




本文只针对创建 B-tree 索引
创建测试数据:
-- 创建表 create table index_t(id int, c1 int,c2 int,info text) ; -- 插入数据 insert into index_t select i,random()*10,10+random()*10,'test_'||i from generate_series(1,10000) as i ;
一、covering Index - 覆盖索引
1、简介
PostgreSQL 11版本引入 covering Index(覆盖索引) ,又称 INCLUDE 索引,是指使用INCLUDE关键字来创建索引。
2、语法
CREATE INDEX index_name ON table_name(column_name) INCLUDE(column_name [, ...])
3、用法
优点:使用 Index Only Scan(仅索引扫描),减少回表次数
例子:
-- 创建索引
--# 单列索引 - idx_id_indext
create index idx_id_indext on index_t(id) ;
-- 查询 id=500 的 info
maleah_db=# explain (analyze on,verbose on) select info from index_t where id = 500 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_id_indext on public.index_t (cost=0.29..8.30 rows=1 width=9) (actual time=0.025..0.026 rows=1 loops=1)
Output: info
Index Cond: (index_t.id = 500)
Planning Time: 0.073 ms
Execution Time: 0.044 ms
(5 rows)
可以看到,使用 idx_id_indext 单列索引进行 Index Scan。此时需要根据索引回表查找info的值
使用 include关键字创建覆盖索引,使用 index-only-scan,减少回表的次数:
--# 覆盖索引 - idx_idinfo_indext
create index idx_idinfo_indext on index_t(id) include(info) ;
-- 再次查看执行计划
maleah_db=# explain (analyze on,verbose on) select info from index_t where id = 500 ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_idinfo_indext on public.index_t (cost=0.29..4.30 rows=1 width=9) (actual time=0.036..0.036 rows=1 loops=1)
Output: info
Index Cond: (index_t.id = 500)
Heap Fetches: 0
Planning Time: 0.195 ms
Execution Time: 0.052 ms
(6 rows)
再次查看执行计划,使用新创建的 idx_idinfo_indext 覆盖索引,计划走了仅索引扫描,可以看到Heap Fetches: 0
4、内部原理
使用 pageinspect插件查看创建的 b-tree 类型的索引内部:
maleah_db=# select * from index_t where ctid = '(1,36)';
id | c1 | c2 | info
-----+----+----+----------
193 | 0 | 19 | test_193
(1 row)
maleah_db=# select ctid,vars,data from bt_page_items('idx_id_indext',1) where ctid = '(1,36)';
ctid | vars | data
--------+------+-------------------------
(1,36) | f | c1 00 00 00 00 00 00 00
(1 row)
maleah_db=# select ctid,vars,data from bt_page_items('idx_idinfo_indext',1) where ctid = '(1,36)';
ctid | vars | data
--------+------+-------------------------------------------------
(1,36) | t | c1 00 00 00 13 74 65 73 74 5f 31 39 33 00 00 00
(1 row)
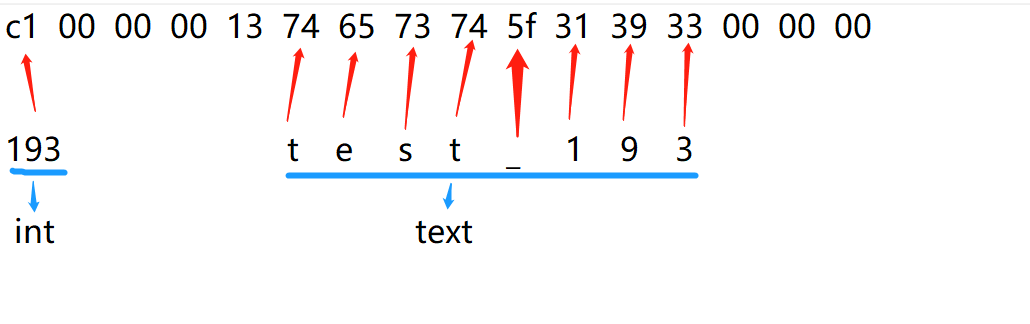
可以看到,普通的单列索引存储索引列的value,include索引不仅存储索引列的键值,还包括include列的值
二、multicolumn index - 多列索引
1、简介
multicolumn indexes(多列索引,又成复合索引)是指在表的多个列上创建索引
2、语法
CREATE INDEX index_name ON table_name(column_name, column_name [, ...])
3、用法
上述的例子可以使用覆盖索引减少回表,也可以通过创建多列索引来达到这一目的:
-- 创建多列索引
create index idx_id_info_indext on index_t(id,info) ;
-- 查看执行计划
maleah_db=# explain (analyze on,verbose on) select info from index_t where id = 500 ;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using idx_id_info_indext on public.index_t (cost=0.29..4.30 rows=1 width=9) (actual time=0.029..0.030 rows=1 loops=1)
Output: info
Index Cond: (index_t.id = 500)
Heap Fetches: 0
Planning Time: 0.175 ms
Execution Time: 0.047 ms
(6 rows)
如果 where 语句中存在多个条件(例如 id=500 and info=‘test_500’),INCLUDE索引不能发挥作用,只能选择多列索引
maleah_db=# explain (analyze on,verbose on) select * from index_t where id = 500 and info = 'test_500';
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_id_info_indext on public.index_t (cost=0.29..8.30 rows=1 width=21) (actual time=0.028..0.029 rows=1 loops=1)
Output: id, c1, c2, info
Index Cond: ((index_t.id = 500) AND (index_t.info = 'test_500'::text))
Planning Time: 0.094 ms
Execution Time: 0.047 ms
(5 rows)
4、内部
使用 pageinspect 查看多列索引内部:
maleah_db=# select ctid,vars,data from bt_page_items('idx_id_info_indext',1) where ctid = '(1,36)';
ctid | vars | data
--------+------+-------------------------------------------------
(1,36) | t | c1 00 00 00 13 74 65 73 74 5f 31 39 33 00 00 00
(1 row)
多列索引保存两个列的值
三、对比
相同点:
- 索引大小:相同。多列索引以及覆盖索引都会存储两个字段的值
- 适用 index-only-scan。覆盖索引在查询非索引列的字段值时,可以减少回表。
多列索引局限性:
可能会违反唯一索引或者唯一性约束
例,要求:id字段必须唯一。在多列上创建唯一索引:
create unique index idx_uniq_id_info_indext on index_t(id,info) ;
maleah_db=# insert into index_t values (1,2,3,'test') ;
INSERT 0 1
maleah_db=# select count(*) from index_t where id = 1 ;
count
-------
2
(1 row)
可以看到,可以插入id字段的重复值,在这种情况下,只能使用INCLUDE关键字创建覆盖索引:
maleah_db=# create unique index idx_uniq_idinfo_indext on index_t(id) include(info) ;
CREATE INDEX
maleah_db=# insert into index_t values (1,2,3,'test') ;
ERROR: duplicate key value violates unique constraint "idx_uniq_idinfo_indext"
DETAIL: Key (id)=(1) already exists.
多列索引在实际使用中还有很多局限性,这里只突出和INCLUDE索引的对比
最后修改时间:2022-12-13 12:25:47
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
