




背景数据分片方式多片数据的一致性保证CAP分布式事务背景单个分布式事务2PC3PC多个分布式事务并发控制的思想并发控制的方法分布式死锁检测
背景
首先什么叫分布式?顾名思义就是把目标分开布置。在计算机系统中,分布式的对象主要就是两个:存储和计算。所以我们常听说分布式存储,也听说了分布式计算。
那么为什么把一个整体分开呢?我总结的有以下几个原因:
| 考虑因素 | 单机 | 分布式 |
|---|---|---|
| 性能瓶颈 | 单机的资源上限 | 理论是节点存储和核数无上限,但是有通信代价。 |
| 可用性 | 单点问题 | 多活副本 |
| 伸缩性 | 受限于单个机器 | 集群理论上没有伸缩上限 |
| 数据隔离 | 全局数据共用一个缓存或存储 | 不同业务数据放在离自己近的位置,性能和安全性上都有保证 |
分布式有很多好处,同样也会存在问题;比如系统设计就会更加复杂、需要处理多节点之间通信的额外开销、很难保障多节点的数据完整性、以及多节点的数据分布方式会影响分布式查询的性能等等。每个方向都是一个课题,已经有很多大佬进行了大量的研究,做工程时需要了解总结前人的研究成果。
本文主要针对分布式存储的数据一致性进行探讨。
数据分片方式
当业务发展到一定规模,受制于单机或单表容量的限制或性能的考量。会将较大的业务表按照某个distributed_id
进行水平(shard_id)或垂直分割(外键)。
另外,每个分片一般都会有一个或多个副本,来保证可用性。每一组副本都是只有一个leader,然后副本之间通过某种同步方式同步数据&读写分离(关于哪个作为leader,一般人为指定优先级,或者基于算法进行选举)。
多片数据的一致性
CAP
单机数据库通过本地事务来保证数据一致性。分布式系统的一致性是保证整个系统的各处的状态是相同的。对于无状态的分布式系统,系统间的协调几乎没有必要了;但是对于像数据库这种有状态的,为了对外表现的是一个整体,就需要在C/A/P之间权衡了(Principles of Distributed Computing ——Eric Brewer)。
(强)Consensus:确保客户端链接上每个分布式节点node,都是看到相同的且最新的数据;并且能够成功的写入。这种一致性是一种强的序列化的一致性。
(高)Availability:每个有效节点都能在合理的时间内响应读写请求;
Partition Tolerant:由于网络隔离或机器故障,将系统分割后,系统能够继续保持服务并且保持一致性;当分割恢复后,能够优雅的恢复回来。
这里的CA和ACID中的CA是两码事。A就不用说了,一个是可用性,一个是原子性。
ACID中的C是Consistency,强调的是连贯性,前后一致。
CAP中的C是Consensus,强調的是共识,各个节点之间是否达成一致意见。
由于CAP三者不能同时满足,从而有状态的分布式系统就分为了三种类型:
CP:当系统出现网络分区时,这时牺牲了可用性,保障整体一致性和分区容忍性。
AP:当系统出现网络分区时,这时牺牲了一致性,保证性能可用性和分区容忍性。
CA:如果单机的DB算一个分布式系统,那么就算一个CA的系统。但是,网络分布式系统中,由于node之间是通过网络进行通信的,网络分割是常有的事。分布式系统中一定要处理P这个问题,因此很少有分布式的CA系统。
所以,分布式系统一般就是在考虑在产生网络分区时,我们应该优先保证强一致性还是完美的可用性。但是一般我们是尽量两方面都做到尽量好。对于AP系统,一般是一些NoSQL系统,这种系统可以通过raft等一致性协议对多个读写操作的顺序进行协调,保证每个节点上的数据操作顺序是相同的,那么就能做到最终一致性。而对于CP系统,更加关注的是一致性,这里就利用分布式事务在整个系统之间进行操作的调度协调。这就到了本文要介绍的分布式事务了。
分布式事务
背景
如果业务后端只有一个DB,那么数据的一致性通过本地事务即可保证。但是如果业务架构类似微服务的方式,同一份数据可能在多个Service后端单独存储,那么要保证不同业务后端的数据是一致的,就需要多个本地事务的协同操作。
最简单的就是多写的方式,即,业务要修改共享的数据,就同时修改。但是这就使得业务代码逻辑复杂,不易于维护。某人说过一个著名格言——"All problems in computer science can be solved by another level of indirection",因此层出不穷的分布式事务中间件就出来了。
单个分布式事务
对于本地事务来说,其就是逻辑上是一个整体的一系列读写操作。 事务比较细致地可以区分为五种状态,分布式事务同样也是有这五种状态,那么就需要他们基于某种协议就行协调:
active:正在执行某条语句
partially commited:上一条语句执行成功
commited:事务成功了
failed:某条语句失败了
aborted:事务失败了
2PC
一个分布式事务可以看做是多个本地事务的按照某个协议的协同操作。常说的就是2PC协议,这是X/Open提出的通用的分布式事务协议。在XA协议中一般有两个角色,一个全局协调者的TM(Transaction Manager)与多个本地存储服务的RM(ResourceManager)。2PC的两个阶段如下:(图片来自DZone)
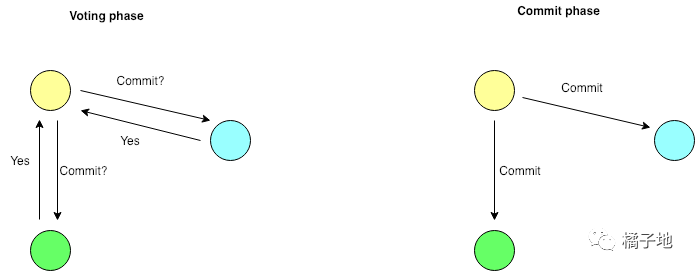
理想情况是:在voting阶段,如果RM节点返回了Yes;那么提交成功。否则,全部回滚。
如果某个RM节点在返回Yes之前挂了,那么TM可以感知到从而进行Rollback。如果在返回Yes之后挂了,那么此时这个全局事务同样标记为Commit;当挂掉的RM节点重启恢复的时候,本地发现还有未提交的Prepared的全局事务,此时会重新查询TM中全局事务的状态,来决定对其进行Commit还是Rollback。
在PostgreSQL和MySQL中都支持了XA协议的prepare等操作,需要注意在MySQL5.7之前的版本中,prepare操作不写binlog,因此如果MySQL5.6作为RM节点,宕机恢复时会有问题。
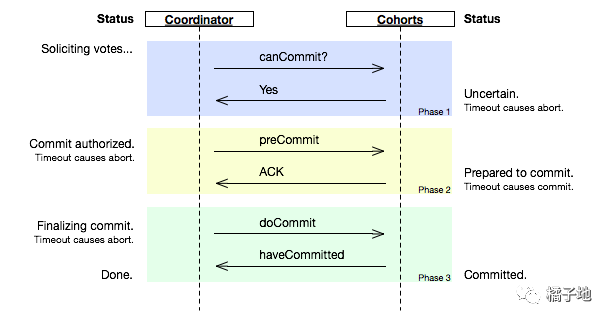
3PC
2PC第一步等待回复时会阻塞操作,在3PC中,基于以下基本前提,可以解决2PC的阻塞问题(图片来自Wikipedia)。
没有网络分区
至少一个节点可用
最多有K个节点同时挂机是可以接受的
另外还有一种分布式事务的实现方式:TCC-柔性事务
篇幅有限,另开一文。
不管基于什么协议实现的单个分布式事务,其保证了ACD特性,而作为一个真正的事务还需要满足并发环境的I(隔离性)。这就需要提到并发控制。
多个分布式事务
在多事务并行中,如果两个事务中的两个操作(这两个操作其中至少有一个是写)目标是同一个对象,那么会产生冲突。这里就要求并行调度保证事务前后的正确性,以及运行期间的隔离性。
并发控制的思想
在单机环境中,一般有三种方式进行并发控制:
MVCC:多版本并发控制。数据带上和事务标识相关的版本号。
S2PL:严格两阶段提交协议;比起2PL,S2PL直到事务结束才释放写锁。
OCC:乐观并发控制。在冲突较低的场景下,在事务结束才判断是否冲突,提高性能。整个事务就分为三个阶段:执行、确认、提交。在确认阶段有一些判断规则。
相应地,在分布式环境中有基于同样思想的并发控制:
Distributed 2PL:系统中有一个或若干个锁管理器节点,该节点负责全局的锁分配和冲突检测。
Distributed MVCC:这里需要有一个全局唯一的自增ID(或时间戳);在Google的spanner中物理的方式实现了一个全局时间戳。另外,还有使用混合逻辑时间戳(CockroachDB)。
Distributed OCC:和单机环境相同。但是在确认阶段有一些分布式环境中相应规则。
并发控制的方法
并发控制的目标就是将同时进行的读写操作,最终整合成为一个串行化的操作,这样在顺序的redolog中就能有序摆放,进而故障恢复的时候也是很有秩序。那么如何达成这一目标呢?一般有两种方式:
实现一个全局锁服务,比如Zookeeper这种,来进行全局操作的同步。
实现一个分布式一致性协议的库,各个Service基于同一个协议进行操作,这要求程序员要熟悉Paxos或者Raft及其衍生协议。
有以下三种,由于篇幅有限,后另开一文。
Paxos:p2p的,没有leader;比如,zoonkeeper
Raft:有leader的;比如,etcd
Gossip:最终一致性;比如,consul
不过是哪种方法,都是为了进行多个全局事务的读写同步;在每个分布式的事务内部还是按照多阶段的方式提交。
分布式死锁检测
中心点集中检测,如果有一个全局锁服务,可以在该服务中,做死锁检测。
每个节点单独检测,需要同步其他节点的事务依赖序列。
