




【导读:数据是二十一世纪的石油,蕴含巨大价值,这是·情报通·大数据技术系列第[36]篇文章,欢迎阅读和收藏】
1 基本概念
传统的关系型数据库( RDBMS )在解决大数据问题时成本更高,故针对 PB 甚至 EB 级的数据能在合理时间内处理更适合的技术是 NoSQL (非关系型数据库)。
HBase 是一个开源的基于列的非关系型分布式数据库,具有高可靠性、高性能、列存储、可伸缩,实现对大型数据的实时、随机的读写访问。它是 Apache 的 Hadoop 的一个子项目,通过 JAVA 语言实现,参考了谷歌的 BigTable 进行建模,利用 Hadoop HDFS 作为其文件存储系统。
HBase 之所以能够迈向成熟,主要是由于:
1 、核心思想来源于 Google 的 BigTable ;
2 、有 Apache 及 Hadoop 开源社区的支撑;
3 、有 Facebook 、淘宝和支付宝等互联网公司的应用实践,当前已经有很多公司都在使用。
HBase 在 Hadoop 的所处位置:
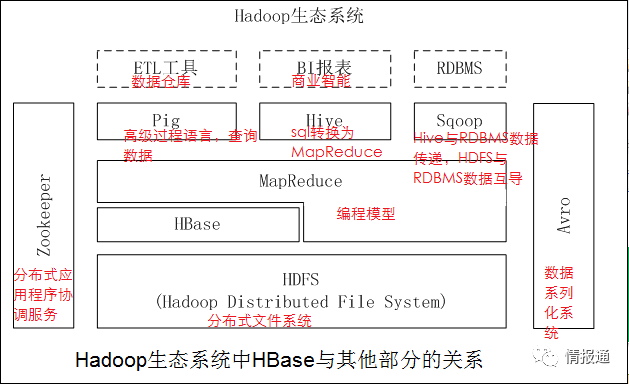
2 术语解释
RDBMS :关系型数据库管理系统 Relational Database Management System 的缩写。
PB :Petabyte ,中文名叫拍字节,等于 2 的 50 次方字节, 1PB=1024TB 。
EB :Exabyte ,中文名叫艾字节, 64 位计算机系统的可用最大的虚拟内存空间是 1EB , 1EB=1024PB 。
NoSQL :非关系型数据库系统 Not-Only-SQL 。
ETL : 数据仓库技术 Extract-Transform-Load 。用来描述将数据从来源端经过抽取( extract )、交互转换( transform )、加载( load )至目的端的过程。
BI :Business Intelligence 商业智能。是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确地提供报表并提出决策依据,帮助企业做出明智的业务经营决策。
Pig :是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。
Hive :基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
Sqoop : ( 发音:skup) 是一款开源的工具,主要用于在 Hadoop(Hive) 与传统的数据库 (mysql 、 postgresql...) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL 、 Oracle 、 Postgres 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
Avro :数据序列化的系统。
Zookeeper :开放源码的分布式应用程序协调服务。
HDFS :Hadoop 分布式文件系统 Hadoop Distributed File System 。
MapReduce :一种编程模型,用于大规模数据集(大于 1TB )的并行运算。指定一个 Map (映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce (归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Ambari :是一种基于 Web 的工具,支持 Apache Hadoop 集群的供应、管理和监控。
HCatalog :是 apache 开源的对于表和底层数据管理统一服务平台。
3 关系型数据库存在的问题
随着数据的不断增多,传统的关系型数据库存在如下问题:
1 、适合存储有限的数据量,但单台机器无法负载大量数据,无法应对在数据规模剧增时导致的系统扩展性和性能问题(分库分表也不能很好解决);
2 、在数据结构变化时一般需要停机维护;
3 、空列浪费存储空间。
由于缺乏划算的方式来存储所有信息,很多公司会忽略某些数据源,将收集到的数据删减后保存,只保存最近 N 天的数据,这种方式无法存储几个月或几年的所有数据。随着业界越来越认同数据资产价值的重要性,所以希望能改进算法或数据模型实现对海量数据的存储和处理。
Hadoop 的 HDFS 和 MapReduce 这两个模块擅长存储任意的、半结构化甚至是非结构化的数据,可以帮助用户在分析数据的时候决定如何解释这些数据,允许用户随时更改数据分类的方式,一旦用户更新了算法只需要重新分析数据,给用户提供了数据存储的无限空间,但这两种方式只能执行批量处理,并且只以顺序方式访问数据。这意味着即使是最简单的搜索工作也必须搜索整个数据集,无法访问数据中的任何点(随机访问)单元。而 HBase 就能很好的解决这类问题,它是存储大量数据并和以随机方式访问数据的数据库。
4 结构化、半结构化和非结构化
HBase 主要用来存储结构化和半结构化的松散数据, 与 Hadoop 一样, HBase 目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
结构化: 数据结构字段含义确定,清晰,具有固定的结构,属性划分,以及类型等信息。关系型数据库中所存储的数据信息,大多是结构化数据, 如职工信息表,拥有 ID 、 Name 、 Phone 、 Address 等属性信息。通常直接存放在数据库表中。数据记录的每一个属性对应数据表的一个字段。
非结构化: 无法用统一的结构来表示,杂乱无章的数据,很难按照一个概念去进行抽取,无规律性。如文本文件、图像、视频、声音、网页等信息。数据记录较小时 ( 如 KB 级别 ) ,可考虑直接存放到数据库表中(整条记录映射到某一个列中),这样也有利于整条记录的快速检索。数据较大时,通常考虑直接存放在文件系统中。数据库可用来存放相关数据的索引信息。
半结构化: 具有一定结构,但语义不够确定,有一定的灵活可变性。典型的如 HTML 网页,有些字段是确定的 (title) , 有些不确定 (table) ;可以考虑直接转换成结构化数据进行存储。根据数据记录的大小和特点,选择合适的存储方式。这一点与非结构化数据的存储类似。
5 HBase 与关系型数据库的区别
主要区别如下:
对比项 | 关系型数据库 | HBase |
数据类型 | 采用关系模型,具有丰富的数据类型和存储方式 | 采用了更加简单的数据模型,它把数据存储为未经解释的字符串 |
数据操作 | 包含了丰富的操作,其中会涉及复杂的多表连接 | 不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为 HBase 在设计上就避免了复杂的表和表之间的关系 |
存储模式 | 基于行模式存储的 | 基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的 |
数据索引 | 可以针对不同列构建复杂的多个索引,以提高数据访问性能 | 只有一个索引——行键 KeyValue ,通过巧妙的设计, HBase 中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来 |
数据维护 | 更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在 | 执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留 |
可伸缩性 | 很难实现横向扩展,纵向扩展的空间也比较有限 | 为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩 |
6 HBase 的特点
1 、大:一个表可以有上十亿行,上百万列;
2 、面向列:面向列 ( 族 ) 的存储和权限控制,列 ( 簇 ) 独立检索;
3 、稀疏:对于为空 (null) 的列,并不占用存储空间,因此,表可以设计的非常稀疏;
4 、无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列。
5 、强一致性读写:HBase 不是“ eventually consistent (最终一致性)”数据存储。这让它很适合高速计数聚合类任务;
6 、自动分片 (Automatic sharding) :HBase 表通过 region 分布在集群中。数据增长时, region 会自动分割并重新分布;
7 、 RegionServer 自动故障转移;
8 、 Hadoop/HDFS 集成:HBase 支持开箱即用地支持 HDFS 作为它的分布式文件系统;
9 、 MapReduce :HBase 通过 MapReduce 支持大并发处理;
10 、 Java 客户端 API :HBase 支持易于使用的 Java API 进行编程访问;
11 、 Thrift/REST API :HBase 也支持 Thrift 和 REST 作为非 Java 前端的访问;
12 、 Block Cache 和 Bloom Filter :对于大容量查询优化, HBase 支持 Block Cache 和 Bloom Filter ;
13 、运维管理:HBase 支持 JMX 提供内置网页用于运维。
7 HBase 的优缺点
优点
•列可以动态增加,并且列为空就不存储数据,节省存储空间
• Hbase 自动切分数据,使得数据存储自动具有水平扩展
• Hbase 可以提供高并发读写操作的支持
•与 Hadoop MapReduce 相结合有利于数据分析
•容错性
•版权免费
•非常灵活的模式设计(或者说没有固定模式的限制)
•可以跟 Hive 集成,使用类 SQL 查询
•自动故障转移
•客户端接口易于使用
•行级别原子性,即 PUT 操作一定是完全成功或者完全失败
• HBase 中每张表的记录数(行数)可多达几十亿条,甚至更多,每条记录可以拥有多达上百万的字段。而这样的存储能力却不需要特别的硬件,普通的服务器集群就可以胜任。
缺点
•不能支持条件查询,只支持按照 row key 来查询
•容易产生单点故障(在只使用一个 HMaster 的时候)
•不支持事务
• JOIN 不是数据库层支持的,而需要用 MapReduce
•只能在逐渐上索引和排序
•没有内置的身份和权限认证
8 HBase 使用场景
HBase 擅长于存储结构简单的海量数据但索引能力有限,而 Oracle 等传统关系型数据库 (RDBMS) 能够提供丰富的查询能力,但却疲于应对 TB 级别的海量数据存储,所以 HBase 对传统的 RDBMS 并不是取代关系,而是一种补充。
Ø 存储大量的数据( >TB )
Ø 需要很高的写吞吐量
Ø 大规模数据集很好性能的随机访问(按列)
Ø 需要进行优雅的数据扩展
Ø 结构化和半结构化的数据
Ø 不需要全部的关系数据库特性,例如交叉列,交叉表,事务,连接等等。
Ø 增量数据存储
Ø 增量用户社交交互数据
Ø 搜索引擎应用
Ø 有足够的硬件,少于 5 节点 Hadoop 时,基本体现不出优势
9 HBase 与 BigTable 的区别
HBase 虽然是参考 BigTable 的,但还是有不少区别的,主要区别如下:
对比项 | HBase | BigTable |
数据存储 | HDFS | Google GFS |
数据计算 | MapReduce | Google MapReduce |
服务协调 | ZooKeeper | Google Chubby |
