




一、SQL优化的重要性
作为一名DBA,SQL优化是我们工作中必不可少的技能,在投产的系统中,存在大量的SQL语句需要我们分析和快速做出处理。很是考验我们的经验。这些慢SQL的原因有很多,有SQL编码不规范,设计有缺陷,SQL场景未考虑全面,数据量未评估等,预先需要建立索引的表而未设计建立,需分表分区的未进行拆解,也有环境因素造成的缺陷。也有出厂测试之前没有问题,但实际部署到客户现场时候却出了问题。这些异常语句,如果不及时处理,会造成对数据库的一个性能瓶颈,直接影响着目标用户的使用和体验。所以数据库SQL的性能优化,快速处理显得尤为重要。
文章目标,希望读者掌握达梦SQL优化的基础,SQL性能分析思路,参数配置标准工艺化理念,性能辅助工具熟练应用。文章最后7,8章也整合了第三方的常见分析工具,辅助达梦数据库性能压测时候的一种分析手段。文章中没有过多对单个SQL性能优化深入讲解,主要原因还是部分SQL涉及公司代码不便发布,其次也是个人能力有限,也是在不断学习中。
预估执行计划生成及基础说明
我们以达梦8数据库为例,拿到一条SQL的时候,首先要下达梦手册中提出的有效SQL规范,及是否命中了特殊OR子句的不规范,是否用了复杂的正则表达式,避免重复很高的索引,UINON ALL 是否可以替换UNION操作等,某些场景INSTR函数导致的NEST LOOP效率等,再就是看下它的预估执行计划。预估执行计划,我们可以采用达梦客户端点击如下图解小按钮生成,也可以按快捷键F9生成,也可以在SQL前加EXPLAIN生成预估计划;
2.1、生成预估执行计划
达梦客户端直接点击菜单栏按钮或按F9生成:
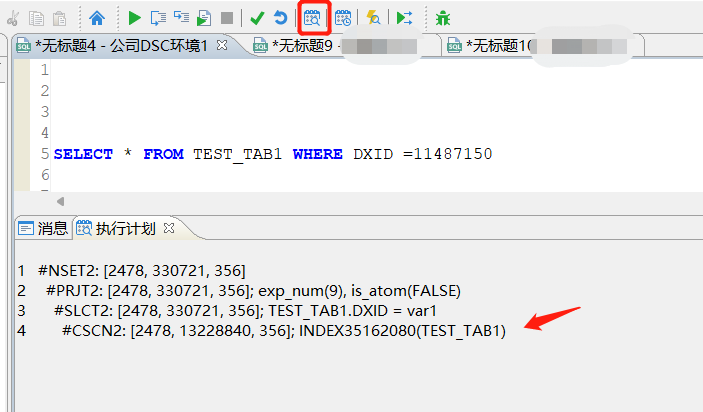
执行EXPLAIN SELECT * FROM TEST_TAB1 WHERE DXID=11487150 生成:
2.2、操作符讲解
执行计划操作符,大家起初可能并不熟悉,这个可以参考达梦官方手册:DM8 DBA.pdf ,在附录3有执行计划操作符说明。常见操作符,需要掌握,比如:聚集索引扫描(CSCN2),全表扫描(CSCN),索引扫描(SSEK),二次回表(BLKUP),除重(DISTINCT) ,二级索引定位(SSEK2)等等;多表关联,我们通常会遇到:(HASH链接)HASH JOIN,嵌套循环连接(NEST LOOP JOIN),
还有MERGE 链接(MERGE JOIN );
大表和大表关联主要HASH JOIN更优,而如果小表和大表关联,通常是NEST LOOP JOIN会更优,实际情况都是和数据量有关,优化器大部分能选择到合适的操作符,少数情况需要人为干涉。
2.3、执行计划相关含义说明
以上图示例简单说下执行计划相关含义,让我们先入门下达梦的优化
1 #NSET2: [2478, 330721, 356]
2 #PRJT2: [2478, 330721, 356]; exp_num(9), is_atom(FALSE)
3 #SLCT2: [2478, 330721, 356]; TEST_TAB1.DXID = var1
4 #CSCN2: [2478, 13228840, 356]; INDEX35162080(TEST_TAB1)
#NSET2 表示收集结果集的操作符
#PRJT2:投影运算,选择表达式的计算
#SLCT2: 查询条件过滤操作符
#CSCN2: [2478, 13228840, 356]
说明:三元组合,3个数字分别表示【估算代价,结果条数,行数据的长度】;
这里第二个值如果是服务器执行计划则会有关联表列的结果条数,中间有->,后面第4.2小结有说明;CSCN2: [2478, 13228840, 356]这句含义是:这是一个全表扫描操作,涉及的整体代价估算为2478,结果集为13228840,每行数据长度为356;
2.4、执行计划顺序讲解
执行计划我们可以理解是一个数型状,看懂执行计划顺序,会让我们更好的分析SQL性能问题,通常执行计划查看,大家可以在达梦客户端选择表格展示或文本方式,看执行顺序表格会更直观,分析执行计划,文本更适合,但是SQL的执行顺序,并不是简单的从下而上,她的解析是要遵守规律,具体大家可以这样理解:
- 缩进越深的越先执行;
- 同样缩进的上面的先执行,下面的后执行;
3、上下的优先级高于内外;
如上说明还是不够直观,我再图解一个样例让大家理解:
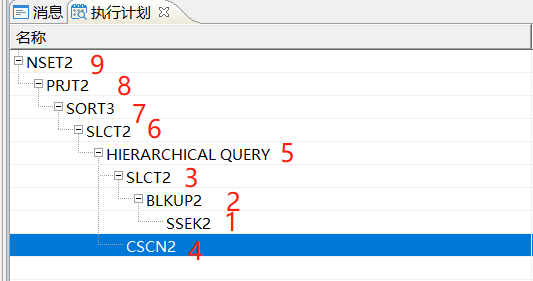
说明:越缩进越先执行,即最终缩进分叉了3,4,同样的缩进,从上由下优先级更高,所以这里的3先执行,3下面又有越深的越先执执行,又有1,2 ,所以整个排序执行顺序就出来了,开始看不习惯,大家多看几次就习惯了。
三、达梦性能分析思路
达梦数据库的优化,我平常使用的最多的还是,达梦数据库优化“三把斧”,在实践中发现可以排除93%(百分比数值只是个人以往解决性能问题的估算百分比)以上的性能问题,我说的三把斧主要三个方面(统计信息收集,合理的索引建立,DM.ini参数的优化),在使用三把斧过程中,我们首先要预检查下SQL,以及SQL编写的初级错误问题,例如:OR语句,困难正则表达式,未加过滤条件,笛卡尔,隐式转换,简单先过一遍。
在实际过程中,大部分SQL优化可以通过收集统计信息,索引新增,索引调整,达梦DM.INI参数调整等得到优化处理,而进阶一些的比较难分析的,就涉及到了增加HINT,SQL改写,在处理过程中,都需要根据具体SQL来判断,常见的有关联临时表查询,层次查询等容易需要Hint辅助,文章中给出浅显的例子来说明,实际优化过程中,还是需要不断的去实践,根据不同的SQL,分析执行计划,这样才能积累更加丰富的经验。
3.1、统计信息收集基础讲解
达梦数据库是基于代价的优化器,达梦数据库统计信息不准,会影响到执行计划的估算,导致SQL解析到错误的执行计划,如何判断统计信息有没有收集呢?
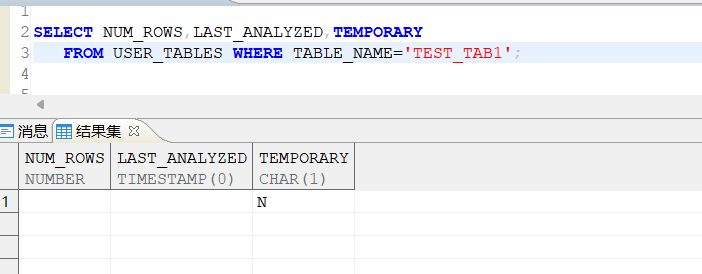
我们看如下SQL,主要看NUM_ROWS字段,如果没有收集通常是空,第二个LAST_ANALYZED 代表收集的时间,如果没有收集这个字段也是空,第三个TEMPORARY字段附带说明,N表示不是临时表,Y表示是临时表,通常如果TEMPORARY=Y 是不用收集的,
这个大家查询的时候注意下,临时表无需收集统计信息;
用例讲解:
SELECT NUM_ROWS,LAST_ANALYZED,TEMPORARY
FROM USER_TABLES WHERE TABLE_NAME='TEST_TAB1';
我们需要对表进行查询,查询语句如下:
当一个表缺失了统计信息我通常用如下语句修复:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(USER,'TEST_TAB1',NULL,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
END;
DBMS_STATS.GATHER_TABLE_STATS参数说明:
以上参数注释:
第一个参数:USER是所属用户,如果你要指定其它用户,单独填写,默认USER是当前用户下的表;
第二个参数:就是你所要收集的表;
第三个参数:一般不是分区表名填写NULL即可,默认也是 NULL,区分大小写;
第四个参数:采样百分比,收集的百分比,范围为 0.000001~100,默认系统自定;第五个参数:TRUE,保留参数,是否使用随机块代替随机行,默认我们填写 TRUE即可,第六个参数:控制列的统计信息集合和直方图的创建的格式默认我们填写FOR ALL COLUMNS SIZE AUTO即可,表示所有列收集,需要深入理解的可以参考达梦官方手册:DM8 - System Packages.pdf,平常我比较常用的还是DBMS_STATS.GATHER_TABLE_STATS;其次官方也提供了一些函数;
3.2、统计信息收集简单案例
什么时候需要收集统计信息?
通常执行计划估算数据量不准的时候就需要收集了,相差不大一般没有影响,如果比较大就要收集了,否则会影响性能;这里用以下例子说明,只是对表未收集统计信息导致执行计划估算有差异的案例:
--步骤1:直接创建2个表,一般新创建的表统计信息是不会自动收集的(否则开启AUTO_STAT_OBJ全表监控的自动收集),我们查一下它的执行计划,这个时候结果集应该是估算有差异的;
CREATE TABLE TEST1208_1 AS
select * from dba_TAB_COLUMNS WHERE TABLE_NAME='ALL_ALL_TABLES';
CREATE TABLE TEST1208_2 AS
select * from dba_TAB_COLUMNS WHERE TABLE_NAME='ALL_ALL_TABLES';
--客户端按F9,查看预估执行计划:
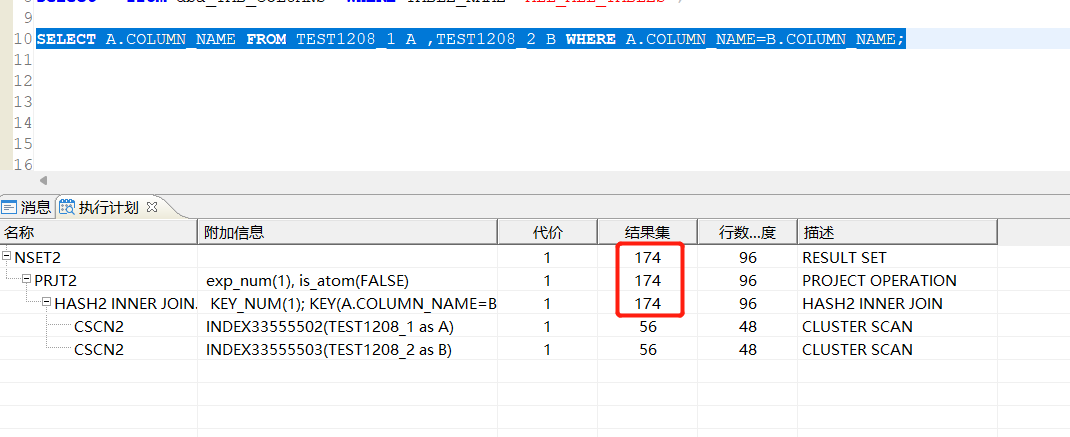
步骤2:获取真实执行计划:
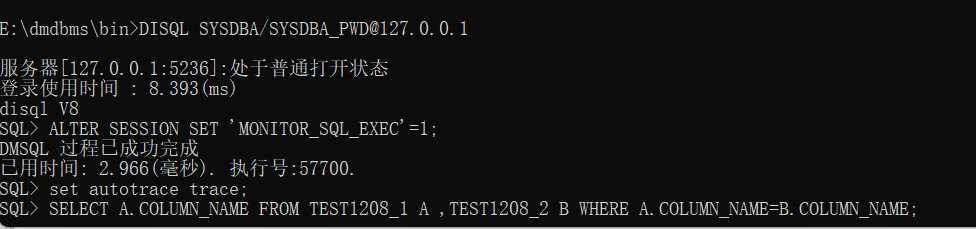
DISQL登录当前用户
E:\dmdbms\bin>DISQL SYSDBA/SYSDBA_PWD@127.0.0.1
然后执行如下命令:
ALTER SESSION SET 'MONITOR_SQL_EXEC'=1;
set autotrace trace;
SELECT A.COLUMN_NAME FROM TEST1208_1 A ,TEST1208_2 B WHERE A.COLUMN_NAME=B.COLUMN_NAME;
最后展示服务端执行计划:
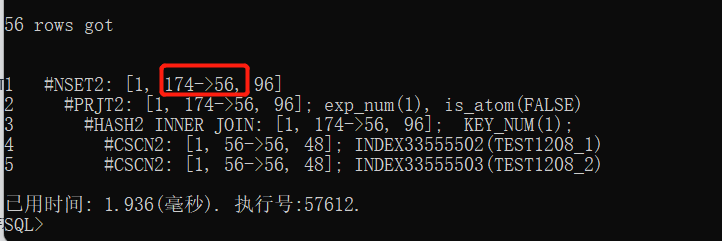
从服务器上的执行计划这里可以看出,实际56,估算174;
步骤3:达梦客户端,我们对这连个表统计信息进行收集;
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(USER,'TEST1208_1',NULL,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DBMS_STATS.GATHER_TABLE_STATS(USER,'TEST1208_2',NULL,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
END;
/
步骤4:客户端F9,我们再来看预估执行计划:
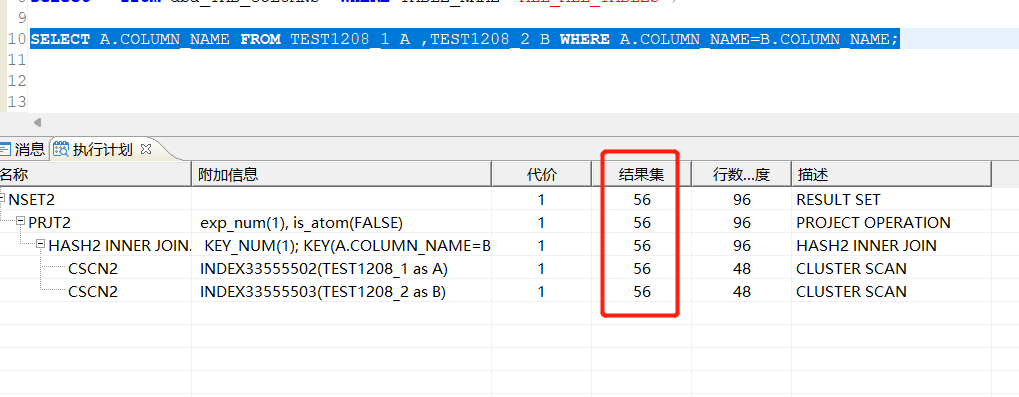
收集统计信息后,预估执行计划是已经正确了;
步骤5:我们重复步骤2看真实SQL计划,那继续再看收集统计信息后执行计划情况:
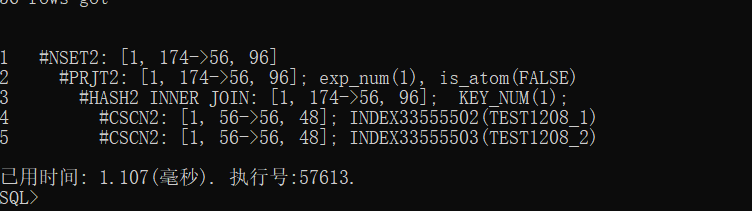
发现并没有变化,这是为什么呢?
我们思考一下就会想到,因为之前在未收集统计信息的时候,我们执行了一遍这个SQL,所以SQL缓存了计划,那遇到这样的情况,我们应该对这个SQL的缓存计划进行清理;
步骤6,清理方法如下:
数值1034139736是通过SELECT * FROM v$cachepln where SQLSTR LIKE '%TEST1208_2 B WHERE A.COLUMN_NAME%';查询出来的;

SP_CLEAR_PLAN_CACHE(1034139736); -对这个SQL语句的缓存计划进行清理;
清理后,我们再来看下它的服务器计划:
步骤7:我们再次重复步骤2登录查询下它的真实执行计划,看如下图,执行计划就更准确了;
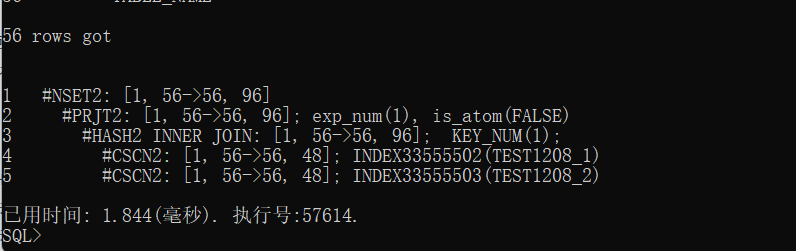
总结:通过如上案例,可以直观的显示收集统计前后的状态,以此案例,可以对照我们实际工作中,在分析SQL的时候,当我们发现数据量差异非常大,而且SQL性能低的时候,我们就应该第一直觉想到该要收集统计信息了,如果结果集相差不大,则性能也不会有太大问题。大家主要关注相差特别大的情况。
3.3、达梦数据库索引创建
合理的索引建立(过多的索引会导致插入的性能下降,我们要根据实际业务情况
合理的建立索引)有助于性能的提升,通常表,记录数300以上,离散度高,而且又是SQL的关联列,这样建立索引,提升查询速度;
例子说明:
没有索引情况下:
TEST_TAB1 有1300万记录,DXID是唯一值;
- 预估执行计划:
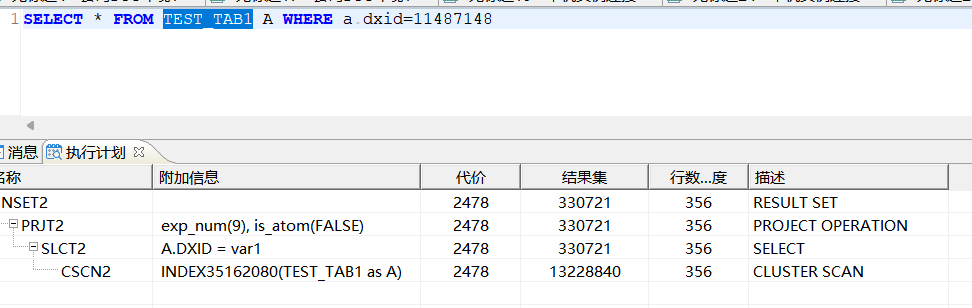
这里显示是4秒18毫秒;
总共1个语句正依次执行...
[执行语句1]:
SELECT * FROM TEST_TAB1 A WHERE a.dxid=11487148
执行成功, 执行耗时4秒 18毫秒. 执行号:108767008
1条语句执行成功执行速度:
- 实际执行计划:
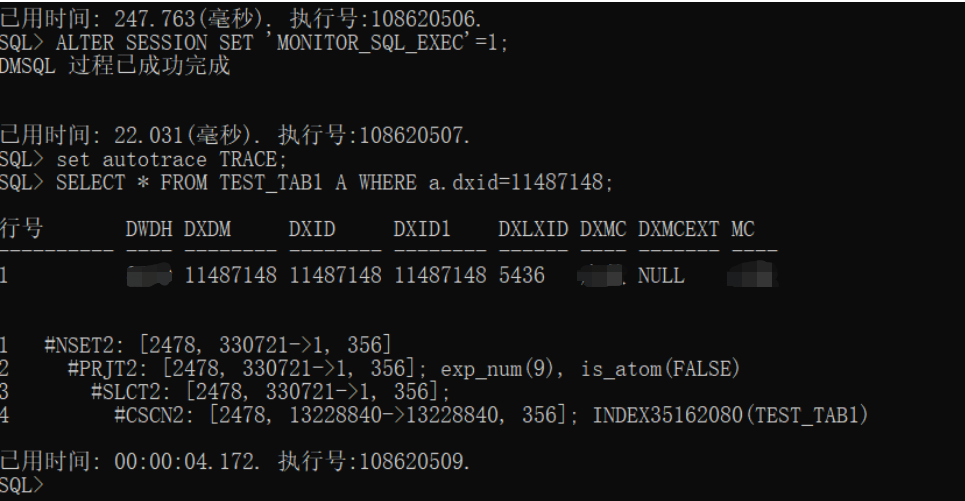
如上是全表扫描,查找一条记录所消耗的时间;
我们对DXID建立索引:
CREATE INDEX IND_TEST_TAB1_DXID ON TEST_TAB1(DXID);
预估执行计划:
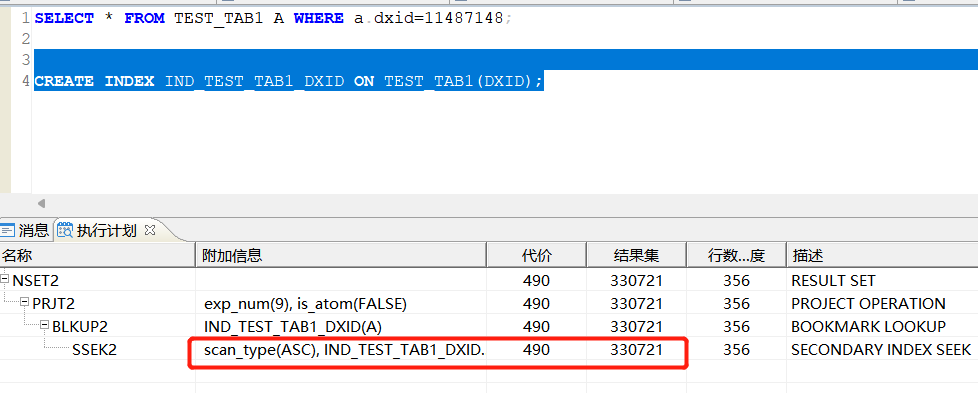
实际执行计划:
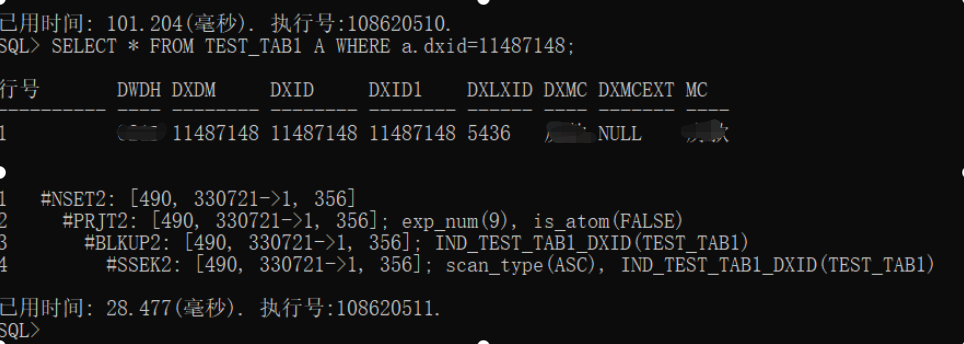
从执行计划上看,SSEK2操作符,已经是二级索引扫描了,说明索引生效了,结果集也是在330721上,而不是13228840,查询速度28毫秒就完成了查询,这里可以说明,加上索引后,速度有140倍的提升;
总共1个语句正依次执行...
[执行语句1]:
SELECT * FROM TEST_TAB1 A WHERE a.dxid=11487148;
执行成功, 执行耗时28毫秒. 执行号:108767013
1条语句执行成功
总结说明:这是一个非常简单的单表过滤SQL语句,主要用例子来说明,不加索引和加索引的查询速度对比,在数据量越大的时候,差别就越大。侧面也可以看到统计信息,全表扫描和二级索引扫描的结果集相差比较大;
3.4、SQL调试工具性能定位思路
存储过程性能问题总是让人头痛,这个时候达梦调试工具就发挥还不错的作用,我们可以直接要调试的存储过程SQL进去,进行单步调试,确定他的性能SQL问题处,然后获取出SQL单独分析处理,这里演示下工具的使用:
- 点击客户端的:绿色小飘虫;
- 再点击执行,在执行:
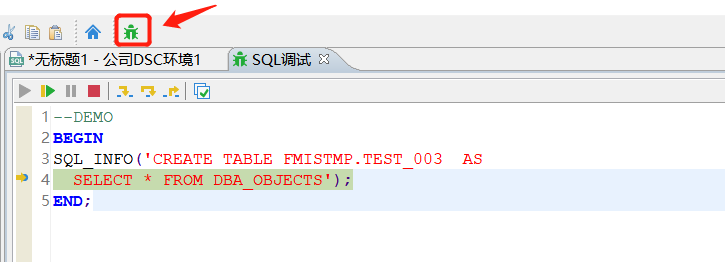
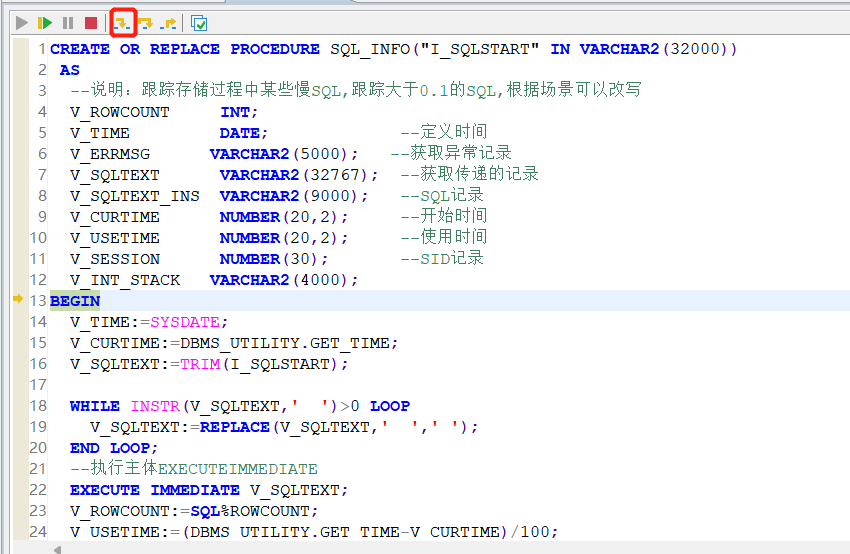
- 点击进入箭头,就进入过程内了,在调试过程中,不断点下一步,则可以真实执行,快速定位下慢的段落了,具体工具使用,在手册中DM8 - SQL Program.pdf中有简单说明,操作方法,如下截图:
DMSQL调试工具已经满足日常的性能调试,平常我们还可以观测变量的输出,这样就可以很完整的看出变量获取异常等问题。对数据库开发人员来说也比较实用。
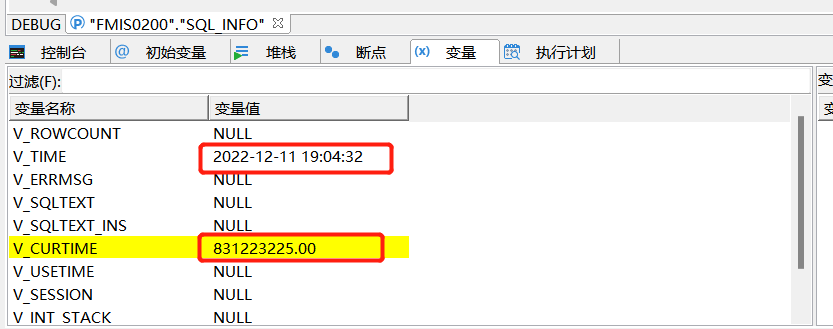
3.5、达梦数据库DM.INI参数调整思路
达梦数据库的参数灵活性非常高,配置的好,它能达到一个整体最优的性能效果,而且跟产品深度融合,复用标准工艺参数,能很好的降本增效,这是我们每一个DBA都要重视的优化方向;
达梦优化参数分类
- 相关文件路径设置参数(控制文件,备份文件,系统文件,临时文件等);
- 实例名
- 内存池以及缓存池
- 线程相关参数
- 查询INI优化类参数(这块跟我们产品特性有比较大关系);
- 检查点参数
- IO优化参数
- 数据库设置类参数
- 兼容类参数(比如兼容Oracle等)
- REDO相关参数
- 事务相关参数
- 监控参数
- ....
达梦数据库参数配置需要考虑如下因素进行:
- 受机器硬件配置影响(CPU,内存根据需要设置);
- 受需要适配的产品影响(以产品和项目实际使用规模等情况为导向来设置,比如大型ERP产品,基础表比较多,字典缓冲区就要调整到合理值,避免设置过小,频繁被淘汰刷新,又例如看整个产品你的SQL分类,HASH类的SQL过多,则需要HJ_BUF_GLOBAL_SIZE ,HJ_BLK_SIZE合理设置,层次查询过多,则需要设置合理的CNNTB_OPT_FLAG;
- 受目标环境影响(生产环境,测试环境)
四、受适配源端数据库影响等;
这里提供一种思路,大量的参数,需要一一去测试验证了解,这就需要非常了解产品的数据库DBA或数据库设计人员,在实践中一一去优化,形成适合自己产品的标准参数工艺;然后复用不断优化,才能深度的和产品融合,这才能真正用好数据库。
达梦有700多个参数,大部分参数,部分参数需要产品特性来调整的,如下总结的需要变动的比较多的参数,部分参数不能照搬,需要根据实际产品进行深度调整,只供参考:
编号 | 原始值 | 参数说明 |
MEMORY_POOL | 80 | 避免频繁向系统申请内存 |
BUFFER | 100 | 总内存的50%,根据机器实际内存调整 |
BUFFER_POOLS | 1 | 减少数据缓存区冲突 |
MAX_BUFFER | 100 | 最大buffer大小,一般调整至机器内存的55%左右,根据机器实际内存调整 |
MAX_SESSIONS | 100 | 最大会话数 |
MAX_SESSION_STATEMENT | 100 | 回话允许打开最大句柄数 |
ENABLE_MONITOR | 2 | 动态监控,上线系统设置为0 |
COMPATIBLE_MODE | 0 | 兼容Oracle参数 |
PWD_POLICY | 2 | 设置系统默认口令策略 |
CNNTB_OPT_FLAG | 0 | 层次查询优化参数。 |
PARALLEL_POLICY | 0 | 多线程策略 |
PARALLEL_THRD_NUM | 10 | 多线程任务 |
MAX_OS_MEMORY | 95 | DM 服务器能使用的最大内存占操作系统物理内存与虚拟内存总和的百分比 |
MEMORY_TARGET | 0 | 共享内存池在扩充到此大小以上后,空闲时收缩回此指定大小,以 M 为单位 |
MEMORY_LEAK_CHE | 0 | 所有内存池的泄漏检查, |
MEMORY_MAGIC_CH | 2 | 对所有内存池的校验。 。 0 : 不开启 |
FAST_POOL_PAGES | 3000 | 快速缓冲区页数 |
FAST_ROLL_PAGES | 1000 | 快速回滚缓冲区页数。 |
RECYCLE_POOLS | 19 | RECYCLE 缓冲区分区数 |
MULTI_PAGE_GET_NUM | 1 | 缓冲区最多一次读取的页面数 |
SORT_BUF_SIZE | 2 | 排序缓存区最大值,以 M 为单位 |
HJ_BUF_GLOBAL_SIZE | 500 | HASH 连接操作符的数据总缓存大小>= HJ_BUF_SIZE ),系统级参数,以兆为单位。 |
HJ_BLK_SIZE | 1 | HASH 连接操作符每次分配缓存( BLK )以兆为单位,必须小于 HJ_BUF_SIZE 。 |
DICT_BUF_SIZE | 5 | 字典缓冲区大小,以兆为单位 |
N_MEM_POOLS | 1 | 内存池的数量 |
LIKE_OPT_FLAG | 7 | LIKE 查询的优化开关 |
VIEW_PULLUP_FLAG | 0 | 是否对视图进行上拉优化,把视图转换为其原始定义,消除视图 |
PARTIAL_JOIN_EVALUATION_FLAG | 1 | 是否对去除重复值操作的下层连接进行转换优 |
USE_FK_REMOVE_T | 1 | 是否利用外键约束消除冗余表。 |
SEL_ITEM_HTAB_FLAG | 0 | 当查询项中有相关子查询时,是否做 HTAB 优化。 |
CASE_WHEN_CVT_I | 5 | 是否将 CASE WHEN THEN ELSE END 语句转换为 IFOPERATOR 函数 |
ORDER_BY_NULLS_FLAG | 0 | ASC 升序排序时,控制 NULL 值返回的位置。 |
IN_LIST_AS_JOIN_KEY | 0 | 搜索多表连接方式时,对于索引连接( INDEX JOIN )的探测, NEXP_IN_LST 表达式类型可以作为多表连接的 KEY 。 |
TOP_ORDER_OPT_FLAG | 0 | 优化带有 TOP 和 ORDER BY 子句的查询, 使得 SORT 操作符可以省略。 |
ENABLE_RQ_TO_NONREF_SPL | 0 | 相关查询表达式转化为非相关查询表达式,目的在于相关查询表达式的执行处理由之前的平坦化方式转化为一行一行处理 |
COMPLEX_VIEW_ME | 0 | 对于复杂视图(一般含有 GROUP 或者集函数等)会执行合并操作, 使得 GROUP 分组操作在连接之后才执行。 |
CNNTB_OPT_FLAG | 0 | 是否使用优化的层次查询执行机制 |
ADAPTIVE_NPLN_FLAG | 3 | 是否启用自适应计划机制,仅 |
VIEW_FILTER_MERGING | 2 | 是否对视图条件进行合并优化以及如何优化 |
CKPT_INTERVAL | 300 | 指定检查点的时间间隔。 |
PK_WITH_CLUSTER | 1 | 在建表语句中指定主关键字时,是否缺省指定为 CLUSTER |
EXPR_N_LEVEL | 200 | 表达式最大嵌套层数 |
TEMP_SIZE | 10 | 默认创建的临时表空间大小,以兆为单位 |
N_PARSE_LEVEL | 100 | 表示对象 PROC 、 VIEW 、 PKG 、 CLASS 的最大 |
CACHE_POOL_SIZE | 20 | SQL 缓冲池大小,以兆为单位 |
STAT_ALL | 0 | 在估算分区表行数时, 控制一些优化。 |
OPTIMIZER_AGGR_GROUPBY_ELIM | 1 | 当对派生视图进行分组查询,且分组项是派生视图分组项的子集时,是否考虑两层分组进行合并。 |
ENHANCED_BEXP_TRANS_GEN | 1 | 是否允许非等值布尔表达式和外连接 ON 条件中的传递闭包 |
RLOG_PARALLEL_ENABLE | 0 | 是否启动并行日志 |
RLOG_APPEND_LOGIC | 0 | 是否启用在日志中记录逻辑操作的功能 |
ENABLE_FLASHBAC | 0 | 是否启用闪回查询 |
UNDO_RETENTION | 90 | 事务提交后回滚页保持时间,单位为秒 |
EXCLUDE_RESERVED_WORDS | 语法解析时,需要去除的保留字列表 | |
CALC_AS_DECIMAL | 0 | 表示将整数与字符或 BINARY 串的所有四则运算都转换为 DEC(0 , 0) 处理 |
ARCH_INI | 0 | 是否启用归档 |
ENABLE_FLASHBACK | 0 | 是否启用闪回查询, 0 :不启用; 1 :启用 |
CASE_WHEN_CVT_IFUN | 5 | CASE_WHEN_转换成IF语句的控制器 |
3.6、跟踪存储过程中的慢SQL思路
当我们拿到一个慢存储过程,有点懵,而且涉及比较复杂的逻辑时候,我们应该如何入手?
拿到存储过程需要优化,我认为是通过一下几个方面进行的:
第一:先要获取存储过程的传递参数,有时候可以找开发人员获取,进行调试,
当开发人员给的参数执行可以调试的存储过程并不慢,那我们应该如何处理呢?
第二:有些存储过程,可能特定的传参才会导致他的缓慢,这个时候,我们应该依靠log_commit工具来分析,通常情况下可以获取到存储过程的传参,而且根据工具分析后可以获取他的执行次数;
第三:存储过程一般都是统计运算类的,一般情况下是可以反复调用的,这个时候,我们一定要确定好,不能盲目执行,避免造成数据错乱,当确定可以调试后,我们就用达梦的客户端调试工具进行调试,我们可以适当在存储过程中打print输出时间,调用完成后,看下在哪一段执行过慢,这样有针对性的优化。
第四:对于有些不能调试的存储过程,我们如何处理呢?这里我在跟踪SQL慢方式中,5.3小节专门有写,我们先手动改好,把改写好有性能的存储过程,更新到仿真测试环境,把可能影响性能的SQL都改写成动态嵌套SQL_INFO中,这样就可以在日志表中获取慢SQL了;
四、辅助性能分析工具
达梦丰富的性能优化辅助工具,能帮助DBA更好的定位问题,给我们日常SQL分析带来了很大的帮助,在预估执行计划不准情况下,我们可以利用性能辅助工具,来处理,举个例子,比如我们存储过程的性能问题,则可以通过ET来看大概性能分布情况,这样就更有效的知道什么操作符造成的。为什么要看实时执行计划?其主要原因还是,预估执行计划可能并不准确。
使用如下工具默认都要检查如下三个参数,否则无法使用:
参数1,2默认开启:
--内存参数DM.INI直接修改,需要重启动生效,默认一般已经开启。
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',1);
SP_SET_PARA_VALUE(1,'MONITOR_TIME',1);
参数3会话级别开启:
----会话参数,建议遇到问题,当前会话开启即可,不建议参数级别开启;
MONITOR_SQL_EXEC为会话级动态参数,可以设置只针对当前会话开启:SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
4.1、达梦ET工具使用
在使用ET工具前检查ENABLE_MONITOR,MONITOR_TIME是否开启,默认配置都是开启状态,我们再检查下MONITOR_SQL_EXEC,如果没有开启,在直接在要执行SQL的会话窗口先执行:SF_SET_SESSION_PARA_VALUE('MONITOR_SQL_EXEC',1);
1、执行了此参数之后,执行我们要跟踪SQL的性能;
执行完成后,点击执行号,就可以弹出分析了;
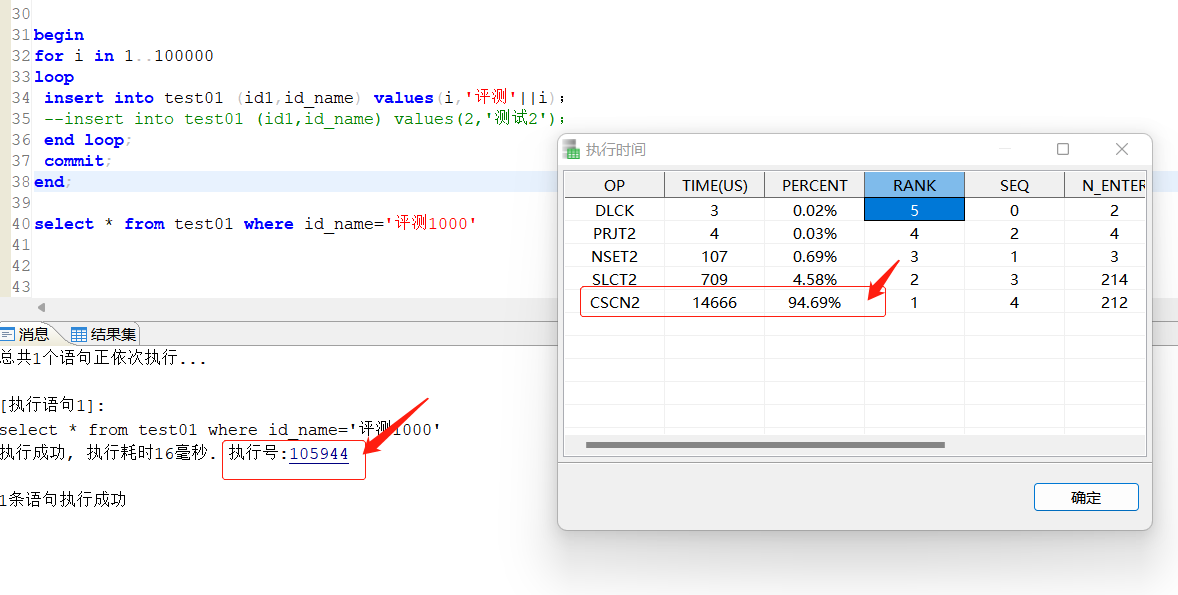
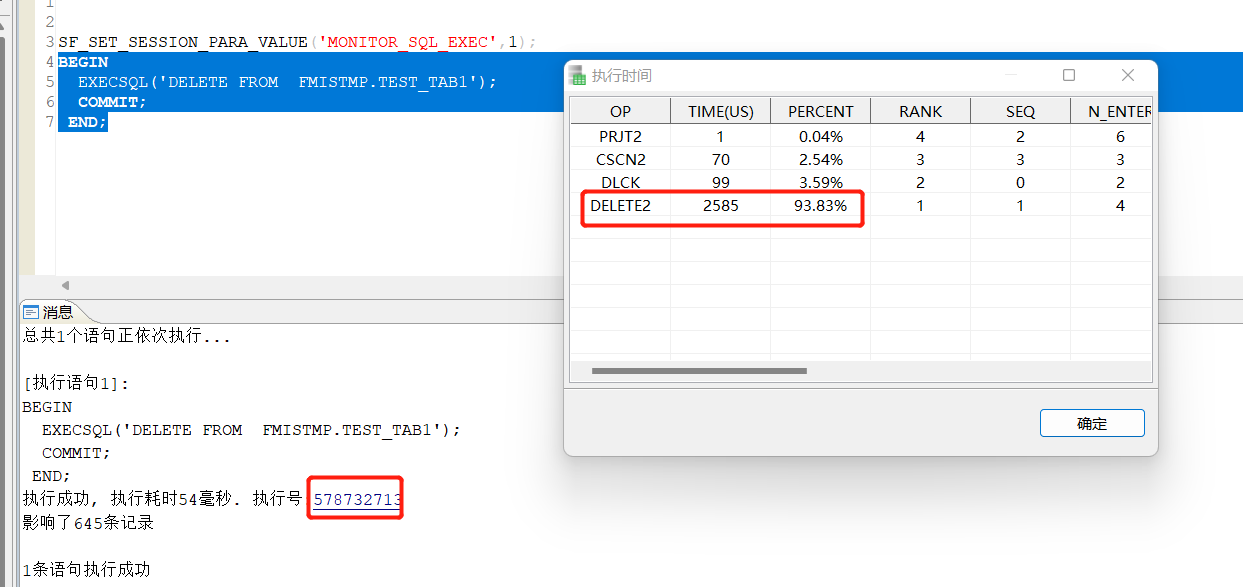
2、ET工具还可以分析存储过程,当存储过程执行比较慢的时候,我们调用后,也可以点击执行号,看他的执行占用备份比,我们通常是看PERCENT百分比,这个通常能代表,哪一个操作符耗时比较长。
用例:
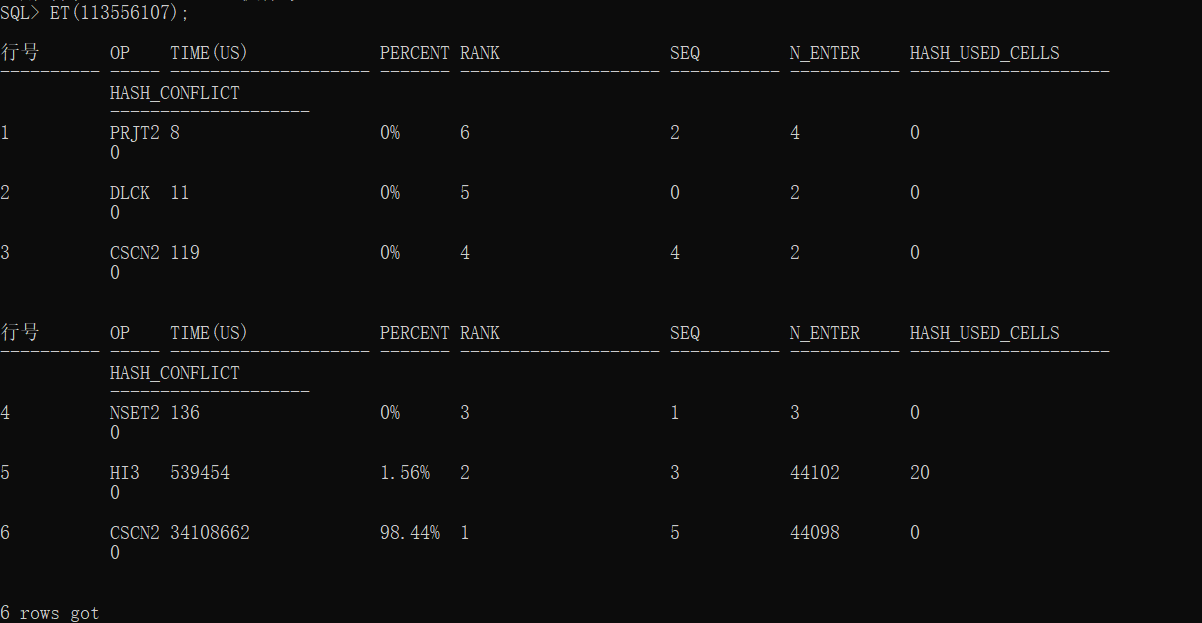
- 当然开启后,在DISQL中也可以使用:
操作方法:ET(执行号);
4.2、v$cachepln中如何获取历史执行计划
v$cachepln保存了历史的SQL缓存计划,平常我们在跟踪问题的时候,也可以分析它的历史缓存计划是否是最优,把历史计划生成出来,此功能对标Oracle的V$SQL_PLAN_STATISTICS_ALL只是获取方式有所差异,今天演示下达梦的获取方法;
演示如下:
--步骤1:我们先查询下v$cachepln,获得我前面执行SQL产生的缓存计划的CACHE_ITEM
我们以此测试SQL语句为例,先执行:
select a.dxid from TEST_TAB1 a,TEST_TAB2 b
where a.dxid=b.dxid;
--再查询
SELECT * FROM v$cachepln WHERE SQLSTR LIKE '%TEST_TAB1%';--140357593086048
--步骤2:再通过调用生成执历史执行计划语句,主要通过步骤1获取得CACHE_ITEM,以及DUMP_FILE指定服务器目录生成历史缓存执行计划信息;
alter session set events 'immediate trace name plndump level 140357593086048, dump_file ''/home/dmdba/140357593086048.log''';
--步骤3:登录服务器在/home/dmdba/140357593086048.log 找到此文件,即可获取历史缓存执行计划信息;
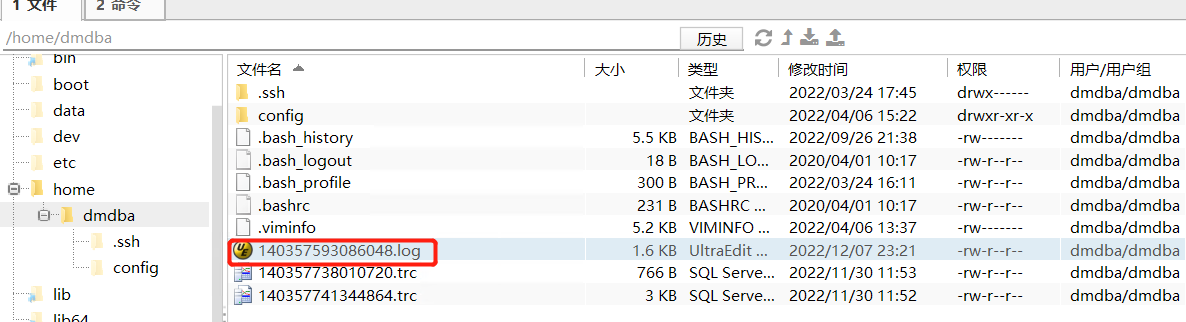
打开140357593086048.log文件
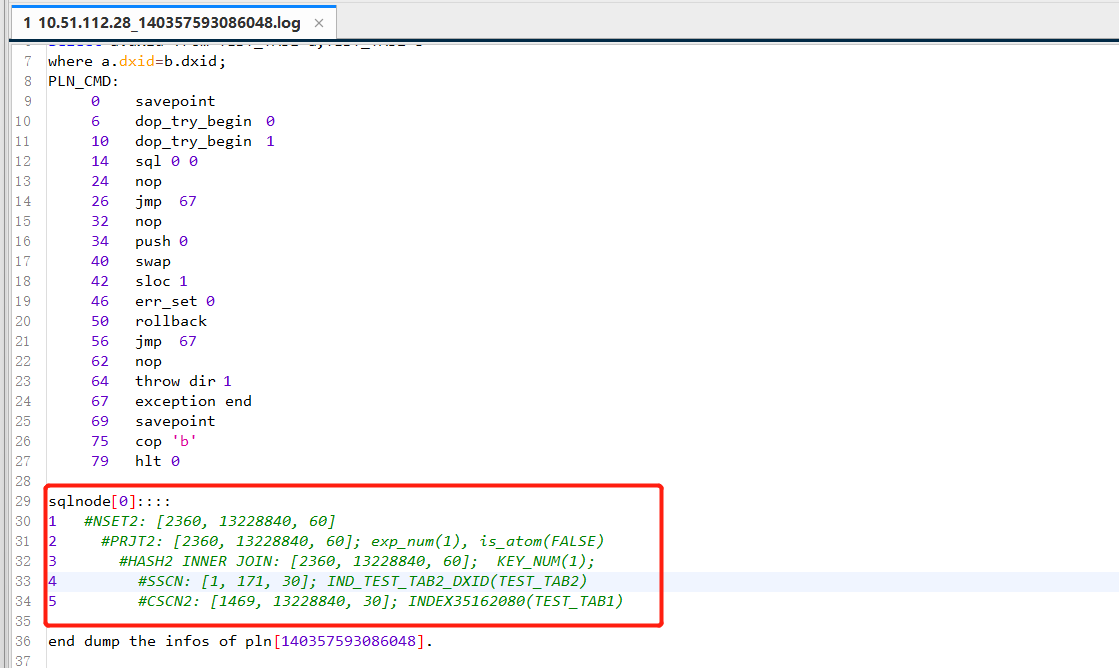
如上就是v$cachepln如何获取历史的缓存执行计划,这个可以结合分析当前SQL语句性能问题,判定缓存计划是否有问题,如果历史的执行计划错误的,我们还可以通过SP_CLEAR_PLAN_CACHE(cache_item)来清理;如果要全部清理,也可以直接使用call SP_CLEAR_PLAN_CACHE();
4.3、实际执行计划和统计信息的跟踪
set autotrace <OFF(默认值) | NL | INDEX | ON|TRACE> ;
参数详解:
“当SET AUTOTRACE OFF 停止 AUTOTRACE 功能,常规执行语句;
当SET AUTOTRACE NL 时,开启 AUTOTRACE 功能,不执行语句,如果执行计划中
有嵌套循环操作,那么打印 NL 操作符的内容;
当 SET AUTOTRACE INDEX(或者 ON)时,开启 AUTOTRACE 功能,不执行语句,如
果有表扫描,那么打印执行计划中表扫描的方式、表名和索引。
当 SET AUTOTRACE TRACE 时,开启 AUTOTRACE 功能,执行语句,打印执行计划。
此功能与服务器 EXPLAIN 语句的区别在于,EXPLAIN 只生成执行计划,并不会真正执行
SQL 语句,因此产生的执行计划有可能不准。而 TRACE 获得的执行计划,是服务器实际执行的计划” ---来自DM8 - Disql.pdf说明手册
预估执行计划:我们看结果集,实际SQL,关联就20条记录,但是结果集显示是:2619310,这个是明显不准确的,这样的前提下,执行性能也是不高的;
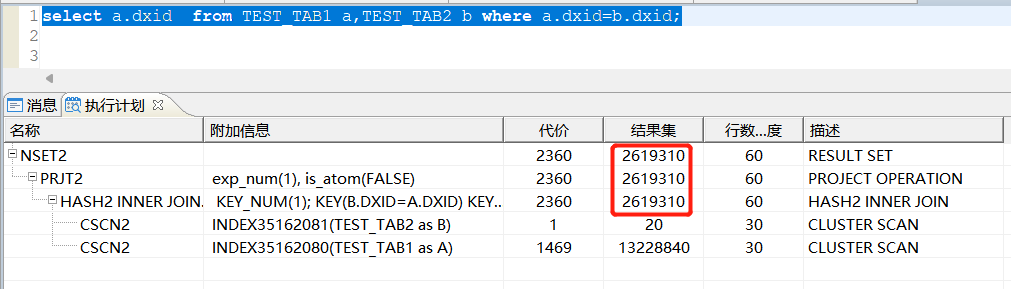
如上预估执行计划不准的情况下,我们需要的是服务器实际的执行计划,所以需要如下
设置SET AUTOTRACE TRACE来获取
实操如下:当登录DISQL后
SQL> ALTER SESSION SET 'MONITOR_SQL_EXEC'=1;
DMSQL 过程已成功完成
已用时间: 174.805(毫秒). 执行号:106510701.
SQL> set autotrace TRACE;
SQL> select a.dxid from TEST_TAB1 a,TEST_TAB2 b where a.dxid=b.dxid;
已用时间: 66.393(毫秒). 执行号:112458304.
SQL> select a.dxid from TEST_TAB1 a,TEST_TAB2 b where a.dxid=b.dxid;
行号 DXID
---------- ---------
1 11487146
.....
20 rows got
1 #NSET2: [2360, 2619310->0, 60]
2 #PRJT2: [2360, 2619310->0, 60]; exp_num(1), is_atom(FALSE)
3 #HASH2 INNER JOIN: [2360, 2619310->0, 60]; KEY_NUM(1);
4 #CSCN2: [1, 20, 30]; INDEX35162081(TEST_TAB2)
5 #CSCN2: [1469, 13228840->11668240, 30]; INDEX35162080(TEST_TAB1)
说明:如上是服务器真实的执行计划,如上例子测试需要,制造SQL统计信息异常,预估执行计划可能是不准确的,但是实际set autotrace TRACE 后就是其真实服务器的执行计划,使用set autotrace TRACE后,我们可以看到带箭头的[2360, 2619310->0, 60]实际计划代价,结果,显示长度,
而预估执行计划应该是这样显示[2360, 2619310, 60]的,即和实际计划对比相差太远;预估计划结果2619310,实际是0,这就明显不对了,以上经验看,是未收集统计信息导致,
收集后计划后,记录数就更准确了。

五、跟踪慢SQL常用方式
5.1、慢SQL实时抓取
达梦数据库开启参数后,SQL实时执行就可以抓取了,通过简单SQL就可以抓取,非常方便,通常在运行过程中,遇到用户反馈系统比较慢的时候,我们都可以先用此SQL查询下,如果加压大量SQL长时间未处理,而且都是重复的,则有2个可能性,
第1种可能性,这个是频繁SQL,但是遇到了某个慢SQL导致数据库整体事务处理能下降了;
第2种可能性,就是本身此SQL就有问题,这样给我们快速响应数据库问题,带来了
实时间慢SQL抓取语句:
Select
'sP_close_session('
||sess_id
||');' ,
datediff(ss, last_recv_time, sysdate) ss ,
cast(sf_get_session_sql(sess_id) as varchar) sql,
*
from
v$sessions
where
state='ACTIVE'
order by
last_send_time;
说明:拼接了结束会话的sP_close_session,可以快速导出结束异常会话,如果时间无法获取
则要v$dm_ini检查下ENABLE_MONITOR是否开启(1:打开;0:关闭),否则时间获取不到,就无法统计时间了;
5.2、达梦日志分析工具
log_commit分析工具使用,主要用于分析达梦的SQL日志,从中找到历史的慢SQL,属于一种事后分析的工具,在实际生产应用过程中也有比较重要的作用;
- 可以统计到SQL执行次数;
- 可以筛选跟踪历史慢SQL;
因为此工具迭代应该比较块,所以我这里只讲思路,实践过程中,希望同学向达梦技获取最新版本操作即可;
操作步骤:
一、把Dmlog_DM_8.10.jar 拷贝到本地达梦数据库目录:E:\dmdbms\jdk\bin
保证JDK兼容
二、首选要获取下你要分析的LOG日志,通常开启日志方法为:
三、将日志COPY到你要分析的机器上,我这边放在E:\dmdbms\jdk\bin\test1
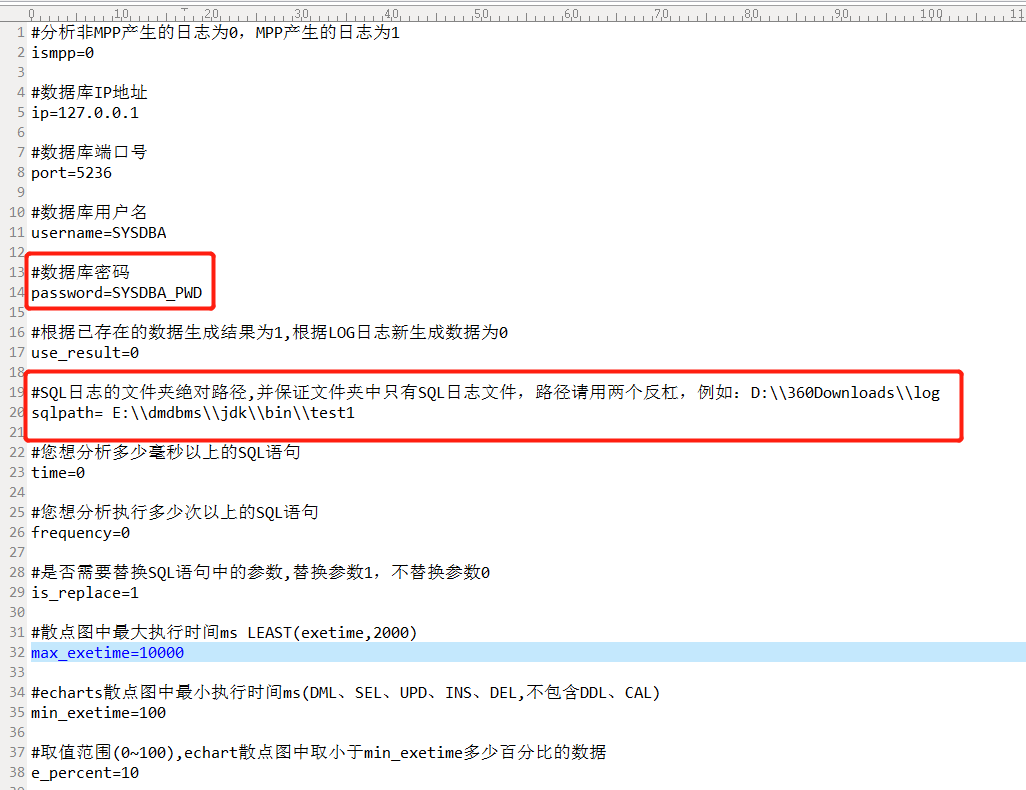
四、配置dmlog.properties
这里是配置你本地数据库的地址,配置dmlog.properties,注意保证文件夹中只有SQL日志文件,格式如截图所示:
配置文件中注意填写,本地IP:端口,用户密码,待分析的文件路径,分析执行多少毫秒的SQL,分析执行多少次的SQL;是否要替换参数,默认建议是替换,目前我只用到这些,工具还其它丰富的功能就待小伙伴去挖掘了。
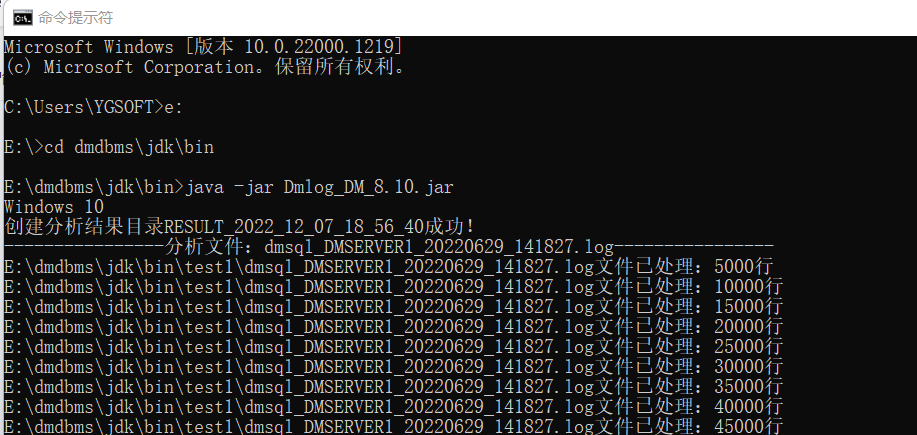
五、进入E:\dmdbms\jdk\bin\java -jar Dmlog_DM_8.10.jar
数据库版本尽量保持跟获取日志的库一致,包含页大小也需要一致,否则解析会有问题
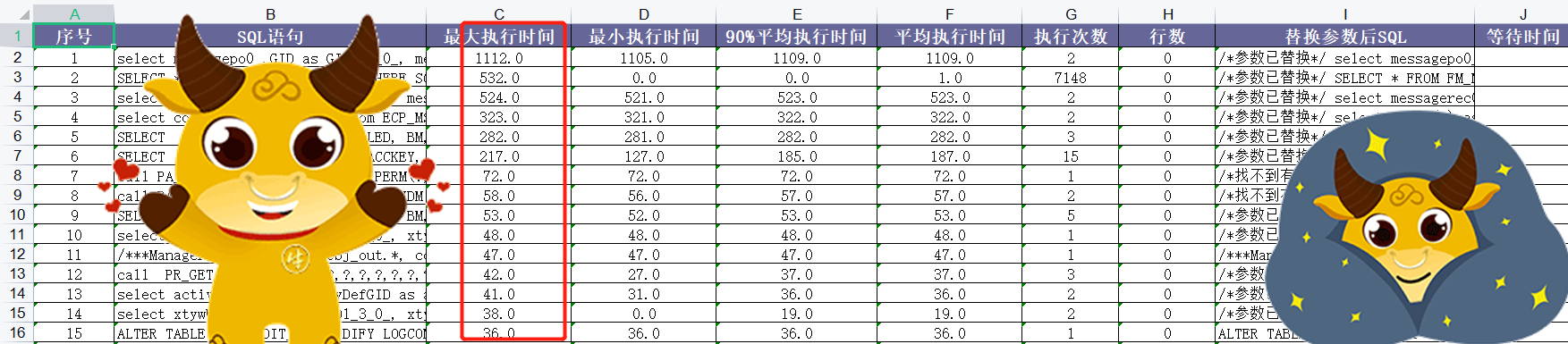
- 解析后在当前目录生成了RESULT_2022_12_07_18_56_40文件,工具生成的内容比较丰富,平常我们常分析的是输出的2个Excel,打开2个输出表格如下:
more_than_0_ms_log_result.xls 按最大时间排序:
more_than_0_times_log_result.xls 按执行次数排序:
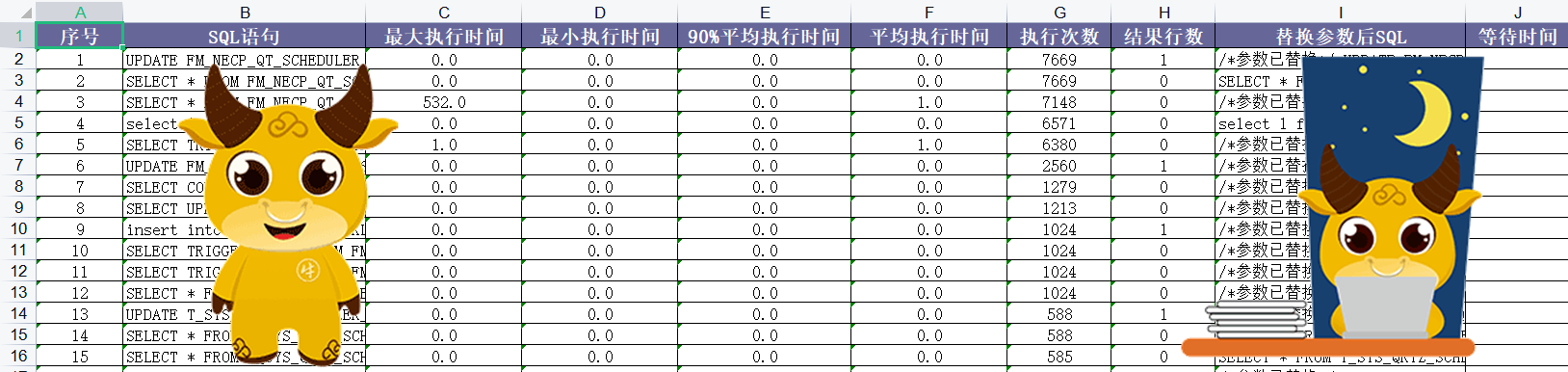
以上SQL解析后,配置参数解析后,大部分参数也解析出来了,接下来针对慢SQL,直接拿出来分析优化即可,在工作中还是挺有帮助的。
5.3、SQL_INFO跟踪性能语句
通常存储过程慢SQL并不好抓取,在不是很好抓取的时候,我们可以采用性能分析工具里说的达梦DEBUG工具,但是有些无法调试的,我们怎么办呢?这个时候,我们可以改写待跟踪的存储过程,在把要跟踪的SQL嵌套到SQL_INFO中,这样有性能的SQL就可以写入日志表SQL_LOG了;实践中,改写存储过程需要有一定数据库开发能力的小伙伴来处理,我这里提供的是一种跟踪的性能方式;
--代码如下:
--创建性能跟踪表
--DROP TABLE SQL_LOG;
CREATE TABLE SQL_LOG
(
GID VARCHAR2(100), --GUID
"USER_NAME" VARCHAR2(32) , --当前用户
"START_TIME" TIMESTAMP(0), --SQL开始执行时间
"END_TIME" TIMESTAMP(0) , --SQL执行结束时间
"SQL_TEXT" VARCHAR2(4000),--SQL执行语句
"ROW_COUNT" NUMBER(15) , --记录数
"LOG_TYPE" VARCHAR2(20) , --完成是SUCCESSFUL,报错是FAILED
"SESSION_ID" NUMBER(38, 0) , --会话ID
"LOG_DETAIL" VARCHAR2(2000), --错误信息
"INT_STACK" VARCHAR2(4000), ----堆栈信息
"SQL_TIMES" NUMBER(10, 2) --记录SQL执行时间
);
CREATE INDEX IND_SQL_LOG_SQLTEXT ON SQL_LOG(SQL_TEXT);
/
--创建跟踪过程
CREATE OR REPLACE PROCEDURE SQL_INFO("I_SQLSTART" IN VARCHAR2(32000))
AS
--说明:跟踪存储过程中某些慢SQL,跟踪大于0.1的SQL,根据场景可以改写
V_ROWCOUNT INT;
V_TIME DATE; --定义时间
V_ERRMSG VARCHAR2(5000); --获取异常记录
V_SQLTEXT VARCHAR2(32767); --获取传递的记录
V_SQLTEXT_INS VARCHAR2(9000); --SQL记录
V_CURTIME NUMBER(20,2); --开始时间
V_USETIME NUMBER(20,2); --使用时间
V_SESSION NUMBER(30); --SID记录
V_INT_STACK VARCHAR2(4000);
BEGIN
V_TIME:=SYSDATE;
V_CURTIME:=DBMS_UTILITY.GET_TIME;
V_SQLTEXT:=TRIM(I_SQLSTART);
WHILE INSTR(V_SQLTEXT,' ')>0 LOOP
V_SQLTEXT:=REPLACE(V_SQLTEXT,' ',' ');
END LOOP;
--执行主体EXECUTEIMMEDIATE
EXECUTE IMMEDIATE V_SQLTEXT;
V_ROWCOUNT:=SQL%ROWCOUNT;
V_USETIME:=(DBMS_UTILITY.GET_TIME-V_CURTIME)/100;
--这里调整多少秒的记录写入到SQL_LOG日志表中,这个可以嵌套到性能表里
IF V_USETIME>=0.1 THEN
V_SQLTEXT_INS:=TRIM(SUBSTRB(V_SQLTEXT,1,4000));--达梦单列VARCHAR2可以存储9000以上,如果SQL够长,我们可以改大些
V_SESSION:=SESSID;--会话SID
V_INT_STACK:=DBMS_UTILITY.FORMAT_CALL_STACK;
INSERT INTO SQL_LOG (GID,USER_NAME,START_TIME,END_TIME,SQL_TEXT,ROW_COUNT,LOG_TYPE,SESSION_ID,INT_STACK,SQL_TIMES)
VALUES (GUID(),USER,V_TIME,SYSDATE,V_SQLTEXT_INS,V_ROWCOUNT,'SUCCESSFUL',V_SESSION,V_INT_STACK,V_USETIME);
END IF;
EXCEPTION
--如果SQL中执行异常,也会写SQL_LOG中,方便我们分析错误语句
WHEN OTHERS THEN
ROLLBACK;
V_ERRMSG:=SQLERRM(SQLCODE);
V_INT_STACK:=DBMS_UTILITY.FORMAT_CALL_STACK;
V_SQLTEXT_INS:=TRIM(SUBSTRB(I_SQLSTART,1,4000));--达梦VARCHAR2可以存储9000以上,如果SQL够长,我们可以改大些
V_USETIME:=(DBMS_UTILITY.GET_TIME-V_CURTIME)/100;
INSERT INTO SQL_LOG (GID,USER_NAME,START_TIME,END_TIME,SQL_TEXT,LOG_TYPE,SESSION_ID,LOG_DETAIL,INT_STACK,SQL_TIMES)
VALUES (GUID(),USER,V_TIME,SYSDATE,V_SQLTEXT_INS,'FAILED',V_SESSION,V_ERRMSG,V_INT_STACK,V_USETIME);
COMMIT;
RAISE;
END SQL_INFO;
样例演示:
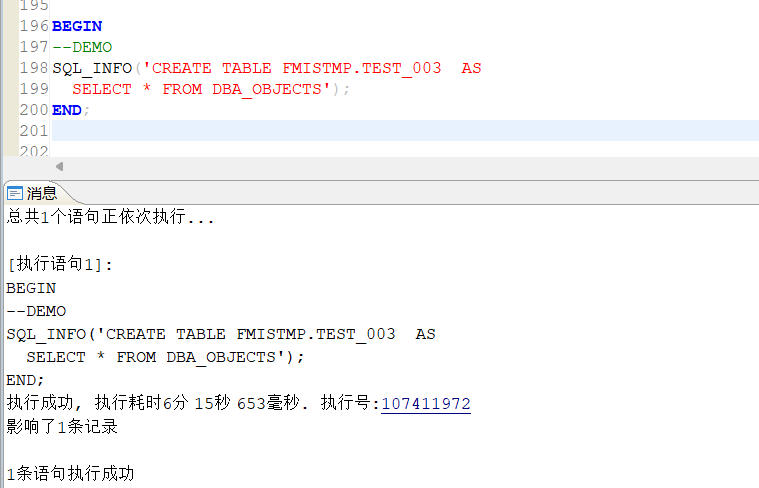
--查看跟踪到执行这个DEMO语句的时间:
BEGIN
--DEMO
SQL_INFO('CREATE TABLE FMISTMP.TEST_003 AS
SELECT * FROM DBA_OBJECTS');
END;
SELECT * FROM SQL_LOG WHERE SQL_TEXT LIKE 'CREATE TABLE FMISTMP.TEST_003%'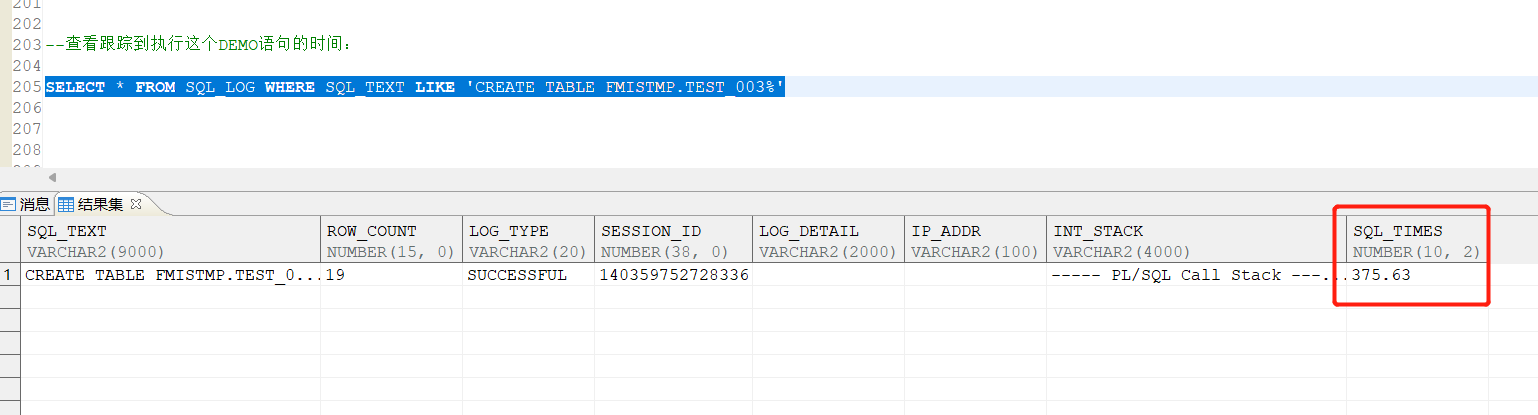
以上只是举例一个简单的创建备份表进行演示,实际上存储过程中很多动态拼接语句,都是可以放到SQL_INFO中,然后在执行过程中就可以跟踪到他的SQL是那一句慢了。
六、江湖救急SF_INJECT_HINT应用
在投产系统中,偶尔出现某个SQL性能问题,当SQL是应用代码发出的时候,通过DBA分析后,需要加hint解决,这个是时候苦于无法立即更新代码,加之系统又在运行中,则通过SF_INJECT_HINT方法急救非常有效,而我们在实际应用中,也是多次通过此函数解决了当前系统的性能瓶颈。使用SF_INJECT_HINT需要开启DM.INI的ENABLE_INJECT_HINT 需设置为 1,否则无法使用,这个需要大家关注;
经过实践总结,根据系统特性,需要加上hint的有如下2大类型的SQL语句,比较常见;
通常会话表,在Oracle系统中也是需要Hint来辅助,否则也有一定的性能瓶颈;
- 会话表关联查询,执行计划无法估算数据情况下,我们需要
新增 /* + NO_USE_CVT_VAR,ENABLE_INDEX_JOIN(0)*/ 这类HINT操作,但是实际上还是要看执行计划了;
- 二类是层次查询,其实我们看到数据库指定的CNNTB_OPT_FLAG并不能满足所有条件下的SQL,通常在DM.INI中,我们是设置的2,但是即使这样,在设计过程中,也需要根据有性能的SQL进行处理,通常我们需要加/*+CNNTB_OPT_FLAG (X)*/,这个CNNTB_OPT_FLAG的X 数值是要根据我们对SQL执行计划优化后得出,并不是直接套用。
目前CNNTB_OPT_FLAG 支持的参数有:1、2、4、8、16,31;
6.1、新增注入HINT方法
SF_INJECT_HINT(
'SQL语句',
'ENABLE_INDEX_JOIN(0)',
'HINT_1207_1',
'这是一条对莫某功能语句的优化',TRUE,TRUE
);
参数说明:
第一个参数:SQL语句这个我们数据库有性能的语句,这个语句贴到函数中,请勿格式化,也请勿前后带有空格,否则不匹配;
第二个参数:ENABLE_INDEX_JOIN(0),这里填写需要新增的hint,直接填写合适的hint即可,无需加/*+ */这类标识符,通常我们写在SQL中才需要这样加;
第三个参数:HINT_1207_1这个是只是一个NAME名称;
第四个参数:可以理解成一种注解;
第五个参数:是否理解生效,我们一般救急肯定就设置TRUE了
第六个参数:匹配规则为精准匹配或模糊匹配,设置NULL和TRUE是模糊匹配,否则FALSE 或缺省时精确匹配,如果SQL明确建议精确匹配;
6.2、删除注入HINT方法;
SF_DEINJECT_HINT('HINT_1207_1'');
6.3、注入SQL HINT实操
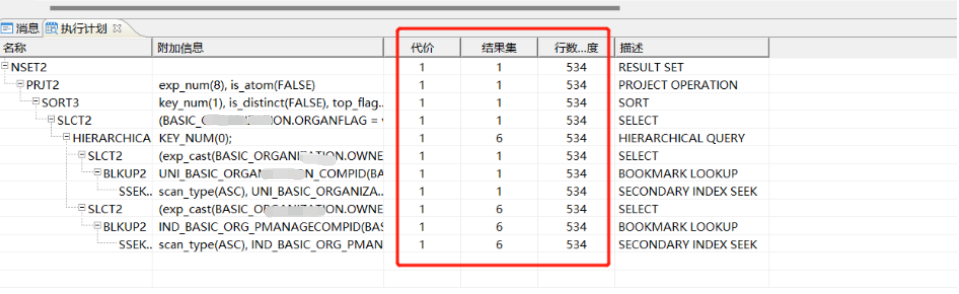
某集团二级单位收到同事反馈,有个SQL执行非常慢,DSC双节点,已经积压了800多活动会话,情况比较紧急,当接到通知,我首先是快速登录客户端,通过慢SQL实时抓取方式,获取到了大量的积压SQL,看是否有异常的SQL,发现大量积压的SQL,是一个层次查询,然后在客户端执行下预估执行计划;
看预估执行计划(如下图),明显估算不准确;
及时检查了当前系统V$DM_INI select * from v$dm_ini where para_name='CNNTB_OPT_FLAG' --发现是2;
--DM_INI参数的值2(2代表优化器自动决定是否使用)
SELECT /*+ CNNTB_OPT_FLAG(2)*/
COXXID ,
COMPXXDE ,
PCOXXID ,
COMPXXME ,
ORGTYPEXXDE,
DCXXDE ,
STIME ,
STOPXXAG
FROM
BASIC_ORGANIXXXXON
WHERE
OWNXXID = -1
AND AXXID = -1
AND NVL(STOPXXAG, 0) =0
AND ORGANXXAG =1 START
WITH COXXID = '3000'
AND OWNXXID = -1
AND AXXID = -1 CONNECT BY PRIOR COXXID = PMANAGECOXXID
AND OWNXXID = -1
AND AXXID = -1
ORDER BY
ORG_SXXT
再通过真实服务器缓存计划发现预估和实际相差比较大;
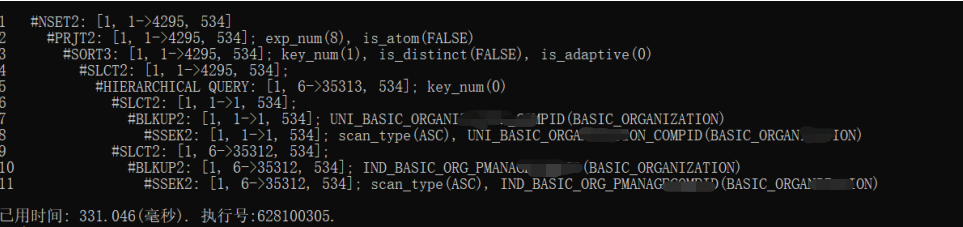
增加hint后/*+ CNNTB_OPT_FLAG(16)*/执行看:
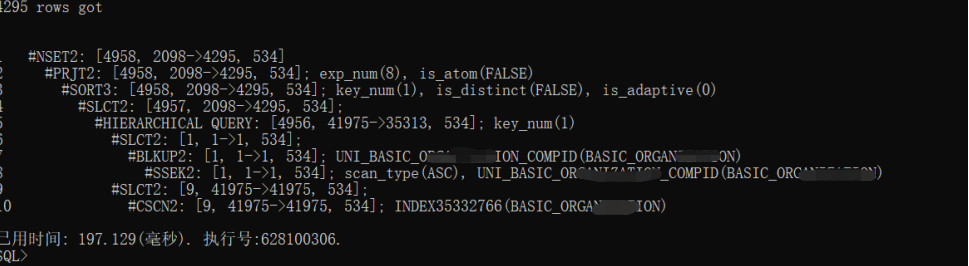
发现通过/*+ CNNTB_OPT_FLAG(16)*/ 更准确,然后快速通过注入HINT解决:
SF_INJECT_HINT(
'SELECT COXXID , COMPXXDE , PCOXXID, COMPXXME,ORGTYPEXXDE,DCXXDE,STIME,STOPXXAG FROM BASIC_ORGANIXXXXON WHERE OWNXXID= ? AND AXXID= ? AND NVL(STOPXXAG,0) =? AND ORGANXXAG=? START WITH COXXID = ? AND OWNXXID= ? AND AXXID= ? CONNECT BY PRIOR COXXID = PMANAGECOXXID AND OWNXXID= ? AND AXXID= ? ORDER BY ORG_SXXT ',
'CNNTB_OPT_FLAG(16)',
'HINT_1207_1',
NULL,TRUE,TRUE
);
--缓存hint添加,SQL请勿格式化,否则无法命中,详细可以看达梦SQL手册详解。
性能压测工具适配达梦使用
工作中,并发SQL测试,是我们日常的一个重要工作项,单个SQL执行比较快,对一些高频的SQL,我们需要进一步的做性能压测,来满足投产需要;
压测达梦数据库SQL,工作中主要用到Apache jmeter工具
针对 jmeter 5.4.1版本,压测工具需要jdk18以上运行环境
7.1、jmeter适配驱动包配置等
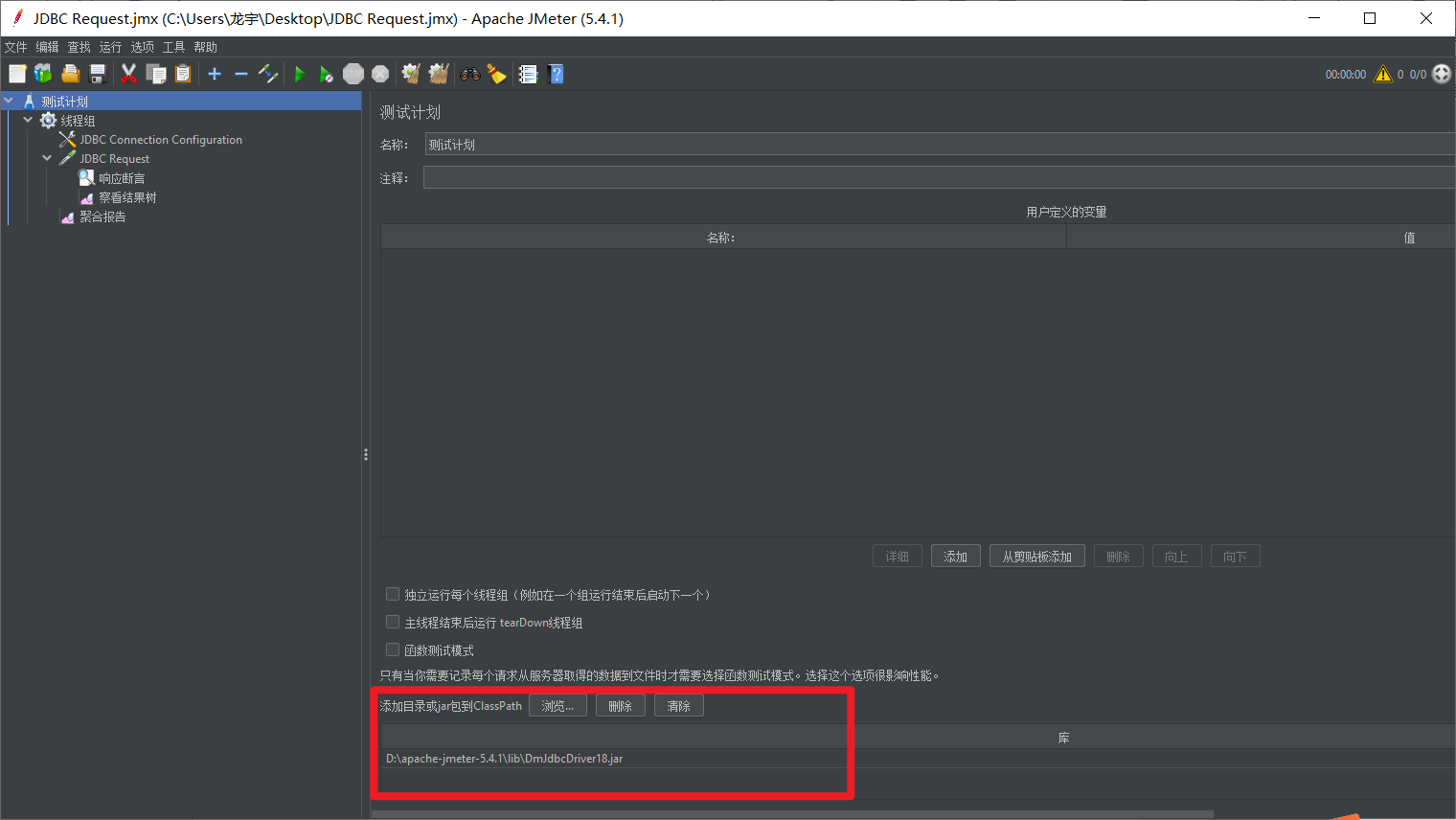
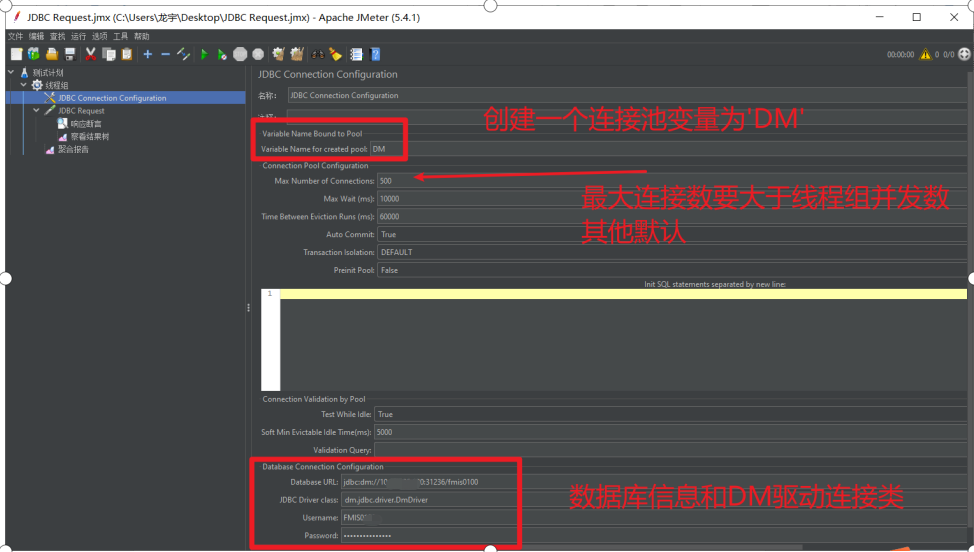
压测SQL,以达梦为例,需在jmeter安装目录的lib目录下放入DM驱动包;
首先在jmeter测试计划里添加我们DM驱动jar包
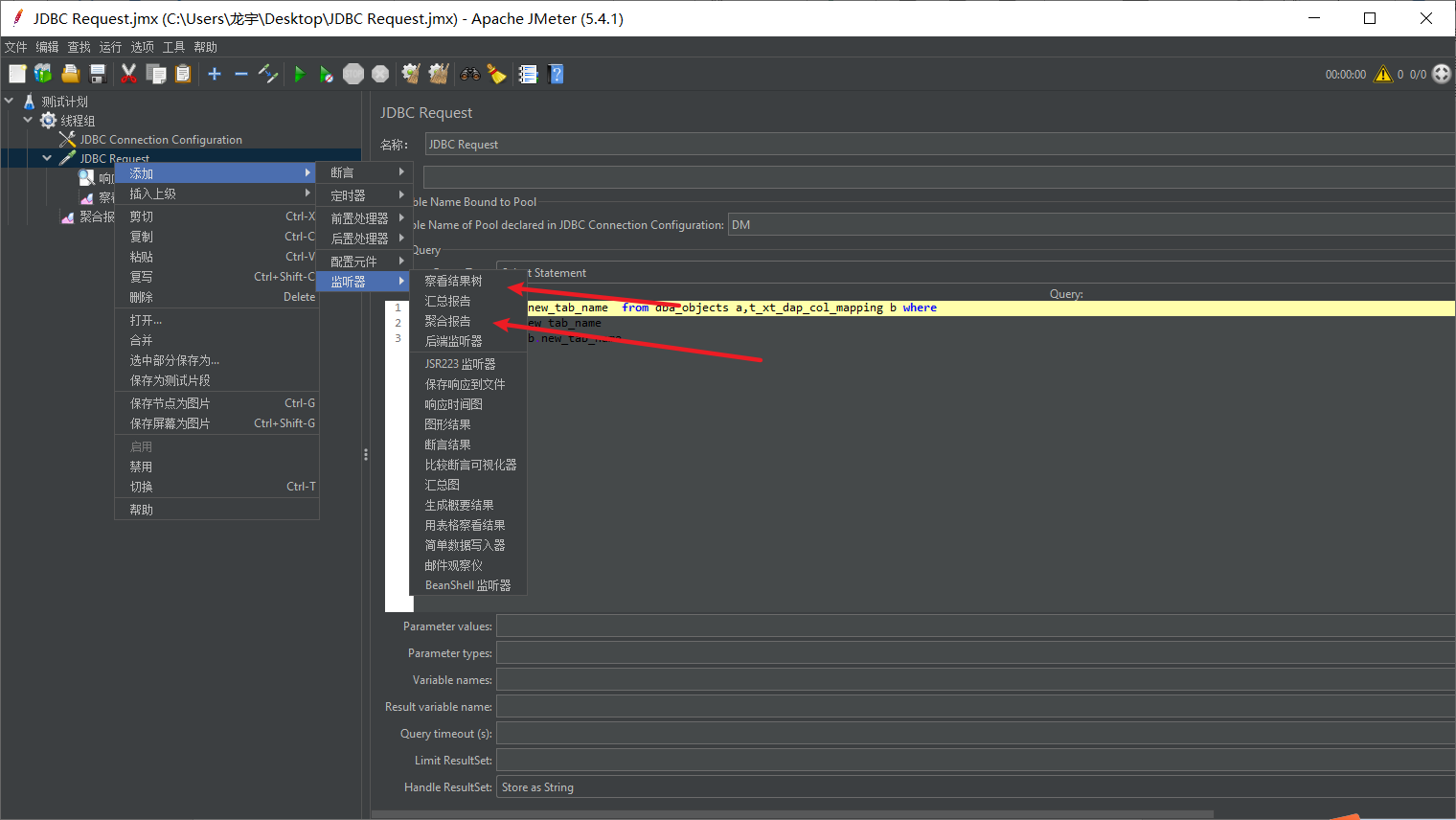
添加一个JDBC连接池配置组件和JDBC取样器
JDBC连接池配置:
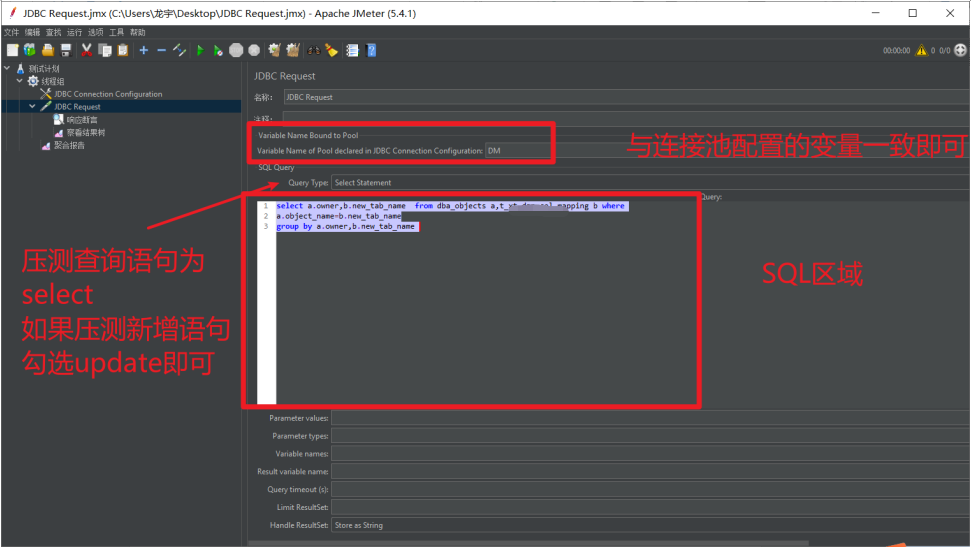
JDBC取样器配置:
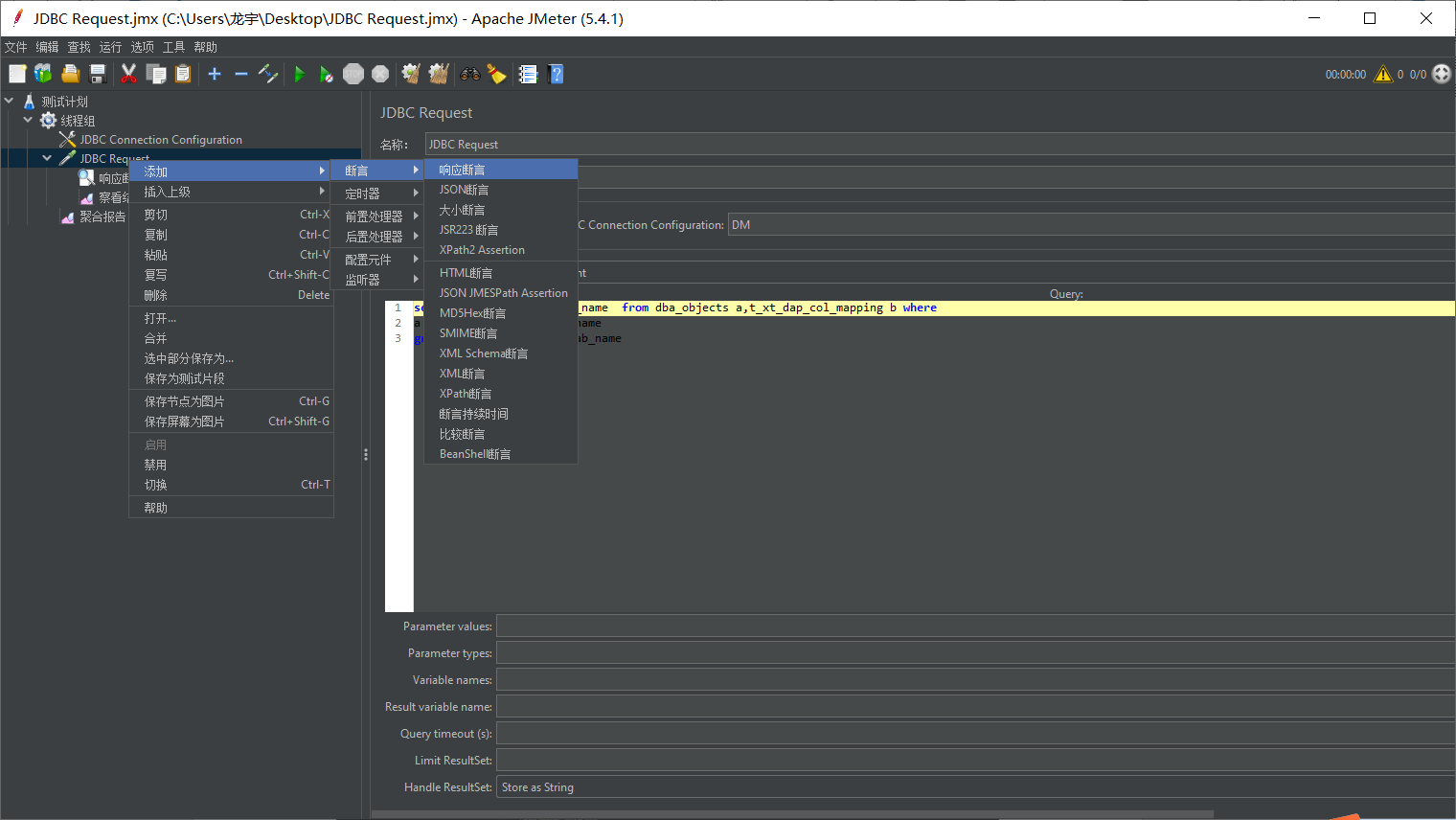
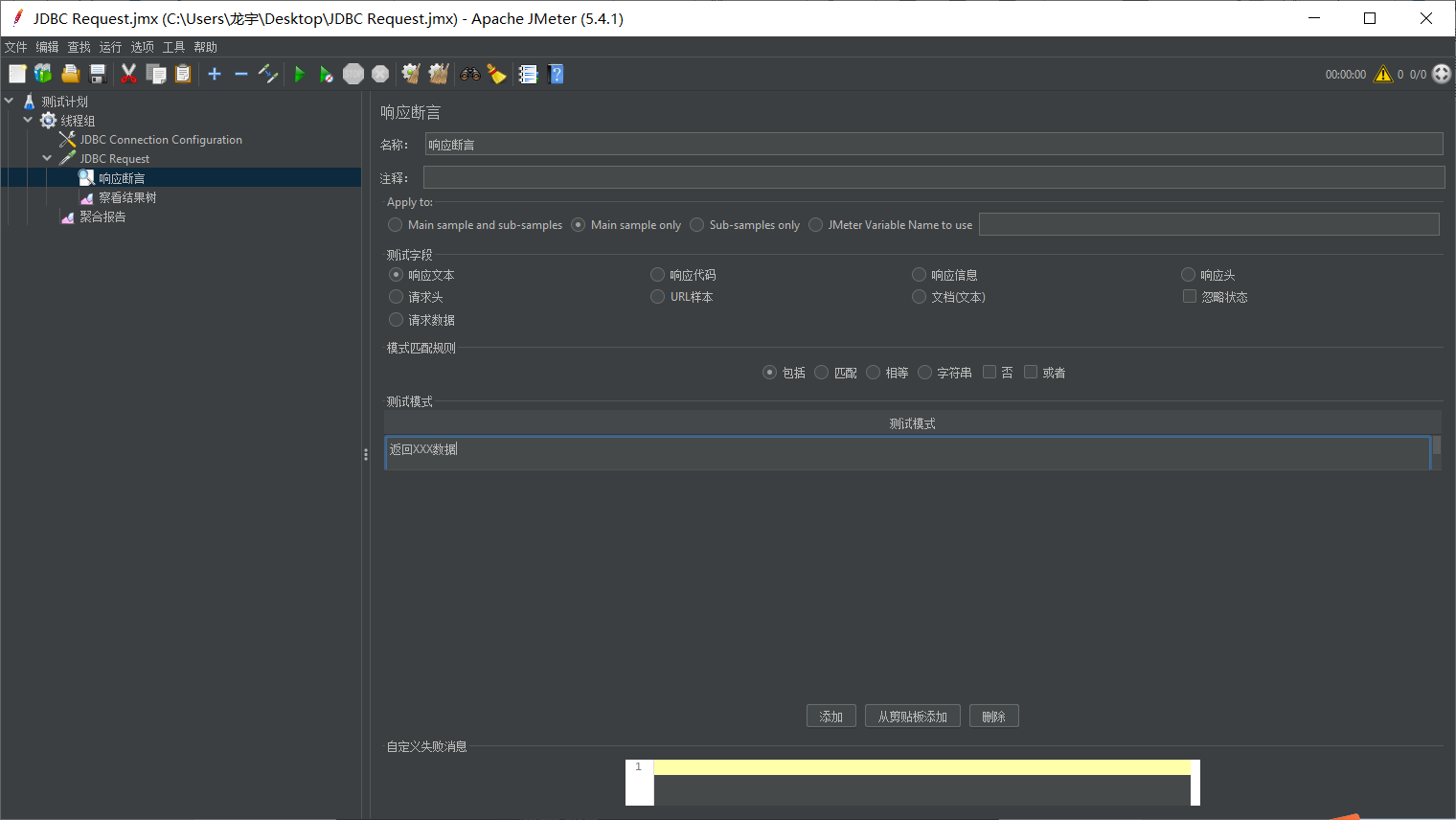
添加断言(断言是以字符串形式去判断)
添加聚合报告和结果树
Jmeter线程组设置
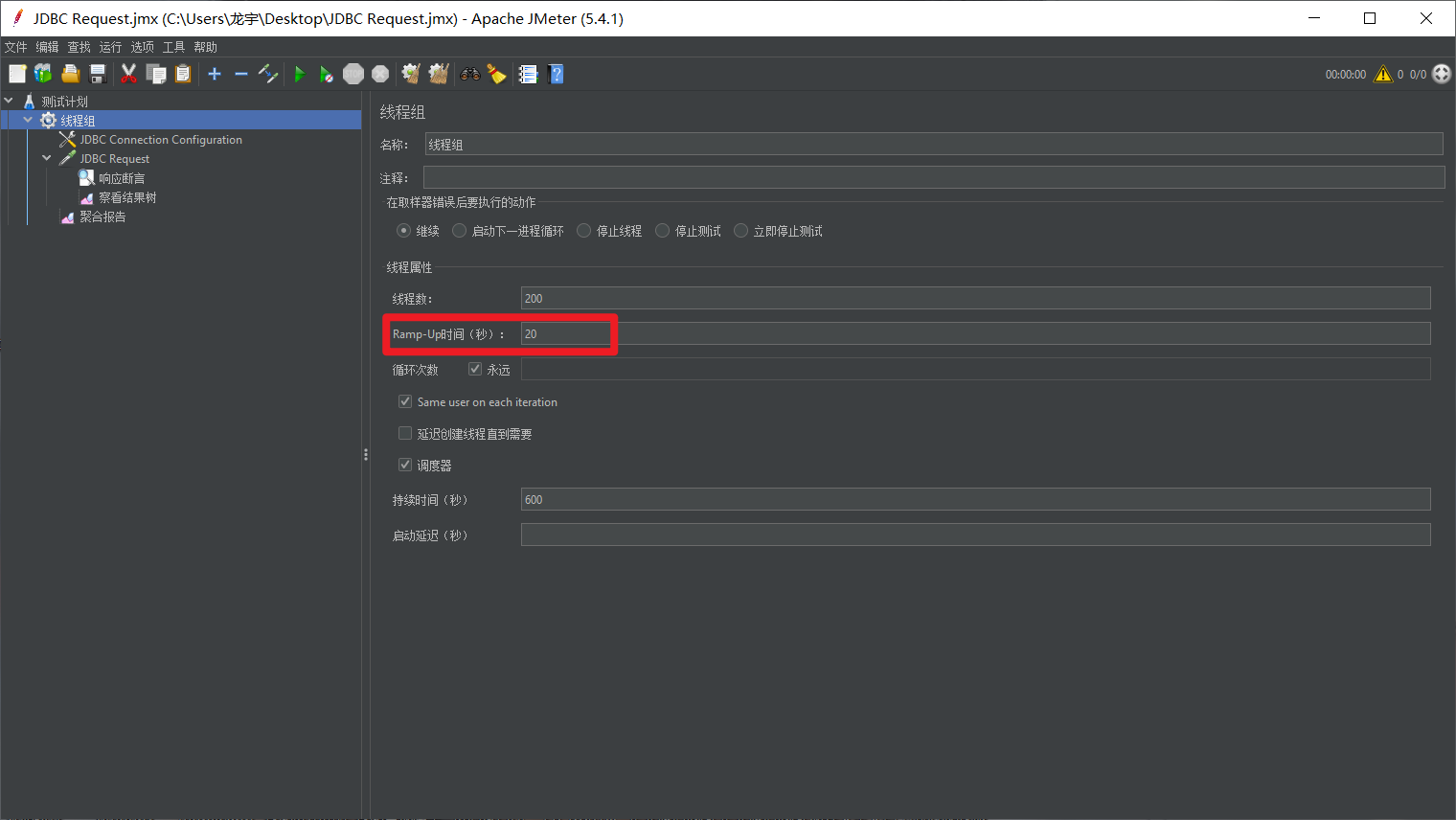
调度器勾选后为运行多久,值得注意的是ramp-up这个值,意思为200个线程要在20秒内去发起请求,为了避免并发下第一次涌入大量的请求(服务器压力大),这个值不建议太小,以日常工作为例,1秒加载10个线程,第一次不要涌入大量请求,循环跑起来后,第一个线程发起请求-服务器响应返回客户端,继续发起请求,第二个第三个线程以此类推,其实每个线程都是在执行自己的操作,发起-响应;
7.2、压测报告
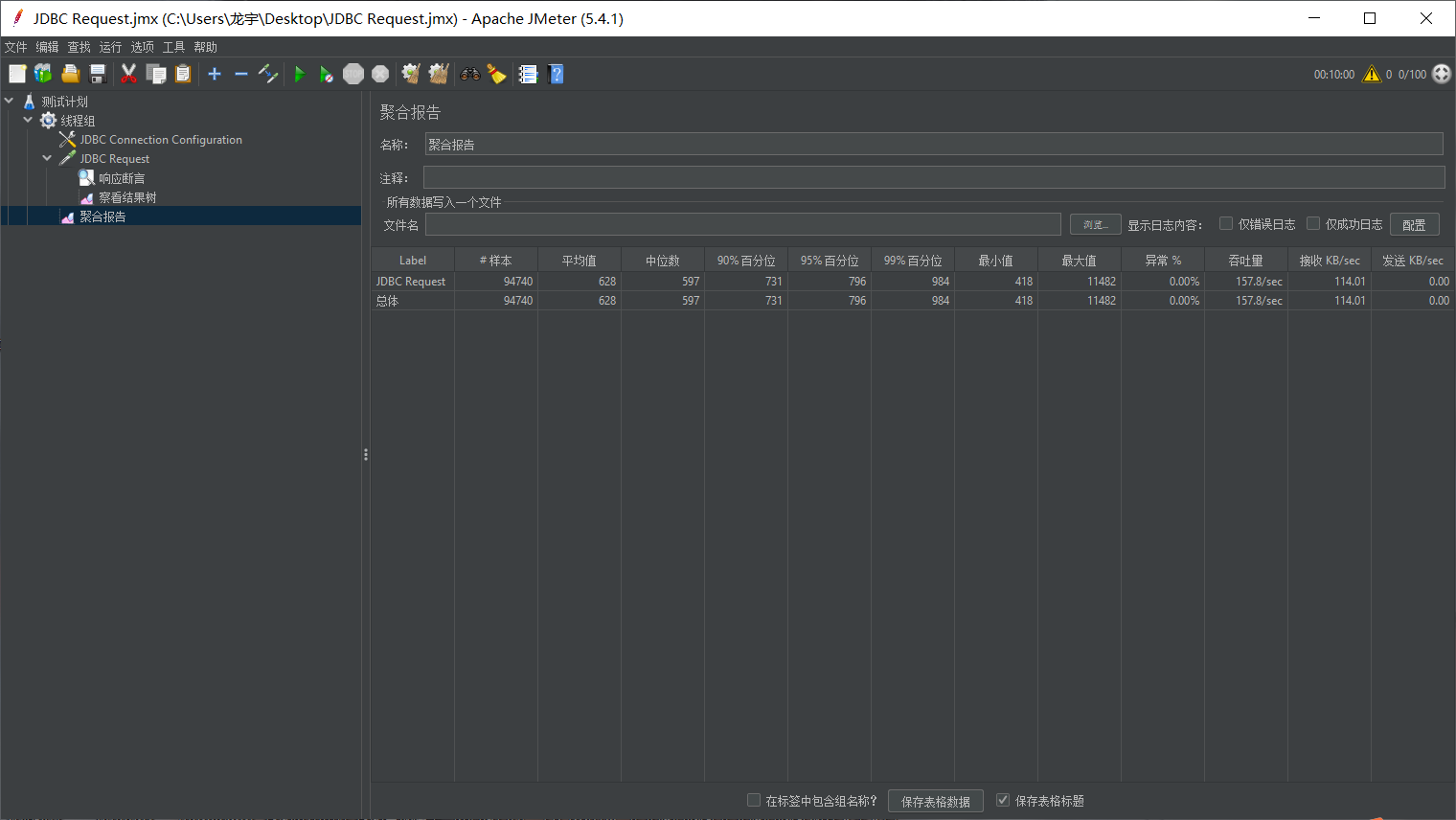
如下图100并发性能报告压测结果图:主要看平均值是否达标;
八、性能压测监控工具
达梦数据库性能并发压测,我们通常会采用第三方工具来监控数据库服务器的压力,今天主要简单介绍Linux服务器下通过nmon监控工具监控CPU,IO,内存等的方法;部署简单,找到对应ARM或X86版本,COPY到服务器任意目录,然后赋执行权限,即可安装使用,详细看如下教程说明;
8.1、nmon简单部署
这里给个下载地址:命令行wget http://sourceforge.net/projects/nmon/files/nmon16e_mpginc.tar.gz --no-check-certificate
追加--no-check-certificate 是因为部分服务器下载证书问题会报错:ERROR: cannot verify downloads.sourceforge.net's certificate
(一般服务器都内网的,大家可以直接http://sourceforge.net/projects/nmon/files/nmon16e_mpginc.tar.gz下载到本地,然后传入到内网,下载解压后版本很多,找适合自己的版本上传至服务);

步骤1:我这边是下载本地,直接FTP上传的;
sftp> lcd C:\Users\xxSOFT\Downloads\nmon16e_mpginc
sftp> put nmon_x86_64_centos7
Uploading nmon_x86_64_centos7 to /root/nmon_x86_64_centos7
100% 392KB 392KB/s 00:00:01
C:/Users/xxSOFT/Downloads/nmon16e_mpginc/nmon_x86_64_centos7: 402146 bytes transferred in 1 seconds (392 KB/s)
sftp> pwd
/root
步骤2:建立一个nmon_test目录,然后因为我FTP没有切目录,直接上传到root下了,做个mv处理;
# mv nmon_x86_64_centos7 /nmon_test/
步骤3:
# chmod 775 nmon_x86_64_centos7
以上就完成了部署。
8.2、实时快捷监控CPU,内存,IO信息等
#./nmon_x86_64_centos7
通常如果只是对单个SQL性能调优压测,不输出报告模式,我们简单用快捷键监控即可,
这里说下常用快捷键:
常用快捷命令说明:
- # c 查看CPU相关信息
2、# m查看内存相关信息
3、# d查看磁盘相关信息
4、# n查看网络相关信息
5、# t 查看相关进程信息
6、# h查看帮助相关信息
7、# q 退出nmon
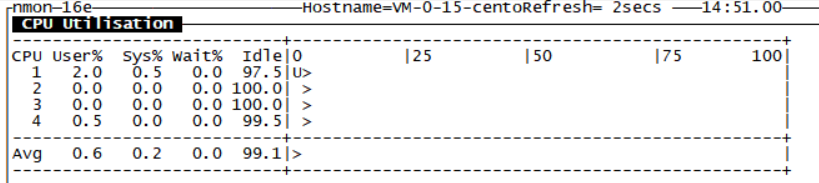
我们简单看下C的监控界面,其它就不一一演示了,大家在压测过程中,直接进入观测即可,容易理解
(如下截图是本人测试虚拟机,所以CPU内核比较少)
8.3、nmon采集数据分析
说下采集数据分析方法,一般性能压测,是一个持续的过程,这个时候需要输出压测报告,那nmon同样也是可以实现的;
通过命令行启动监控,捕获服务器的各项数据,命令如下:
#./nmon_x86_64_centos7 -s 10 -c 30 -f -m /nmon_test
以上参数解释:
-s 每隔多少秒抽样一次,单位是秒,上述命令配置是10s
-c 采样次数,上述命令配置是30,即监控总时长为10*30=300秒
-f 监控结果以文件形式输出,这里没有填写,默认格式机器名+日期.nmon格式
--m 就是制定生成的的目录 /nmon_test
#ls -all

我们如上生成了VM-0-15-centos_221212_1500.nmon就可以对他进行分析了
虽然VM-0-15-centos_221212_1500.nmon可以用文本打开,但是不够直观,
这个时候我们要借助Nmon的文件解析工具是nmon analyser来分析;
此工具下载地址为:
https://nmon.sourceforge.net/pmwiki.php?n=Site.Nmon-Analyser
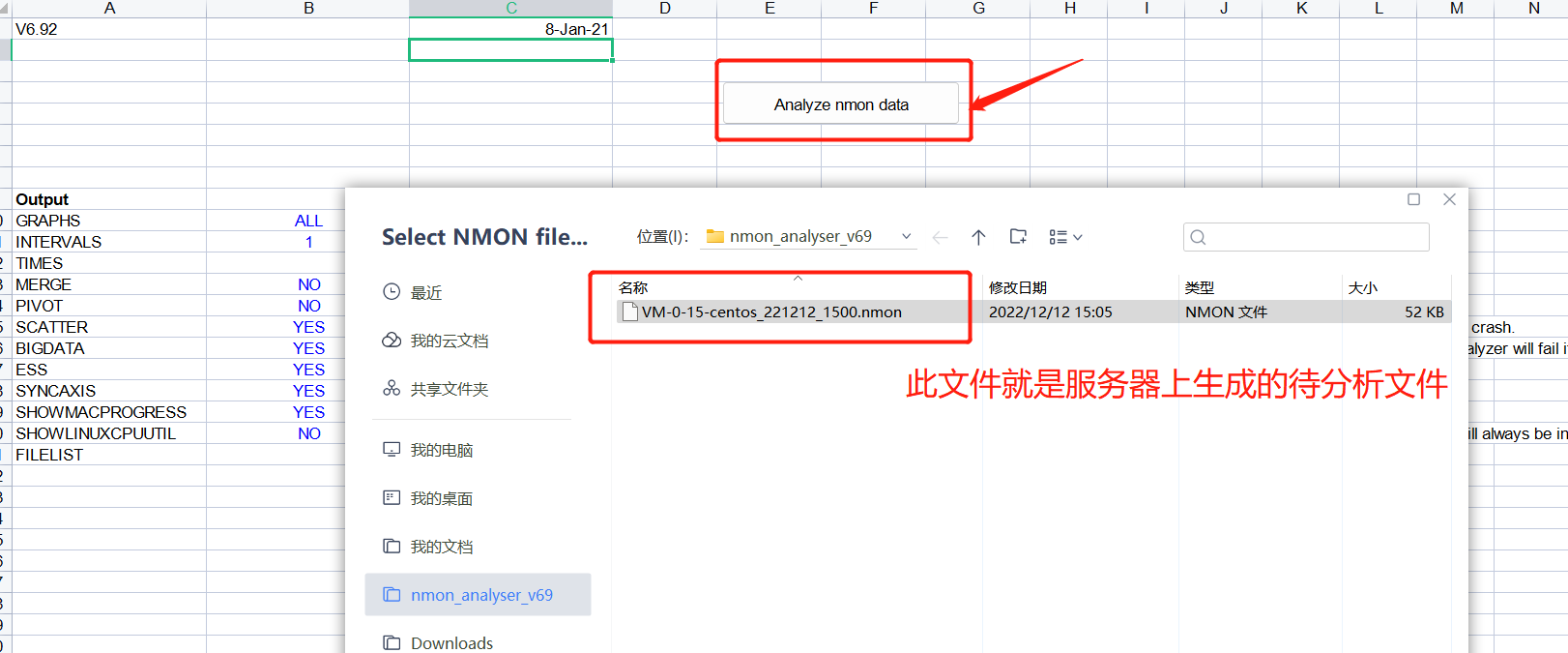
下载后使用方法是:解压直接双击VM-0-15-centos_221212_1500.nmon.xlsx
如果界面提示安全警告,“宏已被禁用”,点击启用内容即可,然后点击Analyze nmon data按钮,弹出需要分析的
如上图红框内容所示。此时,点击【Analyze nmon data】,在windows文件选择框中选择我们待分析的nmon文件
处理完成后,会弹出要我们保存同名带后缀名为.xlsx的文件,我们保存到当前目录就可以打开观看了:
SYS_SUMM:
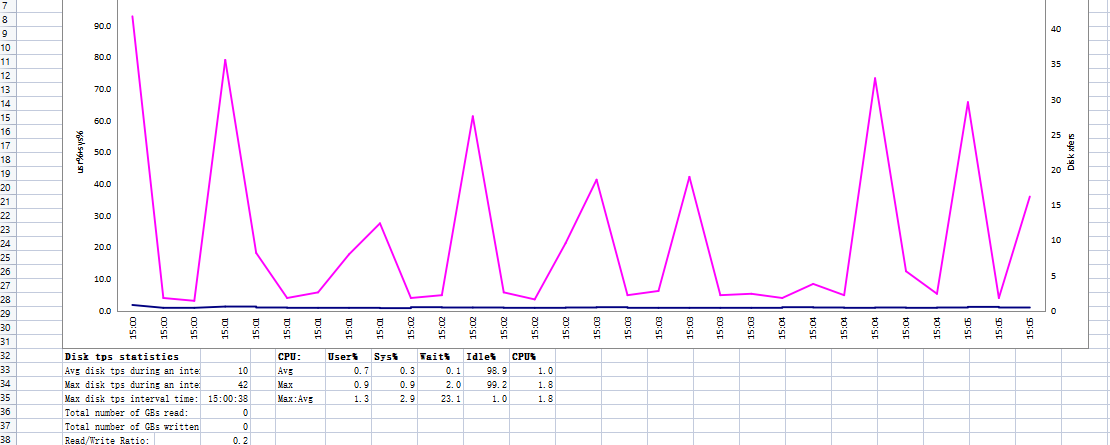
CPU_ALL:
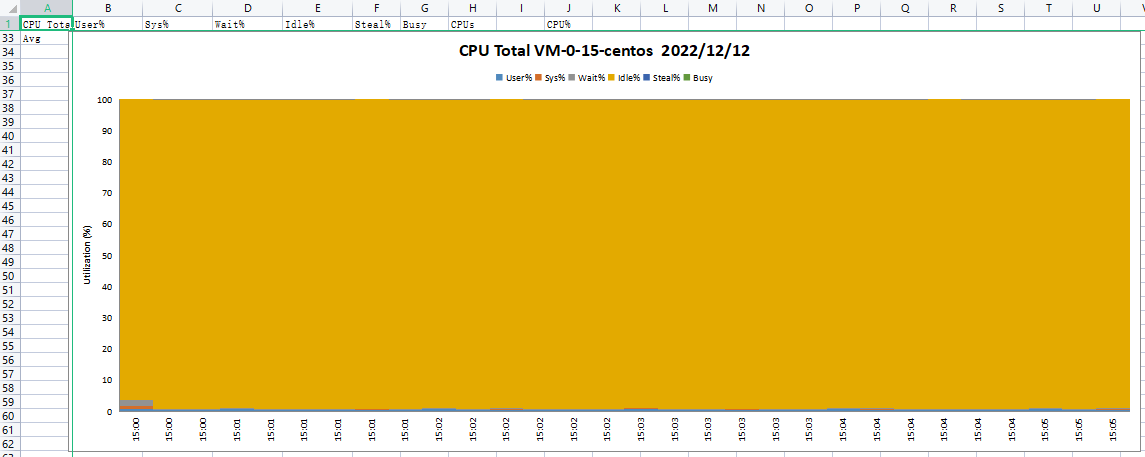
DISK_SUMM:
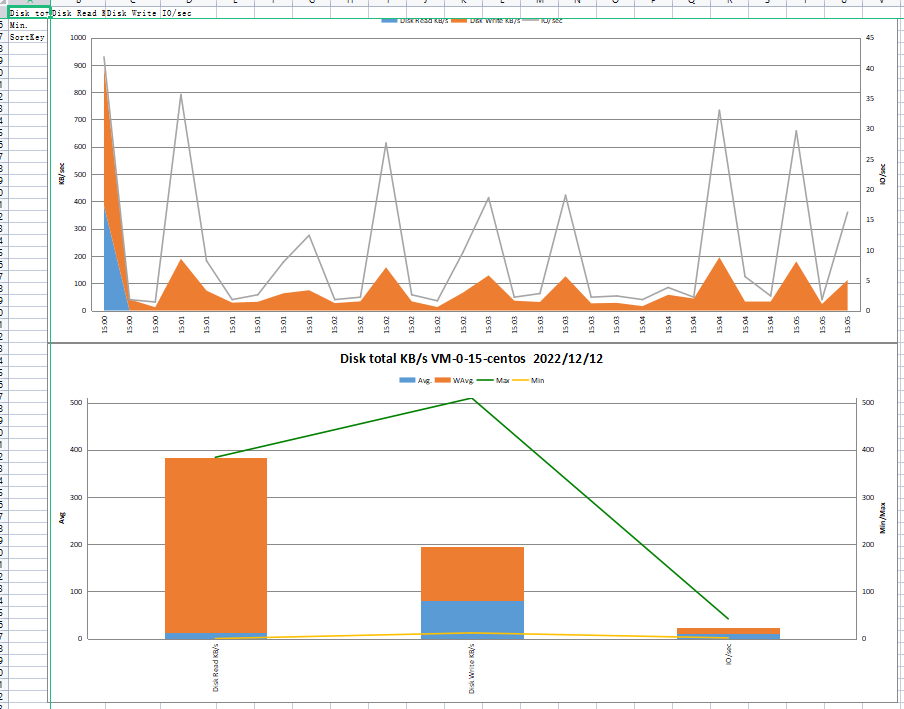
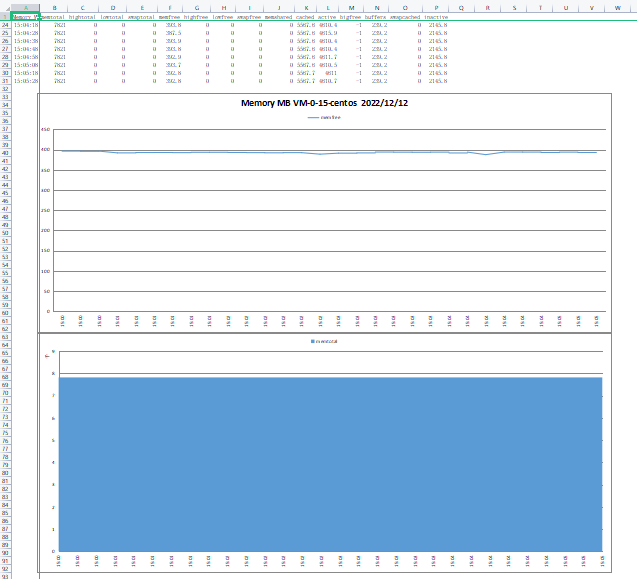
MEM:
以上是我个人工作经验的总结,因个人能力有限,文章技术细节难免有理解偏差,欢迎小伙伴们指正,国产数据库路上,我们一起同行。。。。。。
