




简介多副本的一致性保证quorum协议分段存储事务日志下沉写放大问题日志重放事务日志异步处理异步状态基本操作writecommitreadreplica故障恢复综述
简介
根据业务进行弹性伸缩(resilience)是选择公有云的重要原因;而在传统的数据库中,单机数据库不方便扩展;基于物理机的分布式方案的扩展粒度比较大,容易有资源浪费。因此,在公有云环境下,将存储和计算分离,可以分别针对计算密集型应用和大数据量应用进行scale-up和scale-out,更加灵活方便。
将传统的数据库内核的计算模块和存储模块解耦为两个服务,其通过网络实现数据交互。因此网络代价就成为了公有云的原生数据库的关键优化点。在Amazon的Aurora论文中,针对网络代价进行的优化。
对于一个数据库,重放所有的操作记录即可得到任何时间点的数据;因此我们可以将数据库的数据看做是操作记录的日志,即为存储模块。另外数据读写的时候的命令与调度,即为计算模块;在Aurora中,上层数据库计算节点保留了数据库内核的计算模块(查询处理,事务,锁,缓存管理,访问方法和undo日志管理等);将事务日志,即redo日志,下沉到存储模块中,并且只向存储模块中写日志记录,从而大大减少网络IO;以及redo日志并发异步处理,提高整体的事务吞吐量。
论文中,主要从三个方面介绍了Aurora的架构:
如何保证底层存储模块的有效性,即读到的是最新的一致性数据,写数据的有序且不丢失的;
计算存储分离的实现方式,即,redo日志下沉后的存储模块的机制。
存储模块的一致性与可用性的保证,即,放弃2PC后,如何保证数据库的一致性。
多副本的一致性保证
在分布式环境下,冗余存储是解决高可用与高并发的基本方法。当时多个副本上的数据一致性保证又是一个大问题。在Aurora中,采用quorum+gossip的方式,保证数据的读写一致性。
quorum协议
在多个副本上的数据可能不同,每个副本在读写的是有一份投票权;假设有V个副本,读取需要获得的票,写入需要获得的票;为了保证读写的一致性,需要保证下面两个条件:
:读与写的集合有交集,确保能读到最新的数据。
:写与写的集合有交集,确保写不会覆盖其他的写。
基于以上的条件,最小即可满足条件,但是考虑到公有云的可用区分隔,三副本的容错性低;因此,Aurora采用了的设计,具体部署在三个AZ中,每个AZ有2个副本。这样能够保证一个AZ+一个节点挂掉时的读可用性与一个AZ挂掉时的写可用性。
不同副本上缺失的数据可以通过gossip做到最终一致性。
分段存储
数据整体上COPY了六份,为了方便管理并且提高整体的并发吞吐,Aurora将数据卷(Volume)分成了若干10GB的段(Segment),同一个Segment·的6份数据称为一个PG(Protect Group)。
目前的Volume存储上限是64TB
这样,当发生AZ+1的故障时,服务可用按照段为单位进行恢复,恢复时间短;并且从Amazon的经验中,在这个短时间内没有发生过一个AZ+2的故障,这确保了Quorum协议大概率是有效的[个人理解,可能不准确,原文如下]。
A 10GB segment can be repaired in 10 seconds on a 10Gbps network link. We would need to see two such failures in the same 10 second window plus a failure of an AZ not containing either of these two independent failures to lose quorum. At our observed failure rates, that’s sufficiently unlikely, even for the number of databases we manage for our customers.
因此,分段存储能够消除大量的故障恢复工作;并且在进行数据迁移时,也变得很灵活;另外,当升级上层软件的时候,可以安装段进行灰度发布。
事务日志下沉
事务日志,又叫redolog,下放到存储层是计算与存储分离的关键。在数据库中,我们可以认为日志就是数据库,因为基于日志可以恢复出任何时间点的数据。
写放大问题
在传统数据库架构中,数据更改需要进行多次IO。以MySQL为例,首先需要redo落盘;然后脏页异步刷盘;另外为了防止部分写,刷数据页时采用double-write的方式;还有元数据FRM文件以及可能打开的binlog等写盘。
并且部分磁盘IO还需要同步等待,可能导致系统夯住。
日志重放
在Aurora中,上层只写redo记录,数据库层不在刷写数据页。redo日志下推到存储层后,异步的生成数据页。当读取数据页时,如果下层还未合成好,才会等待下层的数据合成。上层的数据只看做是下层日志重放的缓存(cache,而不是buffer)。
相比于原来需要设置间歇性的CHECKPOINT点,来刷新数据页;Aurora中的数据合成是同步推进的,能够减少整体的性能抖动。并且,原来的CHECKPOINT的间隔取决于整个库的redo大小,而这里的CHECKPOINT只和某些频繁修改的段相关。
由于将尽可能多的数据操作移到后台处理,能够减少前台用户写的响应时间。
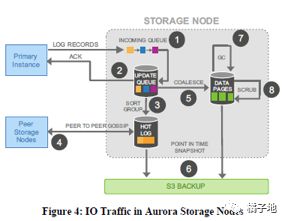
如上图是Aurora的存储节点上的处理流程:
首先将redo日志写入内存中的队列
日志持久化到磁盘的更新队列中后,向上层回ack。
将日志按顺序重新组织,发现日志中的gap。
基于gossip协议,从其他段中获得gap中的日志。
基于持久化的redo记录,合成数据页。
周期性地备份redo记录与数据页。
周期性地清理数据页中的过期版本数据。
周期性地对数据页进行crc校验。
其中只有1与2两步是串行同步的,其他的都是并行异步的处理。
事务日志异步处理
上节介绍了存储模块中的日志处理,那么在上层模块中如何确保数据的一致性呢?上层模块中,维护了数据库的持久化状态,运行时状态和复制状态,从而确保在非2pc的分布式事务模型下的数据一致性。
异步状态
首先上层写redo日志时,每个日志记录都有一个全局单调递增的lsn(Log Sequence Number)。由上面的第1,2步得知,数据库层与存储层始终保持lsn状态的同步,因此在在存储服务中,Aurora维护了一些一致性点(Volume Consistency )和持久化点。那么数据库运行时,读取的最新数据可以直接由维护的运行时状态得知,不需要quorum协议来判断了。然而在数据库恢复时,由于运行时状态丢失,仍然需要quorum协议来读取。
在重启恢复时,存储服务首先进行故障恢复,保证数据库上层看到的是全局一致的存储视图。首先,确定可用的最大的redo日志的lsn为VCL(Volume Complete LSN);将大于VCL的redo记录进行truncate。另外,每个mtr的最后一条记录是CPL(Consistence point LSN);所有CPL的最大值为VDL(Volume Durable LSN),同样将所有大于VDL的redo记录truncate。一般。
基本操作
介绍了Aurora与存储层的基本操作。
write
数据库层是按照LSN的顺序向存储中写入且只写redo日志;存储层中维护了VCL和VDL,并且随着收到的redo日志的增加不断向前推进。
为了防止数据库层分配的LSN速度远远快于存储层的VDL推进的速度,引起过多的redo日志刷盘等待;因此设置了一个阈值LAL(LSN Allocation Limit)=10million,当LSN>VDL+LAL时,上层需要等待存储层推进。
由于是按照quorum协议的分段写入,每个段中的日志记录可能不是连续的;那么每个段内连续的最大LSN为SCL。另外,每个记录内部维护了一个backlink后向指针,其指向前一个日志记录。Aurora按照[seg最新的LSN,SCL,-1]的方式,逆向寻找空缺的日志记录并按照gossip协议补全缺失的日志记录。
commit
Aurora中的事务提交同样是异步的。当client提交一个事务时,用户线程将该提交请求排队,并记录下commit lsn,然后就处理其他任务了。随后,随着VDL推进,当VDL大于该commit lsn时,有一个专用的线程向用户返回commit ok。
因此,在这里Userthread在提交的时候,不会等待,提高了事务吞吐量。
read
当发起读取的时候,当前存储模块的VDL就是当前的ReadPoint。存储模块从各个段中找到的存储节点,进而从该段中读取数据。
当读取时,相应的数据页还未合成完毕,那么会等待回放日志。
在一个PG中,每个节点根据自身收到的read请求,可以维护一个最小ReadPointLSN;那么可以得到整个PG中的最小ReadPoint LSN(PGMRPL)。因此,可以将这之前的数据持久化到磁盘中,并回收这之前的redo日志。
将底层数据读取后的并发控制(事务隔离,页面可见性等)还是在上层引擎中实现,基于回滚段与读取的数据页进行处理。
replica
在计算存储分离架构下,添加read-only的备机几乎是零成本,在Aurora中最多基于共享存储添加15个备机。
主节点写redo日志的同时也会异步的向备机发送redo日志,备机对接收到的redo日志重放,但如果重放时,相应的数据页不在备机的bufferpool中,那么就会丢弃该日志。另外,如果数据页在缓存中,那么按照下面两个规则进行重放:
回放日志的LSN应小于等于VDL,当大于VDL时,将redo日志缓存等待VDL推进后,再重放。
回放日志时需要以MTR为单位,确保能看到一致性的数据视图。
故障恢复
基于ARIES的数据库恢复算法,一般需要周期性的记录CHECKPOINT;然后从CHECKPOINT开始重放redo日志,然后按照undo日志,回滚事务。因此,在传统rdbms中,需要在CHECKPOINT周期的性能抖动与恢复时间之间做权衡。而在Aurora中不需要这种权衡,因为日志恢复和数据库是同步进行的。
在Aurora的恢复中,首先基于Read-Quorum,确保找到满足Write-Quorum的最新数据,并重新计算VDL。然后将需要truncate的LSN区间进行持久化,为了防止恢复失败并再次恢复时的歧义,持久化的truncate区间会带上epoch信息。
另外,上层数据库模块收集好未完成的事务后,即可提供服务;undo的恢复可以在线进行。[??有点不理解,得看代码]
综述
Aurora基于社区版的InnoDB改进,主要修改在于InnoDB的磁盘读写操作。redo日志划分为若干段。存储服务层向上提供和本地读取一样的接口。
在公有云上,Aurora的部署架构如下:
每个数据库实例部署了一个HostManager,负责故障切换等操作。
所有实例都在一个物理区内,但是是跨AZ部署;同样的相应的存储服务也在同一个物理区中。
安全起见,按照3个VPC隔离部署。RDS VPC负责管控平台的通信;Customer VPC负责客户的通信。Storage VPC负责数据库层与存储服务的通信。
存储服务有一组跨AZ的EC2集群构成,支持多用户存储,且从卷中读写与备份恢复等功能。
存储节点将数据备份到S3上,必要时从S3上还原数据。
存储服务的管控信息通过DynamoDB来持久化存储,其进行了高可用的保证。
