




As a cloud-native distributed storage system, JuiceFS was designed into a plug-in structure at the beginning of its birth to ensure that new technologies can be continuously integrated into the JuiceFS ecosystem. According to your needs, you can flexibly choose two core components, the data storage engine and the metadata engine.
The data storage engine is mainly object storage. It supports almost all public and private cloud object storage services, as well as KV storage, WebDAV, and local disks. The metadata engine supports databases such as Redis, MySQL, PostgreSQL, and SQLite.
The newly released JuiceFS v0.16 officially supports TiKV, a distributed key-value database, which further meets the requirements for elastic scaling in high-performance, large-scale data storage.
In this article, I’ll share with you how to use JuiceFS and select TiKV as a metadata engine.
TiKV, a highly scalable KV database
TiKV is a distributed transactional key-value database featuring high scalability, low latency, and ease of use. It easily processes over a trillion rows of data in petabytes.
TiKV supports unlimited horizontal scaling and provides a distributed transaction interface that meets ACID compliance. It also ensures data consistency and high availability of multiple replicas using the Raft protocol.
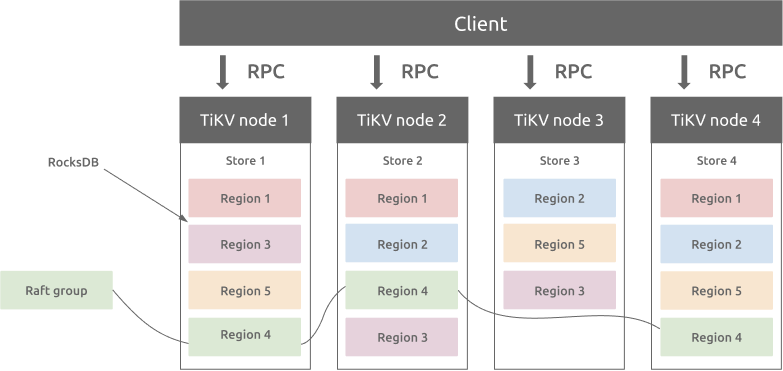
TiKV was developed by PingCAP and is a graduated project of the Cloud Native Computing Foundation (CNCF).
For JuiceFS, the support for TiKV as a metadata engine is a milestone. As a new choice for JuiceFS users, TiKV provides easier horizontal scaling than Redis and better performance than MySQL and PostgreSQL.
