




作为传统的事务型数据库,SQLServer有着出色的读写性能,但当面对高吞吐量数据写入以及海量的数据分析等场景时,却无法满足需求;即使数据量较小,能满足数据写入的要求,也难以同时响应实时计算的请求。本文旨在为有从 SQL Server 迁移至 DolphinDB 需求的用户提供一份简洁明了的参考。
👉完整教程已发布在官方知乎,可点击阅读原文查看。
迁移数据
DolphinDB: DolphinDB_Linux64_V2.00.8.6 SQL Server: Microsoft SQL Server 2017 (RTM-CU31) (KB5016884) - 14.0.3456.2 (X64)
方法一:ODBC 插件
安装 ODBC 驱动(ubunt22.04)
# 安装 freeTDSapt install -y freetds# 安装 unixODBC 库apt-get install unixodbc unixodbc-dev# 安装 SQL Server ODBC 驱动apt-get install tdsodbc
配置环境
建立连接
conn =odbc::connect("Driver={SQLServer};Servername=sqlserver;Uid=sa;Pwd=DolphinDB;database=historyData;;");
同步数据
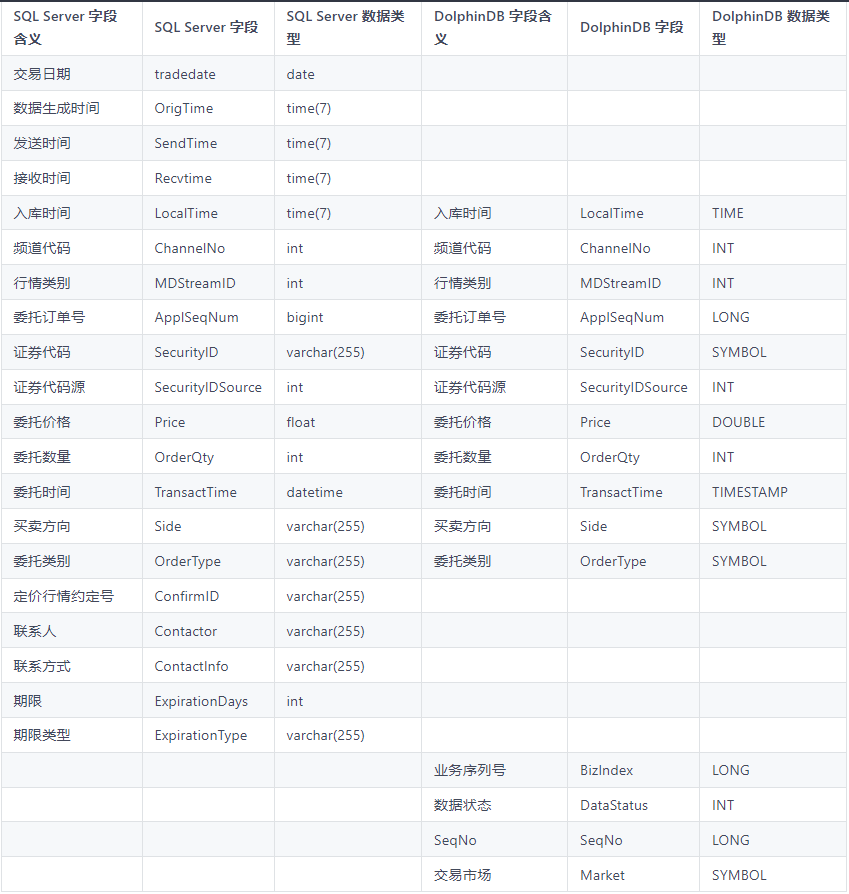
def transform(mutable msg){msg.replaceColumn!(`LocalTime,time(temporalParse(msg.LocalTime,"HH:mm:ss.nnnnnn")))msg.replaceColumn!(`Price,double(msg.Price))msg[`SeqNo]=int(NULL)msg[`DataStatus]=int(NULL)msg[`BizIndex]=long(NULL)msg[`Market]="SZ"msg.reorderColumns!(`ChannelNo`ApplSeqNum`MDStreamID`SecurityID`SecurityIDSource`Price`OrderQty`Side`TransactTime`OrderType`LocalTime`SeqNo`Market`DataStatus`BizIndex)return msg}def synsData(conn,dbName,tbName){odbc::query(conn,"select ChannelNo,ApplSeqNum,MDStreamID,SecurityID,SecurityIDSource,Price,OrderQty,Side,TransactTime,OrderType,LocalTime from data",loadTable(dbName,tbName),100000,transform)}submitJob("synsData","synsData",synsData,conn,dbName,tbName)
startTime endTime2022.11.28 11:51:18.092 2022.11.28 11:53:20.198
👉完整教程已发布在官方知乎,可点击阅读原文查看。
方法二:DataX 驱动
部署 DataX 及相关插件
配置文件
执行任务
cd ./DataX/bin/python DataX.py ../job/synchronization.json
任务启动时刻 : 2022-11-28 17:58:52任务结束时刻 : 2022-11-28 18:02:24任务总计耗时 : 212s任务平均流量 : 3.62MB/s记录写入速度 : 78779rec/s读出记录总数 : 16622527读写失败总数 : 0
👉完整教程已发布在官方知乎,可点击阅读原文查看。
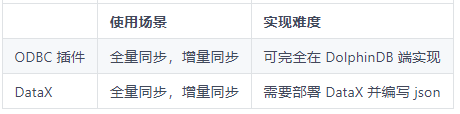
ODBC or DataX ?
Explore More




文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
