




Big Data on S3最佳实践-系列篇之(2)
 本文是Big Data on S3最佳实践系列篇的第二篇,今天要跟大家分享的是EMR HBase on S3的最佳实践。本篇文章主要包括以下内容:
本文是Big Data on S3最佳实践系列篇的第二篇,今天要跟大家分享的是EMR HBase on S3的最佳实践。本篇文章主要包括以下内容:
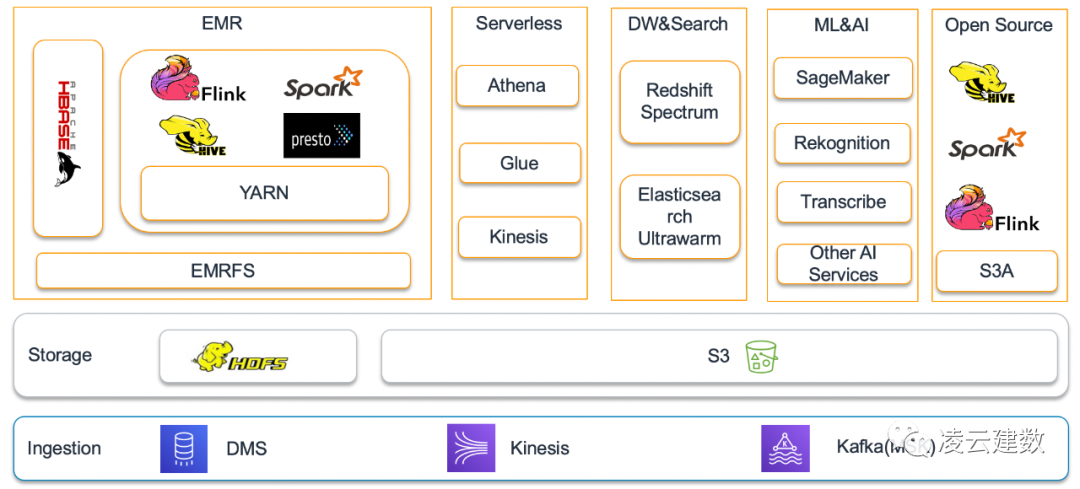
HBase简介及架构
HBase on S3架构
HBase 数据读写流程
HBase on S3最佳实践
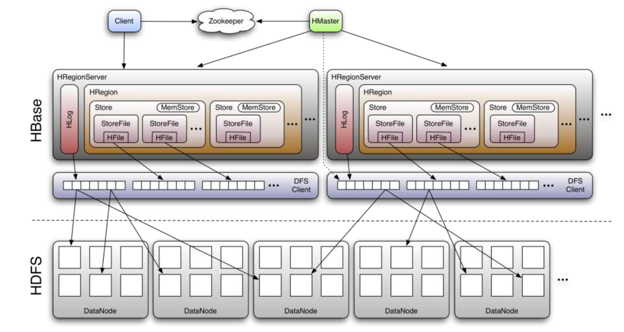
为从节点分配Region 管理Slave节点的负载均衡 发现失效的从节点并重新分配失效节点之上的Region 管理用户对表的元数据操作,比如create table, delete table等
处理客户端的IO请求 WAL Log管理 Region管理 Storefile管理
原始的HBase的数据是放在HDFS存储。但是随着数据量的增长,HDFS存储HBase数据面临同样的挑战:
机器维护及容灾恢复:升级维护HBase集群困难,且HDFS NameNode重启时间与存储的数据量成正比,一个数据中心的宕机会影响在线业务的数据访问。
成本:因为Hadoop集群存储计算偶合在一起,为了存储数据需要为空闲的计算资源支付成本。
资源竞争:Hadoop集群的批处理负载会影响HBase数据的写入,查询的性能。
而数据放在S3上则很好的解决上述的问题。因此很多用户也把HBase的数据从HDFS迁移到S3, 尤其是支持历史数据查询功能的使用场景。美国金融监管局(FINRA)通过把HBase迁移到S3上,成本降低60%。
HBase on S3的实现方案有两种:
AWS EMR HBase: AWS EMR针对HBase组件做了优化,用户在在创建EMR集群过程中选择数据存储在S3之上。
自建HBase:如果用户选择通过EC2自建HBase集群,可以利用开源社区的HBase Object Store Semantics(HBOSS)项目,把自建的HBase集群的数据存储在S3之上。


WAL文件写入HDFS: 因为HDFS有数据写入低延迟的特点,且数据量相对较小,因此WAL文件依旧写入HDFS Storefile写入S3:用户的HBase数据通过EMRFS存储在S3保证数据的持久性 Core节点及Task节点都有Region Server服务:因为数据写入S3,没有要数据本地性的特点,因此Core节点及Task节点都可以启动Region Server服务与S3进行交互读写数据 通过内存及本地磁盘缓存数据:为了提升读数据的性能,HBase利用Block Cache(堆内内存)及Bucket Cache(堆外内存及SSD磁盘)缓存数据。
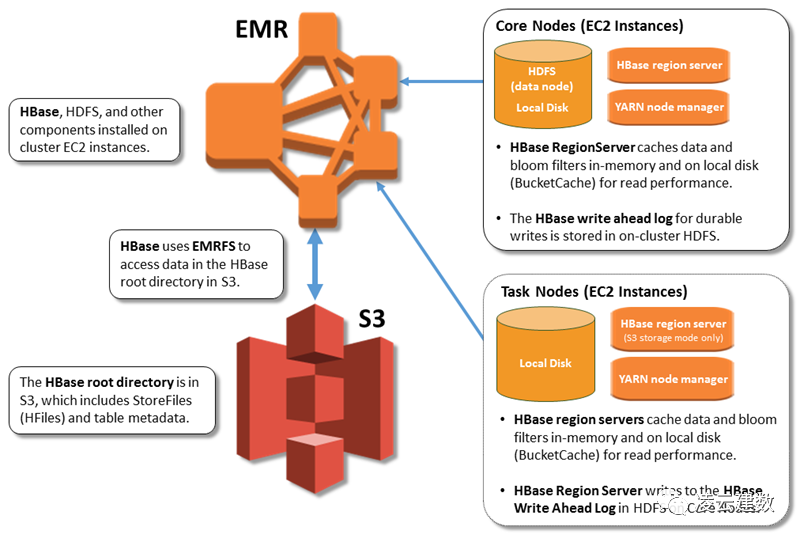
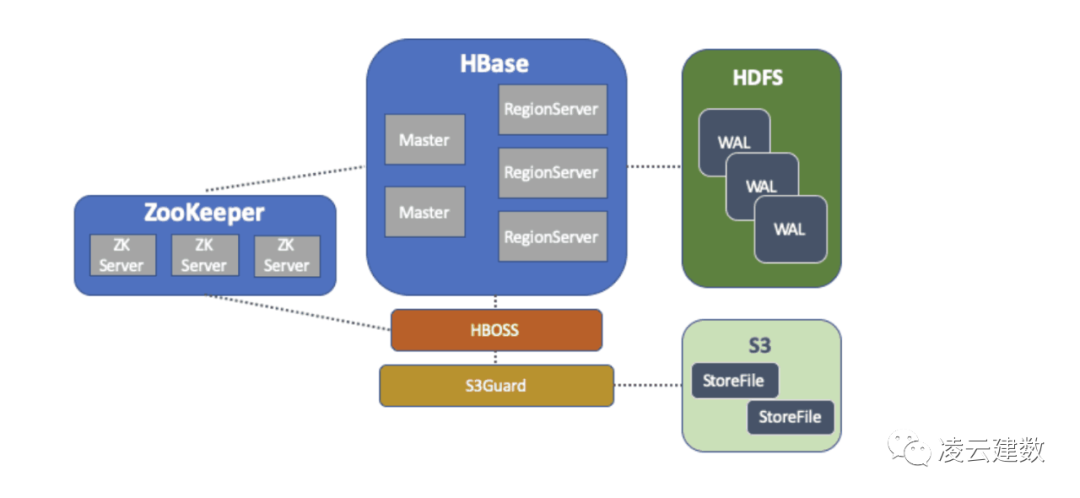
存储计算分离:数据存储在S3上,当HBase集群不需要时,可以随时将HBase集群关闭。可以创建多个集群数据指向同样的S3数据实现高可用方案。
成本:S3与HDFS的成本对比前文已经介绍。如果HBase的数据量比较大,通过S3存储数据降低存储成本。
灵活的架构:可以将在线服务与批处理服务分离,单独进行版本升级及维护,降低耦合性。
了解HBase的数据读写流程会进一步帮助我们了解HBase底层的原理及在使用过程中应该注意的事项。下面就分别介绍一下HBase的数据写入及数据读取的流程。
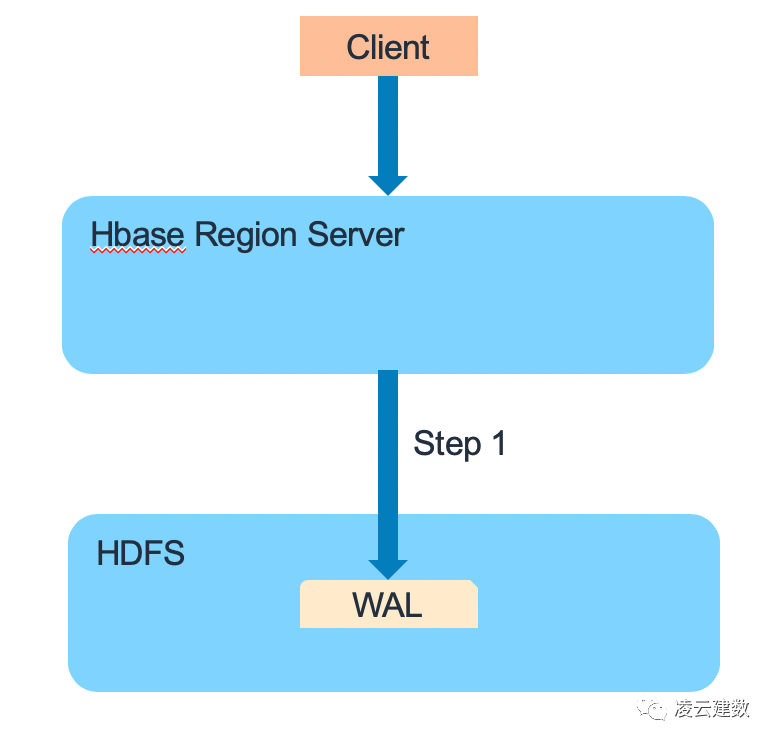
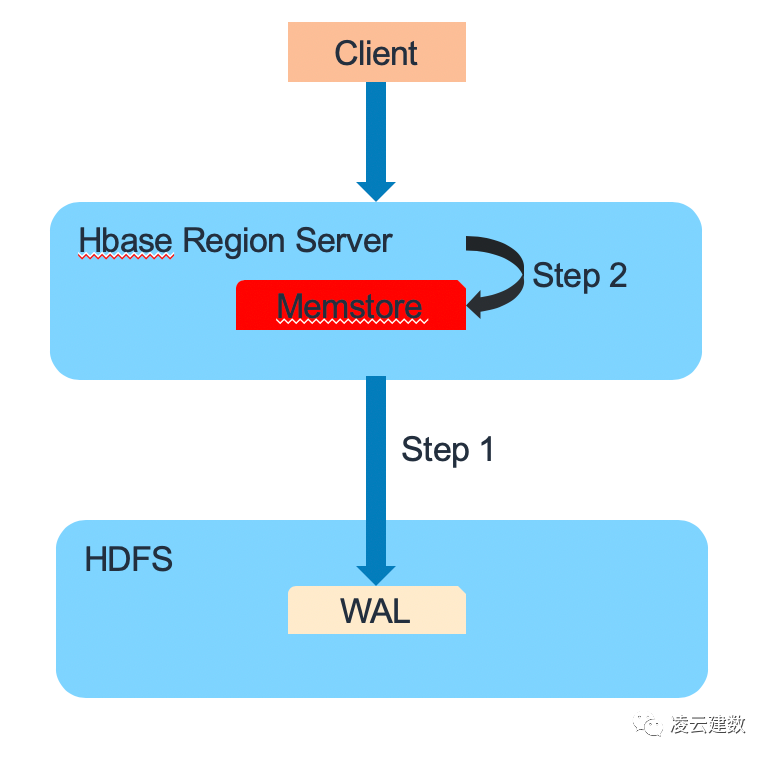
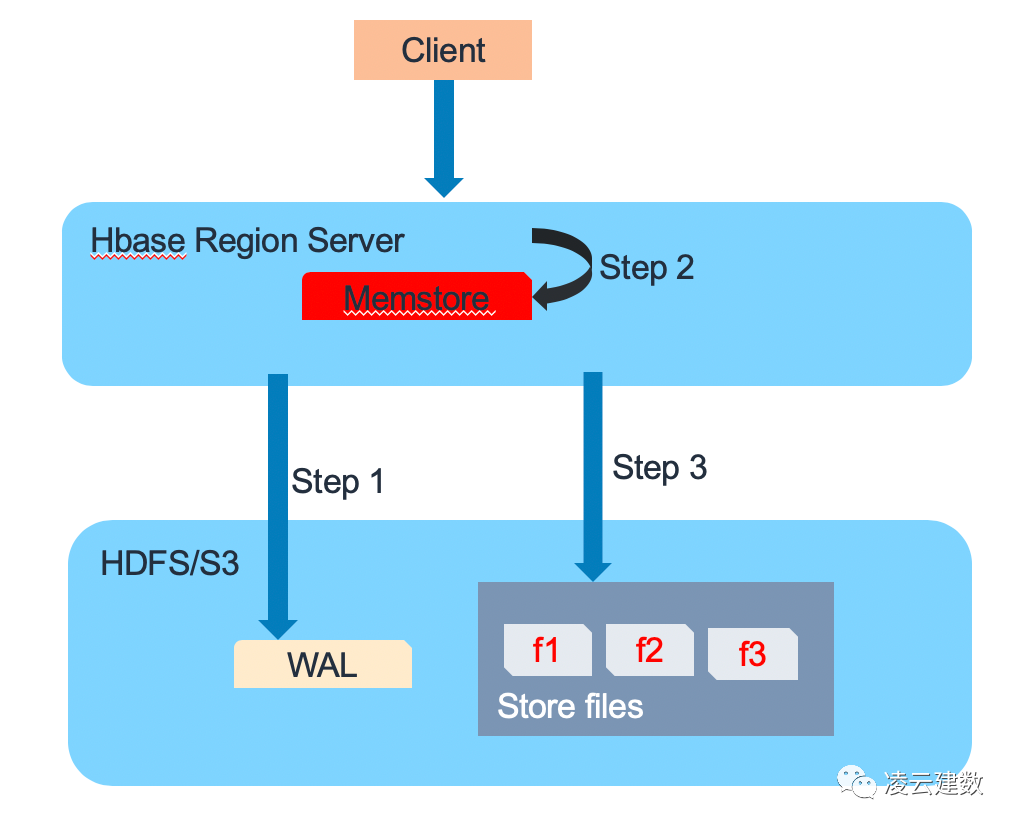
HBase数据读取也分3个步骤。第一步,Region Server会在Block Cache/Bucket Cache查找数据,如果Cache有需要读取的的数据,则直接从Cache返回,避免磁盘的IO操作,提高读取性能。
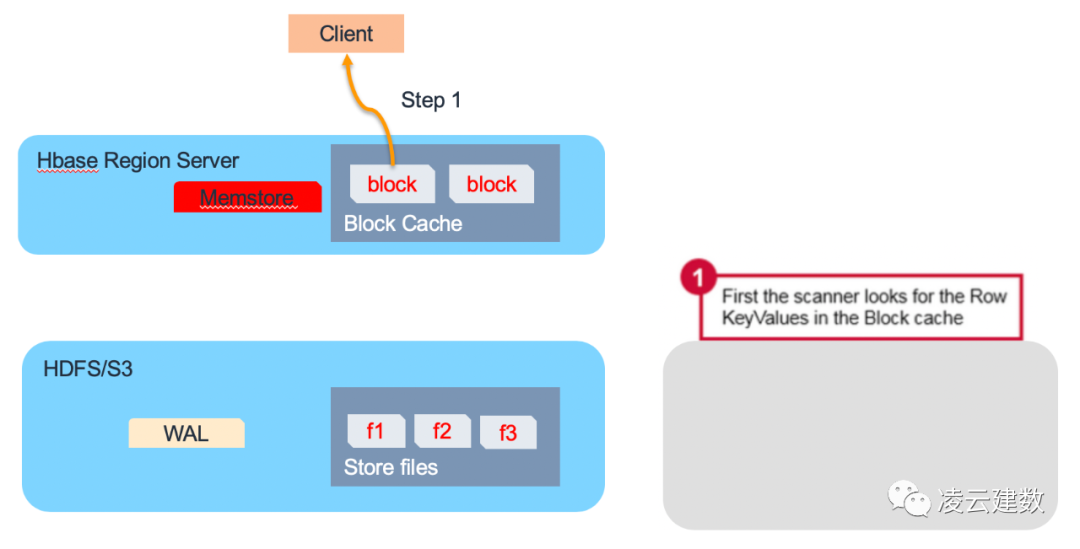
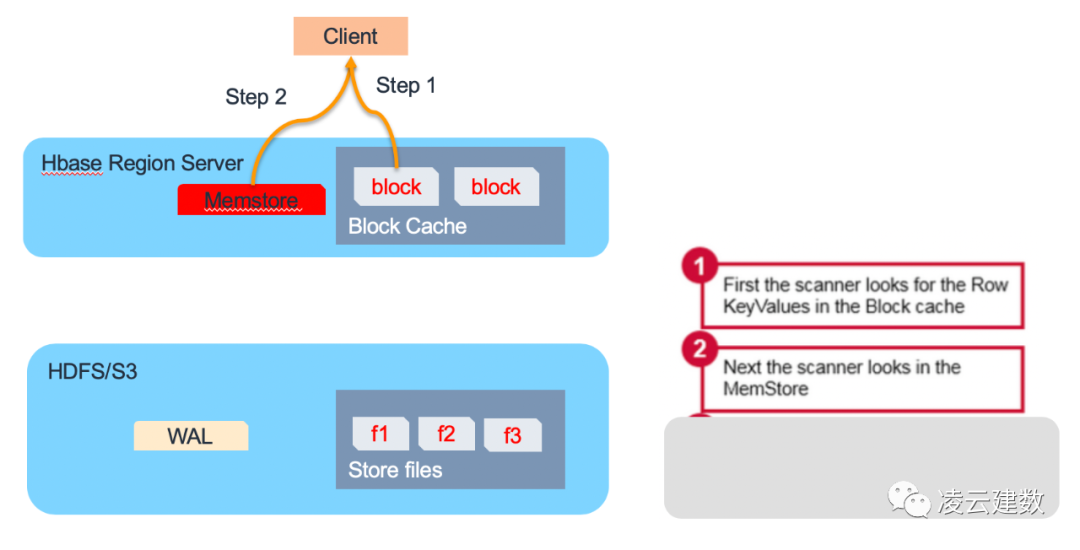
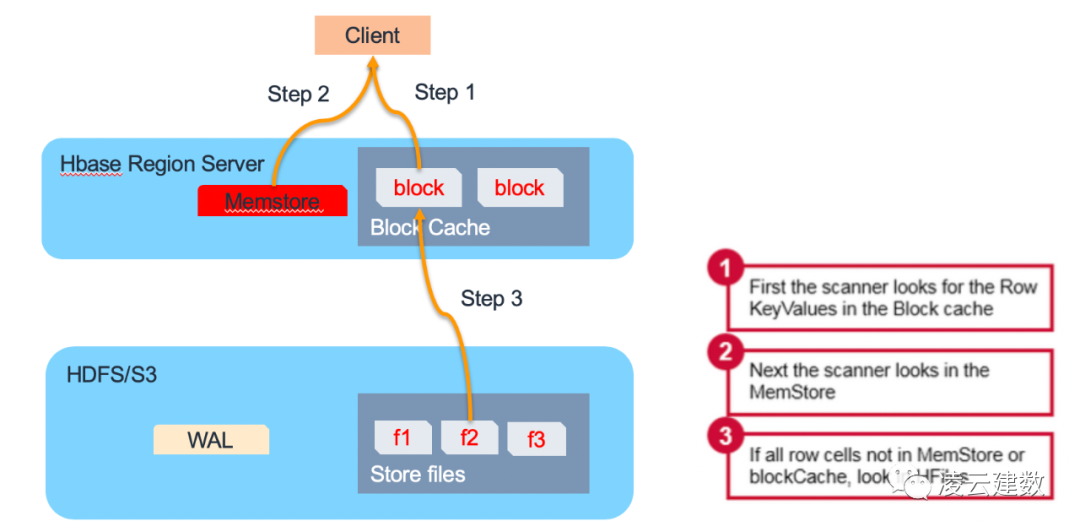
因此可以看到Cache的配置管理对HBase的读取性能影响非常关键。HBase为了更好的利用Cache提升读取性能,将Cache分Block Cache及Bucket Cache。L1缓存即Block Cache是放在Region Server JVM的堆内内存进行管理(通hfile.block.cache.size参数调整大小),L2缓存即Bucket Cache可以放在堆外内存或者SSD硬盘上。可以通过hbase.bucketcache.ioengine,hbase.bucketcache.size等参数进行优化。
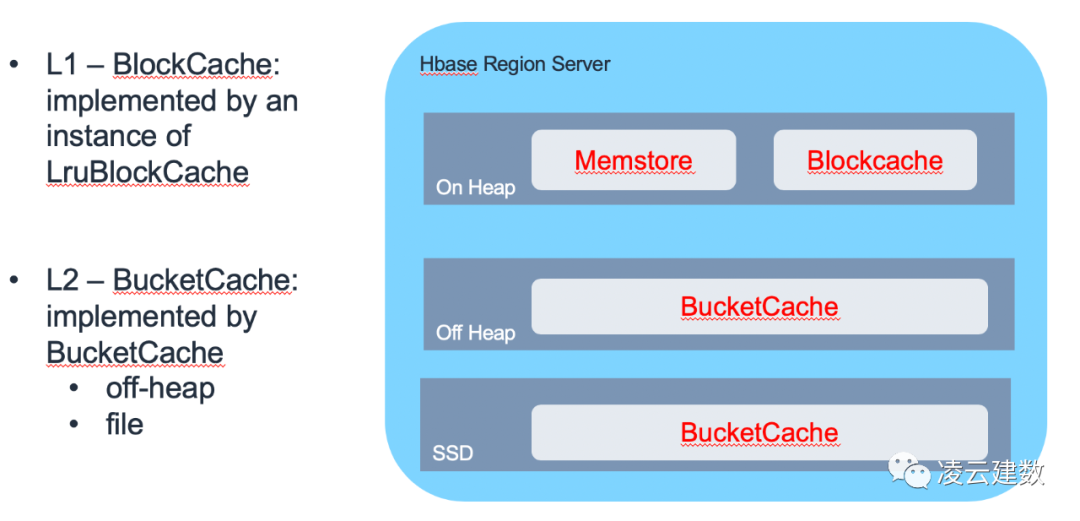
HBase on S3跟 HBase on HDFS的功能总体比较类似,因此HBase的通用最佳实践在HBase on S3同样适用。比如:
HBase机型选择
每台机器存放Region的个数
Region Server Heap Size调整及JVM GC优化
HBase Schema设计
Rowkey设计避免热点数据
根据数据读写比例配置Memstore及Cache大小
优化Compaction 配置L1及L2缓存 调整RPC线程
前文的HBase的数据写入流程描述了HBase数据写入过程涉及两个重要的过程需要Region Server与S3进行交互,分别是Memstore的Flush生成Storefile存储到S3及HFile的Compaction。
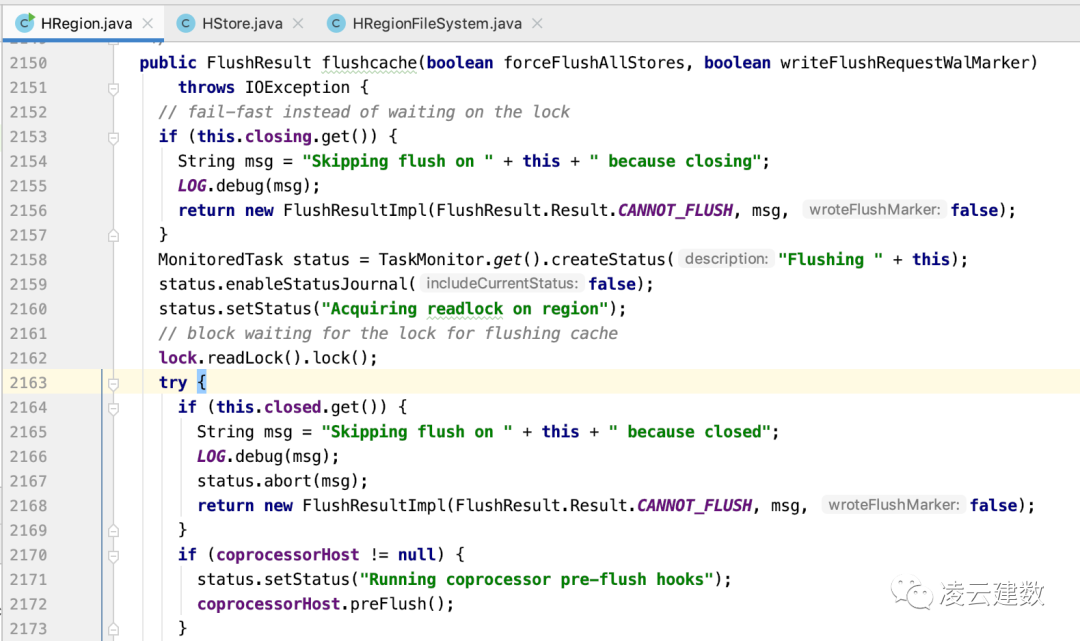
我们先通过HBase的源代码大概了解一下HBase Memstore Flush的流程。Region的Flush入口从HRegion类的flushcache方法开始,期间为了防止正在写入的文件进行读取操作,会将Memstore的数据在分布式文件系统(HDFS或者S3)生成一个临时文件,比如:
s3://s3bucket/hbase/data/{namespace}/{table}/497b5cf3f2660e058191bbd9f51f8388/.tmp/c57f1d7d0f0f4c4d9aa7681fb45c5208
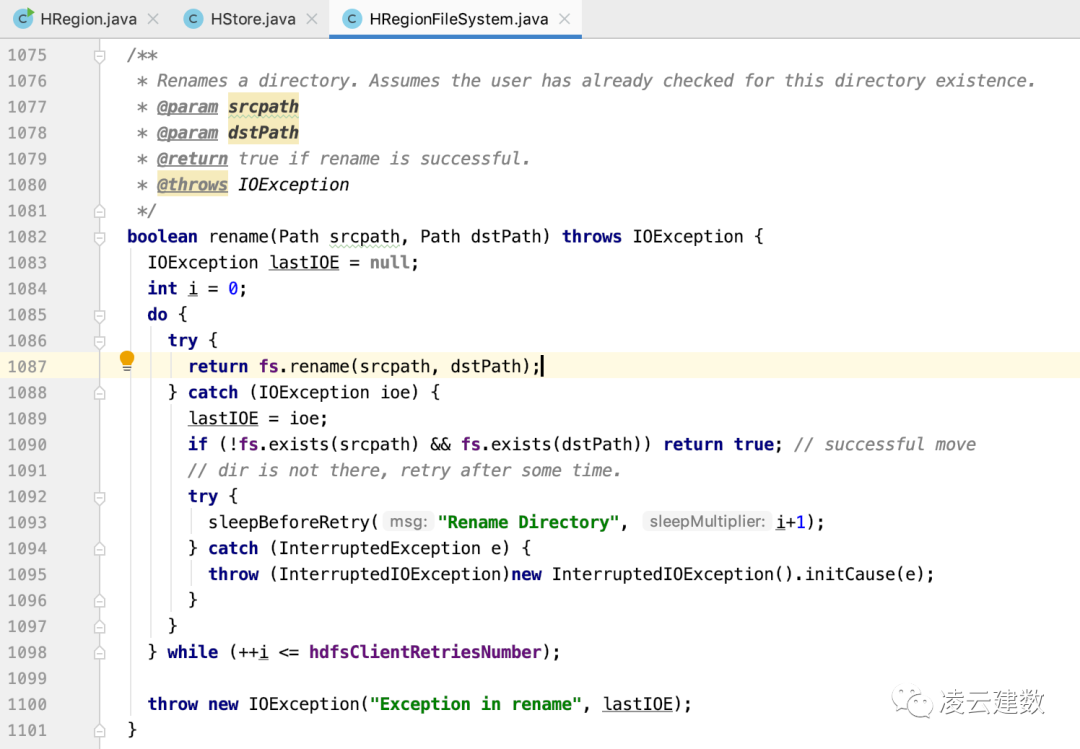
在临时文件写入成功后,会调用HRegionFileSystem类的rename方法将临时文件重新命名到分布式文件系统的最终目录下, 比如:
s3://s3bucket/hbase/data/{namespace}/{table} 497b5cf3f2660e058191bbd9f51f8388/{cf}/c57f1d7d0f0f4c4d9aa7681fb45c5208
在上一篇文章介绍S3的特性中已经提到S3的rename底层实现并非原子性,而是一个Copy + Delete的操作。因此Memstore的flush的耗时要长,而且因为非原子性的rename会导致文件的不一致因而导致HBase Region Server的重启。小编在HBase的社区提交了一个JIRA用来优化HBase Memstore Flush的流程,具体信息可以参考:
https://issues.apache.org/jira/browse/HBASE-23730
为了更好的使用HBase on S3,避免Memstore带来的问题。我们最好需要了解什么时候触发 Memstore Flush。总的来说,主要有以下几种情况会触发 Memstore Flush:
Region中Memstore占用的内存超过阈值:每个Region的Column Family都分配一定的内存给Memstore,如果写入数据的数据量超过此内存,则会触发Flush操作。hbase.hregion.memstore.flush.size参数控制是控制此参数的大小,默认值128MB。可以根据数据写入的频率及单元格的大小适当调整。可以查看Region Server的日志了解Flush文件的大小情况。
整个RegionServerMemStore占用内存总和大于阈值:整个Region Server的Memstore也有上限,如果一个Region Server上的Region比较多,当所有Memstore的总和超过Region Server Memstore的上限,同样会触发Memstore的flush。Region Server Memstore的值可以通过参数hbase.regionserver.global.memstore.size调整。
WAL数量大于一定阈值:一台Region Server的WAL文件数量如果超过一定值同样会触发Memstore Flush。默认值是32,可以通过参数hbase.regionserver.maxlogs调整。
数据更新超过一定阈值:如果某个Region更新频率比较高,总更新次数超过一定数量后也会触发Memstore Flush。
定期自动Flush:为了防止因为Region Server失效,Region会定期的把内存中的数据Flush到磁盘。
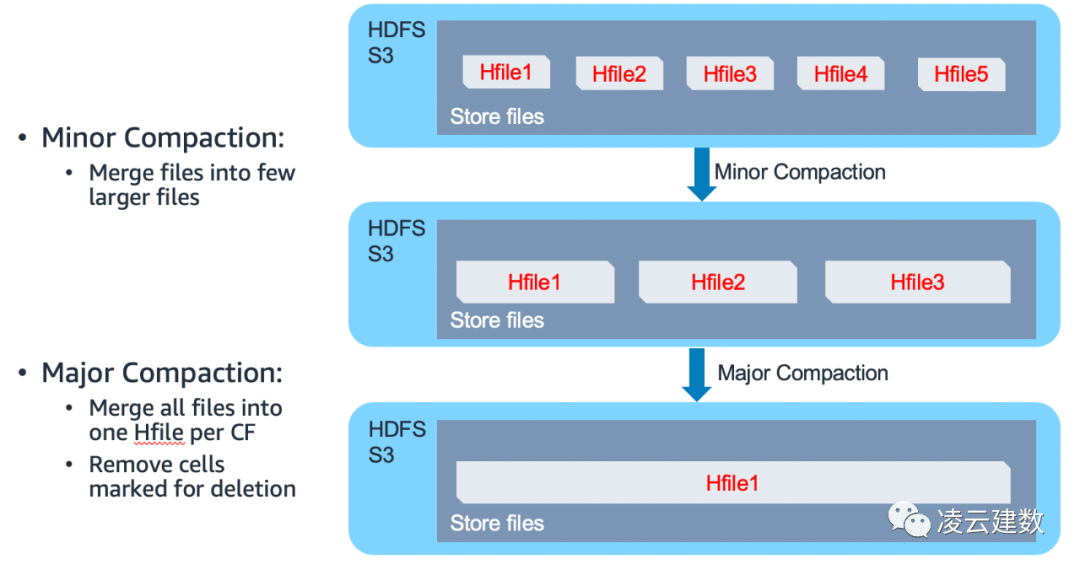
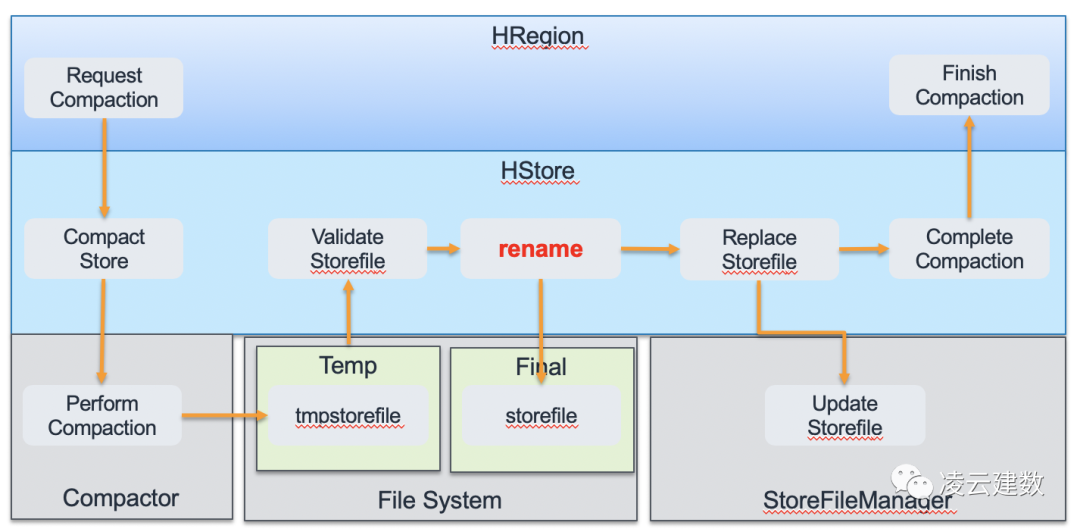
另外一个与S3交互频繁的操作就是HFile Compaction。下图是HFile Compaction的流程,从图中可以看出HFile Compaction同样涉及S3的rename操作。因此HFile Compaction 的优化对HBase on S3的性能及稳定性有非常大的影响。
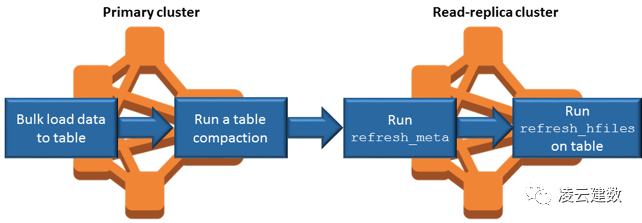
参考

