2、 在hadoop101安装Hadoop
2.0、hadoop重要目录说明
1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
4)sbin目录:存放启动或停止Hadoop相关服务的脚本
5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
2.1、传输hadoop包
用XShell文件传输工具将hadoop-3.3.3.tar.gz导入到opt目录下面的software文件夹下面
2.2、解压hadoop包
#进入到hadoop安装包路径下 cd opt/software/ #解压文件到/opt/module下面 tar -zxvf hadoop-3.3.3.tar.gz -C opt/module/ #查看是否解压成功 ls opt/module/hadoop-3.3.3 |
2.3、将hadoop添加到环境变量
#打开/etc/profile.d/my_env.sh文件 vim etc/profile.d/my_env.sh #在my_env.sh文件末尾添加如下内容 #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.3.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #保存并退出 :wq! #让修改后的文件生效 source etc/profile
|
2.4、验证是否安装成功
执行命令 hadoop version
看到下面展示即为成功
2.5、重启服务器
reboot
、部署hadoop集群(完全分布式运行模式)
3.0、配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
3.1、hadoop集群规划
hadoop101 | hadoop102 | hadoop104 | |
HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
YARN | NodeManager | ResourceManager NodeManager | NodeManager JobHistoryServer |
NameNode不可和SecondaryNameNode放在一台服务器上;另外ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
3.2、在hadoop102、hadoop103上安装hadoop
参考章节2
3.3、配置集群
3.3.1、核心配置文件
配置core-site.xml文件
cd $HADOOP_HOME/etc/hadoop vim core-site.xml |
在<configuration></configuration>中间添加下面内容
<!--指定NameNode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:8020</value> </property> <!--指定hadoop数据的存储目录--> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.3.3/data</value> </property> <!--配置HDFS网页登录使用的静态用户为nps1900--> <property> <name>hadoop.http.staticuser.user</name> <value>nps1900</value> </property> |
3.3.2、HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml |
在<configuration></configuration>中间添加下面内容
<!--nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop101:9870</value> </property>
<!--指定2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:9870</value> </property> |
3.3.3、YARN配置文件
配置yarn-site.xml
vim yarn-site.xml |
在<configuration></configuration>中间添加下面内容
<!--指定MR走shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<!--指定resourcemanager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop102</value> </property>
<!--环境变量的继承--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HDOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> |
3.3.4、MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml |
在<configuration></configuration>中间添加下面内容
<!--指定MapReduce程序运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> |
3.3.5、分发配置文件
xsync opt/module/hadoop-3.3.3/etc/hadoop/ |
或者手工在hadoop102、hadoop103执行3.3.1-3.3.4章节
3.3.6、查看文件分发情况
去hadoop 102、hadoop103机器上查看文件分发情况
cat /opt/module/hadoop-3.3.3/etc/hadoop/core-site.xml cat /opt/module/hadoop-3.3.3/etc/hadoop/hdfs-site.xml cat /opt/module/hadoop-3.3.3/etc/hadoop/yarn-site.xml cat /opt/module/hadoop-3.3.3/etc/hadoop/mapred-site.xml |
注:查看新增的配置内容是否存在。
3.4、启动集群
3.4.1、配置workers
执行下面命令:
vim /opt/module/hadoop-3.3.3/etc/hadoop/workers |
在该文件中增加如下内容:
hadoop101 hadoop102 hadoop103 |
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空格
同步所有节点配置文件
xsync /opt/module/hadoop-3.3.3/etc |
3.4.2、启动集群
3.4.2.1、格式化namenode
注意:如果集群是第一次启动,需要在hadoop101(配置的namenode节点服务器)节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format |
3.4.2.2、启动hdfs
进入hadoop的sbin文件夹下,执行命令
cd /opt/module/hadoop-3.3.3/sbin ./start-dfs.sh |
备注:在执行该命令前,可以先按照下面更新完善该sh文件。
#HDFS格式化后启动dfs出现以下错误:
# ./start-dfs.sh Starting namenodes on [master] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [slave1] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation. |
解决方案如下:
在/opt/module/hadoop-3.3.3/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root |
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root |
修改后重新执行下面命令,成功
cd /opt/module/hadoop-3.3.3/sbin ./start-dfs.sh |
3.4.2.3、启动yarn
在配置了ResourceManager的节点hadoop102,
进入hadoop的sbin文件夹下,执行命令
cd /opt/module/hadoop-3.3.3/sbin ./start-yarn.sh |
3.4.2.4、web端查看HDFS的NameNode
浏览器中输入:http://hadoop101:9870

3.4.2.5、web端查看yarn的ResourceManager
浏览器中输入:http://hadoop102:8088
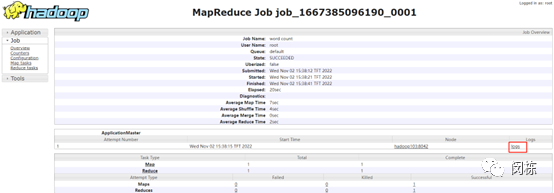
3.4.2.6、查看YARN上运行的job信息
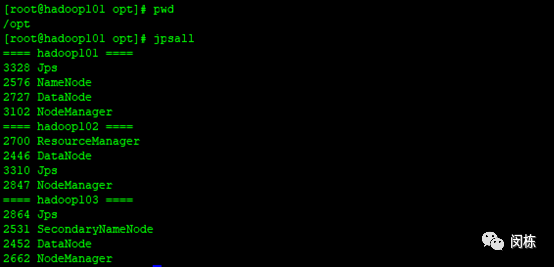
执行jpsall效果如下:
3.5、集群优化配置
3.5.1、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
进入hadoop配置文件路径
cd /opt/module/hadoop-3.3.3/etc/hadoop/ |
编辑配置文件 mapred-site.xml
vim mapred-site.xml |
在该文件里面增加如下配置。
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop103:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop103:19888</value> </property> |
#将配置文件分发到其他服务器上(hadoop102、hadoop103)
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml |
注:也可通过ftp工具上传到相应的服务器上
#在hadoop103服务器上启动historyserver,并用jps命令查看historserver是否启动
mapred --daemon start historyserver |

#查看JobHistory webui界面

3.5.2、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。日志聚集功能好吃:可以方便的查看程序运行详情,方便开发调试。
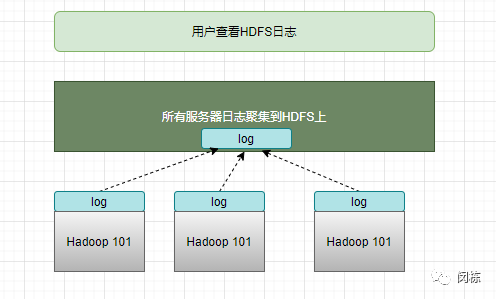
注意:开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryServer
#配置yarn-site.xml
进入配置文件所在路径(hadoop安装路径),编辑 yarn-site.xml
cd /opt/module/hadoop-3.3.3/etc/hadoop/ vim yarn-site.xml |
在该文件里面增加如下配置:
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop103:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
#分发配置文件到其他服务器上
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml |
#关闭NodeManager 、ResourceManager和HistoryServer
stop-yarn.sh mapred --daemon stop historyserver |
备注:分别在对应的服务器上面执行上面命令
#启动NodeManager 、ResourceManager和HistoryServer
start-yarn.sh mapred --daemon start historyserver |
备注:分别在对应的服务器上面执行上面命令
#删除HDFS 上已经存在的输出文件
hadoop fs -rm -r /output |
#执行wordcount程序
cd /opt/module/hadoop-3.3.3/ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.3.jar wordcount /input /output |
#查看日志
历史服务器地址
http://hadoop103:19888/jobhistory
历史任务列表
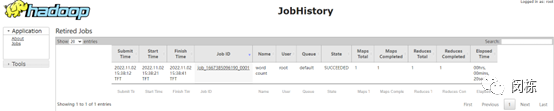
查看任务执行历史
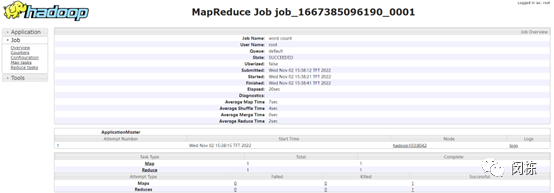
运行日志详情