




假如让我们自己设计一个IP地址的备注系统,把全网IP地址存到纯文本文件中,这个文件预计会有多大?
全网 IPv4 地址范围为 0.0.0.0 到 255.255.255.255,共计有 4294967295,即 42 亿个地址。如果用文本文件来存IP地址,一行一个。1亿个IP地址大概占用的磁盘空间为1.3GB,42亿个地址大概会占用50G的空间。
这些数据不管放在哪儿,查询效率都是个问题。如果放在数据库中,行数为千万级的表在业务中已经属于大表,要单独拿出来优化。而 ip2region 采用的是IP段的方式来备注IP的属地信息。
ip2region是一个离线IP地址定位库和IP定位数据管理框架,具有10微秒级别的查询效率,通过它自己定义格式的数据库文件xdb来提高查询效率。
它自带的 ip2region.xdb 数据库文件只有11M大小,包含了 0.0.0.0 到 255.255.255.255 全网的 IP 地址属地信息。
它的项目地址为:
https://github.com/lionsoul2014/ip2region
使用 git clone 下来后,它提供了 ip2region.xdb 文件和一个数据库文件生成器,以及使用接口。其项目代码的目录结构如下:
ip2region├── ReadMe.md├── binding│ ├── python├── data│ ├── global_region.csv│ ├── ip.merge.txt│ └── ip2region.xdb├── maker└── python
我们先看下如何使用,ip2region 提供了一个交互式测试接口,可以用来交互式查询 IP 属地信息。使用方法为:
$ cd binding/python/$ python ./search_test.py --db=../../data/ip2region.xdb --cache-policy=contentip2region xdb searcher test program, cachePolicy: contenttype 'quit' to exitip2region>> 192.168.10.1{region: 0|0|0|内网IP|内网IP , took: 0.0 ms}ip2region>> 114.114.114.114{region: 中国|0|江苏省|南京市|0 , took: 0.0 ms}ip2region>> 8.8.8.8{region: 美国|0|0|0|Level3 , took: 0.0 ms}ip2region>> 202.103.24.68{region: 中国|0|湖北省|武汉市|电信 , took: 0.0 ms}ip2region>>
可以看到查询效率都在微秒级,它返回的数据格式为 `国家|区域|省份|城市|ISP`,只有中国的数据绝大部分精确到了城市,其他国家部分数据只能定位到国家,字段中数据为空时用 0 表示。
除了可以交互式查询,它也支持批量查询,demo 代码可参考以下文章
ip2region 查询依赖 xdb 数据库文件,它的数据来源主要来自以下三个服务:
淘宝IP地址库
GeoIP
纯真IP库
目前淘宝IP地址库已经发出下线通知,服务截止至2022年3月31日起永久关停服务,不再对外提供API查询。好在 ip2region 把原始数据保存了下来,存放在 data/ip.merge.txt 文件中,共计 683591 个网段。我们可以在这个数据的基础上构建自己的 xdb 数据库文件。
我们先看下ip.merge.txt数据文件的内容,思考一下基于这个地址段数据能做些什么。
$ cd ip2region/data$ grep 内网 ip.merge.txt
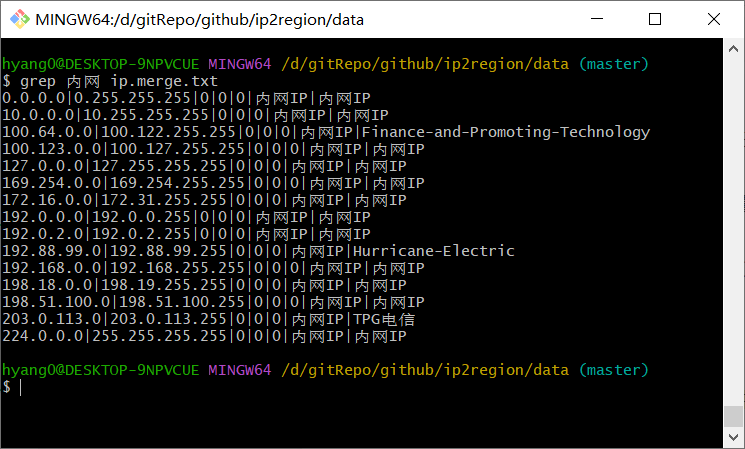
原始数据格式为 `起始地址|结束地址|国家|区域|省份|城市|ISP` ,我们可以从 ip.merge.txt 中过滤出我们感兴趣的地址段。比如内网地址段,国内地址段,省内地址段。其中这里显示的内网地址段比我们常见的三个地址段要更多,其中加了部分运营商级私有地址段,这个是扩展协议。因为公网地址不足,所以运营商拿出来一部分地址作为NAT地址,这部分原属于公网地址的部分也被纳入到私网地址,只有运营商会使用。
我们常用的内网地址段为:
10.0.0.0-10.255.255.255
172.16.0.0-172.31.255.255
192.168.0.0-192.168.255.255
国内地址段:
$ grep 中国 ip.merge.txt
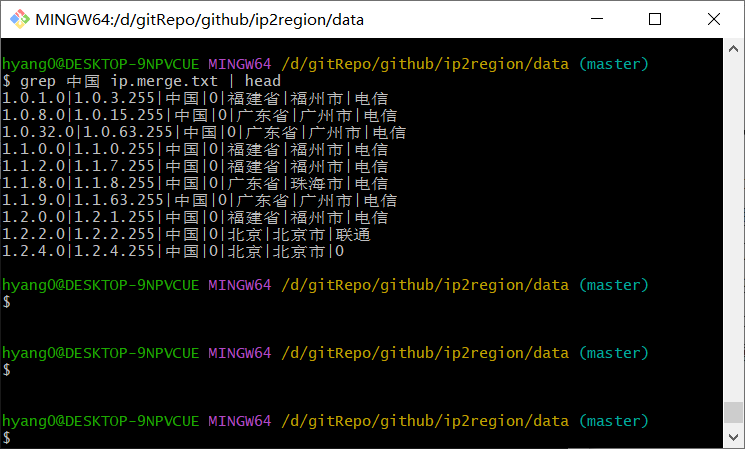
有了原始数据,我们看下如何基于原始数据生成 xdb 数据库文件。
$ cd maker/python/$ python main.py gen --src=../../data/ip.merge.txt --dst=./my.xdb
通过 ip2region 提供的 maker 程序,可以生成自己的 xdb 文件。原始数据是可以维护的,txt 版本的数据文件为 40M,生成 xdb 文件后只有 11M。
这里需要注意的是自己构造的 ip.merge.txt 文件,地址段必须是连续的,不然会报错:
$ cat local_ip.txt0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP10.0.0.0|10.255.255.255|0|0|0|内网IP|内网IP$ python main.py gen --src=./local_ip.txt --dst=./my.xdbERROR - discontinuous data segment: last.eip+1(167772160)!=seg.sip(184549375, 10.0.0.0)
对 maker.py 调试发现每一行的地址必须是连续的,如果出现段之间的跳跃,maker 程序会报错。原始数据文件是从0.0.0.0-255.255.255.255连续的地址段,如果我们只想维护内网地址信息,则需要把各个中断的地址段补全。比如将如下地址段补全:
0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP10.0.0.0|10.255.255.255|0|0|0|内网IP|内网IP
补全后的地址段为:
0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP1.0.0.0|9.255.255.255|0|0|0|内网IP|内网IP10.0.0.0|10.255.255.255|0|0|0|内网IP|内网IP
补全后程序不再报错:
$ python main.py gen --src=./local_ip.txt --dst=./my.xdb2022-12-07 20:36:49,042-root-99-INFO - try to init the db header ...2022-12-07 20:36:49,042-root-122-INFO - try to load the segments ...2022-12-07 20:36:49,042-root-128-INFO - load segment: `0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP`2022-12-07 20:36:49,043-root-128-INFO - load segment: `1.0.0.0|9.255.255.255|0|0|0|内网IP|内网IP`2022-12-07 20:36:49,043-root-128-INFO - load segment: `10.0.0.0|10.255.255.255|0|0|0|内网IP|内网IP`2022-12-07 20:36:49,043-root-168-INFO - all segments loaded, length: 3, elapsed: 0.0010013580322265625[...]2022-12-07 20:36:49,729-root-271-INFO - write done, dataBlocks: 1, indexBlocks: (3, 2816), indexPtr: (524567, 563977)2022-12-07 20:36:49,729-root-67-INFO - Done, elapsed: 0m1s
生成好的数据文件可以用 bench_test.py 脚本测试数据是否完整:
$ cp local_ip.txt my.xdb d/$ cd ../../binding/python/$ python ./bench_test.py --db=/d/my.xdb --src=/d/local_ip.txt --cache-policy=contentBench finished, {cachePolicy: content, total: 15, took: 0.0 s, cost: 0.0 ms/op}
现在的很多程序都在收集我们的位置信息,这个信息可以用来做什么呢?最简单的使用场景就是绑定 IP 和 GPS 经纬度之间的关系。一些大的网站的后台IP地址库就是这么来的。现在的各种 web 服务的后台都是带日志的,以前这些 IP 日志都是没有意义的。但如果IP绑定额外的信息,这些日志数据就变得有意义了。
全文完。
如果转发本文,文末务必注明:“转自微信公众号:生有可恋”。
