






transformers是一个用于构建、训练和部署最先进的NLP 模型的开源项目。
transformers来构建可复用的高效文本分类的工作流,并使用
MLflow管理实验和模型。
01
Java8环境
sudo apt-get updatesudo apt-get install openjdk-8-jdkjava -version
# 确认你的jdk的目录是否为这个,配置环境变量export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64export PATH=$PATH:$JAVA_HOME/bin
02
Apache DolphinScheduler 3.1.1
# 进入需要安装DolphinScheduler的目录
mkdir dolphinscheduler && cd "$_"
## install DolphinScheduler
wget https://mirrors.tuna.tsinghua.edu.cn/apache/dolphinscheduler/3.1.1/apache-dolphinscheduler-3.1.1-bin.tar.gz
tar -zxvf apache-dolphinscheduler-3.1.1-bin.tar.gz
rm apache-dolphinscheduler-3.1.1-bin.tar.gz
## start DolphinScheduler
cd apache-dolphinscheduler-3.1.1-bin
bash bin/dolphinscheduler-daemon.sh start standalone-server
## 可以通过以下命令查看日志
# tail -500f standalone-server/logs/dolphinscheduler-standalone.log
admin,密码:
dolphinscheduler123
03
docker run --name mlflow -p 5000:5000 -d jalonzjg/mlflow:latest启动即可。
01
环境准备
git clone https://github.com/jieguangzhou/Dolphinscheduler-NLP-Workflow.git
cd Dolphinscheduler-NLP-Workflow
transformers-textclassification,安装依赖,用于运行工作流。
conda create -n transformers-textclassification python==3.8 -y
conda activate transformers-textclassification
pip install -r requirements.txt
transformers-textclassificationConda环境。
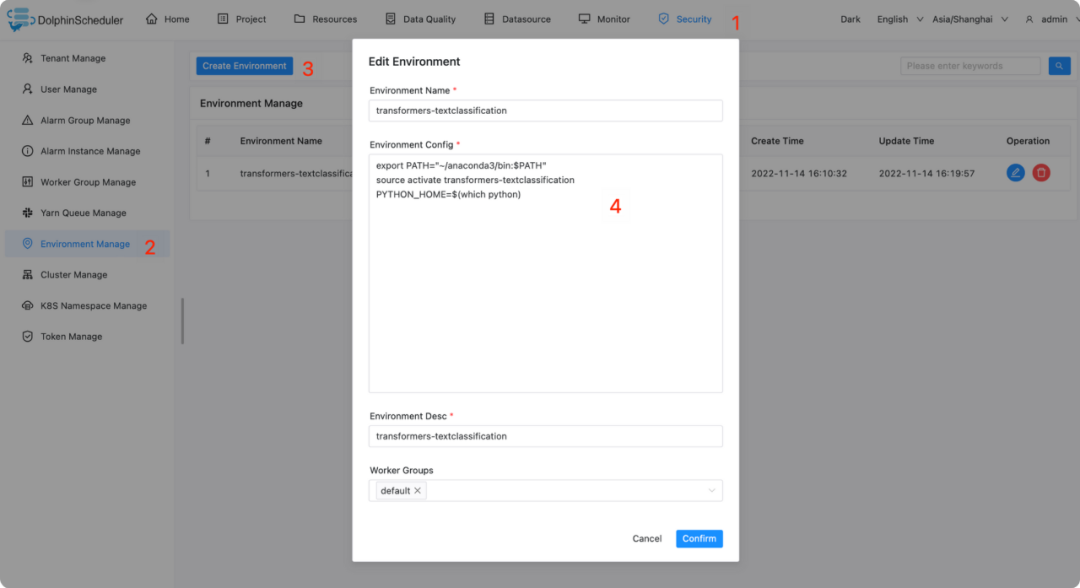
# 请按服务器实际情况修改conda路径
export PATH="~/anaconda3/bin:$PATH"
source activate transformers-textclassification
PYTHON_HOME=$(which python)
02
提交工作流
# 配置python gateway的连接信息
bash init_pyds.sh
# 提交工作流
python pyds.py
03
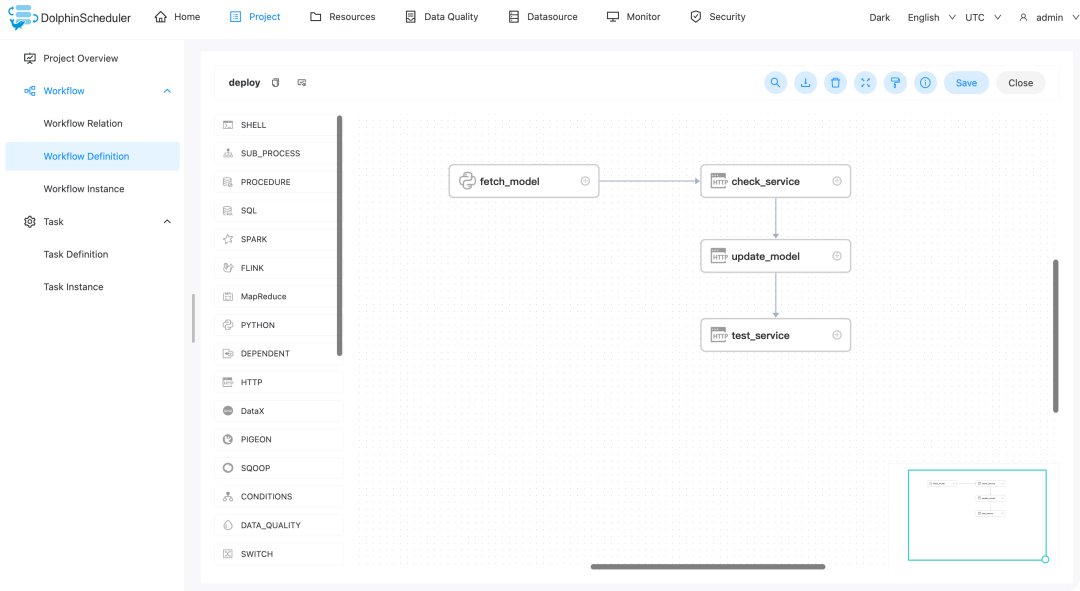
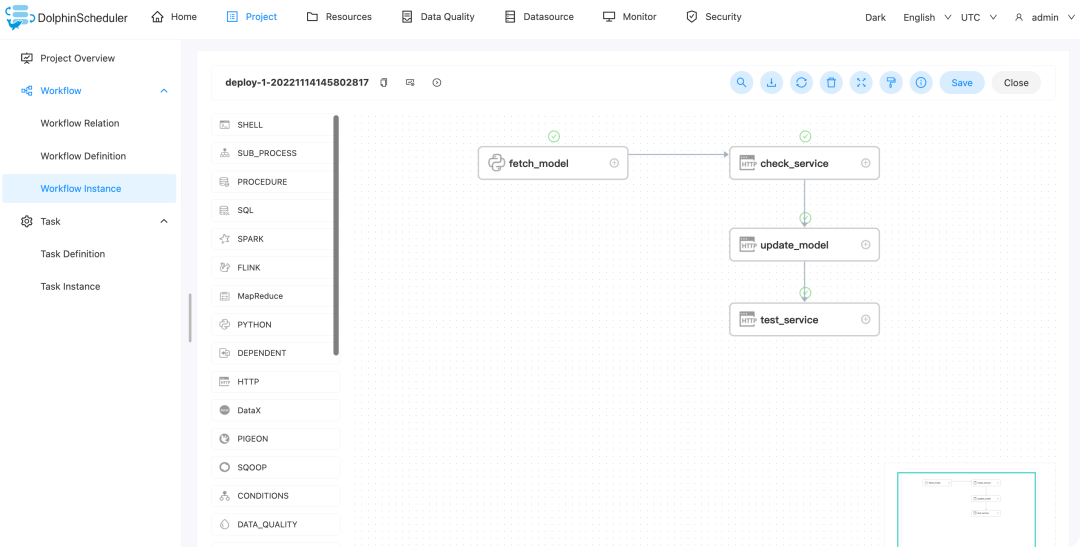
工作流定义
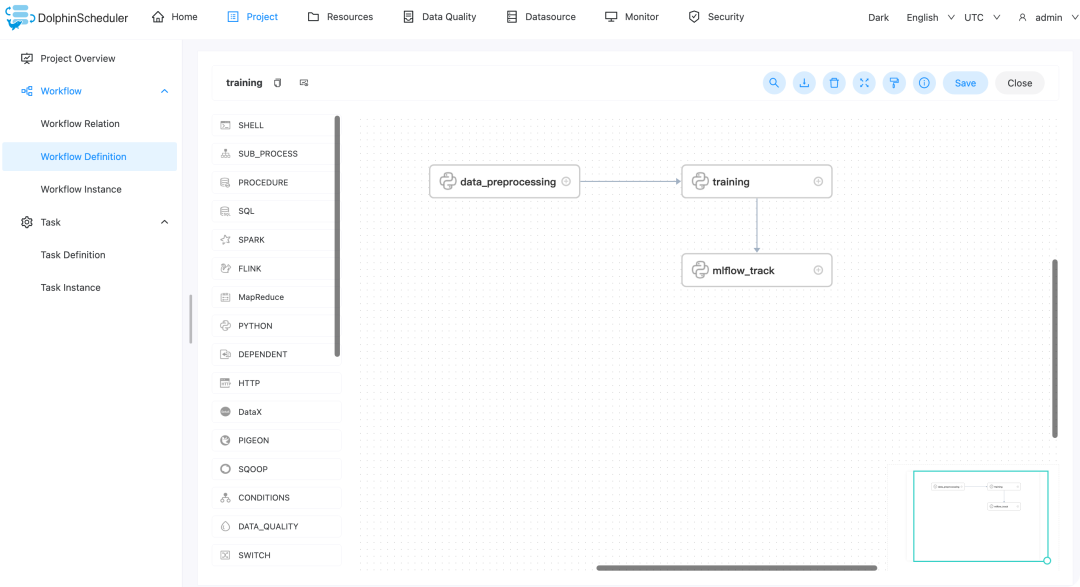
训练模型工作流
data_preprocessing: 数据预处理,主要为文本数据中的切词等操作,具体实现见 data_preprocessing.pytraining:模型训练,主要为训练文本分类模型,具体实现见 [training.py](http://training.py)mlflow_track: 将训练出来的模型文件,执行参数,和评估指标,记录到 mlflow tracking server
中,具体实现见mlflow_track.py
。
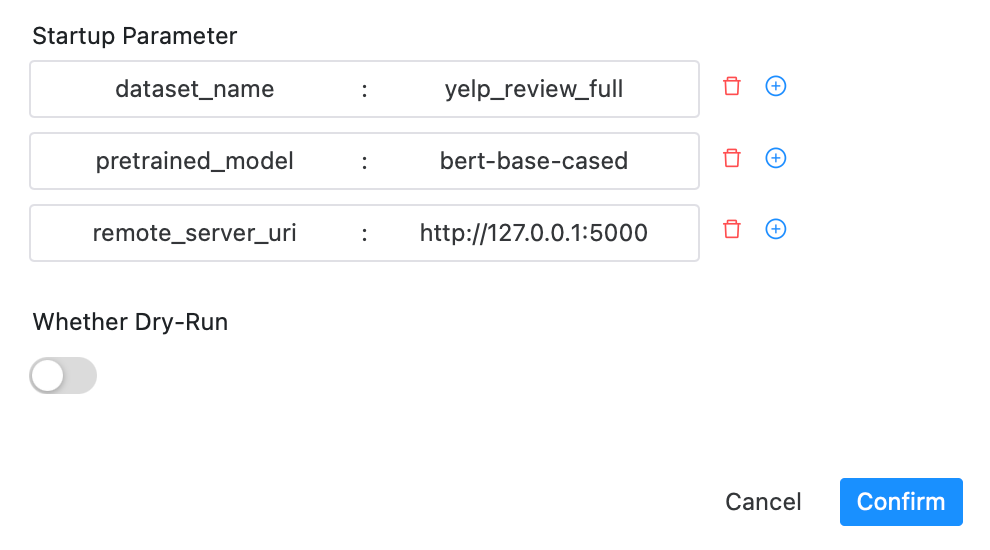
dataset_name: 数据集名字 pretrained_model: 要使用的预训练的模型 remote_server_uri: mlflow tracking server
地址
fetch_model: 从 mlflow tracking server
中拉取指定版本的模型文件,详见fetch_model.pycheck_service: 检测模型服务是否开启,若否,则报错,成功则继续往下运行 update_model: 使用 fetch_model
拉取的模型文件,更新模型服务test_service: 更新完成后,运行服务测试
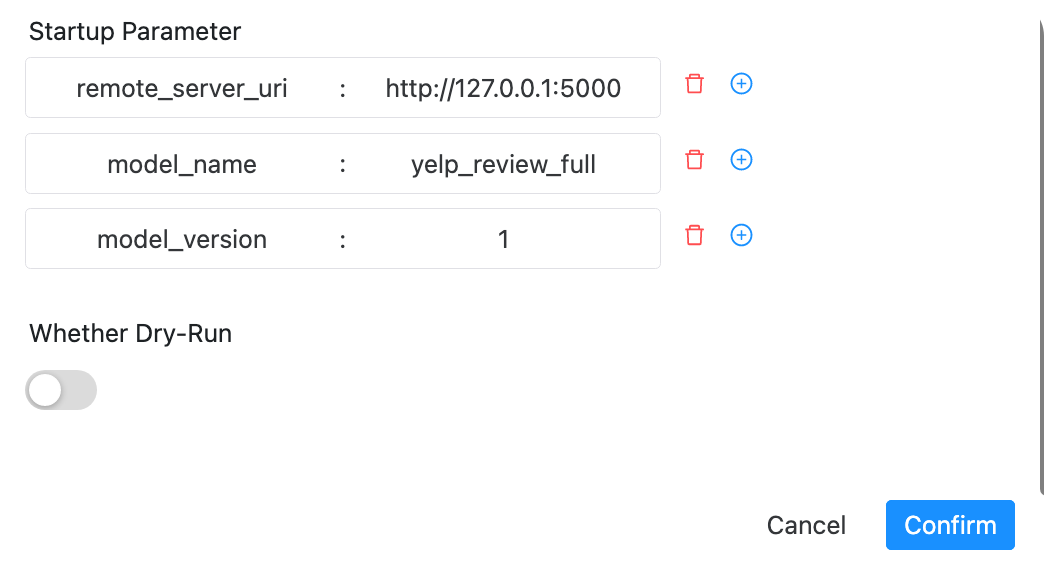
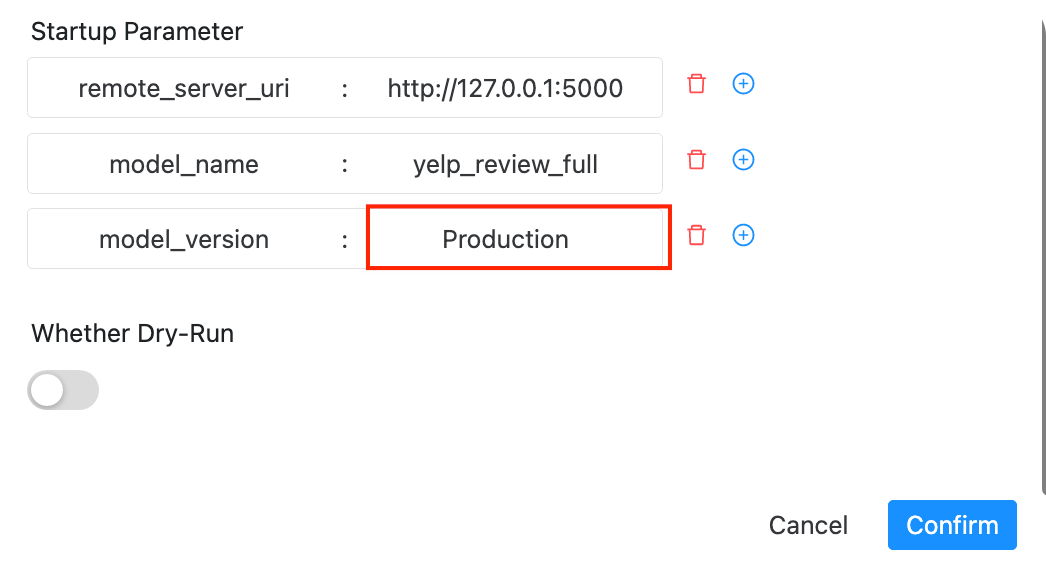
remote_server_uri: mlflow tracking server
地址model_name: 部署的模型的名字 model_version: 部署的模型的版本号
01
模型训练
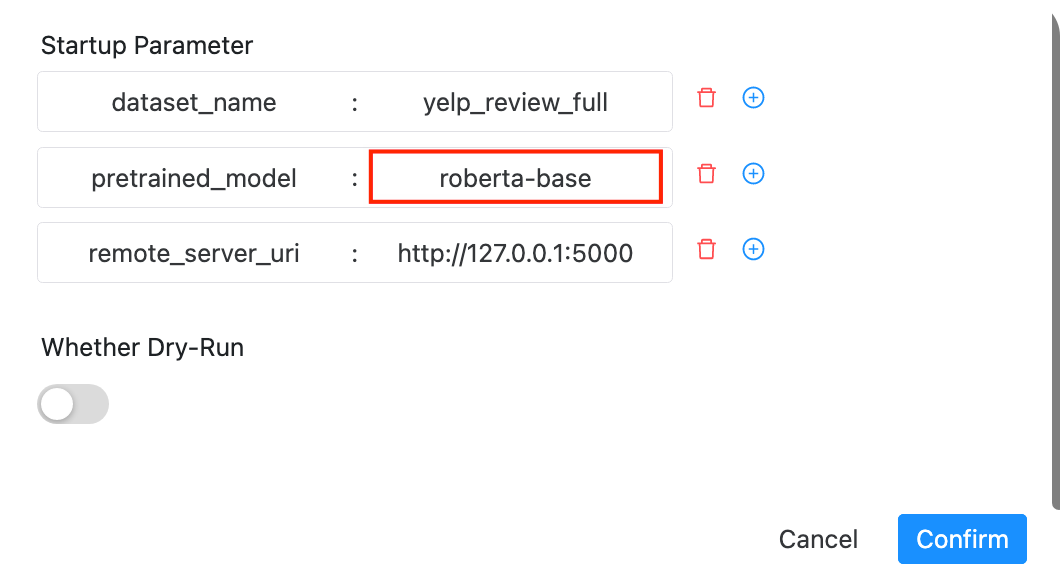
dataset_name=yelp_review_full训练模型,在工作流执行页面中分别依次(如需要并行多个一起跑,请确认GPU资源足够,并且修改脚本指定GPU资源)使用预训练模型
bert-base-cased,
microsoft/deberta-base,
roberta-base运行工作流。
roberta-base时启动界面如下图所示
mlflow tracking server中查看3个试验相关的指标,如图所示:
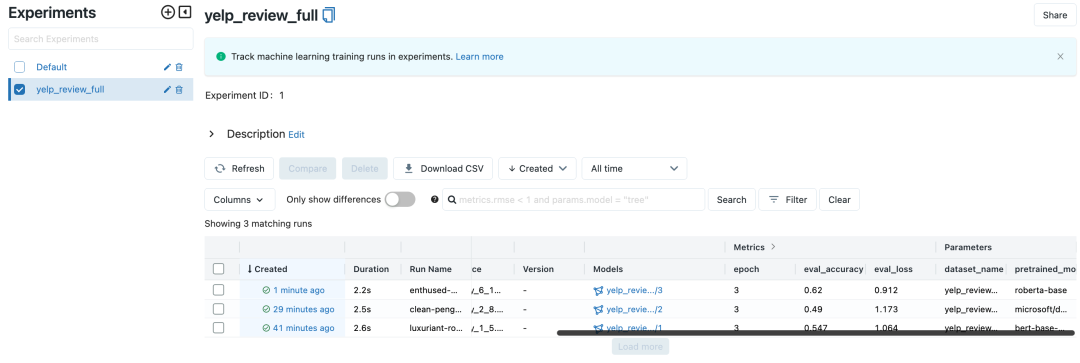
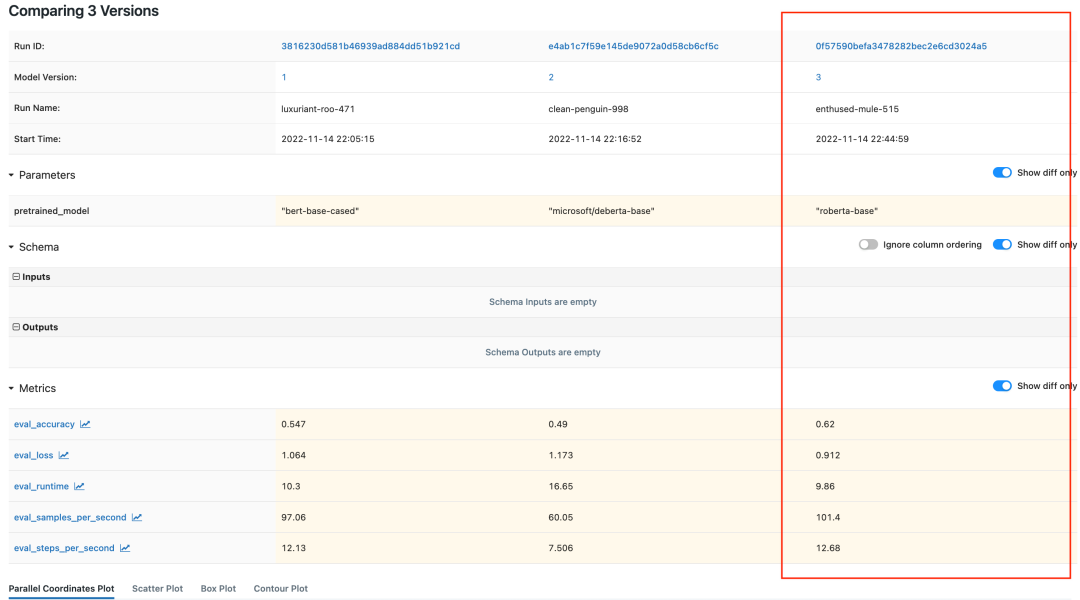
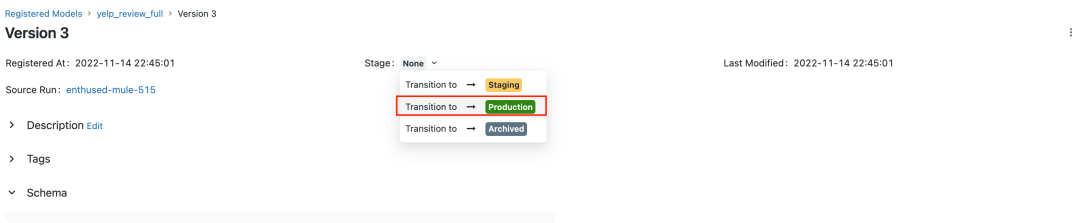
roberta-base, acc为0.62),并将其注册为
Production,用于接下来的模型部署。
02
模型部署
BentoML*,
Seldon Core等。
# 启动服务
uvicorn predict_service:app

transformers库构建文本分类的工作流。
可以基于DolphinScheduler调度系统的特性,稳定执行机器学习各个任务,容错机制,调度机制以及支持丰富的执行任务类型可以更好地运行机器学习工作流,包括模型训练,模型部署等工作流。 工作流的复用,以及工作流内的任务复用,能够提高算法团队研发效率。如上述的模型训练工作流,以及模型部署工作流,针对各自团队的特性进行适配,即可长期使用。 制作完成的工作流,可以使用DolphinScheduler的接口来可以对接企业内部系统,以DolphinScheduler作为AI平台的底层调度系统,再在业务侧的系统实现对应的调用。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞DolphinScheduler 登陆 AWS AMI 应用市场!
☞DolphinScheduler 机器学习工作流预测今年 FIFA 世界杯冠军大概率是荷兰!
☞手把手教你上手Apache DolphinScheduler机器学习工作流
☞最佳实践 | 如何基于GitHub Actions创建 DolphinScheduler Python API的CI/CD?

