




在处理字符串相关的问题时,我们常常会在代码中遇到需要使用正则表达式的场景。正则表达式(regular expressions)就是一种字符串的匹配规则(也称为模式,pattern),可以帮助我们从输入文本中提取需要的字符序列。
网上的很多教程都是直接罗列出几十条常用的表达式让你去查,但每个人的需求场景不同,如果不理解那些元字符的含义和匹配规则,一个个去试的话,反而更加低效。其实,正则表达式中常用的组件并不多,很快就能掌握,而且也足以应对大部分的应用场景。
常用组件
学习正则表达式时首先需要理解一些特殊的元字符,它们是用来构建正则表达式的组件,可以表示单个字符、字符集合、字符范围、字符位置顺序、字符间的选择等。
1. 匹配字母、数字、空白字符
这三类都区分大小写,且大小写形式的意义相近,很适合放在一起记忆。
字母数字元字符 \w:匹配任何一个字母或数字或下划线。 W:匹配任何一个非字母、数字、下划线型字符(如标点符号)。 数字元字符 \d:匹配任何一个数字字符。 \D:匹配任何一个非数字字符。 空白元字符 \s:匹配任何一个空白字符。常见的空白符的形式有空格 (␣)、制表符 (\t)、换行 (\n) 和回车 (\r) ,\s都可以匹配。 \S:匹配任何一个非空白字符。
2. 通配符(wildcard)
由元字符.
来表示,可以匹配任意单个字符(包括字母、数字、空格等,但是不匹配换行符)。如果想要专门匹配句点.
,则需要在前面加一个斜杠来转义:\.
。
3. 指定匹配次数
以上两条都只能匹配单个字符,如果想要匹配多次呢?比如匹配四个数字,输入\d\d\d\d
虽然也可以,但表达式就会显得很长,而且如果重复上千次时就太麻烦了,这时就可以指定匹配的重复次数:
+:重复1次或多次;e.g. \d+
匹配至少一个数字。?:匹配0次或1次;e.g. \w?
最多匹配一个字母。*:匹配0次或多次;e.g. \s*
匹配任意多个空格。{n}:匹配n次;e.g. \d{3}
匹配3个数字。{n,}:匹配至少n次;e.g. \d{3,}
至少匹配3个数字。{n,m}:匹配n到m此;e.g. \d{3,5}
至少匹配3个数字,最多匹配5个数字。
4. 描述位置^$
^:匹配字符的开头 $:匹配字符的结尾
^
和$
不存在作用范围,将它们想象成一种地标,^
在哪里,哪里就是字符串的开头,$
在哪里,哪里就是字符串的结尾。
5. 使用中括号[]
匹配特定范围的字符
如果我们需要匹配的数字只有0-6,而不包括7-9,这时就可以用中括号结合破折号[0-6]
来指定匹配的字符范围。一对中括号中还可以指定多种字符范围,比如[A-Za-z0-9_]
,就相当于\w
。
使用中括号有几个需要注意的地方:
中括号相当于一个集合,里面的元素之间存在“或”的关系, [abc]
只能匹配a或b或c;^
在中括号中表示“非”,不表示字符串的开头。如果需要表示字符串的开头,需要放在中括号之外。
6. 使用小括号()匹配子串
有时候,我们不仅需要匹配字符串,还想从中提取部分对我们有用的信息,这时可以使用小括号()将需要返回的子串括起来,子串也称为捕获组。
一个正则表达式中可以包含多个小括号,比如当我们想要返回多个子串信息时,可以嵌套小括号来使用,这也成为嵌套组。
举个🌰:
存在一类文件:文件名以file_开头,下划线之后是文件的三位数字编号,文件后缀为.pdf。
file_123.pdf
file_234.pdf
当我们想要返回该类文件的文件名但不包含后缀,如何定义正则表达式?
————————————————————————————
^(file_\d{3})\.pdf$
当我们想要返回该类文件的文件名但不包含后缀,并且同时获得文件的编号时,如何定义正则表达式?
————————————————————————————
^(file_(\d{3}))\.pdf$
7. 使用逻辑或条件|
上文中我们提到中括号[]
中是单个字符的或关系,如果我们想表示不同字符集之间的或关系,该如何表示呢?比如想买牛奶或面包,这时就可以使用|
搭配小括号()
使用:I want to buy (milk|bread)
.注意,这里的()
不是用于返回子串,而是用来限定|
的作用范围。
练习工具
推荐一个非常实用的学习正则表达式的网站,英文版和中文版都有,而且每一章节最后都有一个小练习帮助加深理解,预计一小时就能学习通关。本文中的代码和举例大部分来自该英文网站。
英文版地址:https://regexone.com/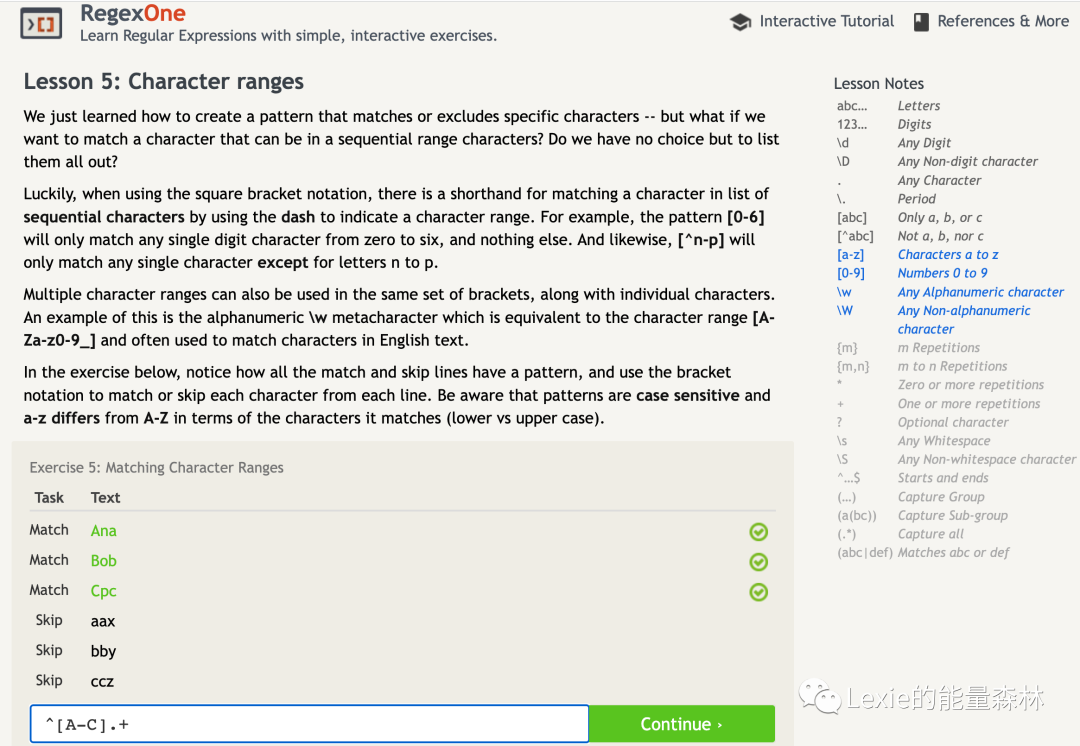
中文版地址:https://imageslr.github.io/regexone-cn/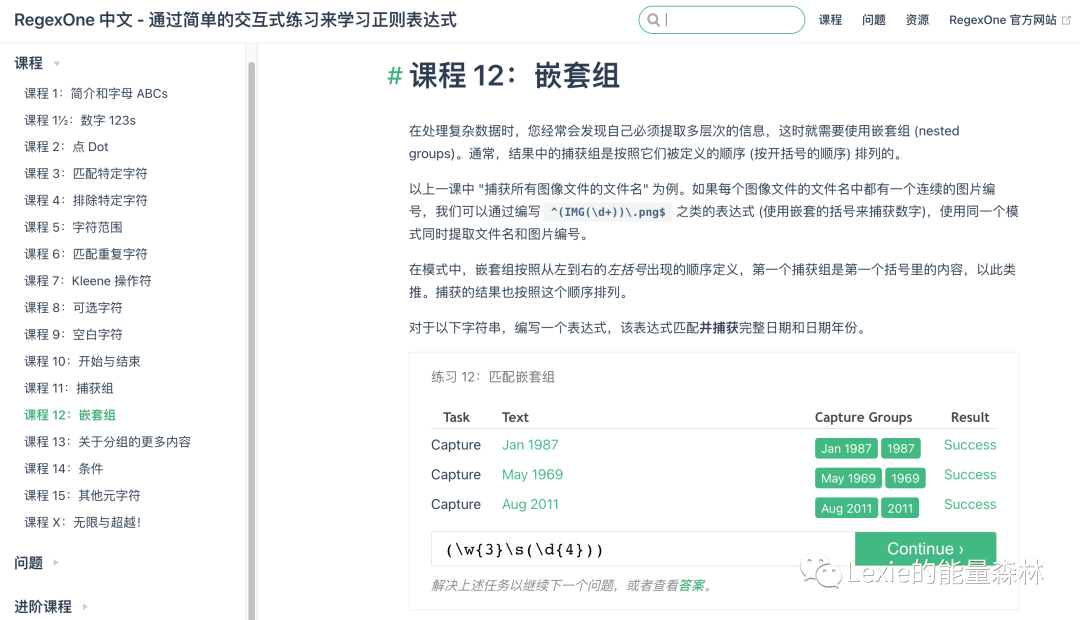
python中使用正则表达式
在python中使用正则表达式时,需要先引入re模块,配合re中的函数使用。
一般使用正则表达式有几个使用场景:匹配一次提取子串、查找和替换字符串中的匹配项、提取多个子串。
01 匹配一次提取子串
一般使用re模块中的match和search函数。
re.match(匹配模式pattern,待匹配字符串input_str,标志位flags)
:从字符串起始位置开始匹配,成功返回匹配的对象,不成功返回None。re.search(匹配模式pattern,待匹配字符串input_str,标志位flags)
:扫描整个字符串并返回第一个成功的匹配对象,不成功返回None。
其中,可选参数flags是用来指定正则表达式中的修饰符的,比如是否区分大小写、多行匹配等。由于re.match函数是从字符串开头开始匹配,如果要匹配的内容不在开头,则匹配失败。
设定一个应用场景:
“匹配"June 24"形式的日期,并分别返回月份和天。
import re
#定义正则表达式
#r表示原生字符串,使用r时表达式中表示\就不需要在前面再加一个转义字符\
regex = r"([a-zA-Z]+) (\d+)"
if re.search(regex, "Today is June 24"):
match = re.search(regex, "June 24")
#返回匹配子串的起始和结束位置
print("Match at index %s, %s" % (match.start(), match.end()))
#返回子串时可以结合group()函数使用
# group(0)返回全部字符串
print("Full match: %s" % (match.group(0)))
# group(1)返回第1个捕获组
print("Month: %s" % (match.group(1)))
# group(2)返回第2个捕获组
print("Day: %s" % (match.group(2)))
02 查找和替换字符串中的匹配项
用到re.sub函数:
re.sub(匹配模式pattern, 替换子串或函数repl, 待匹配字符串input_str, 替换次数count=0, 标志位flags=0)
:可选参数count=0则默认全部替换。
通过替换还可以实现删除特定字符串和重排序的功能。
设定应用场景:
“给定一系列“June 24”形式的日期,并将日期形式改成“24 of June”
import re
regex = r"([a-zA-Z]+) (\d+)"
print(re.sub(regex, r"\2 of \1", "June 24, August 9, Dec 12"))
03 提取多个子串
re.search()函数只能返回第一个成功的匹配,而re.findall()则能实现全局的搜索。
re.findall(匹配模式pattern, 待匹配字符串input_str, 标志位flags=0)
:返回符合匹配的子串列表。re.finditer(匹配模式pattern, 待匹配字符串input_str, 标志位flags=0)
:将所有匹配子串作为迭代器返回。
import re
regex = r"[a-zA-Z]+ \d+"
matchList = re.findall(regex, "June 24, August 9, Dec 12")
for match in matchList:
print("Full match: %s" % (match))
#使用finditer
matchList = re.finditer(regex, "June 24, August 9, Dec 12")
for match in matchList:
print("Match at index: %s, %s" % (match.start(), match.end()))
使用re.compile函数
正则表达式还有另一种使用形式——将正则表达式编译为正则表达式对象,方便后续调用及提高效率,可以配合match、findall等函数使用。
re.compile(正则表达式pattern, 标志位flags)
import re
regex = r"([a-zA-Z]+) (\d+)"
pattern = re.compile(regex)
input_str = "June 24, August 9, Dec 12"
match = pattern.match(input_str) #从起始位置开始匹配
matchList = pattern.findall(input_str, pos=1, endpos=17) #指定匹配的开始和结束位置
