




以找云宝为物体检测项目为例,介绍了ModelArts模型的训练过程。
开始训练
完成数据标注后,在“数据标注”界面,单击右上角的“开始训练”按钮,ModelArts将开启模型的训练过程。自动训练的目的是得到满足需求的图像分类模型。由于用于训练的图片至少有两种以上的分类,每种分类的图片不少于5张,因此在发布训练之前,请确保已标注的图片符合要求,否则“开始训练”按钮会处于灰色状态。
单击“开始训练”按钮,在弹出的“训练设置”对话框中配置相关参数,如图9-30所示。具体参数配置如下所述。

■ 图9-30“训练设置”对话框
(1) 数据集版本名称。此版本即数据管理中发布数据集时设置的版本。自动学习项目中,启动训练作业时,会基于前面的数据标注,将数据集发布为一个版本。系统将自动给出一个版本号,用户也可以根据实际情况进行填写。
(2) 训练验证比例。训练验证比例表示将已标注样本随机分为训练集和验证集的比例,默认训练集比例为0.8,即大部分为训练集,manifest中的usage字段记录划分类别。
(3) 增量训练版本。用户可以在之前训练成功的版本中,自主选择精度最高的版本进行再训练,可以加快模型收敛速度,提高训练精度。
(4) 最大训练时长(分钟)。在设置的最大训练时长内,若训练还未完成,则系统会强制退出。为防止在训练中退出,建议使用较大值。注意:输入值不能小于0.05。适当延长训练时间,500张图片的训练集建议选择运行120分钟以上。
(5) 训练偏好。训练偏好主要有三档,值分别为accuracy first(精度优先、训练时间较长,模型较大)、balance(平衡)、performance first(性能优先、训练时间较短、模型较小)。此样例取值为balance。
(6) 计算规格。计算规格即选择训练使用的资源规格,默认支持两种:增强计算型1实例-自动学习(GPU):按需计费的规格;自动学习免费规格(GPU):免费规格,使用此规格不收费。但是使用此规格时,训练作业在60分钟后会自动停止,即1次最多只能使用60分钟。建议评估下数据大小,确保训练作业不要超过60分钟。当使用人数较多时,此免费规格需排队等待。
单击“下一步”按钮,确认配置后,单击“提交”按钮,即可开始模型的自动训练,如图9-31所示。训练时间相对较长,建议耐心等待。如果训练中关闭或退出此界面,那么系统会继续执行训练操作。
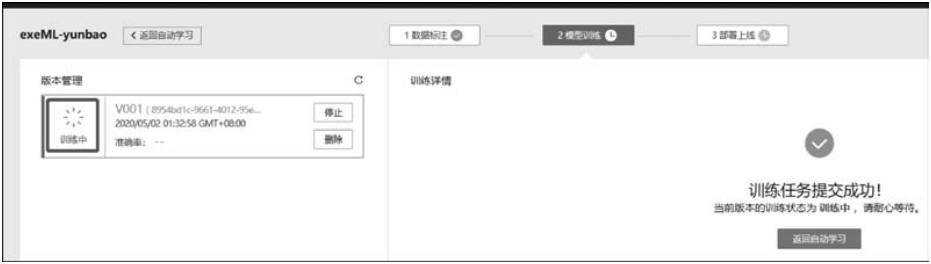
■ 图9-31模型开始训练
训练结果
模型训练完成后,可以在界面中查看训练详情,如“准确率”“评估结果”“训练参数”“分类统计表”等,如图9-32所示。
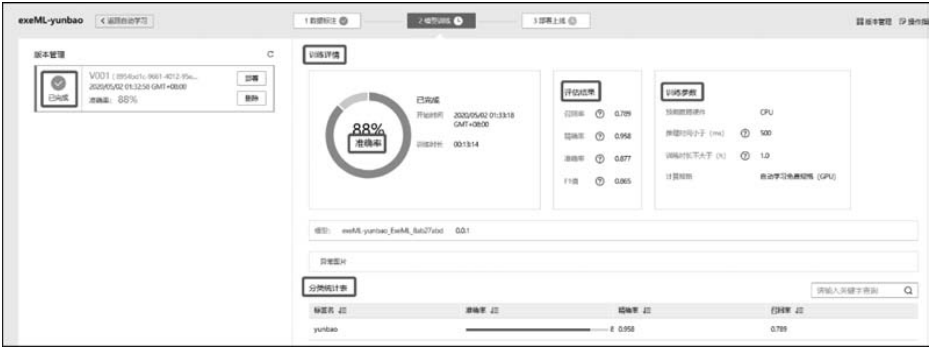
■ 图9-32模型训练结果
评估结果参数说明如下所述。
(1) 召回率: 被用户标注为某个分类的所有样本中,模型正确预测为该分类的样本比率,反映模型对正样本的识别能力。
(2) 精确率:被模型预测为某个分类的所有样本中,模型正确预测的样本比率,反映模型对负样本的区分能力。
(3) 准确率: 所有样本中,模型正确预测的样本比率,反映模型对样本整体的识别能力。
(4) F1值: F1值是模型精确率和召回率的加权调和的平均值,用于评价模型的好坏。当F1较高时,说明模型效果较好。
实例讲解
华为云从入门到实战

精彩回顾
下期预告
WAF应用与部署
参考书籍

《华为云从入门到实战》
ISBN:9787302586913
张建勋 刘航 编著
定价:59.90元
扫描优惠购书
(1) 以工作任务为导向,精准定位市场人才需求,突出部署和应用。
精彩推荐
微信小程序游戏开发│猜数字小游戏(附源码+视频) Flink编程基础│Scala编程初级实践 Flink编程基础│FlinkCEP编程实践 Flink编程基础│DataStream API编程实践 Flink编程基础│DataSet API编程实践 数据分析实战│客户价值分析 数据分析实战│价格预测挑战 数据分析实战│时间序列预测 数据分析实战│KaggleTitanic生存预测


