




某天某应用找到我,说线上 Bulkload
导入数据到 HBase
失败。
check
了一下 MR
日志,报错如下:
org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles.groupOrSplitPhase(LoadIncrementalHFiles.java:591)|||IOException during splitting
java.util.concurrent.ExecutionException: org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://******/*****/f1/2adb6a82818642aca73daf999063f655
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:188)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles.groupOrSplitPhase(LoadIncrementalHFiles.java:584)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles.doBulkLoad(LoadIncrementalHFiles.java:440)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles.doBulkLoad(LoadIncrementalHFiles.java:327)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at sun.reflect.misc.Trampoline.invoke(MethodUtil.java:75)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at sun.reflect.misc.MethodUtil.invoke(MethodUtil.java:279)
Caused by: org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file
hdfs://******/*****/f1/2adb6a82818642aca73daf999063f655
at org.apache.hadoop.hbase.io.hfile.HFile.pickReaderVersion(HFile.java:495)
at org.apache.hadoop.hbase.io.hfile.HFile.createReader(HFile.java:538)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles.groupOrSplit(LoadIncrementalHFiles.java:661)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles$3.call(LoadIncrementalHFiles.java:574)
at org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles$3.call(LoadIncrementalHFiles.java:571)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
... 3 more
Caused by: java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy()Z
at org.apache.hadoop.util.NativeCodeLoader.buildSupportsSnappy(Native Method)
at org.apache.hadoop.io.compress.SnappyCodec.checkNativeCodeLoaded(SnappyCodec.java:63)
at org.apache.hadoop.io.compress.SnappyCodec.getDecompressorType(SnappyCodec.java:195)
at org.apache.hadoop.io.compress.CodecPool.getDecompressor(CodecPool.java:181)
at org.apache.hadoop.hbase.io.compress.Compression$Algorithm.getDecompressor(Compression.java:328)
at org.apache.hadoop.hbase.io.compress.Compression.decompress(Compression.java:423)
at org.apache.hadoop.hbase.io.encoding.HFileBlockDefaultDecodingContext.prepareDecoding(HFileBlockDefaultDecodingContext.java:90)
at org.apache.hadoop.hbase.io.hfile.HFileBlock.unpack(HFileBlock.java:549)
at org.apache.hadoop.hbase.io.hfile.HFileBlock$AbstractFSReader$1.nextBlock(HFileBlock.java:1380)
at org.apache.hadoop.hbase.io.hfile.HFileBlock$AbstractFSReader$1.nextBlockWithBlockType(HFileBlock.java:1386)
at org.apache.hadoop.hbase.io.hfile.HFileReaderV2.<init>(HFileReaderV2.java:150)
at org.apache.hadoop.hbase.io.hfile.HFile.pickReaderVersion(HFile.java:483)
... 8 more
上面的报错很明显,Bulkload
导入最后一步,执行 doBulkload
的时候,将生成的 HFile
导入到 HBase
中出现问题,原因是执行 doBulkload
的客户端 没有 snappy
本地库。所以只需要添加 snappy
本地库即可。但是这样处理是否有问题呢:
首先我们来看一下 Bulkload
的原理:
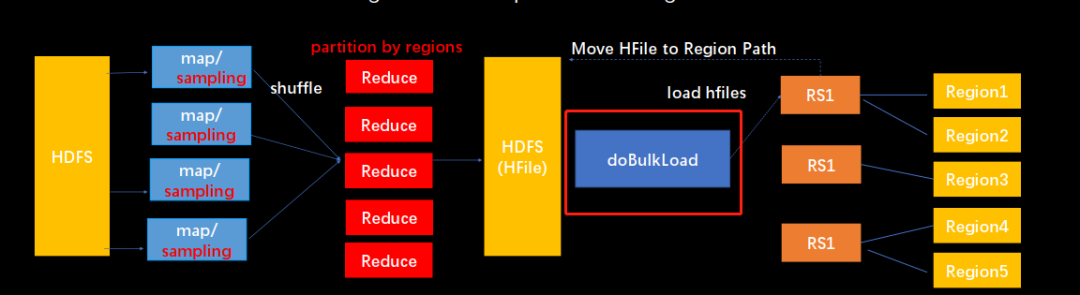
Bulkload
原理就是通过 MR/Spark
程序根据 HBase
表的 region
范围 (startkey/endkey)
来做 partition
直接生成 HFile
,然后通过 doBulkload
命令将 HFile
move
到 HBase RegionServer
的 Region
对应的列族目录下, StoreFileManager
更新维护的 HFile
列表对象即可。bulkload
和 doBulkload
详细原理,由于涉及的内容比较多,后面有时间的话单独写个博客来介绍。这里就不展开了。
所以这里面会使用到压缩的地方应该有三处:
MR
生成HFile
的时候doBulkload
的时候导入到
HBase
,然后HBase
自身读取/写入/compaction
的时候
集群是我们自己开发维护的 HBase
分支, 虽然默认已经集成了常用的 native
的库,比如 snappy
,zstd
,但通常执行 bulkload
的 MR
程序或者 doBulkload
的客户端与 HBase
不在一个集群,例如这个本例就是。这会导致往压缩的 HBase
表中导入数据失败 。
基于以上的原因和问题,对 HBase Bulkload
做了一个简单的改进:
思路很简单:就是 bulkload
的时候,支持在客户端设置压缩格式,而不是直接使用原始表的压缩格式。
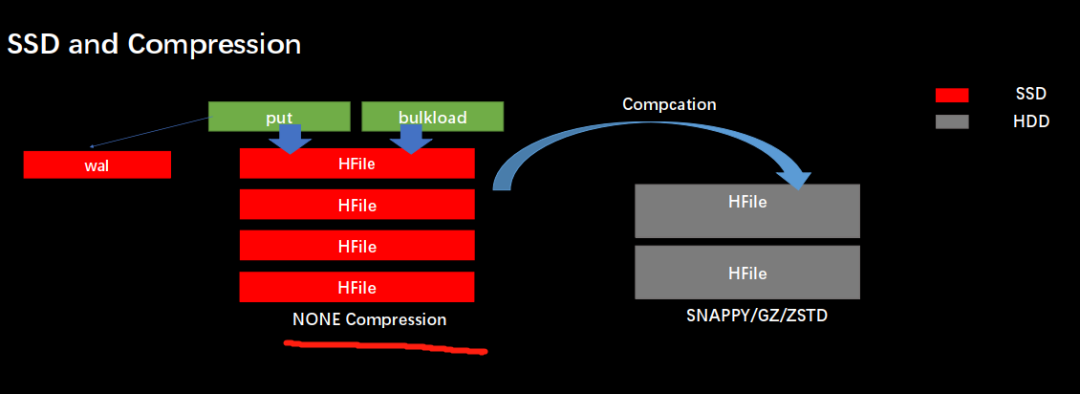
虽然这个改进很简单,但在我们的实际场景下还是很有用的:
MR/doBulkload
客户端可以设置非压缩的格式,从而避免因为没有本地库导致的失败,也就是本文中出现的情况。B
ulkload
设置生成非压缩的HFile
格式,性能更好,后续compaction
,仍然会根据表的压缩格式来合并,存储容量影响很小的情况下,提高性能。这个特性在我们的版本中结合实现的
flush
、compaction
设置异构存储策略、压缩编码以及WAL ON SSD
可以做到数据异构以及冷热分离,比如flush/bulkload
生成的HFile
到SSD
中,并且不设置压缩和编码;通过compaction
执行压缩/编码
到HDD
中. 这样的话,发生在HBase
的关键路径的写入、导入、读取、compaction
性能大幅提升。在跨数据中心同步中,使用
bulkload replication
的情况下,表是未压缩的,可以反过来,设置生成HFile
压缩,这样可以减少跨数据中心的同步带宽消耗。
该改进已经贡献给了社区,感兴趣可参考:
https://issues.apache.org/jira/browse/HBASE-21810
https://utf7.github.io/docs/hbaseconasia2019track31430-190819225905.pdf
