgres=# select last_value from s2_id_seq;
last_value
------------
1
(1 row)
还可以使用pg_sequence_last_value函数
postgres=# select pg_sequence_last_value('s2_id_seq');
pg_sequence_last_value
------------------------
1
(1 row)
Q-B009. 根据表名如何定位在哪些数据库的哪些schema下?
问题描述
需要根据表名确认一张表属于哪个database,哪个schema?
问题解答
PG中可以使用多个database,所以需要遍历所有db进行查找,语句如下:
for db in `psql --pset=pager=off -t -A -q -c 'select datname from pg_database where datname not in ($$template0$$, $$template1$$)'`
do
psql -d $db --pset=pager=off -q -c 'select current_database(),schemaname from pg_stat_user_tables where relname=$$mydb_tab1$$;'
done
实际查找时替换表名即可。
Q-B010. 如何根据序列名获取表及列信息?
问题描述
当我们知道序列名称,我们想获取是哪个表或者表上的哪个列在使用这个序列,目前在PG里并没有元命令可以直接查询,pg_class或者pg_sequence系统表也没有记录。
问题解答
可以使用如下语句:
select ts.nspname as object_schema,
tbl.relname as table_name,
col.attname as column_name,
s.relname as sequence_name
from pg_class s
join pg_namespace sn on sn.oid = s.relnamespace
join pg_depend d on d.refobjid = s.oid and d.refclassid='pg_class'::regclass
join pg_attrdef ad on ad.oid = d.objid and d.classid = 'pg_attrdef'::regclass
join pg_attribute col on col.attrelid = ad.adrelid and col.attnum = ad.adnum
join pg_class tbl on tbl.oid = ad.adrelid
join pg_namespace ts on ts.oid = tbl.relnamespace
where s.relkind = 'S'
-- and s.relname = 'sequence_name'
and d.deptype in ('a', 'n');
另外我们也可以借助.psqlrc文件封装快捷命令来进行调用,.psqlrc文件内容格式
\set short_command 'SQL; '
封装带参数的快捷命令get_table_name_by_seqname
\set get_table_name_by_seqname 'select ts.nspname as object_schema,tbl.relname as table_name, col.attname as column_name,s.relname as sequence_name from pg_class s join pg_namespace sn on sn.oid = s.relnamespace join pg_depend d on d.refobjid = s.oid and d.refclassid=''pg_class''::regclass join pg_attrdef ad on ad.oid = d.objid and d.classid = ''pg_attrdef''::regclass join pg_attribute col on col.attrelid = ad.adrelid and col.attnum = ad.adnum join pg_class tbl on tbl.oid = ad.adrelid join pg_namespace ts on ts.oid = tbl.relnamespace where s.relkind = ''S'' and d.deptype in (''a'', ''n'') and s.relname = :'''v_seqname''' ;
保存到.psqlrc文件后重新使用psql工具连接测试
先需要设置变量参数值
\set v_seqname t_id_seq
然后调用快捷命令
:get_table_name_by_seqname
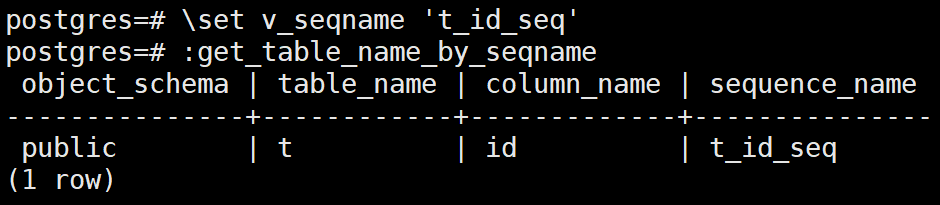
可以看到根据序列名获取到了所需的信息。
Q-B011. 如何定义大对象以及查看一个库中有哪些表使用大对象类型的字段?
问题描述
PostgreSQL中如何使用大对象,如何查找哪些表的哪些字段使用了大对象类型。
问题解答
PostgreSQL中大对象需要使用lo类型,可以参考这篇文章:PostgreSQL二进制类型存取测试。
查找大对象类型可以使用如下语句:
select attrelid ::regclass, attname, atttypid ::regtype
from pg_attribute
where attnum > 0
and attisdropped = 'f'
and atttypid='lo'::regtype;
Q-B012. character类型有哪些别名?
问题描述
PostgreSQL里character类型有哪些别名?
问题解答
PostgreSQL里character类型可以使用char(n)和bpchar(n) (blank-padded char),bpchar是数据库内部使用的一种类型,使用char、bpchar类型,数据库都会转换为character类型。
Q-B013. DDL如何防止SQL注入?
问题描述
JDBC可以使用PreparedStatement对DML进行语句预编译来防注入,但DDL是失效的。
问题解答
可以采用动态语句变通实现,使用函数封装:
CREATE OR REPLACE FUNCTION public.f_enum_add_val(enmu_val character varying)
RETURNS void
LANGUAGE plpgsql
AS $function$
begin
execute format('alter type currency add value %L ',enmu_val);
end;
$function$;
Q-B014. UPSERT如何更新整行数据?
问题描述
当我们使用INSERT INTO … ON CONFLICT … DO UPDATE,对主键重复的记录行进行值覆盖时,需要使用excluded作为前缀,字段较多时比较繁琐,如果对整行进行覆盖,是否有更好的方式?
问题解答
整行可以使用excluded.*进行操作,测试语句如下:
CREATE TABLE t (id int primary key, info text);
INSERT INTO t VALUES (1, 'A');
INSERT INTO t values (1, 'B') ON CONFLICT (id) DO UPDATE SET (id, info) = ROW(excluded.*);
Q-B015. PG里使用ANY替代IN有什么好处?
问题描述
IN是一个很常用的SQL操作符, 不过使用IN会有一些限制:对于标量表达式的变量列表,如果发送5个标量,必须写成IN ($1, $2, $3, $4, $5)。
除此以外,变量列表的个数也有限制,不能超过32768,否则会报错如下:
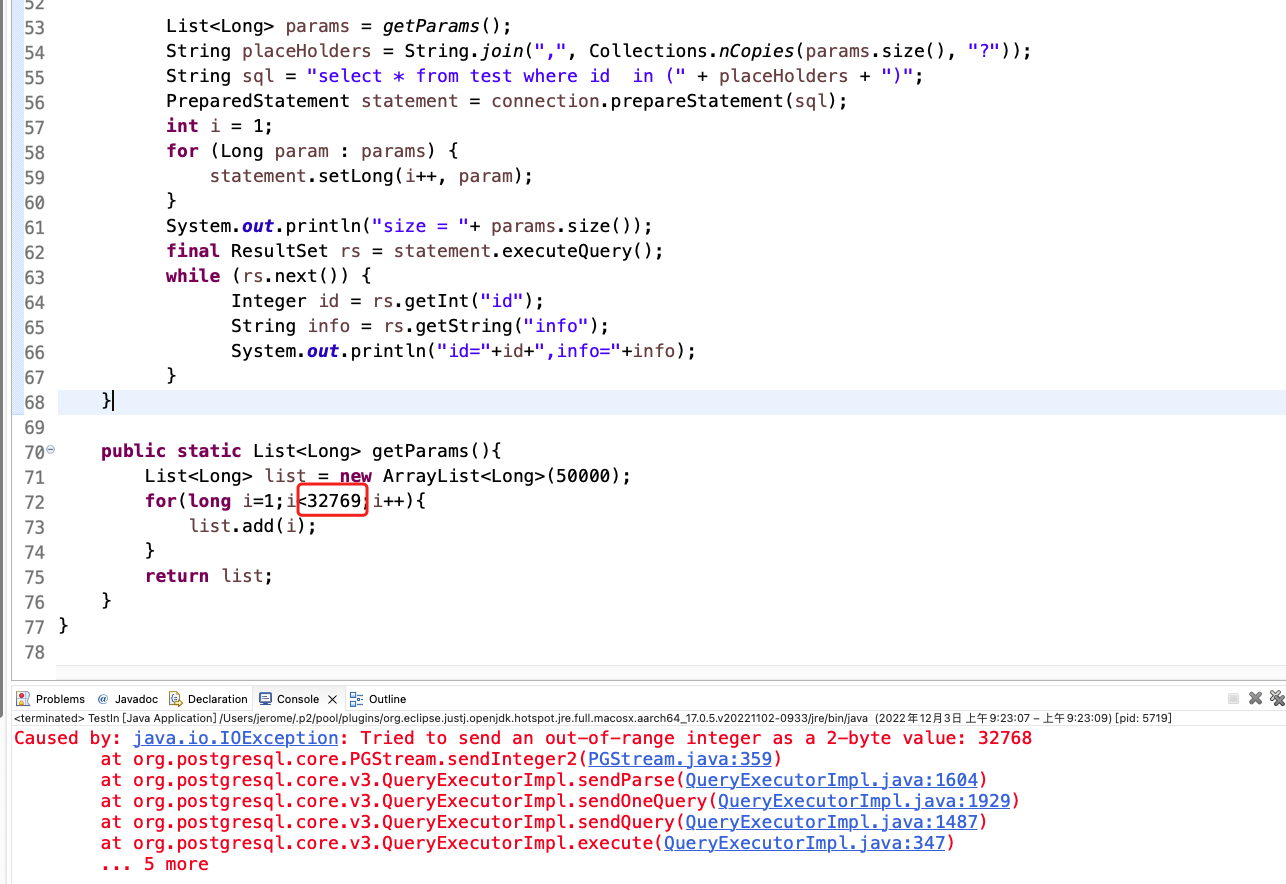
问题解答
如果我们把IN (…)等价替换为 ANY (…),数组可以作为单个参数绑定到ANY,就没有这个限制了。除了参数绑定之外,以下运算符也支持:
foo LIKE ANY ('{"%bar", “%baz”}')
foo ILIKE ANY ('{"%bar", “%baz”}')
id <> ANY ('{1, 2, 3}')
IN多值查询替换为ANY数组单个变量的方式除了突破变量列表个数的限制之外,还能提高性能。优化器也会在内部对IN改写为ANY。
Q-C001. recovery模式和standby模式有什么区别?
问题描述
PostgreSQL里经常能看到recovery模式和standby模式,这两种模式有什么区别呢?
问题解答
recovery模式是一种恢复应用WAL的过程状态,standby模式是主从架构下的一种只读模式,可以提供查询。
Q-C002. PITR配置恢复相关的参数是否可以配置在触发文件里?
问题描述
PostgreSQL 12之前的recover.signal或者12开始的standby.signal文件是否可以配置restore_command等相关参数,还是需要同时配置recovery.conf或者postgresql.conf。
问题解答
触发文件不需要配置,一般是一个空文件,如果配置恢复相关的参数,不会起作用,正确的方式是配置在recovery.conf文件(版本<12),或者postgresql.conf(版本>=12)。
Q-C003. PostgreSQL里是否可以单独做归档备份?
问题描述
PostgreSQL备份数据除了使用pg_basebackup进行基础备份以外,是否可以只备份归档文件,从而节省磁盘空间呢?
问题解答
可以使用pg_receivewal的工具在线备份wal起到虚拟备库的功能,它比使用归档命令备份WAL更加安全,也不需要等待WAL文件写满。该工具基于流复制协议流式传输WAL,当服务器重启时不会发生数据丢失或数据损坏,并且搭配-Z/–compress压缩选项更适合。
Q-C004. 物理备份和恢复的大版本不一致,能否恢复成功?
问题描述
例如用pg_basebackup在14版本备份了一个实例,能否恢复到版本12的机器上,或者12版本用pg_basebackup备份,能否恢复到14版本的机器上。
问题解答
不可以,物理备份恢复的大版本必须匹配。PostgreSQL有版本碰撞机制,启动数据目录时会进行检查,另外在同一个大版本的不同beta版本也会有这个触发机制。
Q-C005. 主备延迟大,有什么方法可以加快备库回放的速度?
问题描述
逻辑复制场景下,主备延迟较大,有什么方法可以加快备库回放的速度?
问题解答
有两个方法可以尝试:
- 增大逻辑解码的内存参数logical_decoding_work_mem
- 使用PostgreSQL 14的streaming特性开启订阅
Q-D001. 游标可以跨事务使用吗?
问题描述
通常游标只能存在于数据库transaction范围内:因为游标就是单一的SQL语句,SQL语句总是事务的一部分,游标在事务结束后会自动关闭。但有些场景是否可以跨transaction使用游标呢?
问题解答
PostgreSQL 11开始对procedure支持WITH HOLD特性的游标,使用WITH HOLD,可以突破单个transaction这个限制,这个特性比较有用,但我们必须要考虑commit对性能的影响,并且记得close游标,释放资源。
Q-D002. 子事务有什么危害?
问题描述
子事务对应的功能是savepoint,即使不显式使用savepoint,存储过程中的begin… exception块也会隐式的引入子事务,那么子事务有什么危害?
问题解答
子事务的危害:
- 事务ID快速增长,增加事务ID回卷风险
- 逻辑订阅场景下,可能产生大量临时小文件(逻辑复制槽目录过快产生.spill落盘文件)
- 单个会话中子事务数超过64后,进入suboverflow状态,高并发场景下可能导致数据库整体性能大幅下降
建议谨慎使用子事务,特别是在大事务,长事务中。
Q-D003. 一个事务频繁更新同一行有什么危害?
问题描述
在PostgreSQL中,在一个事务中频繁更新同一行有什么危害?
问题解答
生产环境中在一个事务里频繁对单行数据进行更新操作会引起vacuum问题,此时基于触发器统计更新数据会变得越来越慢,一个较好的方式可以使用触发器的过渡表特性,使用一条语句进行批量处理。
https://www.cybertec-postgresql.com/en/why-are-my-postgresql-updates-getting-slower/
Q-D004. combined indexes 和 multicolumn indexes有什么区别?
问题描述
什么时候使用combined indexes(组合索引),什么时候使用multicolumn indexes(多列索引)?
问题解答
多列索引是指一个索引定义在表的多个列上,例如
CREATE INDEX idx_test_multi ON test (a, b);
组合索引是指查询时可以使用多个索引,例如下面的语句:
postgres=# explain (costs off) select * from t where a <= 100 and b = 'x';
QUERY PLAN
--------------------------------------------------
Bitmap Heap Scan on t
Recheck Cond: ((a <= 100) AND (b = 'x'::text))
-> BitmapAnd
-> Bitmap Index Scan on t_a_idx
Index Cond: (a <= 100)
-> Bitmap Index Scan on t_b_idx
Index Cond: (b = 'x'::text)
(7 rows)
从执行计划观察查询规划器执行两个位图索引扫描,然后通过BitmapAnd将它们组合成用于扫描堆表。
基于组合索引的位图扫描虽然高效,但每次额外的位图扫描都会增加总查询的成本。多列索引更有针对性,通常返回的结果也更少,这意味着更高效的扫描效率。总体来说多列索引适用于查询结果少,组合索引更针对复杂查询。
关于使用索引的扩展阅读推荐: <<[译] 通过Postgres索引创建理解操作符类及索引类型等概念>>
Q-D005. 使用with查询,对数据库的性能有什么影响?
问题描述
PostgreSQL 研发的人员经常使用with查询,这个操作有什么影响吗?
问题解答
首先with查询是一个标准用法,PostgreSQL、MySQL、Oracle、SQL Server等都支持。
with子句可以看作是一个查询语句在内存中的临时表。在内存中解析,提高执行效率,并且提高SQL语句的可读性,用完即销毁。
with查询常见使用场景的递归查询,比如查询动态菜单树。对性能的影响要看具体语句写法,通常对复杂的语句是可以提速的。递归查询的示例可以参考:PostgreSQL递归查询
Q-D006. pg_stat_activity视图backend_xid和backend_xmin有啥区别?
问题描述
pg_stat_activity视图的backend_xid和backend_xmin官方文档的解释看不明白,如何用大白话解释。
问题解答
从名称的差异来体会:
- backend_xid表示是当前获取到的事务ID,只有查询语句实际对数据库有修改操作时事务管理器才分配生成。
- backend_xmin与事务快照相关,借助事务快照,PG可以确定元组可见性,生产环境应主要关注backend_xmin。
事务快照形式:
xmin:xmax:xip_list
- xmin: “visible since”,活动事务的最旧事务ID。
- xmax: “visible until”,活动事务的最新事务ID。
- xip_list: 所有活动事务ID列表。
Q-E001. PostgreSQL秒能精确到纳秒吗?
问题描述
PostgreSQL里时间类型timestamp能精确到纳秒吗?
问题解答
时间类型timestamp只能存储到微秒,同时SQL标准2016定义了FF1-FF6时间格式,从PostgreSQL 13开始得到了支持,FF1-FF6表示时间数据类型秒后的第一位到第六位,比如FF6就是最高精度微秒。
postgres=# SELECT now(),
to_char(now(),'HH24:MI:SS.FF1'),
to_char(now(),'HH24:MI:SS.FF2'),
to_char(now(),'HH24:MI:SS.FF3'),
to_char(now(),'HH24:MI:SS.FF4'),
to_char(now(),'HH24:MI:SS.FF5'),
to_char(now(),'HH24:MI:SS.FF6');
-[ RECORD 1 ]--------------------------
now | 2022-09-25 08:53:18.443337+08
to_char | 08:53:18.4
to_char | 08:53:18.44
to_char | 08:53:18.443
to_char | 08:53:18.4433
to_char | 08:53:18.44333
to_char | 08:53:18.443337
Q-E002. 如何强制删除数据库?
问题描述
PostgreSQL中在持续有客户端连接的情况下,是否可以强制删除数据库呢?
问题解答
PostgreSQL 13对DROP DATABASE添加了一个FORCE选项,允许在有客户端连接的情况下强制删除数据库,语法如下:
DROP DATABASE database_name WITH (FORCE);
注意:如果目标数据库中存在prepared transaction、活动的逻辑复制槽或subscriptions,则 DROP DATABASE强制删除会失败。
Q-E003. PG 14的pg_surgery插件有什么用途?
问题描述
有客户想了解PG 14有什么新增的扩展插件,有什么用途。
问题解答
查看了一下官方文档及资料,先总结了一张最新的各版本新增插件图。
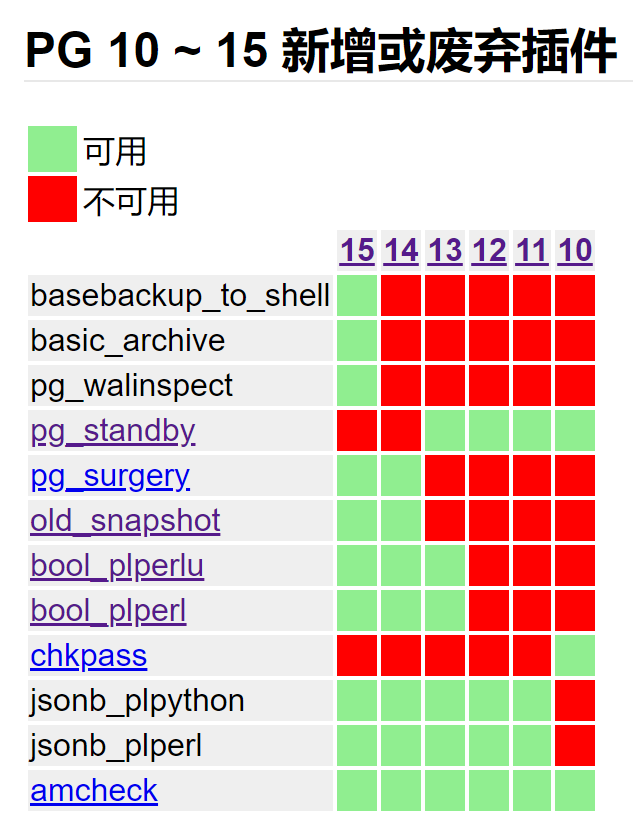
关注到pg_surgery可以与pg_dirtyread很好的搭配起来恢复delete的数据。
下面是参考示例:
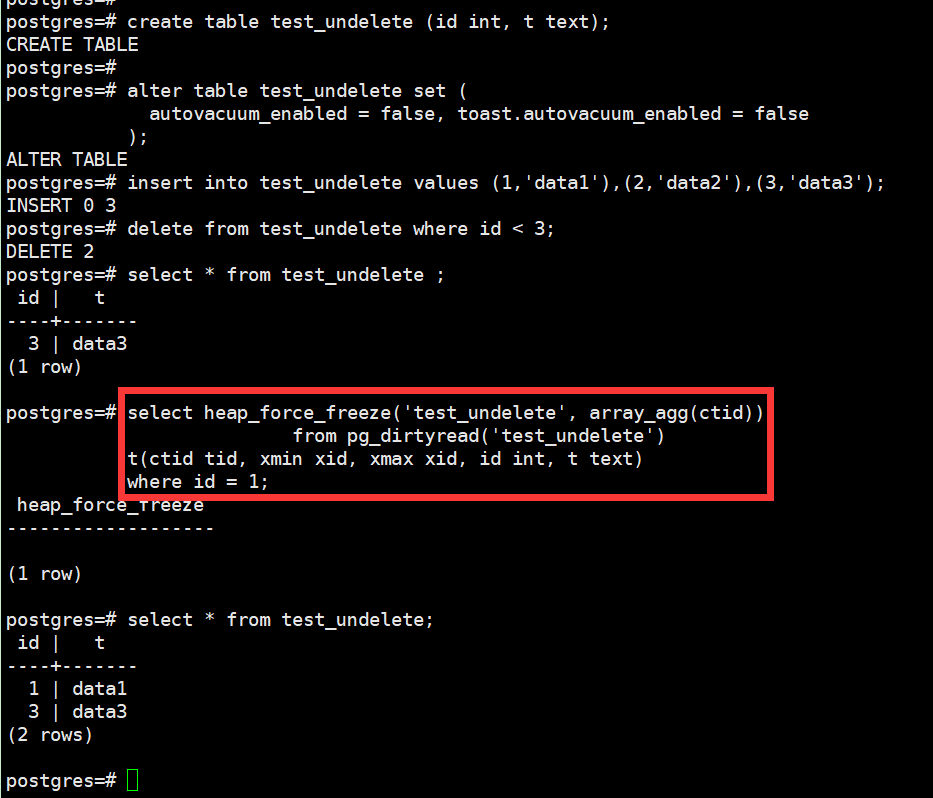
Q-E004.创建数据库会触发检查点吗?
问题描述
在我们创建数据库的过程中,会触发检查点将缓冲区的脏数据刷写到存储吗?
问题解答
PostgreSQL 15之前创建数据库会立刻触发检查点,数据库日志会看到如下的片段信息:
checkpoint starting: immediate force wait flush-all
PostgreSQL 15创建数据库时新增了strategy参数,该参数的默认值是wal_log,也就是对模板数据库数据文件通过写wal的方式逐个拷贝数据块。这种方式可以避免立刻触发检查点。
Q-E005. PSQL如何模糊查看参数值?
问题描述
在PostgreSQL中,是否有类似show all | grep 参数命令过滤参数?
问题解答
PostgreSQL15版本新加了\dconfig元命令,可以使用该元命令模糊查询参数值。
postgres=# \dconfig vacuum*
List of configuration parameters
Parameter | Value
-----------------------------------+------------
vacuum_cost_delay | 0
vacuum_cost_limit | 200
vacuum_cost_page_dirty | 20
vacuum_cost_page_hit | 1
vacuum_cost_page_miss | 2
vacuum_defer_cleanup_age | 0
vacuum_failsafe_age | 1600000000
vacuum_freeze_min_age | 50000000
vacuum_freeze_table_age | 150000000
vacuum_multixact_failsafe_age | 1600000000
vacuum_multixact_freeze_min_age | 5000000
vacuum_multixact_freeze_table_age | 150000000
(12 rows)
Q-E006. 参数allow_in_place_tablespaces有什么作用?
问题描述
PostgreSQL 15包括14.5, 13.8, 12.12, 11.17, 10.22新增了allow_in_place_tablespaces参数,它有什么作用,使用场景是什么呢?
问题解答
该参数可以开启表空间的"in place"功能,数据直接存储在pg_tblspc目录里面,在一些开发测试场景能比较方便的处理自定义表空间的问题,尤其是在同一台机器上。
例如当我们使用pg_basebackup做备份时,可能会遇到如下错误
$ pg_basebackup --pgdata=datarec
pg_basebackup: error: directory "/home/postgres/test_spc1" exists but is not empty
pg_basebackup: removing data directory "datarec"
基础备份拷贝PGDATA时也对pg_tblspc用户自定义表空间符号链接进行拷贝,同一台机器上会有冲突。
因此需要使用–tablespace-mapping选项来进行表空间目录映射:
$ pg_basebackup --pgdata=datarec \
--tablespace-mapping=/home/postgres/test_spc1=/home/postgres/test_spc2
多个用户自定义表空间需要多次使用–tablespace-mapping进行映射。
下面打开allow_in_place_tablespaces参数
postgres=# ALTER SYSTEM SET allow_in_place_tablespaces TO true;
ALTER SYSTEM
postgres=# SELECT pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
然后创建表空间时location设置为空
postgres=# create tablespace myspace location '';
CREATE TABLESPACE
此时直接在pg_tblspc里面生成表空间文件目录来存储数据。
$ ls -l /opt/pgdata1405/pg_tblspc/
total 0
drwxr-x--- 3 postgres dba 29 Oct 26 12:02 623641
Q-F001. 使用pg_cron定时任务插件时,为什么任务延迟了8个小时呢?
问题描述
我的定时任务使用了pg_cron插件,发现任务都延时了8个小时,为什么呢?
问题解答
pg_cron插件采用GMT时间,数据库的时区不一致因此体现出延迟。
Q-F002. repmgr中执行switchover切换报错:无法执行checkpoint。
问答链接参考:
https://www.modb.pro/issue/17000
问题描述
repmgr中执行switchover切换使用–force-rewind时有一个错误提示:
ERROR: unable to execute CHECKPOINT
问题解答
参考repmgr官方文档描述,为了防止切换时未干净关库,使用–force-rewind选项可以在必要时用pg_rewind工具进行主备数据同步,执行checkpoint操作需要repmgr用户具有superuser权限,也可以使用-S/–superuser指定超级用户手工验证确认改问题。
Q-F003. repmgr执行switchover时为什么提示pg_is_in_backup()函数不存在?
问题描述
使用repmgr 5.3.1对PG 15执行switchover时提示pg_is_in_backup()函数不存在,错误截图如下:
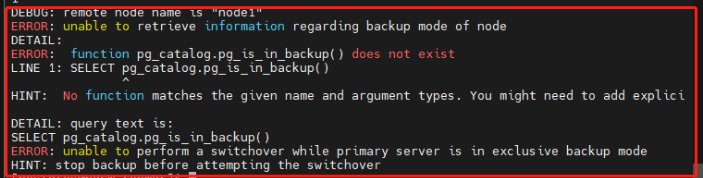
问题解答
从PG 15开始,与排他性备份模式相关的pg_is_in_backup()函数已经被废弃删除了。我们查看repmgr对PG的版本支持情况可以看到repmgr 5.3.3开始支持PG 15。