




由于我们最近在 ClickHouse Cloud 中启用了字典,在这篇文章中,我们将借此机会提醒用户字典在加速查询方面的强大功能——尤其是那些包含 JOIN 的字典,以及一些使用技巧。
有兴趣在 ClickHouse Cloud 中试用字典吗?立即开始(https://clickhouse.cloud/signUp),获得 30 美元的 30 天免费额度。
此外,本文中的所有示例都可以在我们的play.clickhouse.com环境中重现(请参阅blogs数据库)。或者,如果您想更深入地研究这个数据集,ClickHouse Cloud 是一个很好的起点 - 使用免费试用启动一个集群,加载数据,让我们处理基础设施,然后开始查询!
快速回顾
对于那些刚接触天气数据集的人,我们的原始表架构如下所示:
CREATE TABLE noaa ( `station_id` LowCardinality(String), `date` Date32, `tempAvg` Int32 COMMENT 'Average temperature (tenths of a degrees C)', `tempMax` Int32 COMMENT 'Maximum temperature (tenths of degrees C)', `tempMin` Int32 COMMENT 'Minimum temperature (tenths of degrees C)', `precipitation` UInt32 COMMENT 'Precipitation (tenths of mm)', `snowfall` UInt32 COMMENT 'Snowfall (mm)', `snowDepth` UInt32 COMMENT 'Snow depth (mm)', `percentDailySun` UInt8 COMMENT 'Daily percent of possible sunshine (percent)', `averageWindSpeed` UInt32 COMMENT 'Average daily wind speed (tenths of meters per second)', `maxWindSpeed` UInt32 COMMENT 'Peak gust wind speed (tenths of meters per second)', `weatherType` Enum8('Normal' = 0, 'Fog' = 1, 'Heavy Fog' = 2, 'Thunder' = 3, 'Small Hail' = 4, 'Hail' = 5, 'Glaze' = 6, 'Dust/Ash' = 7, 'Smoke/Haze' = 8, 'Blowing/Drifting Snow' = 9, 'Tornado' = 10, 'High Winds' = 11, 'Blowing Spray' = 12, 'Mist' = 13, 'Drizzle' = 14, 'Freezing Drizzle' = 15, 'Rain' = 16, 'Freezing Rain' = 17, 'Snow' = 18, 'Unknown Precipitation' = 19, 'Ground Fog' = 21, 'Freezing Fog' = 22), `location` Point, `elevation` Float32, `name` LowCardinality(String) ) ENGINE = MergeTree() ORDER BY (station_id, date)
name、elevation或的概念location,每行只有一个station_id. 为了保持查询简单,我们最初将这些非规范化到stations.txt文件的每一行,以确保每个测量都有一个地理位置和站点名称。利用前两位数字station_id代表国家代码这一事实,我们可以通过知道其前缀并使用子字符串函数找到一个国家/地区的前 5 个温度。例如,葡萄牙:SELECT tempMax / 10 AS maxTemp, station_id, date, location, name FROM noaa WHERE substring(station_id, 1, 2) = 'PO' ORDER BY tempMax DESC LIMIT 5 ┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐ │ 45.8 │ PO000008549 │ 1944-07-30 │ (-8.4167,40.2) │ COIMBRA │ │ 45.4 │ PO000008562 │ 2003-08-01 │ (-7.8667,38.0167) │ BEJA │ │ 45.2 │ PO000008562 │ 1995-07-23 │ (-7.8667,38.0167) │ BEJA │ │ 44.5 │ POM00008558 │ 2003-08-01 │ (-7.9,38.533) │ EVORA/C. COORD │ │ 44.2 │ POM00008558 │ 2022-07-13 │ (-7.9,38.533) │ EVORA/C. COORD │ └─────────┴─────────────┴────────────┴───────────────────┴────────────────┘ 5 rows in set. Elapsed: 0.259 sec. Processed 1.08 billion rows, 7.46 GB (4.15 billion rows/s., 28.78 GB/s.)
✎
不幸的是,这个查询需要全表扫描,因为它不能利用我们的主键(station_id, date)。
改进数据模型
我们社区的成员很快提出了一个简单的优化,通过减少从磁盘读取的数据量来提高上述查询的响应时间。这可以通过station_id在修改查询以使用简单子查询之前跳过非规范化并将其存储在单独的表中来实现。
为了读者的利益,让我们首先回顾一下这个建议。下面我们创建一个stations表并通过使用 url 函数通过 HTTP 插入数据来直接填充它。
CREATE TABLE stations ( `station_id` LowCardinality(String), `country_code` LowCardinality(String), `state` LowCardinality(String), `name` LowCardinality(String), `lat` Float64, `lon` Float64, `elevation` Float32 ) ENGINE = MergeTree ORDER BY (country_code, station_id) INSERT INTO stations SELECT station_id, substring(station_id, 1, 2) AS country_code, trimBoth(state) AS state, name, lat, lon, elevation FROM url('https://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt', Regexp, 'station_id String, lat Float64, lon Float64, elevation Float32, state String, name String') SETTINGS format_regexp = '^(.{11})\\s+(\\-?\\d{1,2}\\.\\d{4})\\s+(\\-?\\d{1,3}\\.\\d{1,4})\\s+(\\-?\\d*\\.\\d*)\\s+(.{2})\\s(.*?)\\s{2,}.*$' 0 rows in set. Elapsed: 1.781 sec. Processed 123.18 thousand rows, 7.99 MB (69.17 thousand rows/s., 4.48 MB/s.)
正如我们在原始帖子中指出的那样,stations.txt格式不正确,因此我们使用 Regex 类型来解析字段值。
例如,我们现在假设我们的noaa表不再有location、elevation和name字段。我们的葡萄牙查询的前 5 个温度现在几乎可以用子查询来解决:
SELECT tempMax / 10 AS maxTemp, station_id, date, location, name FROM noaa WHERE station_id IN ( SELECT station_id FROM stations WHERE country_code = 'PO' ) ORDER BY tempMax DESC LIMIT 5 ┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐ │ 45.8 │ PO000008549 │ 1944-07-30 │ (-8.4167,40.2) │ COIMBRA │ │ 45.4 │ PO000008562 │ 2003-08-01 │ (-7.8667,38.0167) │ BEJA │ │ 45.2 │ PO000008562 │ 1995-07-23 │ (-7.8667,38.0167) │ BEJA │ │ 44.5 │ POM00008558 │ 2003-08-01 │ (-7.9,38.533) │ EVORA/C. COORD │ │ 44.2 │ POM00008558 │ 2022-07-13 │ (-7.9,38.533) │ EVORA/C. COORD │ └─────────┴─────────────┴────────────┴───────────────────┴────────────────┘ 5 rows in set. Elapsed: 0.009 sec. Processed 522.48 thousand rows, 6.64 MB (59.81 million rows/s., 760.45 MB/s.)
✎
这更快,因为子查询利用表的country_code主键stations。此外,父查询还可以利用其主键。只需要读取这些列的较小范围,从而减少磁盘上的数据,抵消了任何连接成本。正如我们社区成员指出的那样,在这种情况下保持数据非规范化是有益的。
不过这里有一个问题——我们依赖于我们的天气数据location并被name非规范化。如果我们假设我们没有这样做,为了避免重复数据删除,并遵循在stations表上保持规范化和分离的原则,我们需要一个完整的连接(实际上我们可能会保留location和name非规范化并接受存储成本) :
SELECT tempMax / 10 AS maxTemp, station_id, date, stations.name AS name, (stations.lat, stations.lon) AS location FROM noaa INNER JOIN stations ON noaa.station_id = stations.station_id WHERE stations.country_code = 'PO' ORDER BY tempMax DESC LIMIT 5 ┌─maxTemp─┬─station_id──┬───────date─┬─name───────────┬─location──────────┐ │ 45.8 │ PO000008549 │ 1944-07-30 │ COIMBRA │ (40.2,-8.4167) │ │ 45.4 │ PO000008562 │ 2003-08-01 │ BEJA │ (38.0167,-7.8667) │ │ 45.2 │ PO000008562 │ 1995-07-23 │ BEJA │ (38.0167,-7.8667) │ │ 44.5 │ POM00008558 │ 2003-08-01 │ EVORA/C. COORD │ (38.533,-7.9) │ │ 44.2 │ POM00008558 │ 2022-07-13 │ EVORA/C. COORD │ (38.533,-7.9) │ └─────────┴─────────────┴────────────┴────────────────┴───────────────────┘ 5 rows in set. Elapsed: 0.488 sec. Processed 1.08 billion rows, 14.06 GB (2.21 billion rows/s., 28.82 GB/s.)
✎
不幸的是,这比我们之前的非规范化方法慢,因为它需要全表扫描。其原因可以在我们的文档(https://clickhouse.com/docs/en/sql-reference/statements/select/join/#performance)中找到。
运行 JOIN 时,与查询的其他阶段相关的执行顺序没有优化。连接(右表中的搜索)在 WHERE 中过滤之前和聚合之前运行。”
该文档还建议将字典作为一种可能的解决方案。现在让我们演示如何在数据已规范化后使用字典提高此查询性能。
创建字典
字典为我们提供了数据的内存中键值对表示,并针对低延迟查找查询进行了优化。我们可以利用这种结构来提高一般查询的性能,特别是 JOIN 的优势在于 JOIN 的一侧代表适合内存的查找表。
选择源和密钥
在 ClickHouse Cloud 中,字典本身目前可以从两个来源填充:本地 ClickHouse 表和 HTTP URLs*。然后可以将字典的内容配置为定期重新加载以反映源数据中的任何更改。
* 我们预计将来会扩展此功能以包括对 OSS 中支持的其他来源的支持。
stations下面我们使用表格作为源来创建我们的字典。
CREATE DICTIONARY stations_dict ( `station_id` String, `state` String, `country_code` String, `name` String, `lat` Float64, `lon` Float64, `elevation` Float32 ) PRIMARY KEY station_id SOURCE(CLICKHOUSE(TABLE 'stations')) LIFETIME(MIN 0 MAX 0) LAYOUT(complex_key_hashed_array())
这里PRIMARY KEY是station_id并且直观地表示将在其上执行查找的列。值必须是唯一的,即具有相同主键的行将被删除重复数据。其他列代表属性。您可能会注意到我们已将我们的位置分隔为lat和lon因为该Point类型目前不支持作为字典的属性类型。和不太明显,需要一些解释LAYOUT。LIFETIME注意:在 ClickHouse Cloud 中,字典将自动在所有节点上创建。对于 OSS,如果使用复制数据库,这种行为是可能的。其他配置将需要在所有节点上手动或通过使用ON CLUSTER子句创建字典。
选择布局
字典的布局控制它在内存中的存储方式和主键的索引策略。每个布局选项都有不同的优缺点。
该flat类型分配一个数组,其条目数与最大键值一样多,例如,如果最大值为 100k,则该数组也将具有 100k 条目。这非常适合您在源数据中具有单调递增主键的情况。在这种情况下,它的内存非常紧凑,访问速度比基于哈希的替代方案快 4-5 倍——需要简单的数组偏移查找。但是,它的限制在于密钥大小也不能超过 500k - 尽管这可以通过设置进行配置max_array_size。它在大型稀疏分布上的效率也很低,在这种情况下会浪费内存。
对于有大量条目、大键值和/或值分布稀疏的情况,flat布局会变得不太理想。在这一点上,我们通常会推荐一个基于散列的字典——特别是hashed_array可以有效支持数百万条目的字典。这种布局比布局更节省内存,hashed而且速度几乎一样快。对于这种类型,哈希表结构用于存储主键,值提供到特定于属性的数组中的偏移位置。这是对比hashed布局,虽然速度稍快,但需要为每个属性分配一个哈希表——因此会消耗更多内存。因此,在大多数情况下,我们推荐hashed_array布局 - 尽管用户应该尝试hashed如果他们只有几个属性。
所有这些类型还要求密钥可转换为 UInt64。如果不是,例如,它们是字符串,我们可以使用散列字典的复杂变体:complex_key_hashed和complex_key_hashed_array,否则遵循上面的相同规则。
我们尝试使用下面的流程图来捕捉上述逻辑,以帮助您选择正确的布局(大多数情况下):
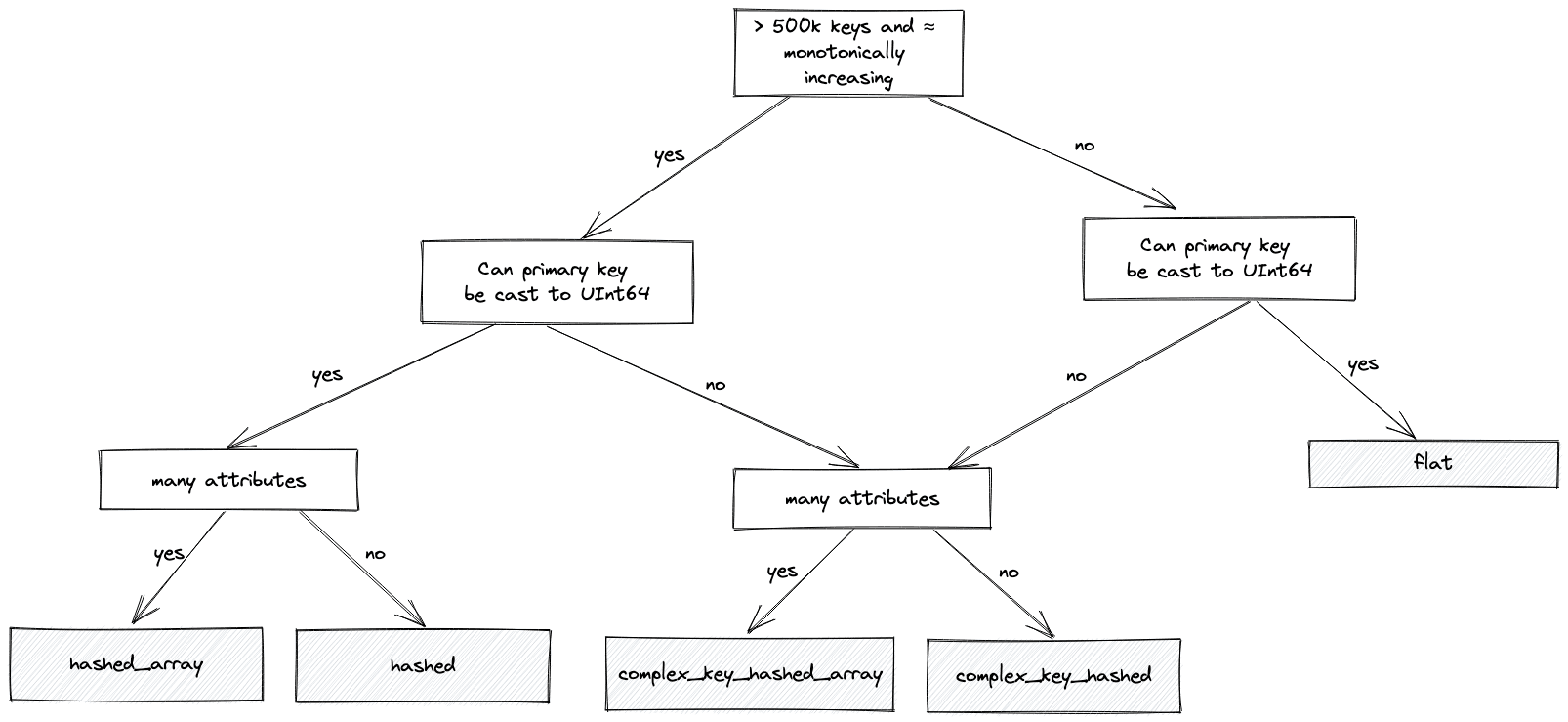
对于我们的数据,我们的主键是 String country_code,我们选择complex_key_hashed_array类型,因为我们的字典在每种情况下至少有三个属性。
注意:我们也有hashed和complex_key_hashed布局的稀疏变体。此布局旨在通过将主键拆分为组并在其中递增范围来实现恒定时间操作。我们很少推荐这种布局,只有当你只有一个属性时才有效。尽管操作是常数时间,但实际常数通常高于非稀疏变体。最后,ClickHouse 提供专门的布局,例如polygon和ip_trie。我们在原始博客中探讨了前者,并将其他人留到以后的帖子中使用,因为它们代表了更高级的用例。
选择一生
我们上面的字典 DDL 也强调了需要LIFETIME为我们的字典指定一个。这指定了通过重新阅读源代码来刷新字典的频率。这可以以秒为单位指定,也可以指定为一个范围,例如LIFETIME(300)或LIFETIME(MIN 300 MAX 360)。在后一种情况下,一个值将选择一个随机时间,均匀分布在范围内。这确保了当多个服务器更新时,字典源上的负载随时间分布。在我们的例子中使用的 valueLIFETIME(MIN 0 MAX 0)意味着字典内容永远不会被更新——在我们的例子中是合适的,因为我们的数据是静态的。
如果您的数据正在更改并且您需要定期重新加载数据,则可以通过返回一行的invalidate_query参数来控制此行为。如果此行的值在更新周期之间发生变化,ClickHouse 知道必须重新获取数据。例如,这可以返回时间戳或行计数。存在其他选项以确保自上次更新加载以来仅数据已更改 - 请参阅我们的文档以获取使用update_field.
使用字典
虽然我们的字典已经创建,但它需要一个查询来将数据加载到内存中。最简单的方法是发出一个简单的dictGet查询来检索单个值(将数据集作为副产品加载到字典中)或发出一个显式SYSTEM RELOAD DICTIONARY命令。
SYSTEM RELOAD DICTIONARY stations_dict 0 rows in set. Elapsed: 0.561 sec. SELECT dictGet(stations_dict, 'state', 'CA00116HFF6') ┌─dictGet(stations_dict, 'state', 'CA00116HFF6')─┐ │ BC │ └────────────────────────────────────────────────┘ 1 row in set. Elapsed: 0.001 sec.
✎
上面的dictGet示例检索station_id国家代码的值PO。
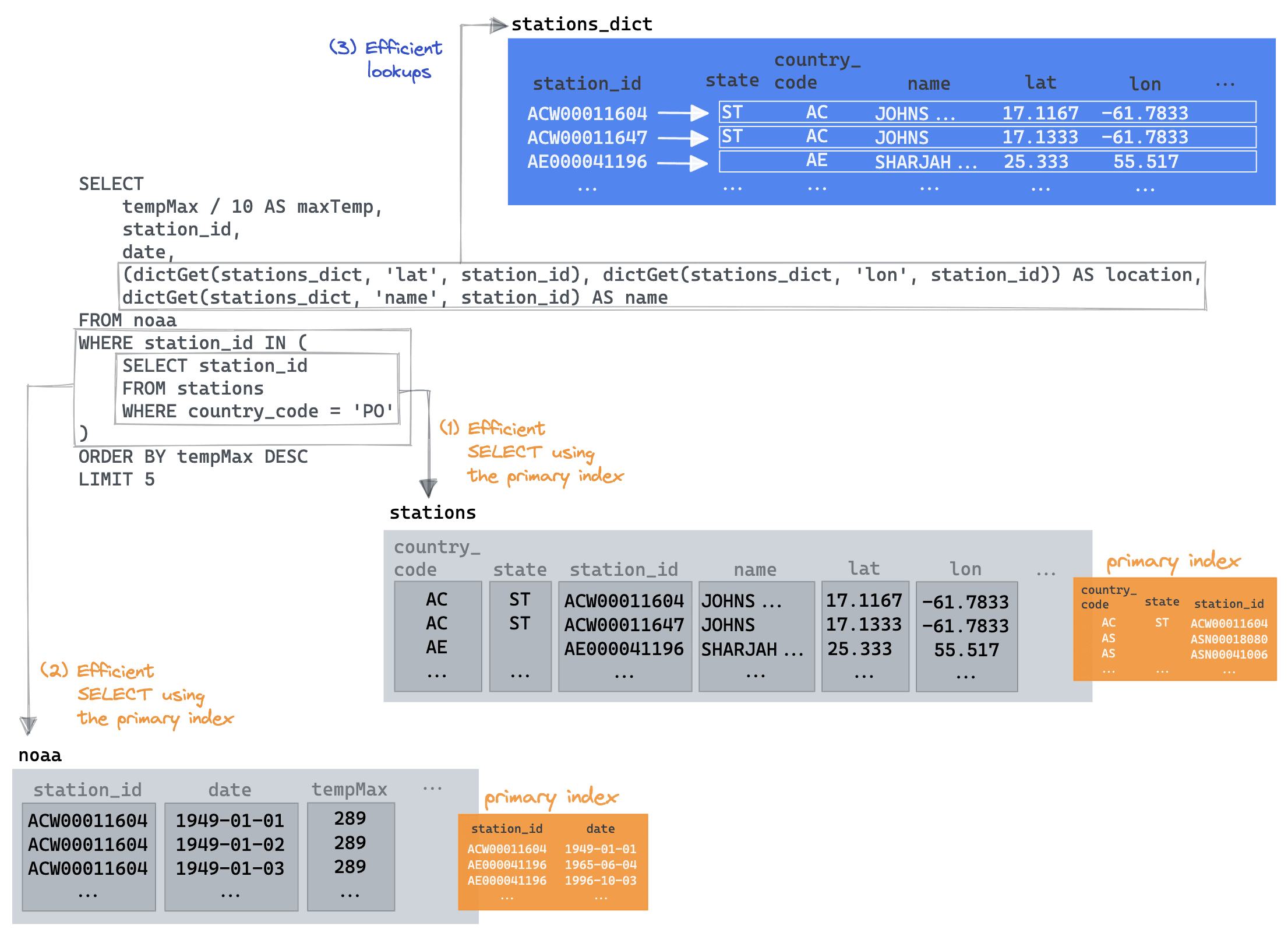
返回到我们最初的连接查询,我们可以恢复我们的子查询并仅将字典用于我们的位置和名称字段。
SELECT tempMax / 10 AS maxTemp, station_id, date, (dictGet(stations_dict, 'lat', station_id), dictGet(stations_dict, 'lon', station_id)) AS location, dictGet(stations_dict, 'name', station_id) AS name FROM noaa WHERE station_id IN ( SELECT station_id FROM stations WHERE country_code = 'PO' ) ORDER BY tempMax DESC LIMIT 5 ┌─maxTemp─┬─station_id──┬───────date─┬─location──────────┬─name───────────┐ │ 45.8 │ PO000008549 │ 1944-07-30 │ (40.2,-8.4167) │ COIMBRA │ │ 45.4 │ PO000008562 │ 2003-08-01 │ (38.0167,-7.8667) │ BEJA │ │ 45.2 │ PO000008562 │ 1995-07-23 │ (38.0167,-7.8667) │ BEJA │ │ 44.5 │ POM00008558 │ 2003-08-01 │ (38.533,-7.9) │ EVORA/C. COORD │ │ 44.2 │ POM00008558 │ 2022-07-13 │ (38.533,-7.9) │ EVORA/C. COORD │ └─────────┴─────────────┴────────────┴───────────────────┴────────────────┘ 5 rows in set. Elapsed: 0.012 sec. Processed 522.48 thousand rows, 6.64 MB (44.90 million rows/s., 570.83 MB/s.)
✎
现在好多了!这里的关键是我们能够利用子查询优化,利用它的country_code主键从中受益。然后,父查询能够将noaa表读取限制为仅那些返回的站 ID,再次利用其主键来最小化读取的数据。最后,dictGet只需要最后 5 行来检索name和location。我们将其可视化如下:
有经验的字典用户可能会想在这里尝试其他方法。例如,我们可以:
- 删除子查询并使用
dictGet(stations_dict, 'country_code', station_id) = 'PO'过滤器。这并不快(大约 0.5 秒),因为需要为每个站点进行字典查找。我们在下面看一个类似的例子。 - 利用字典可以在 JOIN 子句中使用的事实,例如表(见下文)。这与之前的提案面临相同的挑战,提供可比的性能。
我们当然欢迎改进!
更复杂的东西
考虑我们原始博客文章中的最终查询:
使用美国的滑雪胜地列表及其各自的位置,我们将这些与过去 5 年中任何一个月降雪量最多的前 1000 个气象站进行比较。按 geoDistance 对这个连接进行排序并将结果限制为距离小于 20 公里的结果,我们选择每个度假村的最佳结果并按总雪量对其进行排序。请注意,我们还将度假村限制在 1800 米以上,作为良好滑雪条件的广泛指标。
SELECT resort_name, total_snow / 1000 AS total_snow_m, resort_location, month_year FROM ( WITH resorts AS ( SELECT resort_name, state, (lon, lat) AS resort_location, 'US' AS code FROM url('https://gist.githubusercontent.com/Ewiseman/b251e5eaf70ca52a4b9b10dce9e635a4/raw/9f0100fe14169a058c451380edca3bda24d3f673/ski_resort_stats.csv', CSVWithNames) ) SELECT resort_name, highest_snow.station_id, geoDistance(resort_location.1, resort_location.2, station_location.1, station_location.2) / 1000 AS distance_km, highest_snow.total_snow, resort_location, station_location, month_year FROM ( SELECT sum(snowfall) AS total_snow, station_id, any(location) AS station_location, month_year, substring(station_id, 1, 2) AS code FROM noaa WHERE (date > '2017-01-01') AND (code = 'US') AND (elevation > 1800) GROUP BY station_id, toYYYYMM(date) AS month_year ORDER BY total_snow DESC LIMIT 1000 ) AS highest_snow INNER JOIN resorts ON highest_snow.code = resorts.code WHERE distance_km < 20 ORDER BY resort_name ASC, total_snow DESC LIMIT 1 BY resort_name, station_id ) ORDER BY total_snow DESC LIMIT 5
在我们用字典优化它之前,让我们用一个实际的表替换包含我们的度假村的 CTE。这确保我们拥有 ClickHouse 集群的本地数据,并且可以避免获取度假村的 HTTP 延迟。
CREATE TABLE resorts ( `resort_name` LowCardinality(String), `state` LowCardinality(String), `lat` Nullable(Float64), `lon` Nullable(Float64), `code` LowCardinality(String) ) ENGINE = MergeTree ORDER BY state
当我们填充这个表时,我们也借此机会将state字段与stations表对齐(我们稍后会用到)。度假村使用州名称,而车站使用州代码。为了确保这些是一致的,我们可以在将状态名称插入resorts表时将其映射到代码。这代表了另一个创建字典的机会——这次是基于 HTTP 源。
CREATE DICTIONARY states ( `name` String, `code` String ) PRIMARY KEY name SOURCE(HTTP(URL 'https://gist.githubusercontent.com/gingerwizard/b0e7c190474c847fdf038e821692ce9c/raw/19fdac5a37e66f78d292bd8c0ee364ca7e6f9a57/states.csv' FORMAT 'CSVWithNames')) LIFETIME(MIN 0 MAX 0) LAYOUT(COMPLEX_KEY_HASHED_ARRAY()) SELECT * FROM states LIMIT 2 ┌─name─────────┬─code─┐ │ Pennsylvania │ PA │ │ North Dakota │ ND │ └──────────────┴──────┘ 2 rows in set. Elapsed: 0.001 sec.
✎
在插入时,我们可以使用函数将我们的州名称映射到度假村的州代码dictGet。
INSERT INTO resorts SELECT resort_name, dictGet(states, 'code', state) AS state, lat, lon, 'US' AS code FROM url('https://gist.githubusercontent.com/Ewiseman/b251e5eaf70ca52a4b9b10dce9e635a4/raw/9f0100fe14169a058c451380edca3bda24d3f673/ski_resort_stats.csv', CSVWithNames) 0 rows in set. Elapsed: 0.389 sec.
SELECT resort_name, total_snow / 1000 AS total_snow_m, resort_location, month_year FROM ( SELECT resort_name, highest_snow.station_id, geoDistance(lon, lat, station_location.1, station_location.2) / 1000 AS distance_km, highest_snow.total_snow, station_location, month_year, (lon, lat) AS resort_location FROM ( SELECT sum(snowfall) AS total_snow, station_id, any(location) AS station_location, month_year, substring(station_id, 1, 2) AS code FROM noaa WHERE (date > '2017-01-01') AND (code = 'US') AND (elevation > 1800) GROUP BY station_id, toYYYYMM(date) AS month_year ORDER BY total_snow DESC LIMIT 1000 ) AS highest_snow INNER JOIN resorts ON highest_snow.code = resorts.code WHERE distance_km < 20 ORDER BY resort_name ASC, total_snow DESC LIMIT 1 BY resort_name, station_id ) ORDER BY total_snow DESC LIMIT 5 ┌─resort_name──────────┬─total_snow_m─┬─resort_location─┬─month_year─┐ │ Sugar Bowl, CA │ 7.799 │ (-120.3,39.27) │ 201902 │ │ Donner Ski Ranch, CA │ 7.799 │ (-120.34,39.31) │ 201902 │ │ Boreal, CA │ 7.799 │ (-120.35,39.33) │ 201902 │ │ Homewood, CA │ 4.926 │ (-120.17,39.08) │ 201902 │ │ Alpine Meadows, CA │ 4.926 │ (-120.22,39.17) │ 201902 │ └──────────────────────┴──────────────┴─────────────────┴────────────┘ 5 rows in set. Elapsed: 0.673 sec. Processed 580.53 million rows, 4.85 GB (862.48 million rows/s., 7.21 GB/s.)
✎
注意执行时间,看看我们是否可以进一步改进。此查询仍然假定location已对我们的天气测量值进行非规范化。我们现在可以从stations_dict字典中读取这个字段。这也将使我们能够方便地获取站点state并将其用于我们与resorts表的连接而不是code. 这个连接更小,但希望更快,即,我们不连接所有站点和所有美国度假胜地,而是限制在同一州的度假胜地。
我们的resorts表实际上很小(364 个条目)。尽管将其移动到字典中不太可能为该查询带来任何真正的性能优势,但它可能代表了一种在给定数据大小的情况下存储数据的明智方法。我们选择resort_name作为我们的主键,因为它必须是唯一的,如前所述。
CREATE DICTIONARY resorts_dict ( `state` String, `resort_name` String, `lat` Nullable(Float64), `lon` Nullable(Float64) ) PRIMARY KEY resort_name SOURCE(CLICKHOUSE(TABLE 'resorts')) LIFETIME(MIN 0 MAX 0) LAYOUT(COMPLEX_KEY_HASHED_ARRAY())
stations_dict在可能的情况下使用并加入resorts_dict。请注意我们如何仍然加入该state列,即使它不是我们resorts字典中的主键。在这种情况下,我们使用 JOIN 语法,字典将像表格一样被扫描。SELECT resort_name, total_snow / 1000 AS total_snow_m, resort_location, month_year FROM ( SELECT resort_name, highest_snow.station_id, geoDistance(resorts_dict.lon, resorts_dict.lat, station_lon, station_lat) / 1000 AS distance_km, highest_snow.total_snow, (resorts_dict.lon, resorts_dict.lat) AS resort_location, month_year FROM ( SELECT sum(snowfall) AS total_snow, station_id, dictGet(stations_dict, 'lat', station_id) AS station_lat, dictGet(stations_dict, 'lon', station_id) AS station_lon, month_year, dictGet(stations_dict, 'state', station_id) AS state FROM noaa WHERE (date > '2017-01-01') AND (state != '') AND (elevation > 1800) GROUP BY station_id, toYYYYMM(date) AS month_year ORDER BY total_snow DESC LIMIT 1000 ) AS highest_snow INNER JOIN resorts_dict ON highest_snow.state = resorts_dict.state WHERE distance_km < 20 ORDER BY resort_name ASC, total_snow DESC LIMIT 1 BY resort_name, station_id ) ORDER BY total_snow DESC LIMIT 5 ┌─resort_name──────────┬─total_snow_m─┬─resort_location─┬─month_year─┐ │ Sugar Bowl, CA │ 7.799 │ (-120.3,39.27) │ 201902 │ │ Donner Ski Ranch, CA │ 7.799 │ (-120.34,39.31) │ 201902 │ │ Boreal, CA │ 7.799 │ (-120.35,39.33) │ 201902 │ │ Homewood, CA │ 4.926 │ (-120.17,39.08) │ 201902 │ │ Alpine Meadows, CA │ 4.926 │ (-120.22,39.17) │ 201902 │ └──────────────────────┴──────────────┴─────────────────┴────────────┘ 5 rows in set. Elapsed: 0.170 sec. Processed 580.73 million rows, 2.87 GB (3.41 billion rows/s., 16.81 GB/s.)
✎
不错,速度快了一倍多!现在,精明的读者会注意到我们跳过了可能的优化。当然,我们也可以用elevation > 1800值 ie 的字典查找替换海拔检查dictGet(blogs.stations_dict, 'elevation', station_id) > 1800,从而避免读取表?这实际上会更慢,因为将对每一行执行字典查找,这比评估有序的高程数据慢 - 后者受益于移动到PREWHERE的子句。在这种情况下,我们受益于elevation非规范化。这类似于我们dictGet在之前的查询中没有使用 a 来过滤的方式country_code。
因此,这里的建议是测试!如果表中的大部分行都需要dictGet,例如,在某种情况下,您最好只使用 ClickHouse 的本机数据结构和索引。
最后提示
- 我们描述的字典布局完全驻留在内存中。请注意它们的用法并测试任何布局更改。您可以使用system.dictionaries表和
bytes_allocated列跟踪它们的内存开销。该表还包括一个last_exception可用于诊断问题的列。
SELECT *, formatReadableSize(bytes_allocated) AS size FROM system.dictionaries LIMIT 1 FORMAT Vertical Row 1: ────── database: blogs name: resorts_dict uuid: 0f387514-85ed-4c25-bebb-d85ade1e149f status: LOADED origin: 0f387514-85ed-4c25-bebb-d85ade1e149f type: ComplexHashedArray key.names: ['resort_name'] key.types: ['String'] attribute.names: ['state','lat','lon'] attribute.types: ['String','Nullable(Float64)','Nullable(Float64)'] bytes_allocated: 30052 hierarchical_index_bytes_allocated: 0 query_count: 1820 hit_rate: 1 found_rate: 1 element_count: 364 load_factor: 0.7338709677419355 source: ClickHouse: blogs.resorts lifetime_min: 0 lifetime_max: 0 loading_start_time: 2022-11-22 16:26:06 last_successful_update_time: 2022-11-22 16:26:06 loading_duration: 0.001 last_exception: comment: size: 29.35 KiB
- 虽然dictGet可能是您最常使用的字典函数,但存在变体,其中dictGetOrDefault和dictHas特别有用。另外,请注意特定于类型的函数,例如dictGetFloat64
flat字典大小限制为 500k 个条目。虽然可以扩展此限制,但将其视为移动到散列布局的指标。- 关于如何使用Polygon 字典来加速地理查询,我们推荐我们之前的博文(https://clickhouse.com/blog/real-world-data-noaa-climate-data)。
结论
在这篇博文中,我们展示了保持数据规范化有时会导致更快的查询,尤其是在使用字典的情况下。我们提供了一些简单和更复杂的示例来说明字典在哪些方面很有价值,并以一些有用的提示作为结尾。
致谢
特别感谢Stefan Käser提议改进我们原来的帖子,使用字典来加速查询。
原文标题:Using dictionaries to accelerate queries
原文作者:Dale McDiarmid
原文链接:https://clickhouse.com/blog/faster-queries-dictionaries-clickhouse
