




介绍
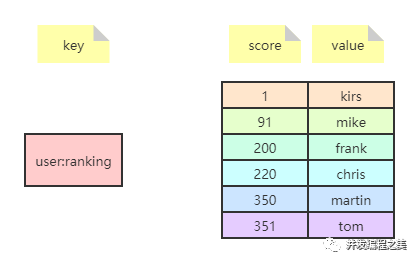
有序集合类型(sorted set)是在集合类型的基础上为集合中的每个元素都关联了一个分数,这使得不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能够获得分数最高或最低的前N个元素、获得指定分数范围内的元素等与分数有关的操作。虽然集合中每个元素都是不同的,但是它们的分数可以相同。
一、有序集合特点
特点:
有序
无重复
element + score
二、应用场景
场景一:排行榜
zadd数据添加
zincrby执行分数的更新
zrem删除榜外
zrangebyscore获取一定范围的榜单
新书,新歌榜单可以使用时间戳
点赞数,关注量可以作为分值实现不同的排行榜
场景二:地理位置应用
三、底层数据结构
127.0.0.1:6379> type k1zset127.0.0.1:6379> object help1) OBJECT <subcommand> arg arg ... arg. Subcommands are:2) ENCODING <key> -- Return the kind of internal representation used in order to store the value associated with a key.3) FREQ <key> -- Return the access frequency index of the key. The returned integer is proportional to the logarithm of the recent access frequency of the key.4) IDLETIME <key> -- Return the idle time of the key, that is the approximated number of seconds elapsed since the last access to the key.5) REFCOUNT <key> -- Return the number of references of the value associated with the specified key.127.0.0.1:6379> object encoding k1"ziplist"127.0.0.1:6379> zadd k1 99 sgasfdfasdfasdfasgagkdsjgfasyhgang;lksdhgkdrhgklajsdglkjalghalsngasdjgkljhadlfngfjkhlfdhgkjsdangasmghsgkdnslgfhqksegtabgksbdfgahndsbgnlashtgbnsdfkjgbaksjbgkajsdbgasbngkbaskgbasdbngkjbfasgnflkbnkfjdshgkjasbndgknfvnflmbnlfkdsngkjqgyhakdjsbgnvlafjgjkalshbglsabn(integer) 1127.0.0.1:6379> object encoding k1"skiplist"127.0.0.1:6379>
type:看key的类型
object
encoding:可以看value底层具体使用的数据结构
ziplist:正常元素的编码数据结构是ziplist
skiplist:元素的内容字节数比较大会变成skiplist
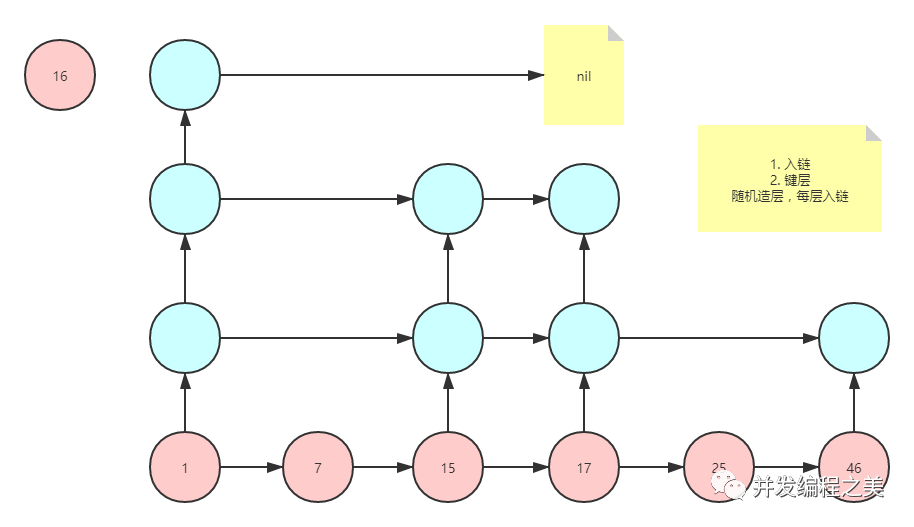
场景:使用跳表动态排序
源码:造层
int zslRandomLevel(void) {int level = 1;while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}
查看最高层数
[root@common src]# grep ZSKIPLIST_MAXLEVEL ./*./defrag.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x, *newx;grep: ./modules: 是一个目录./server.h:#define ZSKIPLIST_MAXLEVEL 64 * Should be enough for 2^64 elements */./t_zset.c: zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);./t_zset.c: for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {./t_zset.c: * The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL./t_zset.c: return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;./t_zset.c: unsigned int rank[ZSKIPLIST_MAXLEVEL];./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;./t_zset.c: zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;[root@common src]#
可以看到最高层是64层
四、命令拾遗
127.0.0.1:6379> help @sorted_setBZPOPMAX key [key ...] timeoutsummary: Remove and return the member with the highest score from one or more sorted sets, or block until one is availablesince: 5.0.0BZPOPMIN key [key ...] timeoutsummary: Remove and return the member with the lowest score from one or more sorted sets, or block until one is availablesince: 5.0.0ZADD key [NX|XX] [CH] [INCR] score member [score member ...]summary: Add one or more members to a sorted set, or update its score if it already existssince: 1.2.0ZCARD keysummary: Get the number of members in a sorted setsince: 1.2.0ZCOUNT key min maxsummary: Count the members in a sorted set with scores within the given valuessince: 2.0.0ZINCRBY key increment membersummary: Increment the score of a member in a sorted setsince: 1.2.0ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]summary: Intersect multiple sorted sets and store the resulting sorted set in a new keysince: 2.0.0ZLEXCOUNT key min maxsummary: Count the number of members in a sorted set between a given lexicographical rangesince: 2.8.9ZPOPMAX key [count]summary: Remove and return members with the highest scores in a sorted setsince: 5.0.0ZPOPMIN key [count]summary: Remove and return members with the lowest scores in a sorted setsince: 5.0.0ZRANGE key start stop [WITHSCORES]summary: Return a range of members in a sorted set, by indexsince: 1.2.0ZRANGEBYLEX key min max [LIMIT offset count]summary: Return a range of members in a sorted set, by lexicographical rangesince: 2.8.9ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]summary: Return a range of members in a sorted set, by scoresince: 1.0.5ZRANK key membersummary: Determine the index of a member in a sorted setsince: 2.0.0ZREM key member [member ...]summary: Remove one or more members from a sorted setsince: 1.2.0ZREMRANGEBYLEX key min maxsummary: Remove all members in a sorted set between the given lexicographical rangesince: 2.8.9ZREMRANGEBYRANK key start stopsummary: Remove all members in a sorted set within the given indexessince: 2.0.0ZREMRANGEBYSCORE key min maxsummary: Remove all members in a sorted set within the given scoressince: 1.2.0ZREVRANGE key start stop [WITHSCORES]summary: Return a range of members in a sorted set, by index, with scores ordered from high to lowsince: 1.2.0ZREVRANGEBYLEX key max min [LIMIT offset count]summary: Return a range of members in a sorted set, by lexicographical range, ordered from higher to lower strings.since: 2.8.9ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]summary: Return a range of members in a sorted set, by score, with scores ordered from high to lowsince: 2.2.0ZREVRANK key membersummary: Determine the index of a member in a sorted set, with scores ordered from high to lowsince: 2.0.0ZSCAN key cursor [MATCH pattern] [COUNT count]summary: Incrementally iterate sorted sets elements and associated scoressince: 2.8.0ZSCORE key membersummary: Get the score associated with the given member in a sorted setsince: 1.2.0ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]summary: Add multiple sorted sets and store the resulting sorted set in a new keysince: 2.0.0127.0.0.1:6379>
命令演示
1. ZADD(增加元素)o(n)
ZADD命令用来向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。ZADD命令的返回值是新加入到集合中的元素个数(不包含之前已经存在的元素)。
127.0.0.1:6379> zadd k1 89 TOM 79 DOG 99 CAT(integer)3127.0.0.1:6379> zadd k2 1.5 a(integer)1127.0.0.1:6379> zadd k2 +inf b(integer)1127.0.0.1:6379> zadd k2 -inf c(integer)1
其中+inf和-inf分别表示正无穷和负无穷。
2. ZSCORE(获得元素的分数)o(1)
127.0.0.1:6379> zscore k1 TOM"89"
3. ZRANGE(获得排名在某个范围的元素列表)o(log(n)+m)
ZRANGE命令会按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素,索引从0开始,负数代表从后向前查找,-1表示最后一个元素。
127.0.0.1:6379> zrange k1 0 21)"DOG"2)"TOM"3)"CAT"127.0.0.1:6379> zrange k1 1 -11)"TOM"2)"CAT"
如果需要同时获得元素的分数的话可以在ZRANGE命令的尾部加上WITHSCORES参数:
127.0.0.1:6379> zrange k1 0 -1 withscores1)"DOG"2)"79"3)"TOM"4)"89"5)"CAT"6)"99"
ZRANGE命令的时间复杂度为0(logn+m)(其中n为有序集合的基数,m为返回的元素个)。如果两个元素的分数相同,Redis会按照字典顺序(即"0"<"9"<"A"<"Z"<"a"<"z")来进行排列。中文取决于编码方式,依然按照字典顺序排列这些元素。
ZREVRANGE命令和ZRANGE的唯一不同在于ZREVRANGE命令是按照元素分数从大到小的顺序给出结果的。
4. ZRANGEBYSCORE(获得指定分数范围的元素)o(log(n)+m)
令按照元素分数从小到大的 顺序返回分数在min和max之间(包含min和max)的元素:
127.0.0.1:6379> zrangebyscore k1 80 1001)"TOM"2)"CAT"
如果希望分数范围不包含端点值,可以在分数前加上“(”符号。例如,希望返回89分到100分的数据,不包含89分,包含100分:
127.0.0.1:6379> zrangebyscore k1 (80 100 withscores1)"CAT"2)"99"
ZREVRANGEBYSCORE命令不仅是按照元素分数从大往小的顺序给出结果的,而且它的min 和max参数的顺序和ZRANGEBYSCORE命令是相反的。从第二个人开始的前3个[80-100]的人
127.0.0.1:6379> zrevrangebyscore k1 100 80 limit 1 31)"CAT"
5. ZINCRBY(增加某个元素的分数)o(1)
127.0.0.1:6379> zincrby k1 6 DOG1)"85"127.0.0.1:6379> zincrby k1 -5 DOG1)"81"
如果指定的元素不存在,Redis在执行命令前会先建立它并将它的分数赋为0再执行操作。
6. ZCARD(获得集合中元素的数量)o(1)
127.0.0.1:6379> zcard k1(integer)3
redis内部会进行优化,计算每个有序集合的元素个数,所以时间复杂度是o(1)。
7. ZCOUNT(获得指定分数范围内的元素个数)o(log(n)+m)
127.0.0.1:6379> zcount k1 85 100(integer)2127.0.0.1:6379> zcount k1 90 +inf(integer)1
8. ZREM(删除一个或多个元素)o(1)
127.0.0.1:6379> zrem k1 DOG(integer)1127.0.0.1:6379> zcard k1(integer)2
ZREM命令的返回值是成功删除的元素数量(不包含本来就不存在的元素)。
9. ZREMRANGEBYRANK(按照排名范围删除元素)o(log(n)+m)
ZREMRANGEBYRANK命令按照元素分数从小到大的顺序(即索引0表示最小的值)删除处在指定排名范围内的所有元素,并返回删除的元素数量。
127.0.0.1:6379> zadd k3 1 a 2 b 3 c 4 d 5 e 6 f(integer)6127.0.0.1:6379> zremrangebyrank k3 0 2(integer)3127.0.0.1:6379> zrange k3 0 -11)"d"2)"e"3)"f"
10. ZREMRANGEBYSCORE(按照分数范围删除元素)o(log(n)+m)
ZREMRANGEBYSCORE命令会删除指定分数范围内的所有元素,返回值是删除的元素数量。
127.0.0.1:6379> zremrangebyscore k3 (4 5(integer)1127.0.0.1:6379> zrange k3 0 -11)"d"2)"f"
11. ZRANK(获得元素排名)
ZRANK命令会按照元素分数从小到大的顺序获得指定的元素的排名从0开始,即分数最小的排名为0。
127.0.0.1:6379> zrank k1 DOM(integer)0127.0.0.1:6379> zrank k1 TOM(integer)1
ZREVRANK命令则相反,分数最大的元素排名为0。
127.0.0.1:6379> zrevrank k1 DOM(integer)2127.0.0.1:6379> zrevrank k1 TOM(integer)1
12. ZINTERSTORE(计算有序集合的交集)
ZINTERSTORE命令用来计算多个有序集合的交集并将结果存储在destination键中,返回值为destination键中的元素个数。destination键中元素的分数是由AGGREGATE参数决定的。
当AGGREGATE是SUM时(也就是默认值),destination键中元素的分数是每个参与计算的集合中该元素分数的和
127.0.0.1:6379> zadd kset1 1 a 2 b(integer)2127.0.0.1:6379> zadd kset2 10 a 20 b(integer)2127.0.0.1:6379> zinterstore res 2 kset1 kset2(integer)2127.0.0.1:6379> zrange res 0 -1 withscores1)"a"2)"11"3)"b"4)"22"当AGGREGATE是MIN时,destination键中元素的分数是每个参与计算的集合中该元 素分数的最小值
127.0.0.1:6379> zinterstore res 2 kset1 kset2 aggregate min(integer)2127.0.0.1:6379> zrange res 0 -1 withscores1)"a"2)"1"3)"b"4)"2"当AGGREGATE是MAX时,destination键中元素的分数是每个参与计算的集合中该元 素分数的最大值
127.0.0.1:6379> zinterstore res 2 kset1 kset2 aggregate max(integer)2127.0.0.1:6379> zrange res 0 -1 withscores1)"a"2)"10"3)"b"4)"20"
ZINTERSTORE命令还能够通过WEIGHTS参数设置每个集合的权重,每个集合在参与计算时元素的分数会被乘上该集合的权重。ZUNIONSTORE的作用是计算集合间的并集。
127.0.0.1:6379> zinterstore res 2 kset1 kset2 weights 1 0.1(integer)2127.0.0.1:6379> zrange res 0 -1 withscores1)"a"2)"2"3)"b"4)"4"
有序集合常见的使用场景是大数据排序,如排行榜,所以很少会需要获得键中的全部数据。同样Redis认为开发者在做完交集、并集运算后不需要直接获得全部结果,而是会希望将结果存入新的键中以便后续处理。这解释了为什么有序集合只有ZINTERSTORE和ZUNIONSTORE命令而没有ZINTER和ZUNION命令。接下来我们看下如何直接获取排序后的全部结果。
五、Redis排序
有序集合
集合类型提供了强大的集合操作命令,但是如果需要排序就要用到有序集合类型。但是有序集合类型的集合操作不如集合类型强大。当我们需要直接获得集合运算的结果时,使用有序集合实现可以使用MULTI,ZINTERSTORE,ZRANGE,DEL和EXEC这5个命令自己实现ZINTER:
MULTI ZINTERSTORE tempKey ...ZRANGE tempKey ...DEL tempKeyEXEC
SORT命令
集合类型经常被用于存储对象的ID,很多情况下都是整数,所以Redis对这种情况进行了特殊的优化,元素的排列是有序的,原因在于集合类型的底层数据结构。示例如下:
127.0.0.1:6379> sadd key 6 2 4 8(integer) 4127.0.0.1:6379> smembers key1) "2"2) "4"3) "6"4) "8"127.0.0.1:6379>
SORT命令的使用,对列表类型进行排序:
127.0.0.1:6379> lpush mylist 4 2 6 8(integer) 4127.0.0.1:6379> lrange mylist 0 -11) "8"2) "6"3) "2"4) "4"127.0.0.1:6379> sort mylist1) "2"2) "4"3) "6"4) "8"127.0.0.1:6379>
在对有序集合类型排序时会忽略元素的分数,只针对元素自身的值进行排序。如下:
127.0.0.1:6379> zadd myset 50 2 40 3 20 1 60 5(integer) 4127.0.0.1:6379> sort myset1) "1"2) "2"3) "3"4) "5"127.0.0.1:6379> sort myset desc1) "5"2) "3"3) "2"4) "1"127.0.0.1:6379>
除了可以排列数字外,SORT命令还可以通过ALPHA参数实现按照字典顺序排列非数字元素。SORT命令还支持LIMIT参数来返回指定范围的结果。用法和SQL语句一样,LIMIT offset count,表示跳过前offset个元素并获取之后的count个元素。如下:
127.0.0.1:6379> lpush mylist a c e d B C A(integer) 7127.0.0.1:6379> sort mylist(error) ERR One or more scores can't be converted into double127.0.0.1:6379> sort mylist alpha1) "a"2) "A"3) "B"4) "c"5) "C"6) "d"7) "e"127.0.0.1:6379> sort mylist alpha desc limit 1 21) "d"2) "C"127.0.0.1:6379>
SORT是Redis中最强大最复杂的命令之一,如果使用不好很容易成为性能瓶颈。SORT命令的时间复杂度是O(n+mlogm),其中n表示要排序的列表中的元素个数,m表示要返回的元素个数。当n较大的时候SORT命令的性能相对较低,并且Redis在排序前会建立一个长度为n(有一个例外是当键类型为有序集合且参考键为常量键名时容器大小为m而不是n)的容器来存储待排序的元素,虽然是一个临时的过程,但如果同时进行较多的大数据量排序操作则会严重影响性能。所以开发中使用SORT命令时需要注意以下几点:
尽可能减少待排序键中元素的数量(使n尽可能小)
使用LIMIT参数只获取需要的数据(使m尽可能小)
如果要排序的数据数量较大,尽可能使用STORE参数将结果缓存
BY参数
BY参数的语法为BY参考键。其中参考键可以是字符串类型键或者是散列类型键的某个字段(表示为键名->字段名)。如果提供了BY参数,SORT命令将不再依据元素自身的值进行排序,而是对每个元素使用元素的值替换参考键中的第一个"*"并获取其值,然后依据该值对元素排序。如下:
127.0.0.1:6379> sort myhash:user by user:* -> age desc1) "5"2) "3"3) "1"4) "2"
在上例中SORT命令会读取user:1、user:2、user:3、user:5几个散列键中的age字段的值并以此决定myhash:user键中各个用户ID的顺序。
除了散列类型之外,参考键还可以是字符串类型,如下:
127.0.0.1:6379> lpush sortbylist 2 1 3(integer) 3127.0.0.1:6379> set itemscore:1 50OK127.0.0.1:6379> set itemscore:2 100OK127.0.0.1:6379> set itemscore:3 -10OK127.0.0.1:6379> sort sortbylist by itemscore:* desc1) "2"2) "1"3) "3"127.0.0.1:6379> sort sortbylist by ANY1) "3"2) "1"3) "2"127.0.0.1:6379>
当参考键名不包含"*"时(即常量键名,与元素值无关),SORT命令将不会执行排序操作,因
为Redis认为这种情况是没有意义的,因为所有要比较的值都一样。
注意:Redis判断参考键名是不是常量键名的方式是判断参考键名中是否包含"*",形如somekey->somefield:*中包含"*"所以不是常量键名。所以在排序的时候Redis对每个元素都会读取键somekey中的somefield:*字 段("*"不会被替換),无论能否获得其值,每个元素的参考键值是相同的,所以Redis会按照元素本身的大小排列。
如果几个元素的参考键值相同,SORT命令会再比较元素本身的值来决定元素的顺序。如下:
127.0.0.1:6379> lpush sortbylist 4(integer) 4127.0.0.1:6379> set itemscore:4 50OK127.0.0.1:6379> sort sortbylist by itemscore:* desc1) "2"2) "4"3) "1"4) "3"127.0.0.1:6379>
元素4的参考键itemscore:4的值和元素1的参考键itemscore:1的值都是50,所以SORT命令会再比较4和1元素本身的大小来决定两者的顺序。
当某个元素的参考键不存在时,会默认参考键的值为0。如下:
127.0.0.1:6379> lpush sortbylist 5(integer) 5127.0.0.1:6379> sort sortbylist by itemscore:* desc1) "2"2) "4"3) "1"4) "5"5) "3"127.0.0.1:6379>
5排在了3的前面,是因为5的参考键不存在,所以默认为0,而3的参考键值为-10。
GET参数
GET参数不影响排序,它的作用是使SORT命令的返回结果不再是元素自身的值,而是GET参数中指定的键值。GET参数的规则和BY参数一样,GET参数也支持字符串类型和散列类型的键,并使用"*"作为占位符。如下:
127.0.0.1:6379> sort myhash:user by user:* -> age descget user:* -> name1) "tom"2) "dog"3) "cat"4) "dodd"127.0.0.1:6379> sort myhash:user by user:* -> age descget user:* -> name get user:* -> age1) "tom"2) "5"3) "dog"4) "3"5) "cat"6) "1"7) "dodd"8) "2"
可见有N个GET参数,每个元素返回的结果就有N行。如果要返回元素自身的值可以使用GET#:
127.0.0.1:6379> sort myhash:user by user:* -> age descget user:* -> name get user:* -> age get#1) "tom"2) "5"3) "user:4"4) "dog"5) "3"6) "user:2"7) "cat"8) "1"9) "user:1"10) "dodd"11) "2"12) "user:2"
STORE参数
默认情况下SORT会直接返回排序结果,如果希望保存排序结果,可以使用STORE参数。如希望把结果保存到sort.result键中:
127.0.0.1:6379> sort myhash:user by user:* -> age descget user:* -> name get user:* -> age get# store sort.result(integer)12127.0.0.1:6379> lrange sort.result 0 -11) "tom"2) "5"3) "user:4"4) "dog"5) "3"6) "user:2"7) "cat"8) "1"9) "user:1"10) "dodd"11) "2"12) "user:2"
六、GEO介绍
地理信息定位,存储经纬度,计算两地距离,范围计算等。适用场景:计算附近酒店,餐馆等。geo的type是zset。使用方法:
1. GEOADD key longitude latitude member(添加地理信息)
127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing(integer) 1127.0.0.1:6379> geoadd cities:locations 116.28 39.55 beijing(integer) 0127.0.0.1:6379> geoadd cities:locations 114.29 38.02 shijiazhuang(integer) 1127.0.0.1:6379>
2. GEOPOS key member [member...](获取地理信息)
127.0.0.1:6379> geopos cities:locations beijing1) 1) "116.28000229597091675"2) "39.5500007245470826"127.0.0.1:6379>
3. GEODIST key member1 member2 [unit](计算两个地理位置的距离)
unit:m(米)、km(千米)、mi(英里)、ft(尺)
127.0.0.1:6379> geodist cities:locations beijing shijiazhuang"242326.2997"127.0.0.1:6379> geodist cities:locations beijing shijiazhuang km"242.3263"127.0.0.1:6379>
4. GEORADIUS(获取指定范围内的地理位置信息集合)

七、有序集合总结
有序集合类型和列表类型对比如下。
相同点:
二者都是有序的
二者都可以获得某一范围的元素
不同点:
列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会较慢,所以它更加适合实现如"新鲜事"或"日志"这样很少访问中间元素的应用
有序集合类型是使用散列表和跳跃表(Skip list)实现的,所以即使读取位于中间部分 的数据速度也很快(时间复杂度是O(log(N)))
列表中不能简单地调整某个元素的位置,但是有序集合可以(通过更改这个元素的分 数)
有序集合要比列表类型更耗费内存。
推荐阅读

看完本文有收获?请转发分享给更多人
关注「并发编程之美」,一起交流Java学习心得
