





文 老滚、那珂、正研、李子、天引
1.前言
2022年是云原生多模数据库Lindorm全面支撑集团双11大促的第五个年头。在这五年中,Lindorm架构从基于 HBase 深度改造的 1.0 架构版本演进到了当前统一在同一个分布式文件系统之上融合了多种存储引擎、数据模型的2.0架构版本。目前Lindorm也在朝着云原生、一体化、更紧密的多模融合方向孕育着新一代架构演进。
过去十多年,得益于内部业务对Lindorm持续的需求牵引,推动了Lindorm不断的技术演进和体验提升,全面服务于淘宝、天猫、支付宝、网商、菜鸟、阿里妈妈、高德、优酷、钉钉、大文娱等各个业务板块,满足应用对于海量结构化、半结构化数据的存储处理需求,目前Lindorm在内部已部署超4万个节点,数据规模超500PB。

在2022年双11中,Lindorm全天平稳运行,日吞吐量39.1万亿次,平均响应时间低于3毫秒,其中读请求峰值 3.68亿次/秒,写请求峰值 2.22亿次/秒,有效支撑了双11指挥室大屏、手淘消息、物流轨迹等核心场景。同时,今年是Lindorm在云上商业化的第二个年头,在诸多外部客户的双11战役中也逐渐发挥越来越大的作用。
纵观整个2022年,内外大环境都发生了剧烈的变化。同时随着阿里云数据库“四化”战略的提出,作为一款阿里云自研的云原生多模数据库产品,将如何向着“云原生化”,“平台化”,“一体化”,“智能化”进一步演进,也是Lindorm当今发展过程中需要不断去抬头对齐的目标,希望通过本文的梳理总结,可以有助于我们更清晰地向未来前进。
2.问题与挑战
2.1 业务降低成本的需求
菜鸟物流
出于2022年整体经营需要降本增效的目标,希望使用Lindorm的场景可以做到在线服务能力不变的情况下,成本下降20%以上。 阿里云物联网平台 IoT平台重度依赖时序数据库的使用,满足亿级设备的高并发吞吐写入需求,在新财年的成本压力下,需要在承接住日益增长的线上负载以及新增功能需求的同时,将使用成本降到原先的1/2以下。
2.2 企业提高效率的需求
随着人力资源的吃紧,越来越多的客户希望更加聚焦于自身业务的开发,而减少对基础设施使用和维护的人力投入,内外客户也开始将搬站上云当成一种增效降本的选择。典型地,在大数据存储与处理领域,许多互联网公司都会首选HBase、Hadoop/Spark作为它们的大数据解决方案,但是HBase以及Hadoop生态的技术复杂度,使得企业的应用维护难度较大,期望能在云端找到平滑替换方案,提升效率,代表性需求如下:
A+流量分析平台
作为全集团采集&流量分析一站式服务平台,为了更好的升级A+产品,对老A+进行全新升级,解决老A无法迭代、运维困难等问题。特别是原本数据存储使用HBase+Phoenix的架构由于社区不够活跃,迭代和维护难以为继。迫切希望能够寻找新的方案既能无缝迁移已有的HBase数据,又能提供足够的SQL能力支撑平台后续的功能迭代。 互联网头部客户
不少互联网客户过去投入大量研发资源支撑起大规模自建HBase和Hadoop集群的运用与维护,但随着整体公司研发战略的调整,人力投入大幅减少,同时在遇到问题时很难从社区获取的足够技术支持,期望能有一种更高人效的方案支撑现有业务。
2.3 技术上的挑战
Lindorm在阿里内部经过十多年的历练打磨,其成熟稳定的能力能够很好匹配业务对于海量数据管理的高效、低成本的需求,一方面,Lindorm脱胎于HBase的底层技术,加入了大量的自研核心技术使得能以更优的性价比去引导客户将应用从自建的HBase搬迁到云上Lindorm;另一方面,Lindorm的多模融合设计理念能够有效降低业务的研发使用成本以及运维难度。
如何通过技术手段进一步切实地降低大规模数据的存储成本。 如何满足外部互联网企业上云的同时兼容开源标准避免锁定在特定云厂商的苛刻要求。 如何让业务更加简单便捷地接入Lindorm从而提升效率。 如何提升Lindorm在不同业务场景下的吞吐性能。
3. Lindorm的能力演进回顾
围绕着上文中提出的技术挑战,Lindorm在整个2022年度针对降本、提效两个方面进行了一系列能力建设:
3.1 降本方面的能力建设
3.1.1 字典压缩实现无感降本
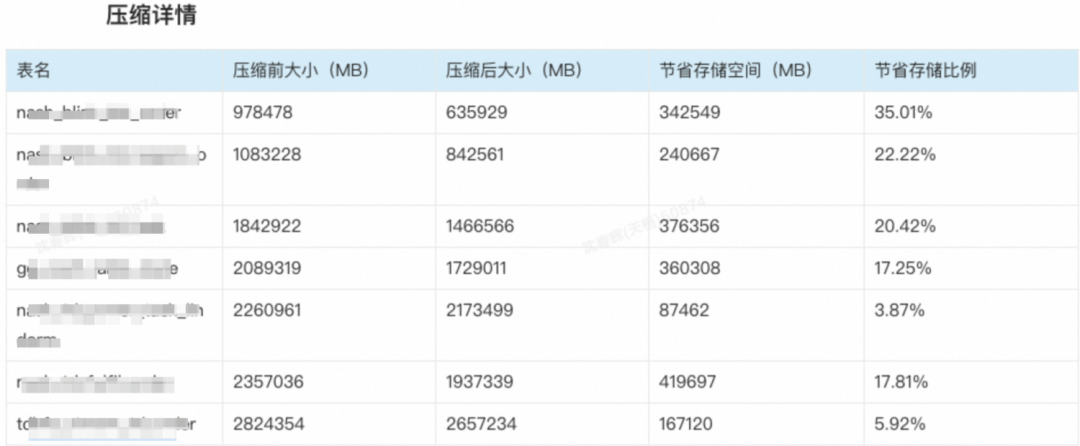
Lindorm宽表是基于LSM-Tree引擎构建数据存储。在单个SSTable文件内部,天然就适合使用压缩算法压缩分块,降低空间占用节省成本。Lindorm宽表引擎在通用压缩算法上更进一步,结合ZSTD深度定制,推出了字典压缩能力。 Lindorm内部会自动提取数据样本采样分析,根据数据特质,智能选择合适的编码压缩参数,并提取公共字典,消除压缩算法中的字典结构带来的额外开销,进一步提升了数据的压缩比率与压缩速度。同时,字典压缩的开启对业务无感,无需业务改造,用户只需要变更表配置,即可获得更高的压缩率。字典压缩在集团内与公共云上被大量应用,帮助业务降低成本。 落地案例
3.1.1 字典压缩实现无感降本
▶︎ 菜鸟物流的Lindorm集群,通过字典压缩、冷热分离、容量性存储等核心技术的落地应用,实现了在线服务能力不变的情况下,总体成本下降20%。其中,在末端履行数据场景,通过开启字典压缩特性,80%的表取得了比较明显的效果,平均存储减少15%+。
▶︎ 国泰产险技术引入Lindorm,通过字典压缩、冷热分离等技术实现了数据存储成本降低75%。

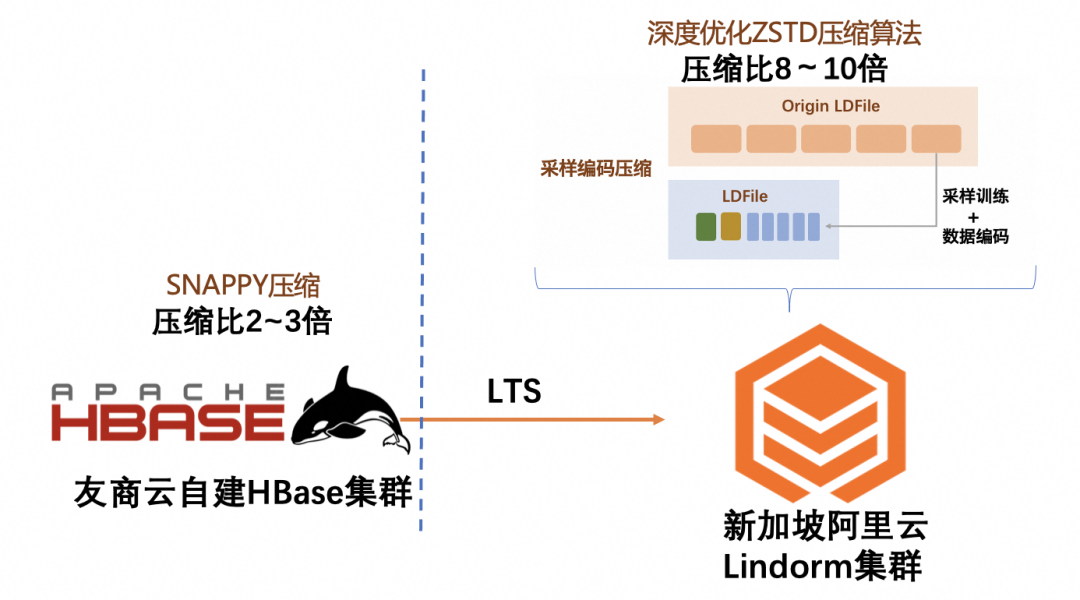
▶︎ 某互联网客户,将友商云上自建的HBase迁移至Lindorm并开启字典压缩后,存储空间直降50%。因此,采用了Lindorm后其存储成本大幅降低。
面向海量数据(>100TB)低成本存储的需求,通过HDD本盘ECS构建Lindorm实例,仍然是业务最具性价比的选择。本地盘大数据型ECS的存储与计算可被Lindorm完全使用,资源利用率更高。
Lindorm始终坚持云原生,充分挖掘云的弹性能力,催生出了新的Lindorm存储形态:本地盘ECS上挂载ESSD,通过LindormDFS异构副本实现1副本ESSD+2HDD冗余,并结合多模引擎层冷热分离的内核能力,实现业务成本的显著优化。
举一个具体点的应用例子:业务每天产生800G轨迹信息,需要保存1年,总数据量约300T。最近1周内的数据作为热数据,会被频繁地在线查询;而一周后的数据则视作冷数据,查询频率较低。在Lindorm本地盘实例上其存储机制如下:
创建一张表,存储轨迹数据,并设置冷热分界线为一周。
一周内的热数据使用1副本ESSD云盘+2副本HDD的存储策略,ESSD云盘容量可按需购买,仅需使用800G * 7 = 5.6T的云盘空间。热数据访问通过ESSD云盘得到加速。
一周外的冷数据使用EC纠删码方式编码存储,相比3副本的3倍存储放大,纠删码只需1.375倍空间进行数据冗余。实现历史数据的低成本存储。
3.1.3 时序数据专用压缩算法
落地案例
▶︎ 在阿里云物联网平台的应用场景中,底层的时序数据存储由早先的TSDB 2.0架构升级到Lindorm时序引擎后,得力于专用时序压缩算法的高压缩率,整个方案的成本节省了50%以上。
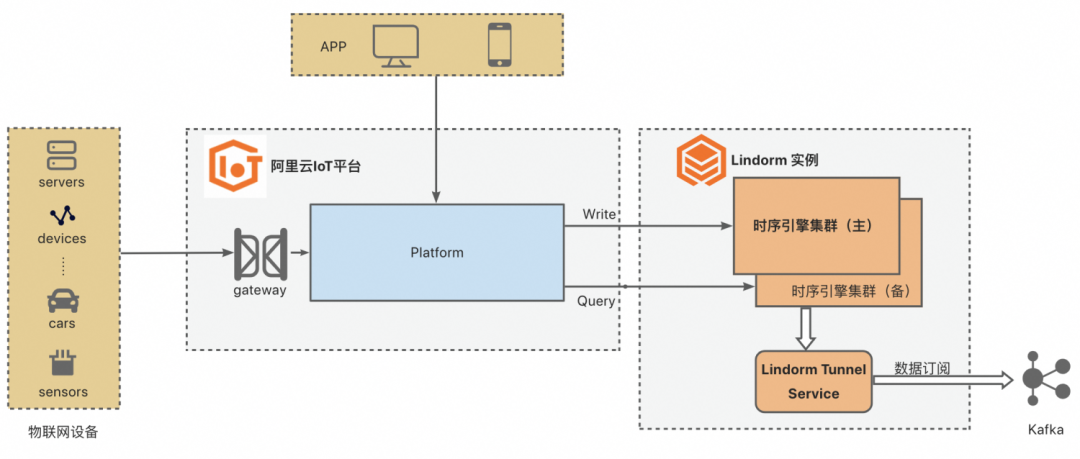
3.1.4 面向海量时间线的性能提升
容器监控场景下会产生大量短生命周期的时间线的迅速膨胀现象。
日志监控场景存在大量时间线生成,但每条时间时间线上的数据点分布稀疏。
系统、设备监控场景存在长周期的海量时间线。
1. 预降采样能力,应对长周期数据查询问题。
预降采样能力是在用户写入时实时降采样存储,降采样之后的数据和原始数据分开存储,在用户进行长周期降采样数据查询时,直接命中降采样之后的数据和数据文件,大幅度减少基于原始数据的计算量和文件数量,提升查询效率。
2. 多级分片能力,应对时间线膨胀问题。
在节点之间基于时间线进行哈希分片,每个分片内部再基于时间进行分区。每个时间分区内部保存一段时间的数据,并独享索引,并在时间分区内部再提供可选的数据分区。通过这样的数据多级分区抑制时间线膨胀带来的查询性能问题。
3. 时间线预聚合能力,实现海量时间线下的聚合查询优化。
落地案例
▶︎ 某互联网社交平台的业务监控场景中,用户有3-4亿的活跃时间线实时写入,单次查询命中多达百万时间线秒级返回。用户由自建的Apache Durid迁移到Lindorm后,查询响应延时大幅降低,成本节省50%以上。
3.2 提效方面的能力建设
3.2.1 深度兼容HBase通信协议
这个技术方案对于习惯HBase技术栈的开发人员编写新的业务是一个绝佳的方案,但是在搬山上云的场景下也逐渐暴露出若干缺点:
部分客户业务并非是直接调用HBase API,而是依赖于捆绑了HBase原生客户端的开源解决方案。这些方案中的原生HBase客户端无法替换。如使用华为云的Hive以HBase兼容模式访问Lindorm。
客户业务架构复杂,大量服务应用在线上运行,逐个应用替换客户端繁琐,甚至找不到人升级应用。
部分客户希望上云,但却不想被特定云服务厂商锁定,希望使用标准的开源接口。
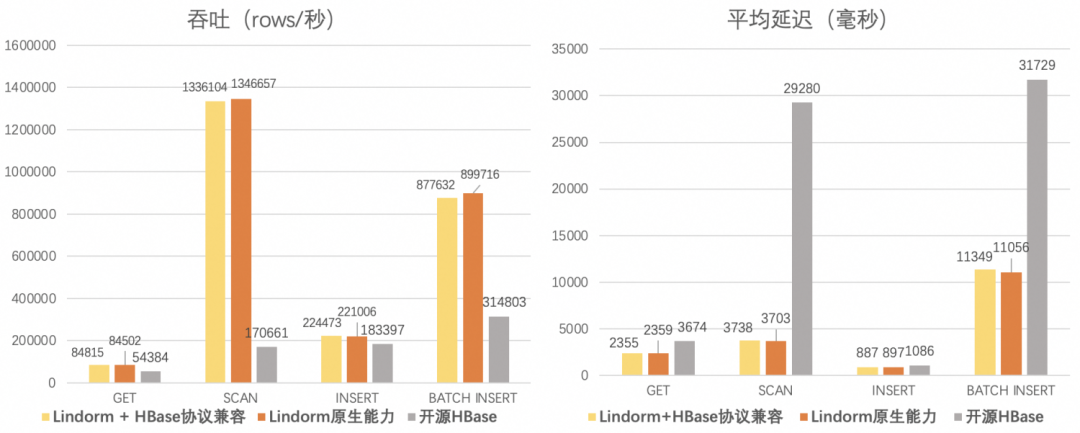
针对这些需求,Lindorm设计并实现了协议级别的深度兼容,通过增加一个HBase Proxy模块完全支持HBase的原生协议。
该方案相对于Lindorm的原生客户端,读写链路上新增了一个代理,因此整体链路会多一个环节。但是得益于Lindorm多年以来持续的性能优化,并且通过短路优化技术,将兼容开源HBase客户端直连场景的性能优化至与使用Lindorm原生客户端的场景持平。帮助用户在实现HBase无缝搬站的同时,也可享受到Lindorm在阿里集团内沉淀多年的性能优势。
落地案例
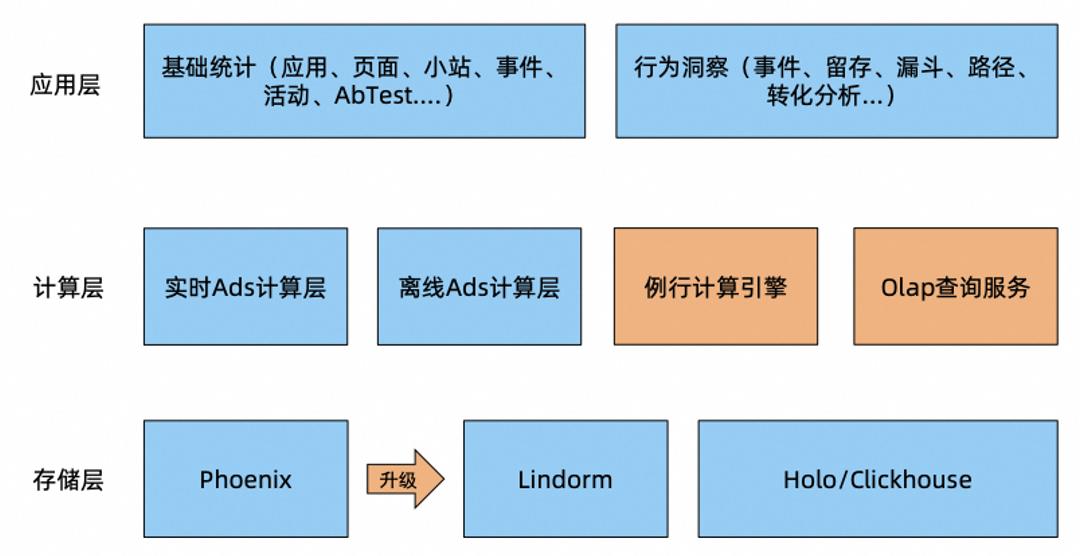
Lindorm的SQL能力经过这两年的发展已经初具规模,随着Lindorm各个引擎之间的融合程度越来越高,Lindorm 的SQL引擎也将作为Lindorm产品的统一接口去承接对各个引擎的数据访问。
但是Lindorm SQL作为执行OLTP型业务的接口,其能力的完备度早先存在一些不足。比如,对于在线业务中常见的小范围ORDER BY、GROUP BY这样的计算时常会触发全表扫描,导致性能不高。针对这样的问题,Lindorm的SQL与存储引擎紧密结合,基于存储引擎提供的数据近端计算能力,在优化器中进行了深度的优化,实现了大量计算能力的下推。比如在与宽表引擎协同时实现排序、分组聚合的下推;在与时序引擎协同时实现了时间线扫描、降采样等特色计算能力的下推,使得查询中流入SQL引擎的结果量级大幅下降、SQL引擎查询计划的节点深度减少,实现了查询性能的提升。
落地案例
▶︎ 集团A+业务的架构升级项目中,基于SQL的Ads结果存储场景选择了使用 Lindorm 替换原有的Phoenix + HBase的方案。同等计算资源下查询性能得到了提升的同时,成本降低为原先的1/2。同时,全面采用Lindorm SQL 能力,支撑了平台迭代开发分析洞察、URL搜索、留存分析等能力。
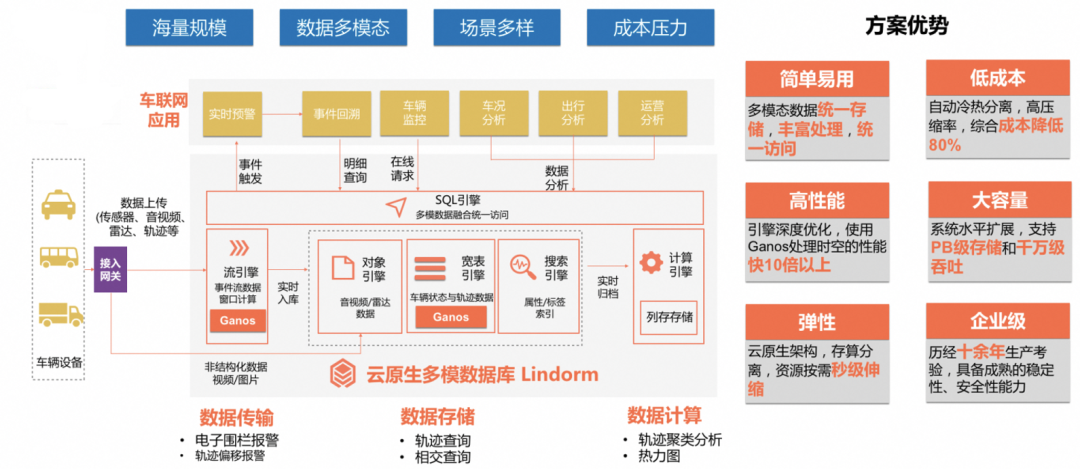
1. 车载信息服务提供商(TSP)
2. 自动驾驶厂商
3. 政府监管方为代表的平台管理
Geo类型 Lindorm团队和达摩院Ganos团队合作,内置了达摩院空天数据库引擎Ganos,原生支持地理空间类型及相关算子,可以一站式的解决海量轨迹场景的存储和各类查询需求。在Lindorm中可以使用SQL语法非常便捷地处理各类时空查询场景,在查询性能上,要大幅领先业界已有系统2~3倍。
Blob类型 Lindorm新增支持Blob类型,Blob类型的数据会直接存储在Lindorm底层的文件系统中,并使用Key-Value分离方式的存储,避免了传统数据库存储大KV数据库时产生的读写放大问题。因此在Lindorm中,使用SQL就可以轻松存储数GB的大对象数据。
JSON类型 JSON类型给车辆网这种存在大量半结构化数据的场景中带来了不少便利。Lindorm支持了原生的JSON类型,用户可以直接使用JSON类型实现整存零取,部分更新,甚至支持给JSON的部分列建立二级索引,搜索索引;也可以直接利用JSON内的经纬度坐标直接建立Ganos时空索引,实现时空查询。
CREATE TABLE vehicle_data (vehicle_id VARCHAR,vtime BIGINT,vender VARCHAR,vevent JSON,vloc GEOMETRY(POINT),blf_data BLOB,PRIMARY KEY (vehicle_id, vtime)) WITH (NUMREGIONS='256');
▶︎ 在车联网场景中,用户利用Lindorm的时空数据管理和计算能力,解决了他们存储车辆轨迹、计算电子围栏等多个痛点。
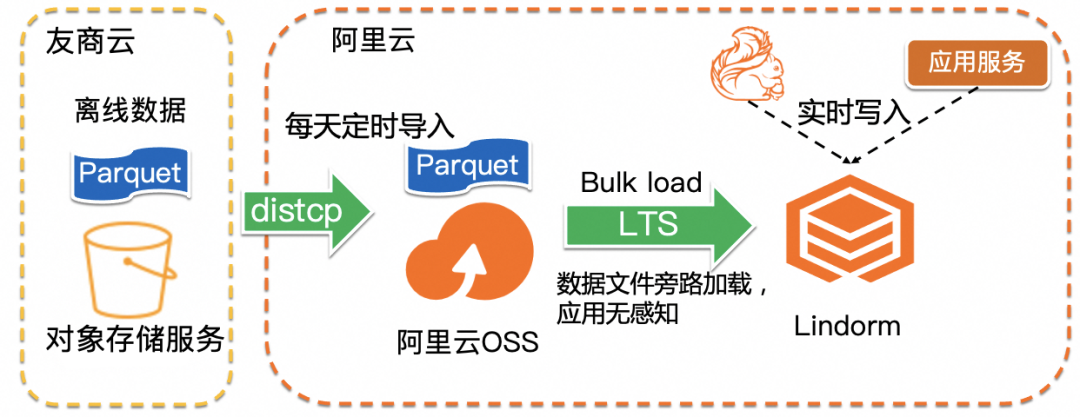
3.2.4 更加高效的离线数据导入
落地案例
▶︎ 在某社区搜索场景,业务需要每日执行数据的离线导入。LTS Bulkload基于Lindorm计算引擎提供的云原生弹性能力,可以按需配置资源以整体较低的成本高性能地完成数据导入。
4.未来展望
5.结束语
Lindorm的发展,离不开所有客户的鼓励与鞭策,也离不开技术同仁的宣传与推广。感谢各位的支持,也欢迎大家继续给我们提出各种建议,我们一定努力做最好的大数据 NoSQL 产品,众志成城、不忘初心、砥砺前行!










 点击「阅读原文」查看云原生多模数据库Lindorm更多内容
点击「阅读原文」查看云原生多模数据库Lindorm更多内容
