




看看两个声称拥有 Kubernetes 原生标签的数据库:TiDB 和 DataStax Astra DB。
云计算革命激发并受益于多种相互关联的趋势。自助服务、公共云基础设施的可用性帮助推动了微服务架构和 DevOps 实践的采用,包括自动化和可观察性。
容器化和容器编排的推动导致 Kubernetes 被广泛采用作为管理云原生应用程序的环境。
但这场革命中的一个滞后领域是数据和数据基础设施。长期以来,数据一直存在于 Kubernetes 之外,这导致开发人员在部署云原生应用程序时需要付出很多额外的努力和复杂性。
在 Kubernetes 的早期,一个经常重复的公理是它还没有为有状态的工作负载做好准备。值得庆幸的是,一个重大转变已经悄然发生,事实上已经达到了成熟点。
转型起初进展缓慢,首先是努力将现有数据库容器化。这在运行在单个计算节点上的小型数据库或在云原生世界中设计的数据库(如 Apache Cassandra 和 DynamoDB)的情况下效果相对较好,但挑战仍然存在。
在过去的两三年里,新一代的数据库出现了。这些“Kubernetes 原生”数据库是为在这个开源编排系统上运行而设计的。
在这里,我们将定义使数据库成为 Kubernetes 原生数据库的品质,以及采用 Kubernetes 原生数据库所带来的好处。为此,我们将研究两个声称拥有 Kubernetes 原生标签的数据库:TiDB 和 DataStax Astra DB。
DataStax 是一家实时数据公司,在统一堆栈中提供 Apache Cassandra®(世界上最具扩展性的数据库)的强大功能,并在任何云上提供先进的 Apache Pulsar™ 流技术。
Kubernetes Native MySQL 与 TiDB
首先,我们来看一个强调关系的数据库:TiDB(Titanium Database 的简称)。TiDB 是 PingCAP 构建的一个开源系统,它提供了一个兼容 MySQL 的数据库以及一个支持混合事务和分析处理(简称 HTAP)的列式数据库。
如下图 1 所示,TiDB 采用微服务设计,TiDB 查询层、TiKV MySQL 数据库、TiFlash 列式数据库、Spark 节点和元数据管理都作为可扩展的微服务部署在各自的集群中。这种设计将计算密集型工作与存储密集型工作分开,因为查询层和数据库层是独立可扩展的。
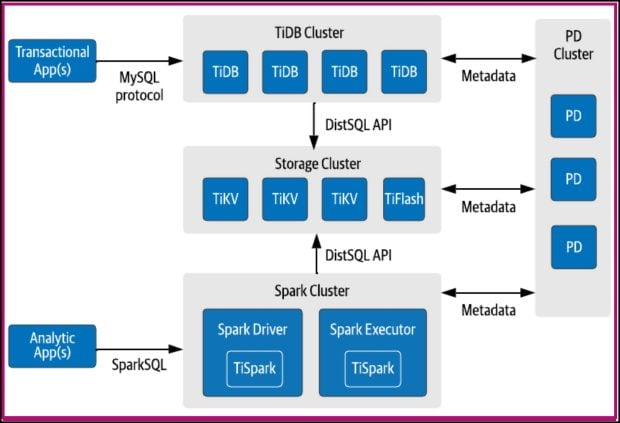
图 1:TiDB 架构(来源:PingCAP官方文档)
TiDB 创建者做出的一项重要承诺是该数据库仅在 Kubernetes 上运行。这足以让它成为 Kubernetes 原生的吗?让我们再深入一点。首先,TiDB 由 Kubernetes 操作员使用自定义资源(CRD) 进行部署和管理。TiDB CRD 包括 TiDBCluster,它使您能够指定每个微服务的扩展和配置,以及数据库层组件如何通过 Kubernetes 持久卷使用存储。额外的 CRD 用于部署监控工具和管理备份和恢复等操作任务。
TiDB 还有一个可选的调度器扩展,它与默认的 K8s 调度器交互,以做出更多应用程序感知的调度决策。强调在可用的情况下使用现有的 Kubernetes 功能是 Kubernetes 原生数据库的标志。
Kubernetes Native Cassandra 与 DataStax Astra DB
现在让我们看看另一个 Kubernetes 原生数据库,并注意一些相似点和不同点。Cassandra是一个高度可扩展的 NoSQL 数据库,是最早声称是云原生的数据库之一,但是在 Kubernetes 中部署 Cassandra 是什么样子的呢?DataStax Astra DB是已纳入微服务的 Cassandra 版本,如图 2 所示。
与 TiDB 类似,数据库包括与查询处理和数据存储有关的微服务,以及身份和访问控制、数据修复和备份/恢复的服务。数据服务在使用存储方面特别有趣,Kubernetes Persistent Volumes 仅用于缓存,对象存储用于长期持久化。将压缩分离到它自己的服务中可以使这种计算密集型处理在后台发生,而不会影响为读写流量提供服务的数据服务的性能。
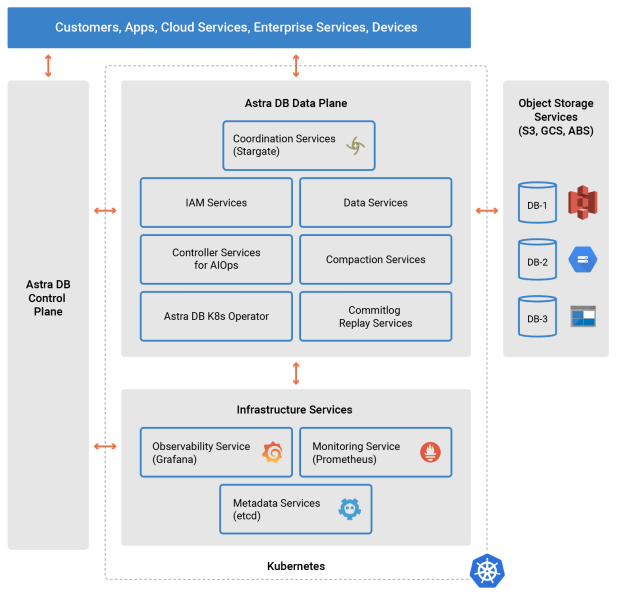
图 2:DataStax Astra DB 架构(来源:DataStax 白皮书)
Astra DB 作为托管服务在多个云区域提供。每个区域包含一个由上述服务组成的数据平面,由 Kubernetes 操作员管理,以及基础设施服务,包括用于可观察性的Kube- Promethus堆栈和用于元数据管理的 etcd。数据平面由可以在一个或多个云中运行的控制平面管理,以执行诸如管理客户帐户和数据库以及在新区域中配置 Kubernetes 集群等任务。
Astra DB 的一个新颖之处在于它的多租户架构,其中多个用户数据库可以共享相同的微服务和支持基础设施,从而降低小规模用户的单位经济效益。随着用户应用程序的增长,他们可以选择转移到专用资源以大规模实现最佳性能,所有这些都是在“现收现付”的基础上进行的。
Kubernetes 原生数据库原理
基于我们对 TiDB 和 Astra DB 的观察,我们可以得出一些关于什么使数据库成为 Kubernetes 原生的想法。其中许多对应于云原生数据的原则列表,我在之前的文章中对此进行了描述:
- 可组合的微服务架构:首先,一个被分解成微服务的数据库使每个服务都可以独立扩展。对于真正的无服务器解决方案,某些类型的计算密集型处理甚至可以扩展为零,尤其是与多租户设计结合使用时。
- 将计算、网络和存储视为商品:由 Kubernetes 原生数据库组成的微服务应最大限度地利用 Kubernetes API 来管理云原生应用程序的基本资源:计算资源,例如用于管理工作负载的 StatefulSet 和部署,用于存储的 Persistent Volume 子系统、Kubernetes 入口和服务,用于公开对数据的网络访问等。这包括利用 Kubernetes 中已有的功能(例如用于元数据管理的 etcd),而不是引入具有重复功能的组件。
- 利用 Kubernetes 最佳实践:遵循 Kubernetes 应用程序的通用模式将产生多种操作优势,例如,公开每个微服务的活跃性和就绪性检查以帮助可用性,并通过 Prometheus PromQL API 公开指标以实现可观察性。默认情况下,Kubernetes 本身树立了一个很好的例子,数据库应该遵循如何确保安全:使用 Kubernetes Secrets 分发安全凭证,仅在需要时公开端口等等。
- 通过操作符进行声明式管理: Kubernetes 原生数据库应该体现 Kubernetes 通过操作符和自定义资源进行声明式管理的原则,而不是依赖于遗留的数据库管理 UI 和 CLI。必要时,可以使用 Kubernetes 扩展点(例如调度程序扩展)来添加特定于应用程序的行为。目标是将数据平面功能(管理数据)与控制平面功能(管理数据库)完全分离。
忠实地采用这些原则的数据库和其他数据基础设施将带来好处,包括在所有规模上以最佳成本实现高性能、降低操作复杂性从而加快上市时间以及满足当今高可用性和安全性需求的符合标准的解决方案。
Kubernetes 原生数据基础设施的未来
仍有许多进步需要取得,而且不仅仅局限于数据库。Kubernetes 原生原则可以应用于其他类型的数据基础设施,包括流媒体、分析和机器学习。
Kubernetes 原生解决方案将继续在多集群和多云部署方面取得长足进步,以便在全球范围内扩展,并将采用多租户和无服务器原则来更好地优化成本。Kubernetes 本身在为 StatefulSets 增加更多灵活性和支持多集群联邦方面还有改进的空间。
持续进步的关键是开放式协作。Data on Kubernetes Community是一个高度活跃的数据极客群体,汇集了数据密集型应用程序的构建者和支持它们的基础设施。
加入我们讨论想法,例如开发可以管理多个数据库的可重用运算符或为备份/恢复和数据加载等概念定义一组通用的 CRD。为了所有人的利益,我们将一起继续推动云计算的发展。
本文基于Jeff Carpenter 和 Patrick McFadin合着的 O'Reilly 著作“ Managing Cloud Native Data on Kubernetes ”中的第 7 章“Kubernetes Native Database”。
原文标题:Simplify Database Geo-Redundancy Backup With Cloud Storage Services
原文作者:Jeff Carpenter、Patrick McFadin
原文链接:https://thenewstack.io/the-rise-of-the-kubernetes-native-database/
