




本期将分享近期全球知识图谱相关
行业动态、会议讲座、论文推荐

EOT(embassyofthings.com)是能源,制造和工业物联网(IIoT)软件的领导者,一直在与亚马逊网络服务(AWS)合作,为工业4.0之旅的工业公司开发两种即插即用的软件即服务(SaaS)解决方案EOT Twin Sight和EOT Twin Central。这两个解决方案利用并扩展了 EOT Twin Talk 的功能,并使用 AWS IoT SiteWise 构建,用于云历史数据存储和资产层次结构管理,并使用 AWS IoT TwinMaker 构建,能够将来自多个业务和运营数据源的孤立资产层次结构集成到集成且灵活的知识图谱模型中。
EOT Twin Sight 是一个 SaaS 应用程序,支持大规模分析和 ML 模型的可视化和报告。ML 模型结果嵌入到用例驱动的现代、低代码、AI 驱动的可视化平台中,供运营用户做出数据支持的决策,从而提高整个企业的运营效率。
EOT Twin Central是一个资产模型层次结构SaaS应用程序,它将企业业务系统数据(SAP,EAM,自定义SQL数据库等)与资产模型层次结构(历史学家,SCADA,OPC UA源)无缝集成到单一事实来源中。以资产为中心的语义知识图谱是 Twin Central 运营技术堆栈的核心。

Equitus International Inc
Equitus Corporation是一家主要以其在先进数据科学和信息技术方面支持美国国家安全领域的工作而闻名的公司,该公司成立Equitus International Inc负责Equitus Corporation旗舰图数据结构生态系统的国际分销。
Equitus Corporation开发并交付了下一代高可扩展性、高速数据生态系统,该生态系统将 AI、ML 和动态管理的图数据库集成并整合到一个统一的平台中,能够快速、大规模地自动收敛和关联大量不同数据。Equitus公司花了数年时间开发军用级数据结构和分析开发平台,使国防公司能够为政府客户构建量身定制的解决方案,轻松集成、组合,关联和连接大量不同的数据,为作战人员提供整合的洞察力。
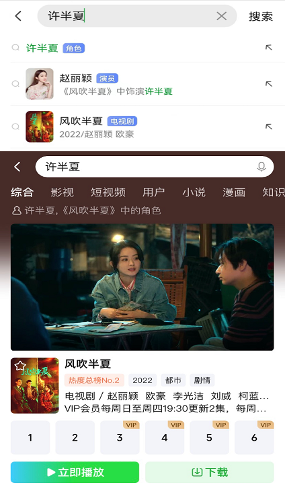
正在爱奇艺热播的时代群像闯剧《风吹半夏》内容热度值破9000,成为近期又一部高讨论、高热度的大剧。
《风吹半夏》讲述了改革开放前期九十年代,以许半夏为代表的民营企业家的创业故事。该剧以敢想敢拼、大胆博弈的创业精神,映照时代发展路径。引发大量关注。
基于爱奇艺行业领先的知识图谱与语义理解能力,用户搜索剧中角色或剧情卡段,会自动跳转剧集内容,这满足了用户多样化的搜索需求。比如在爱奇艺搜索“许半夏”,将直接关联角色扮演者赵丽颖和《风吹半夏》,搜索“赵丽颖新剧”也能一键跳转播放,进一步便捷查找和观看路径。
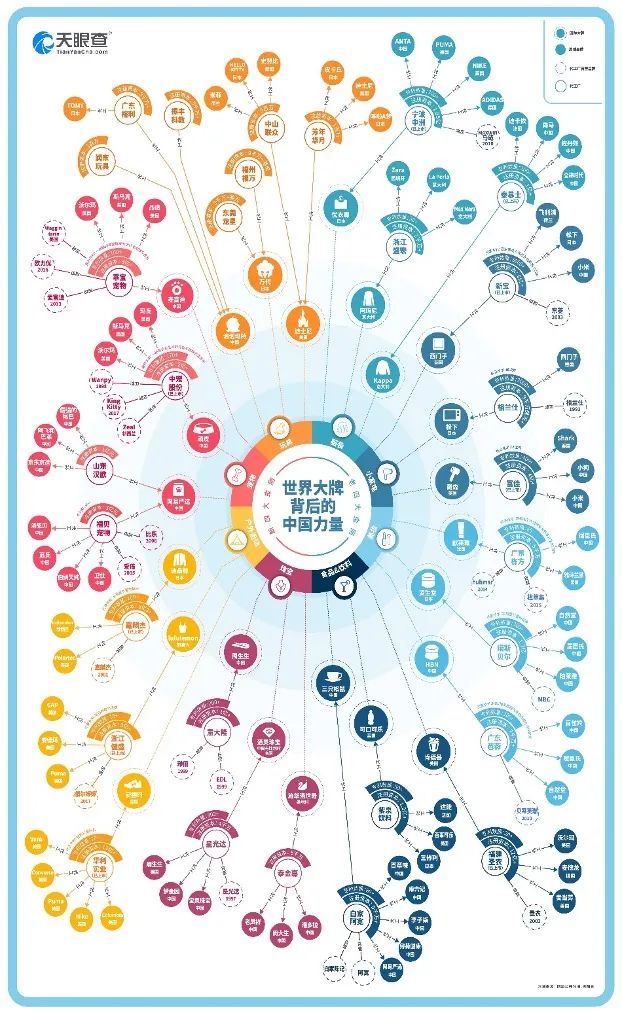
近日,天眼查App盘点了“世界大牌背后的中国力量”,基于平台收录的超3亿社会实体信息及AI大数据分析能力,在消费新趋势中洞见优秀的中国企业、国产品牌的崛起,看清核心产业带的布局情况及其发展趋势。从站在幕后到“品牌崛起”,一张“知识图谱”读懂中国制造的份量。围绕新老“四大金刚”,透过天眼查对“企业关系”、“股权结构”洞察形成的知识图谱,我们或可看见国内外品牌崛起中,中国制造的分量。
第六届网络犯罪侦查与预防大数据分析国际研讨会
大数据范式已成为当今数字取证调查中不可避免的一个方面。由于存储容量不断增加,获取被扣押数据介质的取证副本已经需要几个小时。此外,还需要其他几个耗时的实验室分析步骤,例如证据识别、相应的数据预处理、分析、链接和最终报告。必须对刑事案件中检查的每个物理设备重复这些步骤。传统的数字取证数据预处理和分析方法在处理案例数据的当代多样性、可变性、数量和速度时会遇到困难。因此,必须制定积极主动的方法并将其纳入日常执法行动;及时发现和预防数据密集型环境中的非法活动。因此,需要先进的大数据分析来协助网络犯罪调查,这需要新的自动化分析方法。本次研讨会旨在汇集大数据分析的最新发展,以帮助应对当前网络犯罪调查中的挑战。
研讨会将于 12 月 17 日至 20 日在日本大阪与IEEE 大数据 2022会议同期举办。

2022 CCF全国全国高性能计算学术年会
2022 CCF全国高性能计算学术年会(CCF HPC China 2022)将于2022年12月12-14日以 “大线上+小线下(济南·山东) ”的形式举办。CCF全国高性能计算学术年会(National Annual Conference on High Performance Computing,简称CCF HPC China)是高性能计算领域全球最具影响力的三大超算盛会之一,与德国ISC超算盛会、美国SC超算盛会并驾齐驱。大会旨在通过汇聚前沿学术成果、展示创新应用技术、交流创造行业价值,促进超算技术应用生态与科研、产业数字化升级转型,打造全球化、开放式HPC技术、学术共享交流平台。

本周推荐的是近期发布于arxiv上的论文:Start Small, Think Big: On Hyperparameter Optimization for Large-Scale Knowledge Graph Embeddings, 设计了一种新的知识图谱嵌入表示的超参数优化方法,作者来自德国曼海姆大学。

知识图谱以结构化的形式表示实体之间的关系,嵌入模型(KGE)将知识图谱中的实体和关系表示成低维稠密向量,广泛应用于链接预测、智能问答、多模态关系识别等任务中,新的嵌入模型和嵌入方法也在不断发展演进。
近年来有实验文章表明,知识图谱嵌入的质量受超参数的影响很大,如嵌入维度、训练类型、负采样数量、损失函数、优化方法、正则化方式等等,甚至可能超过了模型结构本身的影响。而在全量空间中进行超参数搜索代价太大,因此有一些工作采用一些启发式方法进行超参数优化,如只使用少量的训练论次或在采样子图上进行超参数搜索等。
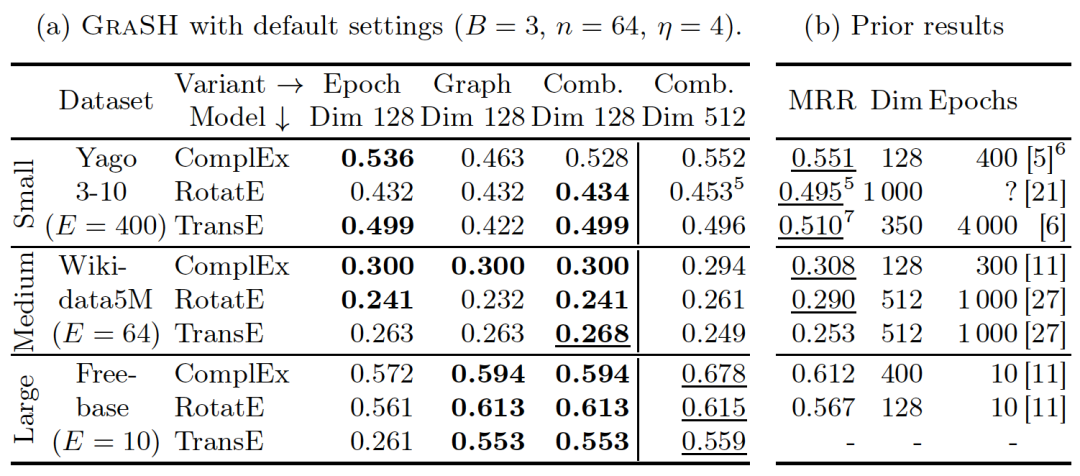
本文致力于在给定的搜索代价约束下,尽可能高效地获得高质量的KGE模型。基于连续减半的思想,提出了一个GRASH算法,通过将减少训练轮次和减小图规模的技术结合,在多质量层级下,实现KGE超参数优化的高质量和低消耗。算法的核心思想见下图:

文章在YAGO3-10、Wikidata5M、Freebase几个数据集上进行了实验,证明了本文方法的高质量、低资源消耗和健壮性,能够在大规模知识图谱上以很小的代价达到或超过sota的结果,而其中将k-core的图采样技术和训练轮次减少的技术结合是成功的关键。
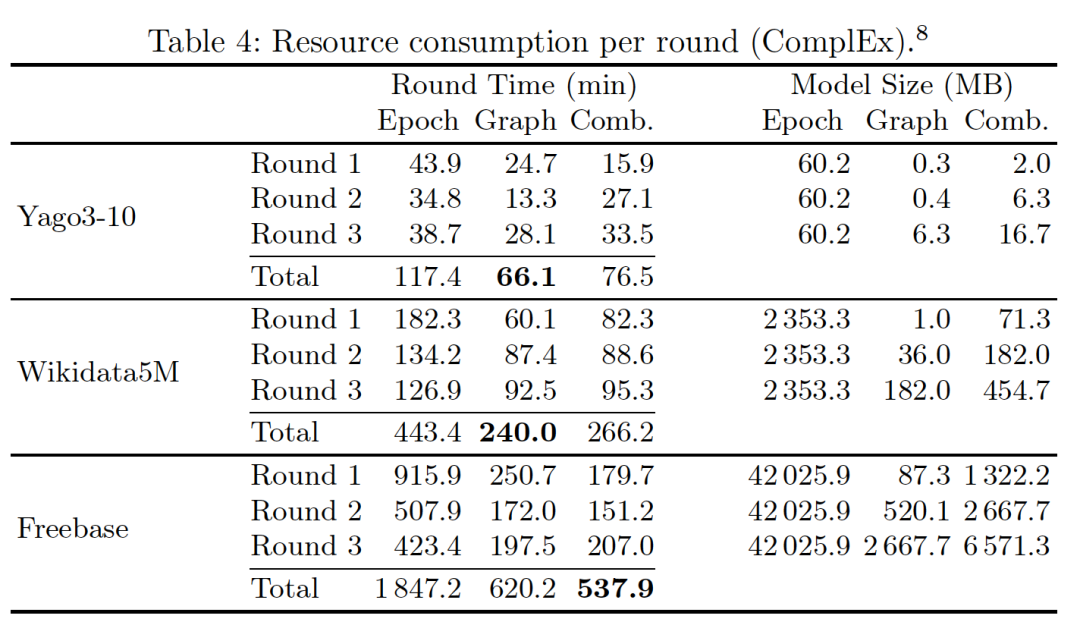
文章的代码和相关配置均已开源https://github.com/uma-pi1/GraSH,感兴趣的读者可以前去尝试。
更多链接
内容:胡喆媛、代雪佩、薛冰聪、王图图
编辑:王图图
排版:王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~或扫码入群



欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

