





【案例名称】 美国总统大选数据可视化分析
任务描述
对特朗普和克林顿每个月的民意调查数据进行统计分析,本教材第六章使用numpy数组完成统计分析的过程,主要步骤为:首先,读取指定列的数据;然后,处理表示日期的文本数据,转换为形如“yyyy-mm”的字符串,提取选票日期;最后,统计每个月的投票数据。涉及的知识点包括:numpy读取CSV文件、处理日期格式的文本数据、numpy的切片与索引、numpy的统计方法以及列表推导式等。显然,使用numpy数组进行统计分析之前,需要完成繁琐的数据预处理,这也是扩展库numpy用于数据分析的缺陷。
本案例使用扩展库pandas提供的函数和相关方法实现美国总统大选数据可视化分析。
数据集简介
本案例使用的数据集包含了从2015年11月到2016年11月美国总统大选的民意调查选票数据。该数据集由27列不同类型的数据组成,保存为一个CSV文件,如图6-1所示。此数据集来源于kaggle网站,网址为:https://www.kaggle.com/fivethirtyeight/2016-election-polls。
■ 图1 2016美国总统大选数据集
本案例的数据文件中可以用于每个月民意调查统计的数据有3列。其中enddate属性表示统计选票数据的结束日期;rawpoll_clinton和rawpoll_trump属性分别表示克林顿和特朗普在这一天获得的选票数。因此,本案例的任务是从enddate属性中提取年份和月份,然后将rawpoll_clinton和rawpoll_trump属性的取值以月份为单位进行统计。
实现代码
基于扩展库pandas的Python实现代码如下所示:
import datetimeimport pandas as pdimport matplotlib.pyplot as pltdf_data = pd.read_csv('/home/aistudio/data/data76670/presidential_polls.csv') # 加载数据## step 1 标准化数据df_data['enddate']=pd.to_datetime(df_data['enddate'])df_data["enddate"]=df_data["enddate"].dt.to_period("M")## step 2 数据可视化fig,axes = plt.subplots(nrows=2, ncols=2,figsize=(15,10))grouped_rawdata = df_data.groupby(df_data["enddate"])['rawpoll_clinton','rawpoll_trump'].sum()# 原始数据趋势展示grouped_adjdata = df_data.groupby(df_data["enddate"])['adjpoll_clinton','adjpoll_trump'].sum()# 调整后数据显示grouped_rawdata.plot(ax=axes[0,0])grouped_adjdata.plot(ax=axes[0,1])grouped_rawdata.plot(kind='bar',ax=axes[1, 0])grouped_adjdata.plot(kind='bar',ax=axes[1, 1])plt.show()
代码8~9行使用扩展库pandas提供的to_datetime()函数可以将格式不统一的日期字符串转换为Series对象,其中Series对象的值是形如“yyyy-mm-dd”格式的时间日期型标准化数据,然后使用to_period("M")方法将时刻向量df_data["enddate"].dt转换成形如“yyyy-mm”的时期数据。
运行结果可视化分析
运行以上代码可视化结果如图2所示。
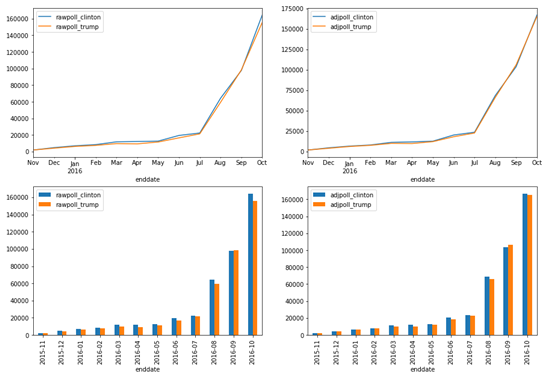
■ 图2美国总统大选数据可视化
从图2可以看出,基于原始数据的选票统计信息中,克林顿(Clinton)获得的选票数量与川普(Trump)旗鼓相当,有些时间段克林顿获得的选票数量比川普还略胜一筹。然而,在调整后的选票数量对比中发现,克林顿的选票优势逐渐下降,有些时间段比川普获得的选票数量稍逊一筹。这也许就是部分民众对川普2016年当选美国总统颇有微词的可能原因之一吧。
显然,由于扩展库pandas提供了大量用于数据清洗和数据分析的函数和对象方法,使得数据分析工作快捷而有效。对比发现,数值计算工具numpy更擅长科学计算应用,而基于扩展库numpy的数据分析工具pandas更擅长简洁而有效的专业化数据分析工作。
源代码下载及运行
关注微信公众号,后台回复关键词 “美国总统大选数据可视化分析” 即可获得完整源代码。
参考书籍

《Python数据分析案例教程(微课版)》
ISBN:9787302604211
作者:于晓梅 李贞 郑向伟 朱磊
定价:99.9元
内容简介
本书内容从Python基础到扩展库,从编程到数据分析,再到机器学习和深度学习,循序渐进,逐步推进知识点的实际应用。首先简要介绍数据分析相关概念和Python基础知识;然后按照数据分析的主要步骤,重点介绍数据获取、数据预处理、数据分析、数据可视化以及机器学习过程相关的扩展库,包括beautifulsoup4、numpy、matplotlib、pandas、pyecharts和sklearn等;最后将Python数据分析知识和实用案例有机结合,通过大量的实用案例演示相关理论和Python语言的应用。本书适合作为高等院校本科生、研究生数据分析等课程的教材,也可以作为数据分析初学者的自学用书,还适合从事相关工作的工程师和爱好者阅读。







