





本篇文章介绍KGE与图路径结合的知识图谱推荐算法,而RippLeNet在这一类的推荐算法中是最为典型且效果也非常优秀的。
RippLeNet基础思想
水波网络(RippLeNet)由上海交通大学和微软亚洲在2018年提出。RippLeNet有效地结合了知识图谱嵌入与知识图谱图路径提供的信息。效果很好,模型可解释性也很便于理解。该算法现在是最热门的知识图谱推荐算法之一。
它的基础思想是利用物品的知识图谱数据一层一层地往外扩散后提取节点,然后聚合Embedding,每一层的物品会影响到在它之后的所有层,并且越往外对结果的影响就越小,就像水波一样,如图5-28所示。
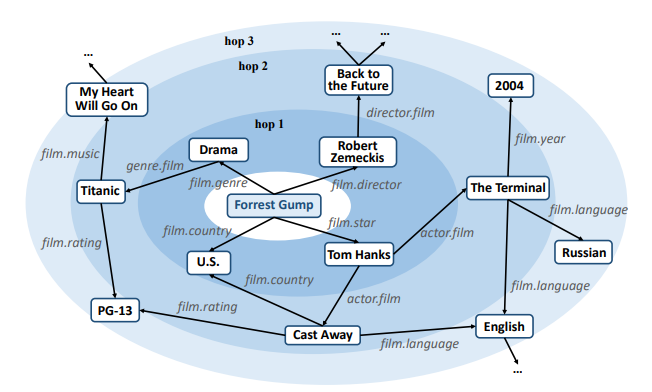
■ 图5-28 RippLeNet水波扩散示意图
这听起来很像是一种图采样。虽然说RippLeNet的提出年份在GCN 与GraphSAGE之后,但是从RippLeNet的论文中可以推理出,作者当时似乎并不是从图神经网络的思想出发,所以RippLeNet相当于从侧面碰撞到了图神经网络。
RippLeNet计算过程
首先参看RippLeNet模型的计算总览图,如图5-29所示。
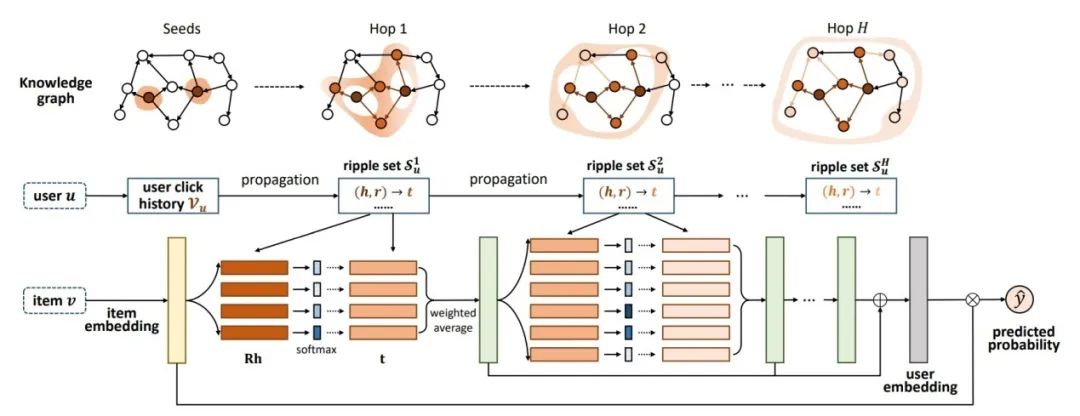
■ 图5-29 RippLeNet计算总览图
这张图初看之下有点复杂,为了方便理解,先把注意力集中在Item Embedding UserEmbedding和Predicted Probability这三项中,所以先把其余部分遮盖掉,如图5-30所示。

■ 图5-30 RippLeNet图解(1)
将其余部分先视作黑匣子。这样一来可以理解为,经过一通操作,最后将得到的User Embedding与Item Embedding做某种计算后预测出该User对该Item 的喜爱程度。如何计算有很多方法,这里就先用论文中给出的最简单的计算方式,其实是在最常用的求内积之后套个Sigmoid,公式如下:

V 代表物品向量,随机初始化即可,而用户向量U 的计算方式如下:
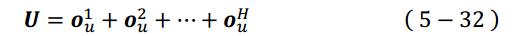
公式中的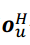 代表第H 波的输出向量。即图5-31中用方框标记出来的长条所代表的向量。
代表第H 波的输出向量。即图5-31中用方框标记出来的长条所代表的向量。
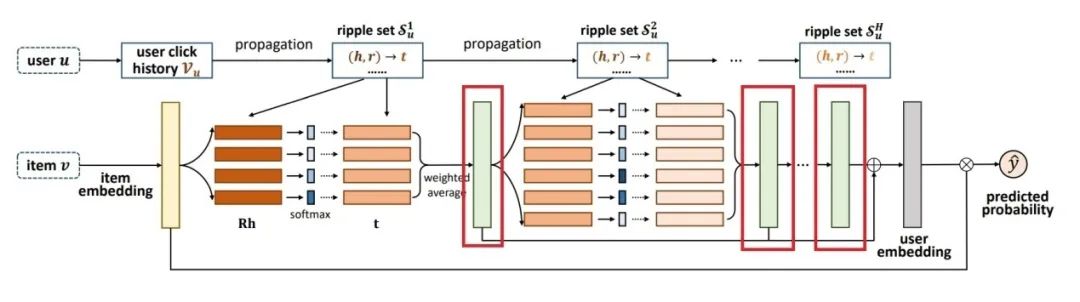
■ 图5-31 RippLeNet图解(2)
所以关键是如何得到o 向量,先说第1个o 向量,参看以下公式组:
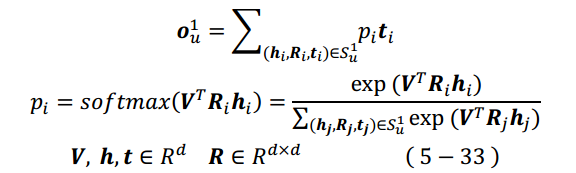
V 是Item 向量,t 是Tail向量,h 是Head向量,r 是Relation映射矩阵,这些都是模型要学的Embedding。式(5-33)表示的计算过程如图5-32所示。
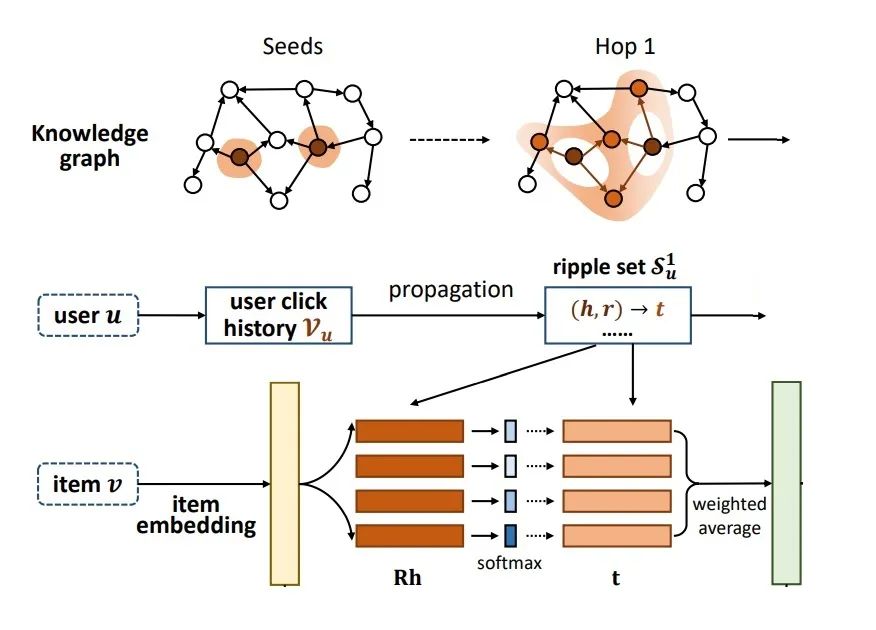
■ 图5-32 RippLeNet图解(3)
式(5-33)中的S1u代表User的第一层Ripple Set(第一层水波集,在图5-32中表示为Hop 1)。首先取一定数量的用户历史交互Item,然后由这些Item 作为Head实体通过它们的关系r 找到Tail实体,记作(h,r)→t,所以第二层水波(在图5-29中表示为Hop 2)是将第一层水波得到的Tail实体作为这一层的Head实体从而找到本层对应的Tail实体,以此类推。
公式所表达的含义相当于是对每个Hop的Tail做一个注意力操作,而权重由Head和Relation得到。
之后将上述步骤得到的o 向量作为下一层水波的V 向量,然后重复进行式(5-33) 的计算。重复H 次后,就可以得到H 个o 向量,然后代入式(5-32)得到用户向量,最后通过与物品向量点积得到预测值。
水波图采样
在水波网络中所谓每一层向外扩散的操作,实际上每一次都会产生笛卡儿乘积数量级的新实体,所以实际操作时需要设定一个值来限定每一次扩散取得新实体的数量上限,假设这个值为n_memory,若某层中(尤其是初始层)的实体数量不足n_memory,则在候选实体中进行有返回地重复采样,以此补足n_memory个新实体。
水波采样与GraphSage略有不同。最普通的GraphSage通常会限定每个节点采样的邻居数量,假设这个值为n,则经过3层采样,则总共采集到的节点数量为n3,而水波网络限定的是每一层采样的邻居总数量为n,即经过3层采样后采集到的节点数量为3×n。对于利用物品图谱作推荐的模型,水波采样的方式有下几点优势:
(1) 统一了每一层中实体的数量,便于模型训练时的batch计算。
(2) 在物品图谱中不需要对每个节点平等对待,位于中心的物品节点及周围的一阶邻居采样被采集的概率较高,而越外层的节点被采集到的概率越低,这反而更合理。水波模型中心节点是该用户历史最近交互的物品实体,而越往外扩散自然应该像水波一般慢慢稀释后续实体的权重。
水波采样的实际操作还需注意的是,训练时每一次迭代应该重新进行一次随机采样,增加训练数据的覆盖率。在做评估时同样也需重新进行一次随机采样,而不是用训练时已经采样好的水波集作为评估时的水波集。
在做预测时,理论上讲用户的Embedding也会根据其历史交互的正例物品通过随机采样的方式进行水波扩散而得到,所以预测时也有随机因子,用户相同的请求也会得到略有不同的推荐列表,但是如果不想有随机因子,则可采取训练时最后采样得到的水波集聚合出的用户Embedding直接用作后续计算。
另外水波采样的层数也有讲究,水波采样的层数最好为最小对称元路径阶数的倍数,下面来慢慢讲解这句话。
元路径的阶数指的是元路径包含的节点类型数量。例如:
元路径为电影→演员→电影,则阶数为3。
元路径为电影→角色→演员→角色→电影,则阶数为5。
水波采样最好通过候选物品的知识图谱扩散出去找到相关的其他目标物品,从而挖掘出推荐物品。假设目前知识图谱的最小对称元路径是电影→演员→电影,即路径阶数为3。如果水波采样层数仅为2,则代表每次迭代根本就没有挖掘出其他电影,而仅采集到演员,所以采样的水波层数需要不小于最小对称元路径阶数。
至于为什么最好是最小对称元路径路径阶数的倍数倒并不是很关键,为倍数的优势是因为这样大概率能在最终一层的水波集节点停留在与候选物品同样实体类型的实体上,实测后得知这对模型的训练有正向影响,但更关键的是要保证水波采样的层数要大于或等于最小对称元路径阶数。

扫码观看视频讲解
参考书籍
《动手学推荐系统——基于PyTorch的算法实现(微课视频版)》
ISBN:978-7-302- 60628-4
於方仁 编著
定价:79元


扫码优惠购书
内容简介
本书从理论结合实践编程来学习推荐系统。由浅入深,先基础后进阶,先理论后实践,先主流后推导。
第1章较为简单,仅初步带领大家了解什么是推荐系统及推荐系统的简史。第2章到第5章介绍的是主流的推荐算法及推荐算法的推导过程,这部分是本书的核心,每个算法都描述的非常详细且有具体代码帮助大家理解,深度学习的框架将采用PyTorch。第6章介绍的是商业及推荐系统的组成结构,第7章系统地介绍了推荐系统的评估指标及方式。第8章则介绍整个推荐工程的生命周期。第6~8章可随时抽取出来提前看。本书配套示例代码及微课视频,帮助读者快速入门推荐算法及系统。
本书可作为高等院校、科研机构或从事推荐系统工作的工程师的参考书籍,也可作为高年级本科生和研究生的学习参考书籍。







