




1.概述
在分布式系统中,负载均衡是一个非常重要的功能,HBase通过Region的数量实现负载均衡,即通过hbase.master.loadbalancer.class实现自定义负载均衡算法。下面将为大家剖析HBase负载均衡的相关内容以及性能指标。
2.内容
HBase系统负载均衡是一个周期性的操作,通过负载均衡来均匀分配Region到各个RegionServer上,通过hbase.balancer.period属性来控制负载均衡的时间间隔,默认是5分钟。触发负载均衡操作是有条件的,但是如果发生以下情况则不会触发负载均衡操作:
负载均衡自动操作balance_switch关闭,即:balance_switch false;
HBase Master节点正在初始化操作;
HBase集群中正在执行RIT,即Region正在迁移中;
HBase集群正在处理离线的RegionServer;
2.1 负载均衡算法
HBase执行负载均衡操作的时候,如何判断各个RegionServer节点上的Region个数是否均衡,这里通过以下步骤来判断:
计算均衡值的区间范围,通过总Region个数以及RegionServer节点个数,算出平均Region个数,然后在此基础上计算最小值和最大值;
遍历超过Region最大值的RegionServer节点,将该节点上的Region值迁移出去,直到该节点的Region个数小于等于最大值的Region;
遍历低于Region最小值的RegionServer节点,分配集群中的Region到这些RegionServer上,直到大于等于最小值的Region;
负责上述操作,直到集群中所有的RegionServer上的Region个数在最小值与最大值之间,集群才算到达负载均衡,之后,即使再次手动执行均衡命令,HBase底层逻辑判断会执行忽略操作。
2.2 算法流程实例
下面笔者通过实际的应用场景来给大家剖析HBase负载均衡算法的实现流程。举个例子,假如我们当前有一个5台节点规模的HBase集群(包含Master和RegionServer),其中2台Master和3台RegionServer组成,每台RegionServer上的Region个数,如图所示:
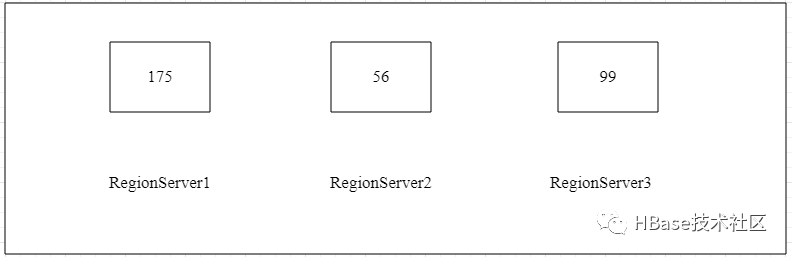
执行负载均衡操作之前,首先计算集群中总的Region个数,当前实例中集群中的Region总个数为175+56+99=330,然后计算每个RegionServer需要容纳的Region平均值,计算结果:
平均值(110) = 总Region个数(330) / RegionServers总数(3)
计算最小值和最大值来判断HBase集群是否需要进行负载均衡操作,计算公式:
# hbase.regions.slop 权重值,默认为0.2
最小值 = Math.floor(平均值 * (1-0.2))
最大值 = Math.ceil(平均值 * (1+0.2))
HBase集群如果判断各个RegionServer中的最小Region个数大于计算后的最小值,并且最大Region个数小于最大值,这是直接返回不会触发负载均衡操作。根据实例中给出的Region数,计算得出最小值Region为88,最大值Region为120。
由于实例中RegionServer2的Region个数为56,小于最小值Region数88,而RegionServer1的Region个数为175,大于了最大值Region数120,所以需要负载均衡操作。
HBase系统提供管理员命令来操作负载均衡,具体操作命令:
# 使用hbase shell命令进入到HBase控制台,然后开启自动执行负载均衡
hbase(main):001:0> balance_switch true
balance_switch命令底层实现balance_switch.rb和admin.rb文件源码:
module Shell
module Commands
class BalanceSwitch < Command
def help
<<-EOF
Enable/Disable balancer. Returns previous balancer state.
Examples:
hbase> balance_switch true
hbase> balance_switch false
EOF
end
def command(enableDisable)
prev_state = admin.balance_switch(enableDisable) ? 'true' : 'false'
formatter.row(["Previous balancer state : #{prev_state}"])
prev_state
end
end
end
end
#----------------------------------------------------------------------------------------------
# Enable/disable balancer
# Returns previous balancer switch setting.
def balance_switch(enableDisable)
@admin.setBalancerRunning(
java.lang.Boolean.valueOf(enableDisable), java.lang.Boolean.valueOf(false)
)
end
此命令输出的是之前负载均衡器balancer的开关设置,再看balance_switch命令处理实现源码:
/**
* Assigns balancer switch according to BalanceSwitchMode
* @param b new balancer switch
* @param mode BalanceSwitchMode
* @return old balancer switch
*/
boolean switchBalancer(final boolean b, BalanceSwitchMode mode) throws IOException {
boolean oldValue = master.loadBalancerTracker.isBalancerOn();
boolean newValue = b;
try {
if (master.cpHost != null) {
master.cpHost.preBalanceSwitch(newValue);
}
try {
if (mode == BalanceSwitchMode.SYNC) {
synchronized (master.getLoadBalancer()) {
master.loadBalancerTracker.setBalancerOn(newValue);
}
} else {
master.loadBalancerTracker.setBalancerOn(newValue);
}
} catch (KeeperException ke) {
throw new IOException(ke);
}
LOG.info(master.getClientIdAuditPrefix() + " set balanceSwitch=" + newValue);
if (master.cpHost != null) {
master.cpHost.postBalanceSwitch(oldValue, newValue);
}
master.getLoadBalancer().updateBalancerStatus(newValue);
} catch (IOException ioe) {
LOG.warn("Error flipping balance switch", ioe);
}
return oldValue;
}
此时HBase负载均衡自动操作就开启完毕,但是如果我们需要立即均衡集群的Region个数怎么办?这里HBase也提供管理命令,通过balancer命令来实现,操作命令:
hbase(main):001:0> balancer
balancer命令实现查看balancer.rb和admin.rb文件源码:
module Shell
module Commands
class Balancer < Command
def help
<<-EOF
Trigger the cluster balancer. Returns true if balancer ran and was able to
tell the region servers to unassign all the regions to balance (the re-assignment itself is async).
Otherwise false (Will not run if regions in transition).
Parameter tells master whether we should force balance even if there is region in transition.
WARNING: For experts only. Forcing a balance may do more damage than repair
when assignment is confused
Examples:
hbase> balancer
hbase> balancer "force"
EOF
end
def command(force = nil)
force_balancer = 'false'
if force == 'force'
force_balancer = 'true'
elsif !force.nil?
raise ArgumentError, "Invalid argument #{force}."
end
formatter.row([admin.balancer(force_balancer) ? 'true' : 'false'])
end
end
end
end
#----------------------------------------------------------------------------------------------
# Requests a cluster balance
# Returns true if balancer ran
def balancer(force)
@admin.balancer(java.lang.Boolean.valueOf(force))
end
该命令通过调用负载均衡器balancer的balanceCluster()方法生成负载均衡计划执行集群的负载均衡操作,Master实现负载均衡底层源码:
public boolean balance(boolean force) throws IOException {
// if master not initialized, don't run balancer.
if (!isInitialized()) {
LOG.debug("Master has not been initialized, don't run balancer.");
return false;
}
if (isInMaintenanceMode()) {
LOG.info("Master is in maintenanceMode mode, don't run balancer.");
return false;
}
int maxRegionsInTransition = getMaxRegionsInTransition();
synchronized (this.balancer) {
// If balance not true, don't run balancer.
if (!this.loadBalancerTracker.isBalancerOn()) return false;
...
boolean isByTable = getConfiguration().getBoolean("hbase.master.loadbalance.bytable", false);
Map<TableName, Map<ServerName, List<RegionInfo>>> assignmentsByTable =
this.assignmentManager.getRegionStates().getAssignmentsByTable(!isByTable);
List<RegionPlan> plans = new ArrayList<>();
//Give the balancer the current cluster state.
this.balancer.setClusterMetrics(getClusterMetricsWithoutCoprocessor());
this.balancer.setClusterLoad(assignmentsByTable);
for (Map<ServerName, List<RegionInfo>> serverMap : assignmentsByTable.values()) {
serverMap.keySet().removeAll(this.serverManager.getDrainingServersList());
}
for (Entry<TableName, Map<ServerName, List<RegionInfo>>> e : assignmentsByTable.entrySet()) {
List<RegionPlan> partialPlans = this.balancer.balanceCluster(e.getKey(), e.getValue());
if (partialPlans != null) plans.addAll(partialPlans);
}
long balanceStartTime = System.currentTimeMillis();
long cutoffTime = balanceStartTime + this.maxBlancingTime;
int rpCount = 0; // number of RegionPlans balanced so far
if (plans != null && !plans.isEmpty()) {
int balanceInterval = this.maxBlancingTime / plans.size();
LOG.info("Balancer plans size is " + plans.size() + ", the balance interval is "
+ balanceInterval + " ms, and the max number regions in transition is "
+ maxRegionsInTransition);
for (RegionPlan plan: plans) {
LOG.info("balance " + plan);
//TODO: bulk assign
this.assignmentManager.moveAsync(plan);
rpCount++;
balanceThrottling(balanceStartTime + rpCount * balanceInterval, maxRegionsInTransition,
cutoffTime);
// if performing next balance exceeds cutoff time, exit the loop
if (rpCount < plans.size() && System.currentTimeMillis() > cutoffTime) {
// TODO: After balance, there should not be a cutoff time (keeping it as
// a security net for now)
LOG.debug("No more balancing till next balance run; maxBalanceTime="
+ this.maxBlancingTime);
break;
}
}
}
...
}
// If LoadBalancer did not generate any plans, it means the cluster is already balanced.
// Return true indicating a success.
return true;
}
但是这样每次手动执行,每次均衡的个数不一定能满足要求,那么我们可以通过封装该命令,用脚本来调度执行,具体实现代码:
#! /bin/bash
num=$1
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : RegionServer Start Balancer..."
if [ ! -n "$num" ]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Default Balancer 20 Times."
num=20
elif [[ $num == *[!0-9]* ]]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Input [$num] Times Must Be Number."
exit 1
else
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : User-Defined Balancer [$num] Times."
fi
for (( i=1; i<=$num; i++ ))
do
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Balancer [$i] Times,Total [$num] Times."
echo "balancer"|hbase shell
sleep 5
done
此脚本默认执行20次,可以通过输入整型参数来自定义执行次数。
当HBase集群检查完所有的RegionServer上的Region个数已打要求,那么此时集群的负载均衡操作就已经完成了。如果没有达到要求,可以再次执行上述脚本,直到所有的Region个数在最小值和最大值之间为止。当HBase集群中所有的RegionServer完成负载均衡后,实例中的各个RegionServer上的Region个数分布,如图所示:
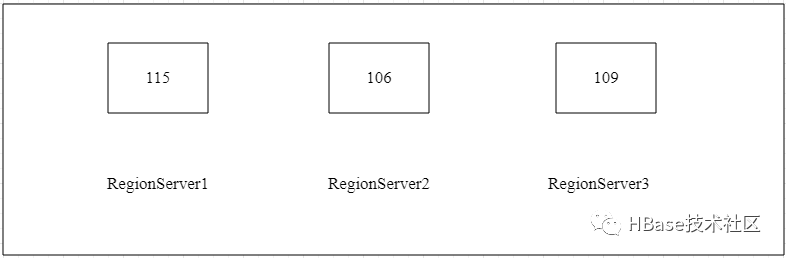
此时各个RegionServer节点上的Region个数均在最小值和最大值范围内,HBase集群各个RegionServer节点上的Region处理均衡状态。
3.性能指标
HBase系统有一个非常重要的性能指标,那就是集群处理请求的延时。HBase系统为了反应集群内部处理请求所耗费的时间提供一个工具类即:
org.apache.hadoop.hbase.tool.Canary
此类主要用来检查HBase系统的耗时状态。如果不知道使用方法,通过help命令来查看具体的用法,操作命令:
hbase org.apache.hadoop.hbase.tool.Canary -help
(1)查看集群中每个表中每个Region的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary
(2)查看money表中每个Region的耗时情况,多个表之间使用空格分割
# 查看money表和person表
hbase org.apache.hadoop.hbase.tool.Canary money person
(3)查看每个RegionServer的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary -regionserver dn1
通常情况下我们比较关注每个RegionServer节点的耗时情况,将该命令封装一下,然后打印集群中每个RegionServer的耗时情况,脚本实现:
#########################################################
# 将捕获的RS耗时,写入到InfluxDB中进行存储,用于绘制历史趋势图
#########################################################
#!/bin/bash
post_influxdb_write='http://influxdb:8086/write?db=telegraf_rs'
source /home/hadoop/.bash_profile
for i in `cat rs.list`
do
timespanStr=`(hbase org.apache.hadoop.hbase.tool.Canary -regionserver $i 2>&1) | grep tool.Canary`
timespanMs=`echo $timespanStr|awk -F ' ' '{print $NF}'`
timespan=`echo $timespanMs|awk -F "ms" '{print $1}'`
echo `date +'%Y-%m-%d %H:%M:%S'` INFO : RegionServer $i delay $timespanMs .
currentTime=`date "+%Y-%m-%d %H:%M:%S"`
currentTimeStamp=`date -d "$currentTime" +%s`
insert_sql="regionsever,host=$i value=$timespan ${currentTimeStamp}000000000"
#echo $insert_sql
curl -i -X POST "$post_influxdb_write" --data-binary "$insert_sql"
done
exit
4.总结
维护HBase集群,比如重启某几个RegionServer节点后,可能会发送Region不均衡的情况,这时如果开启自动均衡后,需要立即使当前集群上其他RegionServer上的Region处于均衡状态,那么就可以使用手动均衡操作。另外,HBase集群各个RegionServer的耗时情况,能够反映当前集群的健康状态。

大家工作学习遇到HBase技术问题,把问题发布到HBase技术社区论坛http://hbase.group,欢迎大家论坛上面提问留言讨论。想了解更多HBase技术关注HBase技术社区公众号(微信号:hbasegroup),非常欢迎大家积极投稿。

号外:值此国庆假期特别感谢以下公众号推广HBase技术社区,强烈推荐关注!
【阿里巴巴中间件】
阿里巴巴中间件团队,是国内为数不多的极具技术挑战性的团队之一,依托于阿里巴巴集团的巨大流量和海量数据,以及集团对系统稳定性的高要求,使得团队有机会去面对一个又一个的技术难题,创造一个又一个的技术奇迹。
我们是一群不安于现状且喜欢折腾的人,未必很资深但是很执着、充满热情。大家来自五湖四海,到这里一起解决技术难题,提升系统性能,完成业务突破,构建新的应用,玩转技术、业务、数据和无线。
我们在这里发声,在这里互动,还有服务开发者的中间件小姐姐,更有不定期福利放出。

【中生代架构】
中生代架构,囊括金融科技,电商技术架构等知识,架构师从入门到提高必备必知,每月精彩技术图书赠送,线上线下技术交流,除了技术干货之外,也会关注架构师的个人成长,心得领悟

【云时代架构】
“云时代架构”技术社区秉着“做互联网时代适合的架构”原则,回归架构的简洁之美,为读者提供互联网前沿技术解决方案、方法论和优秀实践,目前提供分享、培训、开源和咨询等技术服务。已出版图书《分布式服务架构原理、设计与实践》《可伸缩服务架构框架与中间件》

【Java架构沉思录】
本公众号专注但不限于Java Web领域的技术分享。目前已经发布Java进阶、MySQL优化、Redis高级应用、Spring进阶、计算机网络、密码学、设计模式、微服务、Linux、Zookeeper等优质原创内容。不定期发布独家内推资讯,每月至少举办1次送书活动。偶尔也会分享职场感悟以及程序员认知提升话题。是你磨练技术、提升认知、积累人脉的不二选择。

【养码场】
一个技术人职场社交平台。现有“养码人” 80000+ ,覆盖 JAVA / PHP / iOS / 测试 / 运维等领域。80% 级别在 P6 及以上,含 P9 技术大咖 30 余人,技术总监和 CTO 500 余人。在这里,你可以对话大咖、获得招聘内推,还有满满的干货等你来!

【秦子帅】
专注于Android、Java、Python技术分享,从起步到进阶,坚持原创,认真总结每一个阶段的技术干货,包括面试、设计模式架构,性能优化、技术功能实现等;不仅如此,还会分享一些职场经验感悟。每个月都会争取送书活动给大家。

【Sharding-Sphere官微】
定期发布Sharding-Sphere官方更新。Sharding-Sphere由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar组成的开源生态圈,提供数据分片、读写分离、柔性事务和数据治理功能。

【工匠小猪猪的技术世界】
Java进阶技术干货、实践分享、新技术、算法研磨、追求代码写得更快更好更健壮、最全的hikari源码解析及最佳实践、Sharding-JDBC狂热爱好者,欢迎关注!!!

