




语文辅导的重要帮手
春游活动作文

写一件人与人之间真正关心帮助的事

现代诗歌也是信手拈来

有古韵风味的诗词也不再话下

一首《春天的校园》也很惊艳

精通数学的解题能手
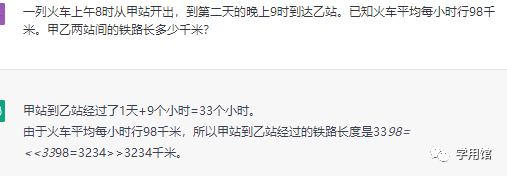
题一:一列火车上午8时从甲站开出,到第二天的晚上9时到达乙站。已知火车平均每小时行98千米。甲乙两站间的铁路长多少千米?
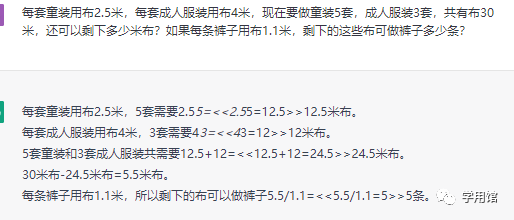
题二:每套童装用布2.5米,每套成人服装用布4米,现在要做童装5套,成人服装3套,共有布30米,还可以省下多少米布?如果每条裤子用布1.1米,剩下的这些布可做裤子多少条?
英语题目更是不在话下
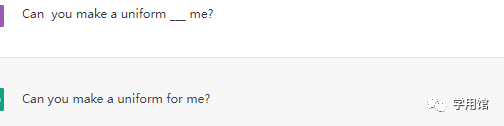
填空题
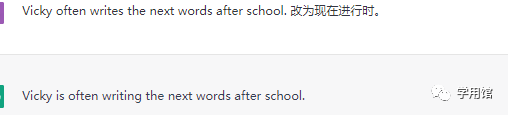
变换句式题
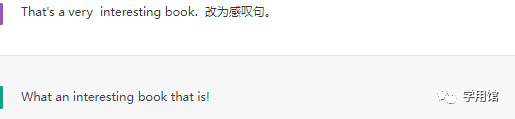
知之为知之,不知为不知,是知也

大型语言模型的突破
Galactica遭遇滑铁卢

ChatGPT:优化对话的语言模型
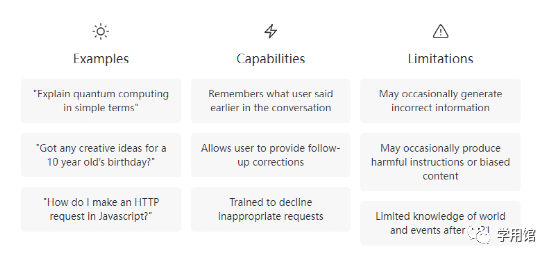
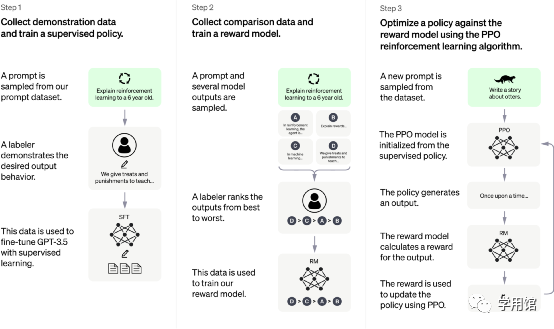
仍然存在的缺陷与不足
ChatGPT 有时会写出看似合理但不正确或荒谬的答案。解决这个问题具有挑战性,因为:
ChatGPT 对输入措辞的调整或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但只要稍作改写,就可以正确回答。 该模型通常过于冗长并过度使用某些短语,例如重申它是 OpenAI 训练的语言模型。这些问题源于训练数据的偏差(训练者更喜欢看起来更全面的更长答案)和众所周知的过度优化问题。 理想情况下,当用户提供模棱两可的查询时,模型会提出澄清问题。相反,我们当前的模型通常会猜测用户的意图。 虽然我们已努力使模型拒绝不当请求,但它有时会响应有害指令或表现出有偏见的行为。我们正在使用Moderation API来警告或阻止某些类型的不安全内容,但我们预计它目前会有一些漏报。我们渴望收集用户反馈,以帮助我们正在进行的改进该系统的工作。
文章转载自学用馆,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
