





动手学推荐系统实例:DIEN 模拟兴趣演化的序列网络
实例:DIEN 模拟兴趣演化的序列网络
深度兴趣演化网络(Deep Interest Evolution Network,DIEN)是阿里巴巴团队在2018年推出的另一力作,比DIN 多了一个Evolution,即演化的概念。
在DIEN 模型结构上比DIN 复杂许多,但大家丝毫不用担心,本书会将DIEN 拆解开来详细地说明。首先来看从DIEN 论文中截下的模型结构图,如图3-23所示。
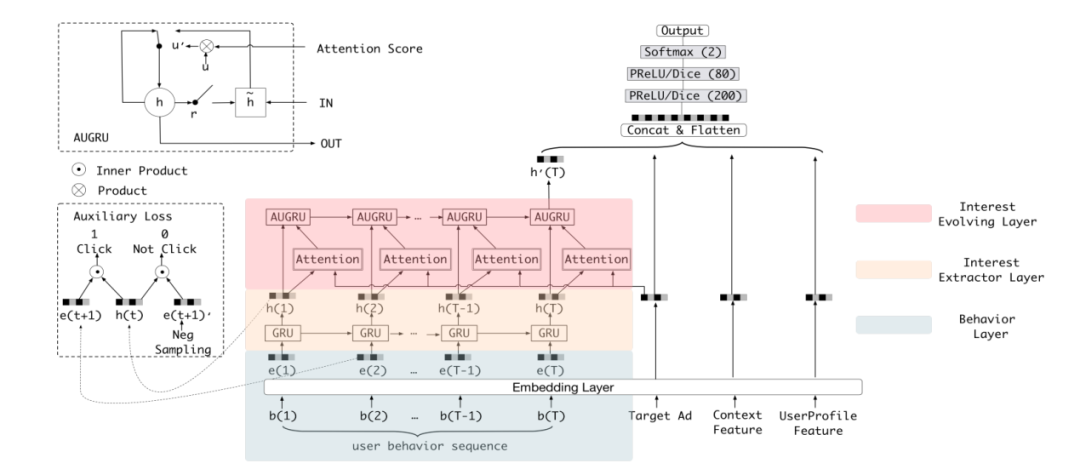
■ 图3-23 DIEN模型结构全图
这张图初看之下很复杂,但可从简单到难一点点来说明。首先最后输出往前一段的截图如图3-24所示。
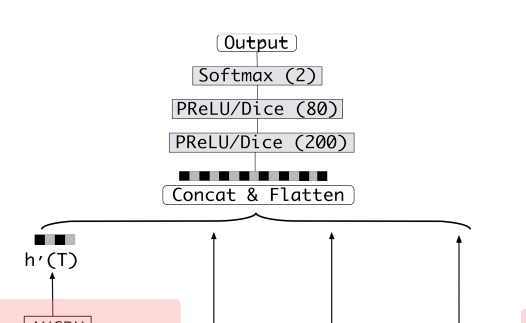
■ 图3-24 DIEN模型结构局部图(1)
这部分很简单,是一个MLP,下面一些箭头表示经过处理的向量。这些向量会经一个拼接层拼接,然后经几个全连接层,全连接层的激活函数可选择PReLU 或者Dice。最后用了一个Softmax(2)表示二分类,当然也可用Sigmoid进行二分类任务。
对输出端了解过后,再来看输入端,将输入端的部分放大后截图如图3-25所示。
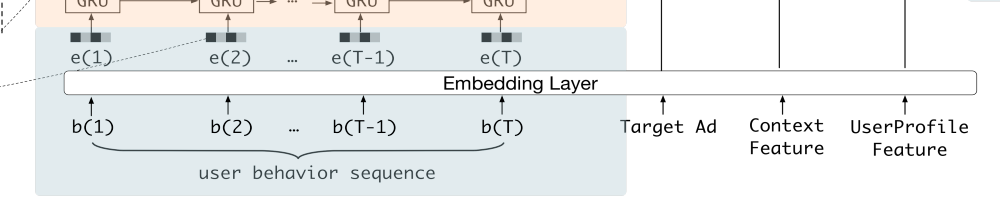
■ 图3-25 DIEN模型结构局部图(2)
从右往左看,UserProfile Feature 指用户特征,Context Feature指内容特征,Target Ad指目标物品,其实这3个特征表示的无非是随机初始化一些向量,或者通过特征聚合的方式量化表达各种信息。
DIEN 模型的重点就在图3-25的user behavior sequence区域。user behavior sequence代表用户行为序列,通常利用用户历史交互的物品代替。图3-26展示了这块区域的全貌。
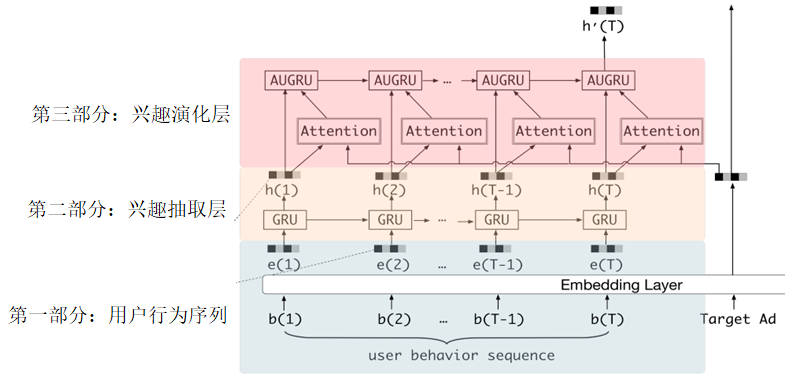
■ 图3-26 DIEN模型结构局部图(3)
这部分是DIEN 算法的核心,这里直接配合公式和代码来讲解。本节代码的地址为recbyhand\chapter3\s34_DIEN.py。
第一部分: 用户行为序列,是将用户历史交互的物品序列经Embedding层初始化物品序列向量准备输入下一层,代码如下:
#recbyhand\chapter3\s34_DIEN.py
#初始化embedding
items = nn.Embedding( n_items, dim, max_norm = 1 )
#[batch_size, len_seqs, dim]
item_embs = items(history_seqs)#history_seqs指用户历史物品序列id
所以输出的是一个[批次样本数量,序列长度,向量维度]的张量。
第二部分: 兴趣抽取层,是一个GRU 网络,将上一层的输出在这一层输入。GRU 是RNN 的一个变种,在PyTorch里有现成模型,所以只有以下两行代码。
#recbyhand\chapter3\s34_DIEN.py
#初始化gru网络,注意正式写代码时,初始化动作通常写在__init__() 方法里
GRU = nn.GRU( dim, dim, batch_first=True)
outs, h = GRU(item_embs)
和RNN 网络一样,会有两个输出,一个是outs,是每个GRU 单元输出向量组成的序列,维度是[批次样本数量,序列长度,向量维度],另一个h 指的是最后一个GRU 单元的输出向量。在DIEN 模型中,目前位置处的h 并没有作用,而outs却有两个作用。一个作用是作为下一层的输入,另一个作用是获取辅助loss。
什么是辅助loss,其实DIEN 网络是一个联合训练任务,最终对目标物品的推荐预测可以产生一个损失函数,暂且称为Ltarget,而这里可以利用历史物品的标注得到一个辅助损失函数,此处称为Laux。总的损失函数的计算公式为
L =Ltarget+α·Laux (3-26)
其中,α 是辅助损失函数的权重系数,是个超参。这里辅助损失函数的计算与3.1.6节中所介绍的联合训练RNN 不同,3.1.6节说的是多分类预测产生的损失函数,而DIEN 给出的方法是一个二分类预测,如图3-27所示。
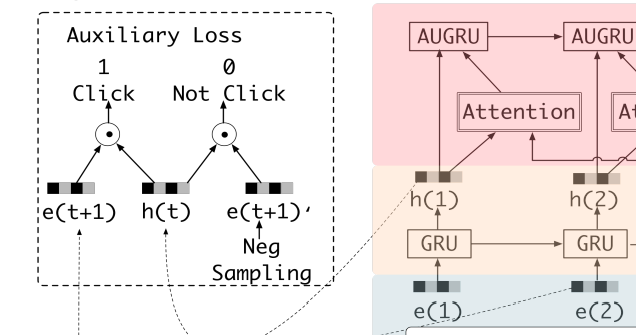
■ 图3-27 DIEN模型结构局部图(4)
历史物品标注指的是用户对对应位置的历史物品交互的情况,通常由1和0组成,1表示“感兴趣”,0则表示“不感兴趣”,如图3-27所示,将GRU 网络输出的outs与历史物品序列的Embedding输入一个二分类的预测模型中即可得到辅助损失函数,代码如下:
#recbyhand\chapter3\s34_DIEN.py
#辅助损失函数的计算过程
def forwardAuxiliary( self, outs, item_embs, history_labels ):
'''
:param item_embs: 历史序列物品的向量 [ batch_size, len_seqs, dim ]
:param outs: 兴趣抽取层GRU网络输出的outs [ batch_size, len_seqs, dim ]
:param history_labels: 历史序列物品标注 [ batch_size, len_seqs, 1 ]
:return: 辅助损失函数
'''
#[ batch_size * len_seqs, dim ]
item_embs = item_embs.reshape( -1, self.dim )
#[ batch_size * len_seqs, dim ]
outs = outs.reshape( -1, self.dim )
#[ batch_size * len_seqs ]
out = torch.sum( outs * item_embs, dim = 1 )
#[ batch_size * len_seqs, 1 ]
out = torch.unsqueeze( torch.sigmoid( out ), 1 )
#[ batch_size * len_seqs,1 ]
history_labels = history_labels.reshape( -1, 1 ).float()
return self.BCELoss( out, history_labels )
调整张量形状后做点乘,Sigmoid激活后与历史序列物品标注做二分类交叉熵损失函数(BCEloss)。
以上是第二部分兴趣抽取层所做的事情,最后来看最关键的第三部分。
第三部分: 兴趣演化层,主要由一个叫作AUGRU 的网络组成,AUGRU 是在GRU 的基础上增加了注意力机制。全称叫作GRU With Attentional Update Gate。AUGRU 的细节结构如图3-28所示。
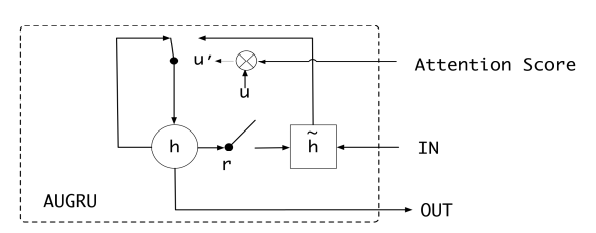
■ 图3-28 AUGRU 单元细节

扫码观看视频讲解
参考书籍
《动手学推荐系统——基于PyTorch的算法实现(微课视频版)》
ISBN:978-7-302- 60628-4
於方仁 编著
定价:79元


扫码优惠购书
内容简介
本书从理论结合实践编程来学习推荐系统。由浅入深,先基础后进阶,先理论后实践,先主流后推导。
第1章较为简单,仅初步带领大家了解什么是推荐系统及推荐系统的简史。第2章到第5章介绍的是主流的推荐算法及推荐算法的推导过程,这部分是本书的核心,每个算法都描述的非常详细且有具体代码帮助大家理解,深度学习的框架将采用PyTorch。第6章介绍的是商业及推荐系统的组成结构,第7章系统地介绍了推荐系统的评估指标及方式。第8章则介绍整个推荐工程的生命周期。第6~8章可随时抽取出来提前看。本书配套示例代码及微课视频,帮助读者快速入门推荐算法及系统。
本书可作为高等院校、科研机构或从事推荐系统工作的工程师的参考书籍,也可作为高年级本科生和研究生的学习参考书籍。







