




点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel

01
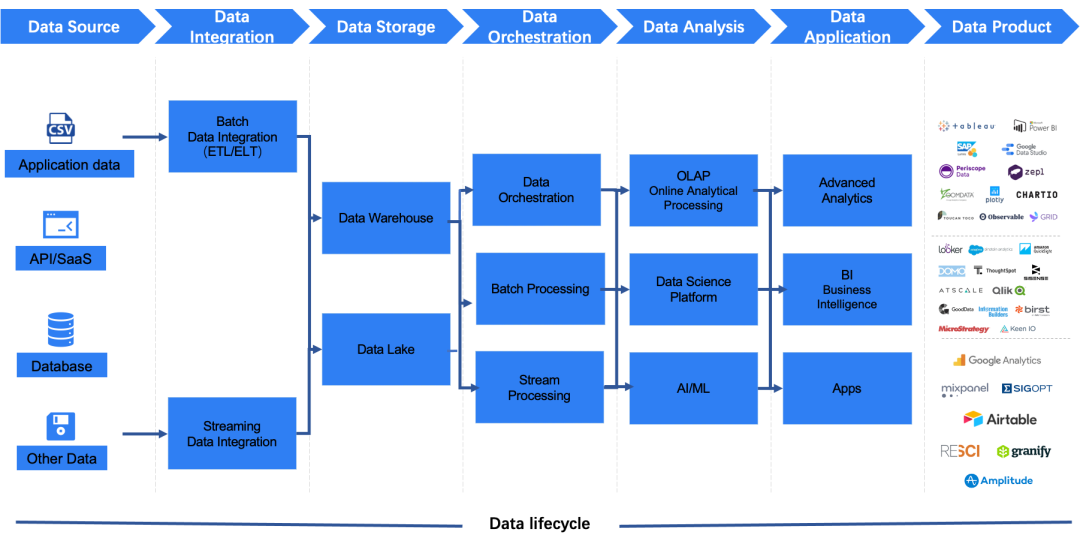
数据集成是什么?

02
数据集成的业务场景
同构/异构数据源间的同步:用户的原始数据需要转移存储,或利用目标存储系统的查询、分析能力,如 Hive 数据、本地数据需要同步到 Snowflake、Clickhouse 等做快速查询; 数据上云:用户需要把云下的数据快速安全的迁移到云上存储并做进一步的业务分析,如线下 MySQL、Postgre 等到云上 RDS。
03
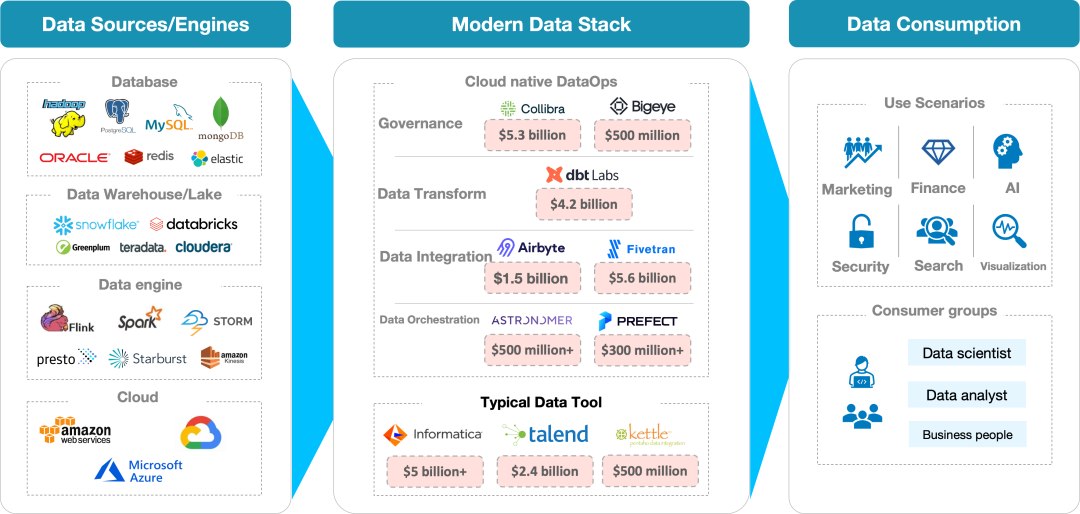
数据集成的常见策略
商业软件:Informatica PowerCenter、IBM InfoSphere DataStage 、Microsoft SQL Server Integration Services 等 开源软件:Kettle、Talend、Sqoop 等
04
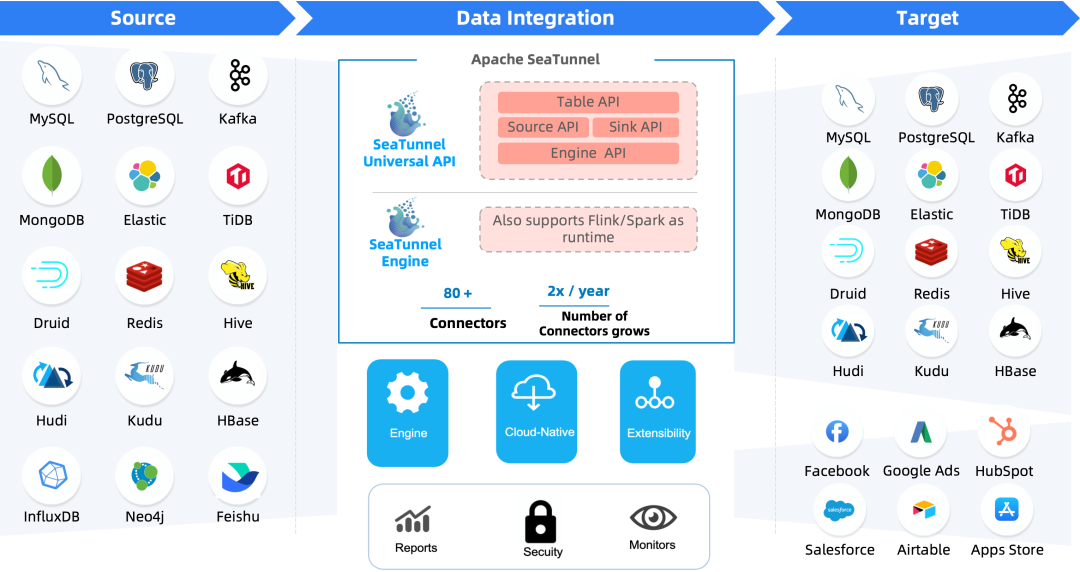
什么是SeaTunnel?
05
SeaTunnel 的特性
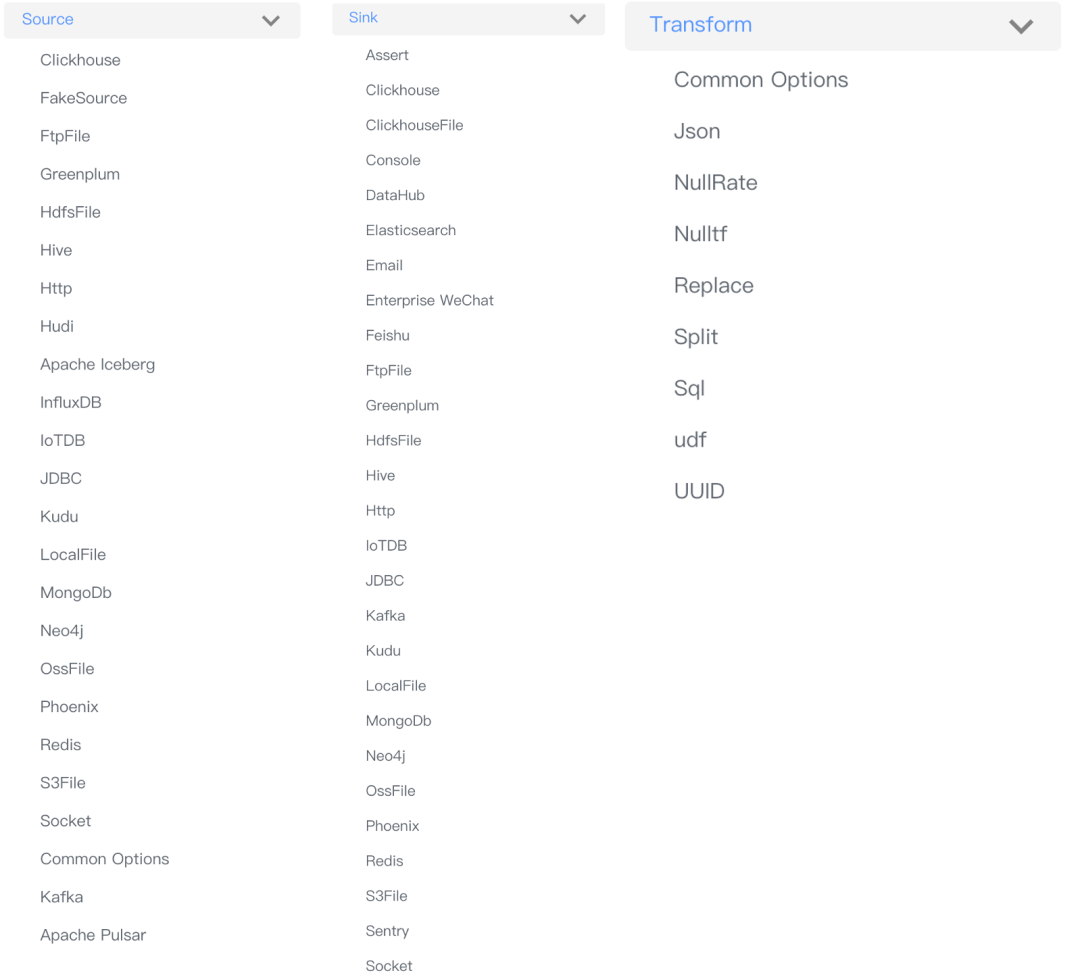
丰富易扩展的 Connector:SeaTunnel提供了不依赖具体执行引擎的 Connector API,SeaTunnel 提供了一套不依赖于具体执行引擎的 SeaTunnel Connector API,基于这套API开发的 Connector(Source, Transform, Sink) 可以运行在多种不同的引擎上,目前支持 SeaTunnel Engine, Flink, Spark。 Connector 插件化:插件化的设计让用户可以方便的开发自己的 Connector 并轻松集成到 SeaTunnel 项目中,目前 SeaTunnel 已经支持的 Connector 有 80 多个,这个数量正在以极快的速度增长。目前已经支持的连接器列表见下图。 批流一体:基于 SeaTunnel Connector API 开发的连接器可以完美兼容离线同步、实时同步、全量同步、增量同步等多种场景。这在极大程度上降低了数据集成任务管理的困难。 支持分布式快照算法,保证数据一致性。 多引擎支持:SeaTunnel 默认使用 SeaTunnel Engine 进行数据同步。同时为了适配企业已有的技术组件,SeaTunnel 还同时支持使用 Flink 或者 Spark 做为 Connector 的运行时执行引擎,SeaTunnel 支持多个 Spark 和 Flink 版本。 JDBC 多路复用,数据库日志多表解析:SeaTunnel 支持多表或整库同步,解决 JDBC 连接数过多的问题;支持多表或整库数据库日志读取解析,解决 CDC 多表同步场景下需要重复读取和解析日志的问题。 高吞吐、低延时:SeaTunnel 支持并行读取和写入,提供了高吞吐低延时稳定可靠的数据同步能力。 完善的实时监控:SeaTunnel 正在支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读取和写入的数据条数、数据大小、QPS 等信息。 支持编码和画布设计两种作业开发方式:SeaTunnel web 项目中提供了作业可视化管理、调度、运行和监控能力。
06
SeaTunnel Connectors
07
SeaTunnel 运行流程
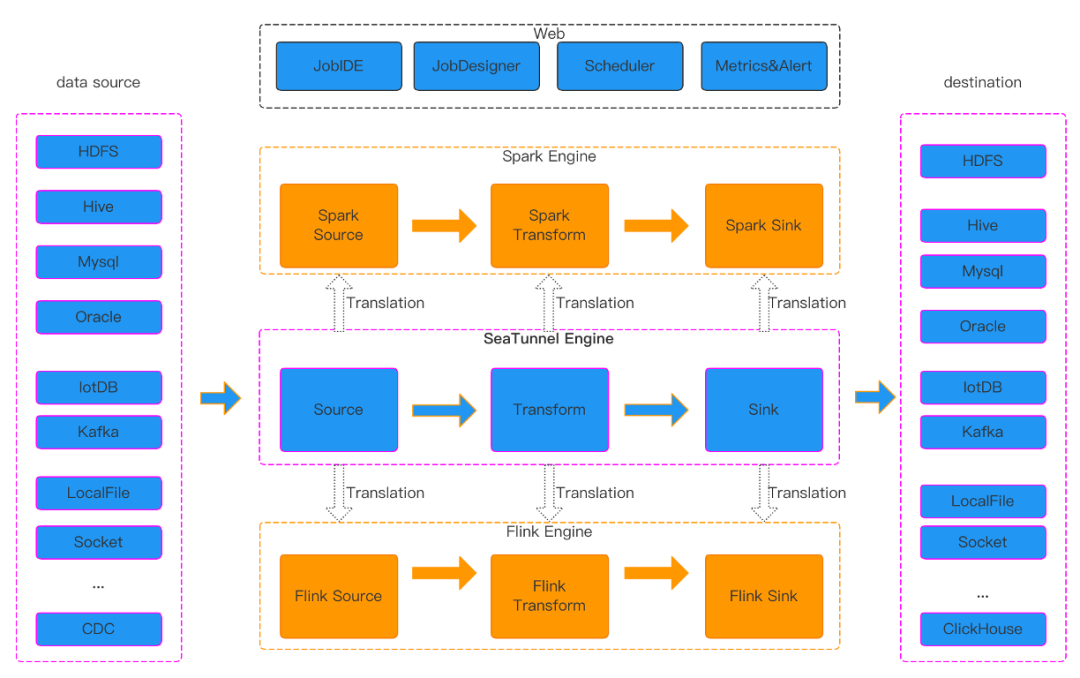
08
Quick Start for SeaTunnel
Spark Flink SeaTunnel Engine
cd "apache-seatunnel-incubating-${version}"./bin/seatunnel.sh \--config ./config/seatunnel.streaming.conf.template -e local
09
小结
数据集成是消除企业信息孤岛,实现数据共享,是现代数据技术栈成功的关键,进而为企业实现数据治理提供扎实的 ”hardcore“ 。 数据集成可以将企业本地数据、SaaS 数据等不同“孤岛”的数据连接起来,让数据不在孤立,从而挖掘出更大的价值。 数据集成可以让企业的应用、流程、系统、组织和人员等关键要素都协同起来,提高企业业务效率。 数据集成可以将不同类型的数据聚合,让用户可以快速获得有用信息并迅速分析提炼出有价值的信息,从而提升数字化决策的成功率。
Apache SeaTunnel

往期推荐
你这么可爱,点个赞吧!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
