




注:本次是在kafka学习过程中的一些知识记录整理及尝试搭建Kakfa集群环境,限于知识,内容难免有纰漏,还望对此熟悉的大牛多多指正。
1 简介
1.1 消息队列简介
1.1.1 什么是消息队列
消息队列,英文名:Message Queue,经常缩写为MQ,从字面上来理解,消息队列是一种用来存储消息的队列,拥有先进先出(FIFO)的特性,主要用于不同线程和进程间的通信,处理一系列的输入请求。
消息队列采用的的是异步通信机制,即消息的发送者和接收者无须同时与消息队列进行数据交互,消息会一直保存在队列中,直到被接收者读取。每条消息记录都包含了详细的数据说明,如(数据产生时间、数据类型、特定的输入参数等)。
MQ的真正目的是为了通讯,屏蔽底层复杂的通讯协议,定义了一套应用层、更加简单的通讯协议。
消息队列又叫消息系统,是分布式系统中重要的组件,其通用场景可简单描述为:当不需要立即获得结果,但是并发量又需要进行控制的时候,差不多就是需要消息队列的时候。
消息队列负责将数据从一个应用传递到另外一个应用,应用只关注于数据,无需关注数据在两个或多个应用间是如何传递的。分布式消息传递基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
消息就是一个字节数组
消息队列主要为解决应用耦合、异步处理、流量削峰等问题。
当前使用较多的消息队列有RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ、部分数据库如Redis、MySQL等也可实现消息队列的功能。
消息队列通过将消息的发送和接收分离来实现应用程序的异步和解耦,但消息队列真正的目的是解决了异步的通信问题,消息队列屏蔽了底层复杂的通信协议。
1.1.1.1 消息队列分类
1.1.1.1.1 有Broker的消息队列
通常有一台服务器作为Broker,所有的消息都通过它进行中转,生产者把消息发送给它就结束自己的任务,Broker则把消息主动推送给消费者(或消费者主动轮训)。其根据Topic又可大致分为两类。
-
重Topic: Kafka、ActiveMQ、RocketMQ都属于该类,是指整个消息在进行转发的时候以Topic作为依据来进行中转。 生产者发送key和数据到Broker,然后由Broker比较key之后决定推送给哪个消费者,此种是常见的模式。该模式下,一个Topic往往是一比较大的概念,甚至一个系统可能只有一个Topic,Topic某种意义上就是队列。
-
轻Topic: 如RabbitMQ(或者说是AMQP),其内部可以用Topic,也可以不用Topic。生产者发送key和数据,消费者定义订阅的队列,Broker收到数据之后会通过一定的逻辑算出key对应的队列,然后将数据交给队列。
1.1.1.1.2 无Broker的消息队列
无Broker的MQ的典型代表是ZeroMQ,其无Broker这一中转站。MQ是更高级的socket,解决通讯问题,ZeroMQ 被设计成一个"库"而不是一个中间件,达到了无Broker的目的。
1.1.2 消息队列应用场景
- 应用解耦
只要两个对象之间存在一方依赖一方的关系,那么就称这两个对象之间存在耦合。假设生产者和消费者分别是两个类,如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(即耦合)。将来如果消费者代码发生变化,可能会影响到生产者。而假如两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。
解耦就是上下游应用不再紧耦合,两边只要约定好消息格式或者规范即可。
- 异步通信
很多时候,应用不需要立即处理消息,消息队列提供了异步处理机制,允许应用把一个消息放入队列,但并不立即处理它,可以向队列中放入很多消息,然后在需要的时候再去处理它们。
- 扩展性
因为消息队列解耦了处理过程,所以增大消息入列和处理的频率是很容易的,只要另外增加处理过程即可,无需修改代码、也无需调节参数。
- 削峰填谷
对于突发的大量请求,可以通过配置流控规则,以稳定的速度逐步处理这些请求,起到"削峰填谷"的效果,从而避免流量突增带来的系统负载过高问题。
1.2 Kafka简介
1.2.1 Kafka三大角色
-
消息系统:Kafka除和传统消息系统都具备系统解耦、冗余存储、异步通信等功能外,其还提供了其它消息系统都难以实现的顺序性保障及回溯消费的功能
-
**存储系统:**相比其它基于内存存储的消息系统而言,Kafka可将消息持久化到磁盘,Kafka提供的消息持久化和多副本机制,只需将对应数据保留策略设置为"永久"或启用主题的日志压缩功能,这样极大降低了数据丢失的风险
-
**流式处理平台:**Kafka为当下很多流行的流式处理框架提供了可靠数据来源,另外还提供一个完整流式处理类库,如窗口、连接、变换和聚合等多种操作
1.2.2 Kafka体系结构
一个比较典型的Kafka体系架构包括若干个Producer、若干个Broker、若干个Consumer,以及一套Zookeeper集群。其中Zookeeper是Kafka用来负责集群元数据管理、控制器选举等操作。Producer负责将消息发送给Broker、Broker负责将收到的消息存储到磁盘中,Consumer负责从Broker订阅和消费消息,Consumer是消费者组的一部分,会有一个或多个consumer共同读取一个主题。
Kafka中的消息以主题为单位进行归类,Producer负责将消息发送到特定的主题(发送到Kafka集群中的每条消息都要指定一个主题),消费者负责订阅主题并进行消费。
主题是逻辑上的概念,其分为多个分区,每个分区只属于一个主题,通常也将分区称为主题分区(Topic-Partition)。
Kafka为分区引入了多副本(Replica)机制,通过增加副本数量提升容灾能力,同一分区的不同副本中保存的相同消息(同一时刻,各副本之间并非完全一致)。副本之间是遵循"一主多从"关系,leader副本负责处理读写请求,follower副本只负责与leader副本消息同步,一旦leader副本故障,会从follower副本中选举新的leader对外提供服务。
比较典型的Kafka集群体系结构如下图所示:
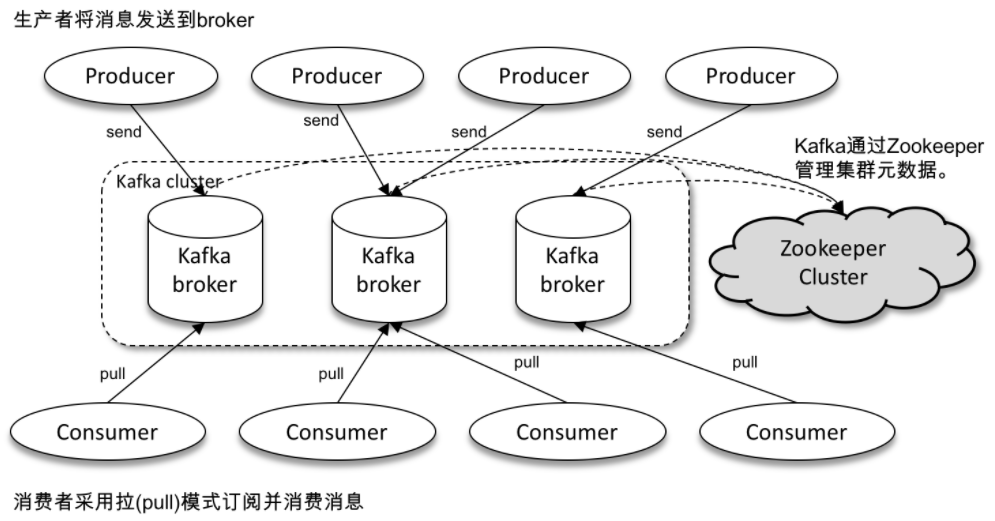
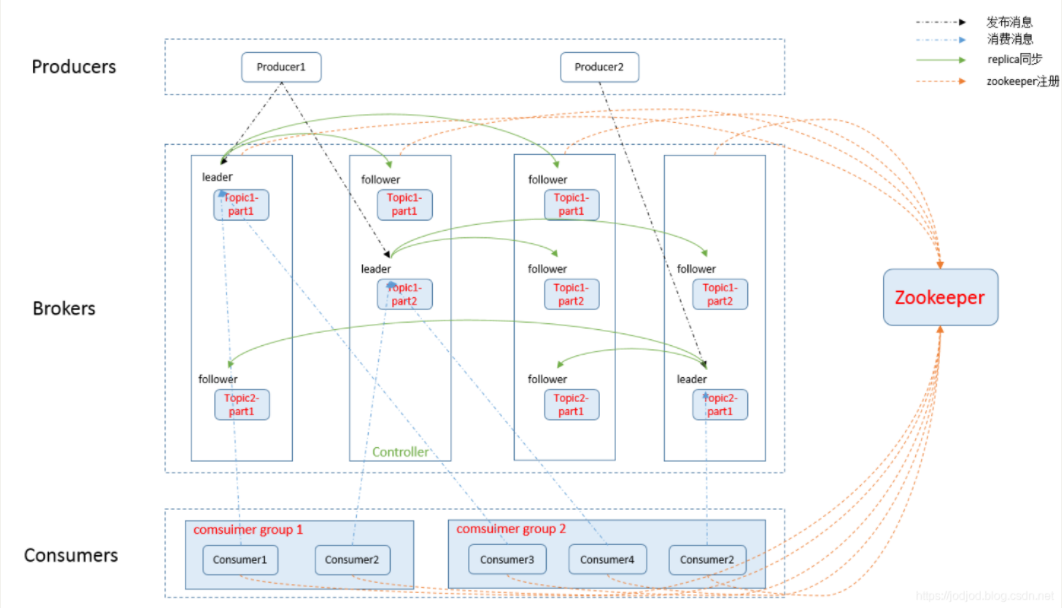
1.2.3 Kafka名词解释
-
**Producer(生产者):**发送消息的一方,生产者负责创建消息,并将其投递到Kafka的Broker
-
**Consumer(消费者):**接收消息的一方,消费者连接到Kafka上并接收消息,进而进行相应的业务逻辑处理
-
**Consumer Group(消费者组):**消费者是消费者组的一部分,一个或多个Consumer共同读取一个主题,消费者组保证每个分区只能被一个Consumer使用,用来提高Consumer的可靠性,一个Consumer失效可由多个消费者组中的消费者顶替。消费者组还是Kafka用来实现一个Topic的广播(发给所有消费者)和单播(发给任意一个消费者)的手段,一个Topic可有多个消费者组,Topic的消息会被抓取到所有消费者组,但每个Partition只会把消息发送给消费者组终的一个消费者;如果需实现广播,只要每个消费者有一个独立的消费者组就可以;实现单播只要所有的消费者在同一个消费者组
-
**Broker(服务代理节点):**Broker可简单看作一个独立的Kafka服务节点或Kafka实例。大多数情况下也可将Broker看作一台Kafka服务器,一个或多个Broker组成一个Kafka集群
-
**Topic(主题):**Topic是一个存储消息的逻辑概念,Topic类似于文件系统中的文件件,事件就是该文件夹中的文件。可认为是一个消息集合,每条发送到Kafka的消息都有一个类别,从物理上来讲,不同的Topic的消息是分开存储的,每个Topic可以有多个生产者向它发送消息,也可以有多个消费者取消费其中的消息
-
**Partition(分区):**Partition是物理概念,每个Topic可划分为多个Partition,同一Topic下不同分区包含的消息是不同的,每个消息在被添加到分区时,都会被分配一个offset,它是消息在此分区中的唯一编号,Kafka通过offset保证消费消息在分区内的顺序,offset的顺序不跨分区,即Kakfa只保证在同一个分区内的消息是有序的。Kafka支持动态增加一个已存在Topic的Partition个数,但不支持动态减少Partition个数
-
**Replication(副本集):**为使数据具有容错性和高可用性,每个Topic都可以有多个Replication,以便始终可有多个Kafka节点具有数据副本,已防出现故障。每个Partition有且只有一个Leader Replica,其负责处理所有的Producer和Consumer的请求,同时,Leader Replica还负责监管和维护ISR中所有follower的滞后状态。每个Partition中除Leader以外的所有Replica均为follower,其不处理任何来自客户端请求,至通过fetch request拉取leader replica的数据进行同步
-
**AR(Assigned Replicas):**分区中的所有副本统称为AR
-
**ISR(In-Sync-Replicas):**所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR,ISR集合是AR集合中的一个子集。leader副本负责维护和跟踪ISR集合中所有follower副本的滞后状态,当follower副本落后太多或失效时,leader副本会将其从ISR集合中剔除。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格 被选举为新的leader,而OSR集合中的副本则没有任何机会
-
**OSR(Out-of-Sync Replicas):**与leader副本同步滞后过多的副本(不包括leader副本)组成OSR。AR=ISR+OSR,任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。如果OSR集合中有follower副本追上了leader副本,则leader副本会将其从OSR集合转移至ISR集合
-
**HW(高水位):**取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置,每个replica都有HW,leader和follower各自负责更新自己的HW的状态,对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样保证了如果leader所在broker失效,该消息仍可以从新选举的leader种获取。对于来自内部broker的读取请求,没有HW的限制
-
**LEO(Log End Offset)😗*LEO是Log End Offset的缩写,标识当前日志文件中下一条待写入消息的offset,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身LEO,ISR集合中最小的LEO即为分区的HW,consumer只能消费HW之前的消息
1.2.4 Kafka可靠性及持久性保证
producer向leader发送消息时,可通过设置request.required.acks参数控制数据可靠性级别:
-
request.required.acks = 1 此为默认设置,意即producer发送数据到leader,leader写本地日志成功,返回客户端成功;此时ISR中其它副本还未及时拉取该消息,此时一旦leader宕机会造成此次发送的消息丢失
-
request.required.acks = 0 此情况下,producer不停向leader发送数据,无需leader反馈成功消息,该种情况下数据传输效率最高,但数据可靠性也最低,有可能在发送过程或leader宕机时丢失数据。
-
request.required.acks = -1 此情况下,producer发送数据给leader,leader收到数据后需等到ISR列表中所有follower都同步数据完成后,才会向producer返回成功消息,如一直未收到成功消息,就认为发送数据失败就会自动重发数据,此为可靠性最高方案,但性能也会受到影响。
# 如要提高数据可靠性,设置request.required.acks=-1时,还需min.insync.replicas参数配合,该参数用于设置ISR中最小副本数,默认值为1,只有当request.required.acks=-1时,此参数才生效。当ISR中副本数小于min.insync.replicas所配数量时,客户端会返回异常。如min.insync.replicas设置为2,当ISR中实际副本数为1时,会无法保证可靠性,此时会拒绝客户端写请求已防消息丢失。
1.3 Zookeeper简介
1.3.1 Zookeeper概念
官方对Zookeeper的解释是:Zookeeper分布式服务框架是Apache Hadoop的一个子项目,主要用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
分布式组件里,Zookeeper属于鼻祖地方,很多分布式系统都借鉴或采纳了Zookeeper的分布式思想。
Zookeeper是一基于观察者设计模式的分布式服务管理框架,其负责和管理需关心的数据,然后接受观察者的注册,一旦这些数据状态发生变化,Zookeeper就将负责通知已在Zookeeper上注册的那些观察者做出相应反应。
简单描述就是:Zookeeper=文件系统+通知机制
Zookeeper遵循**最终一致性**原则。
遵循:快速领导者选举机制、过半机制、数据同步机制
遵循:2PC(两阶段提交):预提交、收到ACK(过半机制)、提交
1.3.2 Zookeeper特点
**最终一致性:**为客户端展示同一视图,是Zookeeper最重要功能
**可靠性:**如果消息被一台服务器接受,那么它将被所有的服务器接受
**实时性:**Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据前调用sync()接口
**等待无关(wait-free):**慢的或者失效的client不干预快的client的请求
**原子性:**更新只能成功或者失败,没有中间状态
**顺序性:**所有server同一消息发布顺序一致
1.3.3 Zookeeper架构
- 一个leader和多个follower组成集群,启动时根据Paxos协议选举出一个leader
- 集群中只要有半数以上的节点存活,集群就能正常提供服务
- 全局一致性,每个Server保存一份相同数据副本,Client无论连接哪个Server,数据都一致
- leader根据Zab协议负责处理数据的更新等操作
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行
- 原子性:一次更新操作(可以是多个),当且仅当大多数Server在内存中成功修改数据,要么成功,要么失败
- 实时性:在一定时间范围内,Client能读到最新数据
--Paxos核心思想:当多数Server写成功,则任务数据写成功
--如果有3个Server,则需要2个写成功即可
--如果有5个Server,则需要3个写成功即可
-- Zookeeper Server数目一般为奇数-->
--如果有3个Server,则最多允许1个Server挂掉
--如果有4个Server,则最多允许1个Server挂掉
--所以3台和4台效果一样-->
-- Zab协议的全称是Zookeeper Atomic Broadcast (Zookeeper原子广播)
-- Zookeeper是通过 Zab 协议来保证分布式事务的最终一致性
投票集群里的节点数要求是奇数
一个集群能容忍的节点数为 N = 2F + 1,N为投票集群节点数,F为能同时容忍失败节点数,如一个三节点集群,可挂掉一个,5节点集群可挂掉两个
一个写操作需半数以上的节点ack,节点数越多,整个集群可容忍故障节点数越多,但吞吐量越差
1.3.4 Zookeeper角色
- 领导者(leader):leader服务器为客户端提供读服务和写服务
- 学习者(learner):
- 跟随者(follower):follower服务器为客户端提供读服务,参与leader选举,参与写操作"过半写成功"策略
- 观察者(observer):observer服务器为客户端提供读服务,不参与leader选举,不参与写操作"过半写成功"策略,用于在不影响写性能的前提下提升集群读性能,除了不参与leader选举和proposal投票外,与follower作用相同
- 客户端(client):服务请求发起方
1.3.5 Zookeeper角色作用
1.3.5.1 leader作用
- 发起与提交写请求。所有的follower与observer节点的写请求都会转交给leader执行,leader接受到一个写请求后,首先会发送给所有的follower,并统计follower写入成功的数量。当有超过半数的follower写入成功后,leader就认为此写请求提交成功,并通知所有的follower commit此操作
- 与learner保持心跳
- 当ZAB崩溃恢复时负责恢复数据以及同步数据到learner
1.3.5.2 follower作用
follower在集群中有多个,主要作用如下:
-
与leader保持心跳连接
-
当leader发生故障时,进行投票选举产生新的leader,leader的重新选举是由follower内部投票决定的
-
向leader发送消息与请求
-
处理leader发来的消息与请求
1.3.5.3 observer作用
observer更像是Zookeeper集群中最边缘的,其作用主要是提高Zookeeper集群的读性能,其作用如下
-
与leader同步数据
-
不参与leader选举,无投票权,也不参与写操作的提议过程
-
数据不会事务化到硬盘,即observer只会将数据加载到内存
1.3.6 Zookeeper角色状态
-
LOOKING: 当前Server未知集群中的leader,并且正在寻找
-
LEADING: 当前Server即为选举出来的leader
-
FOLLOWING: 当前follower已与选举出的leader同步
-
OBSERVING: 当前observer已与选举出来的leader同步
1.3.7 Zookeeper中的请求
- **事务请求:**在Zookeeper中,会改变服务器状态的请求称为事务请求(如:创建节点、删除节点、更新数据、创建会话等)
- **非事务请求:**从Zookeeper中仅仅读取数据,不会对服务器数据状态进行任何修改的请求称为非事务请求
1.3.8 Zookeeper数据结构
-
Zookeeper数据模型结构与Unix文件系统很类似,整体类似一棵树,每个节点为一个znode,每个znode默认能存储1MB数据,每个znode都可以通过其路径唯一标识
-
Zookeeper和Unix不同的是,znode不仅可以存数据,还可以有子节点(不同于文件和文件件概念)
1.3.8.1 Zookeeper中znode结构含义
Zookeeper中的znode包含了四个部分
-
data 保存数据
-
**acl:**权限,定义了什么样的用户可以操作这个节点,且能够进行怎样的操作
- c: create创建权限,允许在该节点下创建子节点
- w: write更新权限,允许更新该节点的数据
- r: read读取权限,允许读取该节点的内容以及子节点的列表信息
- d: delete删除权限,允许删除该节点的子节点
- a: admin管理者权限,允许对该节点进行acl权限设置
-
stat: 描述当前znode的元数据
-
child: 当前节点的子节点
1.3.8.2 Zookeeper中znode类型
-
持久节点: 创建出的节点,在会话结束后依然存在,保存数据
持久节点实现逻辑如下注释所描述:
-
持久序号节点: 创建出的节点,根据先后顺序,会在节点之后带上一个数值,越后执行数值越大,使用分布式锁的应用场景----单调递增,并发严重情况下
-
临时节点: 在当前会话一直持续的时候,该节点是一直存在的。临时节点是在会话结束后,自动被删除的,通过这个特性,ZK可以实现服务注册与发现的效果
临时节点实现逻辑如下注释所描述:
-
临时序号节点: 跟持久序号节点相同,适用于临时的分布式锁
-
Container节点(3.5.3版本新增): Container容器节点,当容器中没有任何子节点,该节点会被ZK定期删除(60s),用来解决分布式锁场景下产生大量孤儿节点的问题
-
TTL节点:(3.5.3版本新增),挡在TTL时间内节点没有被修改且没有自节点将被删除, 可以指定节点的到期时间,到期后被ZK定时删除,只能通过系统配置zookeeper,extendedTypesEnabled=True开启,(搭配PERSISTENT、PERSISTENT_SEQUENTIAL使用)
1.3.9 Zookeeper应用场景
-
分布式协调组件: 在某种环境下,某些内容不均衡、出现了矛盾,此时就需要一个协调者,协调分布式系统中的状态。
-
分布式锁: Zookeeper在实现分布式锁上,可以做到一定条件下的强一致性,ZK使用ZAB协议进行主从数据同步,ZAB协议认为只要半数节点写入即为成功,ZK为了保证强一致性,使两个客户端读到的数据一致,使用了sync()方法
-
**无状态化的实现:**几个服务公共部分的数据信息存储到zookeeper上面,这几个服务需要数据的时候直接到zookeeper里获取
如:用户进行登录后,登录就可以直接放在zookeeper上,这样就不需要分别在几个负载均衡的设备上面进行登录信息的存储,需要的时候直接去zookeeper上获取就行
1.3.10 Zookeeper两种持久化机制
- 事务持久化:
- 快照持久化:
1.3.11 Zookeeper客户端zkCli.sh使用
运行zkCli.sh脚本进入命令行工具
zkCli.sh -server localhost:2181
[zk: 192.168.17.112:2181(CONNECTED) 2] help #使用help命令查看帮助
ZooKeeper -server host:port -client-configuration properties-file cmd args
addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE
addauth scheme auth
close
config [-c] [-w] [-s]
connect host:port
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
delete [-v version] path
deleteall path [-b batch size]
delquota [-n|-b|-N|-B] path
get [-s] [-w] path
getAcl [-s] path
getAllChildrenNumber path
getEphemerals path
history
listquota path
ls [-s] [-w] [-R] path
printwatches on|off
quit
reconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*]
redo cmdno
removewatches path [-c|-d|-a] [-l]
set [-s] [-v version] path data
setAcl [-s] [-v version] [-R] path acl
setquota -n|-b|-N|-B val path
stat [-w] path
sync path
version
whoami
[zk: localhost:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
# 测试创建一kafka_study节点
[zk: localhost:2181(CONNECTED) 1] create /kafka_study
Created /kafka_study
[zk: localhost:2181(CONNECTED) 2] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, kafka_study, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: 192.168.17.112:2181(CONNECTED) 1] get -s -w /zookeeper # 使用get 命令获取信息
# 创建节点时的事务ID
cZxid = 0x0
# 创建节点时的时间
ctime = Thu Jan 01 08:00:00 CST 1970
# 最后修改节点时的事务ID
mZxid = 0x0
# 修改节点时的时间
mtime = Thu Jan 01 08:00:00 CST 1970
# 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但修改子节点的数据内容则不影响该ID
pZxid = 0x0
# 子节点版本号,子节点每次修改版本号加1
cversion = -2
# 数据版本号,数据每次修改该版本号加1
dataVersion = 0
# 权限版本号,权限每次修改该版本号加1
aclVersion = 0
# 创建该临时节点的会话的sessionID(如该节点是持久节点,则该属性值为0)
ephemeralOwner = 0x0
# 该节点的数据长度
dataLength = 0
# 直接子节点的数量
numChildren = 2
zk: 192.168.17.112:2181(CONNECTED) 4] create /zk_test a
Created /zk_test
[zk: 192.168.17.112:2181(CONNECTED) 5] ls /zk_test
[]
[zk: 192.168.17.112:2181(CONNECTED) 6] get /zk_test
a
# 此时在其它节点连上zookeeper,使用 ls -w / 也能看到刚刚创建的kafka_study节点
2 集群部署
2.1 Kakfa 3.1 (kraft模式)集群部署
Kraft简介
Karft是基于OSGI(Open Service Gateway Initiative)之上建立的应用容器,能方便部署各种选定的组件,简化打包和安装应用的操作难度。
Karft是一个Apache基金会项目,具有Apache v2许可证。未来Kraft将作为Apache Kafka的内置共识机制将取代Zookeeper。该模式在Kafka 2.8版本发布了体验版本,Kafka 3.X系列中Kraft是一个稳定版本。Kraft运行模式的Kafka集群,不会将元数据存在zk中,部署Kakfa集群时无需再部署zk集群,Kafka将元数据存储在Controller节点的Kraft Quorum中。Kraft模式提供很多优势,如可支持更多分区,更快速切换Controller,另外还避免Controller缓存的元数据和zk存储的数据不一致带来的一系列问题。
Zookeeper是一个重量级的协调系统,非常笨重,zk还要求奇数个节点的集群配置,扩容和收缩都非常不方便,另外zk的配置方式也和Kafka完全不一样。当zk和Kafka放在一个存储系统里,当topic和partition的数量上了规模,数据同步问题就会非常显著。
环境规划
本次选择三台服务器部署Kakfa集群。
2.1.1 关闭防火墙
[root@hadoop01 ~]# systemctl stop firewalld.service
[root@hadoop01 ~]# systemctl disable firewalld.service
[root@hadoop01 ~]# systemctl stop firewalld.service
[root@hadoop01 ~]# systemctl disable firewalld.service
[root@hadoop01 ~]# systemctl stop firewalld.service
[root@hadoop01 ~]# systemctl disable firewalld.service
2.1.2 下载Kafka 3.1
[root@hadoop01 ~]# wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz --no-check-certificate
[root@hadoop01 ~]# tar -zxvf kafka_2.13-3.1.0.tgz
[root@hadoop01 ~]# mv kafka_2.13-3.1.0/ /usr/local/kafka
2.1.3 配置server.properties
-
如 process.roles = broker,服务器在kraft模式中充当 broker
-
如 process.roles = controller, 服务器在kraft模式下充当 controller
-
如 process.roles = broker,controller,服务器在kraft模式中同时充当 broker controller
-
如 process.roles 没有设置,则集群就假定是运行在ZooKeeper模式下
同时充当broker和controller的节点称为"组合"节点
# 分别修改三个节点的server.properties
################################################################################
# 节点一
################################################################################
[root@hadoop01 ~]# cd /usr/local/kafka/config/kraft
[root@hadoop01 kraft]# vim server.properties
# 主要编辑内容如下
# 节点角色
process.roles=broker,controller
# 节点ID,和节点所承担的角色相关联
node.id=1
# controller quorum连接的集群地址字符串,和配置zk连接差不多,只是格式不同,每个服务器相同
controller.quorum.voters=1@10.110.3.152:9093,2@10.110.3.153:9093,3@10.110.3.154:9093
# 本机IP+端口号,每个服务器不同
listeners=PLAINTEXT://10.110.3.152:9092,CONTROLLER://10.110.3.152:9093
# 本机IP+端口号,每个服务器不同
advertised.listeners=PLAINTEXT://10.110.3.152:9092
# 数据日志目录
log.dirs=/usr/local/kafka/config/kraft/kraft-combined-logs
################################################################################
# 节点二
################################################################################
[root@hadoop01 ~]# cd /usr/local/kafka/config/kraft
[root@hadoop01 kraft]# vim server.properties
# 主要编辑内容如下
# 节点角色
process.roles=broker,controller
# 节点ID,和节点所承担的 角色相关联
node.id=2
# controller quorum连接的集群地址字符串,和配置zk连接差不多,只是格式不同,每个服务器相同
controller.quorum.voters=1@10.110.3.152:9093,2@10.110.3.153:9093,3@10.110.3.154:9093
# 本机IP+端口号,每个服务器不同
listeners=PLAINTEXT://10.110.3.153:9092,CONTROLLER://10.110.3.153:9093
# 本机IP+端口号,每个服务器不同
advertised.listeners=PLAINTEXT://10.110.3.152:9092
# 数据日志目录
log.dirs=/usr/local/kafka/config/kraft/kraft-combined-logs
################################################################################
# 节点三
################################################################################
[root@hadoop01 ~]# cd /usr/local/kafka/config/kraft
[root@hadoop01 kraft]# vim server.properties
# 主要编辑内容如下
# 节点角色
process.roles=broker,controller
# 节点ID,和节点所承担的角色相关联
node.id=3
# controller quorum连接的集群地址字符串,和配置zk连接差不多,只是格式不同,每个服务器相同
controller.quorum.voters=1@10.110.3.152:9093,2@10.110.3.153:9093,3@10.110.3.154:9093
# 本机IP+端口号,每个服务器不同
listeners=PLAINTEXT://10.110.3.154:9092,CONTROLLER://10.110.3.154:9093
# 本机IP+端口号,每个服务器不同
advertised.listeners=PLAINTEXT://10.110.3.154:9092
# 数据日志目录
log.dirs=/usr/local/kafka/config/kraft/kraft-combined-logs
2.1.4 生成集群唯一ID
# 只需在其中一个节点执行生成一个uuid
[root@hadoop01 kraft]# cd /usr/local/kafka/
[root@hadoop01 kafka]# ./bin/kafka-storage.sh random-uuid
q570BlHuQzag-8nHZJ029w
2.1.5 格式化存储数据目录
# 每个节点都需操作
[root@hadoop0x kraft]# cd /usr/local/kafka
[root@hadoop0x kafka]# ./bin/kafka-storage.sh format -t q570BlHuQzag-8nHZJ029w -c ./config/kraft/server.properties
Formatting /usr/local/kafka/config/kraft/kraft-combined-logs
#####################################################################################
##格式化/usr/local/kafka/config/kraft/kraft-combined-logs信息如下
[root@hadoop01 kafka]# cd /usr/local/kafka/config/kraft/kraft-combined-logs
[root@hadoop01 kraft-combined-logs]# ll
total 4
-rw-r--r-- 1 root root 86 Apr 26 16:51 meta.properties
[root@hadoop01 kraft-combined-logs]# more meta.properties
#
#Tue Apr 26 16:51:42 CST 2022
cluster.id=q570BlHuQzag-8nHZJ029w
version=1
node.id=1
[root@hadoop02 kafka]# cd /usr/local/kafka/config/kraft/kraft-combined-logs
[root@hadoop02 kraft-combined-logs]# ll
total 4
-rw-r--r-- 1 root root 86 Apr 26 16:54 meta.properties
[root@hadoop02 kraft-combined-logs]# more meta.properties
#
#Tue Apr 26 16:54:16 CST 2022
cluster.id=q570BlHuQzag-8nHZJ029w
version=1
node.id=2
[root@hadoop03 kafka]# cd /usr/local/kafka/config/kraft/kraft-combined-logs
[root@hadoop03 kraft-combined-logs]# ll
total 4
-rw-r--r-- 1 root root 86 Apr 26 16:55 meta.properties
[root@hadoop03 kraft-combined-logs]# more meta.properties
#
#Tue Apr 26 16:55:40 CST 2022
cluster.id=q570BlHuQzag-8nHZJ029w
version=1
node.id=3
2.1.6 启动Kafka服务
#每个节点都要执行
[root@hadoop01 ~]# cd /usr/local/kafka
[root@hadoop01 kafka]# nohup ./bin/kafka-server-start.sh ./config/kraft/server.properties 1>/dev/null 2>&1 &
2.1.7 集群测试
# 创建topic
[root@hadoop01 ~]# cd /usr/local/kafka
[root@hadoop02 kafka]# ./bin/kafka-topics.sh --create --topic kafkaraftTest --partitions 1 --replication-factor 1 --bootstrap-server 10.110.3.153:9092
# 查看topic
[root@hadoop02 kafka]#./bin/kafka-topics.sh --list --bootstrap-server 10.110.3.153:9092
# 发送消息
[root@hadoop02 kafka]#./bin/kafka-console-producer.sh --bootstrap-server 10.110.3.153:9092 --topic kafkaraftTest
# 消费者取消息
[root@hadoop02 kafka]#./bin/kafka-console-consumer.sh --bootstrap-server 10.110.3.153:9092 --topic kafkaraftTest
# 查询log文件
/usr/local/kafka/bin/kafka-dump-log.sh --files /usr/local/kafka/config/kraft/kraft-combined-logs/__consumer_offsets-3/00000000000000000000.log
# 查询log文件具体信息
/usr/local/kafka/bin/kafka-dump-log.sh --files /usr/local/kafka/config/kraft/kraft-combined-logs/__consumer_offsets-3/00000000000000000000.log --print-data-log
# 查询index具体文件信息 log.index.size.max.bytes(控制创建索引的大小)
/usr/local/kafka/bin/kafka-dump-log.sh --files /usr/local/kafka/config/kraft/kraft-combined-logs/__consumer_offsets-3/00000000000000000000.index
# 查询timeindex文件信息
/usr/local/kafka/bin/kafka-dump-log.sh --files /usr/local/kafka/config/kraft/kraft-combined-logs/__consumer_offsets-3/00000000000000000000.timeindex
# 查看元数据信息
[root@hadoop03 kraft-combined-logs]# /usr/local/kafka/bin/kafka-metadata-shell.sh --snapshot /usr/local/kafka/config/kraft/kraft-combined-logs/__cluster_metadata-0/00000000000000000000.log
Loading...
Starting...
[ Kafka Metadata Shell ]
>> ls /
brokers configs local metadataQuorum topicIds topics
>> ls topics/
__consumer_offsets kafkaraftTest
>> cat /topics/kafkaraftTest/0/data
{
"partitionId" : 0,
"topicId" : "pvrhqhZORkaL5n-AusMLOA",
"replicas" : [ 3 ],
"isr" : [ 3 ],
"removingReplicas" : [ ],
"addingReplicas" : [ ],
"leader" : 3,
"leaderEpoch" : 0,
"partitionEpoch" : 0
}
>> cat /topics/kafkaraftTest/1/data
cat: /topics/kafkaraftTest/1/data: No such file or directory.
>> exit
2.2 基于Zookeeper部署Kakfa集群
2.2.1 安装jdk 1.8
mkdir -p /opt/module
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /opt/module
# 所有节点配置JAVA_HOME环境变量
vim /etc/profile
# 添加如下内容
export JAVA_HOME=/opt/module/jdk1.8.0_321
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
# 生效配置
source /etc/profile
java -version
2.2.2 Zookeeper集群部署
2.2.2.1 创建目录&标识节点
创建目录
# 每个节点都需操作
# 节点一
mkdir -p /usr/local/zookeeper-cluster/zookeeper01/data
mkdir -p /usr/local/zookeeper-cluster/zookeeper01/log
# 节点二
mkdir -p /usr/local/zookeeper-cluster/zookeeper02/data
mkdir -p /usr/local/zookeeper-cluster/zookeeper02/log
# 节点三
mkdir -p /usr/local/zookeeper-cluster/zookeeper03/data
mkdir -p /usr/local/zookeeper-cluster/zookeeper03/log
标识节点
# 每个节点都需要操作
# 节点一
echo "1" > /usr/local/zookeeper-cluster/zookeeper01/data/myid
# 节点二
echo "2" > /usr/local/zookeeper-cluster/zookeeper02/data/myid
# 节点三
echo "3" > /usr/local/zookeeper-cluster/zookeeper03/data/myid
2.2.2.2 下载&解压
下载安装包
# 下载ZK二进制安装包,然后分发到其它两台服务器
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
解压安装包
# 节点一
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz -C /usr/local/zookeeper-cluster/zookeeper01/
cd /usr/local/zookeeper-cluster/zookeeper01
mv apache-zookeeper-3.5.6-bin/* ./
rm -rf apache-zookeeper-3.5.6-bin
# 节点二
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz -C /usr/local/zookeeper-cluster/zookeeper02/
cd /usr/local/zookeeper-cluster/zookeeper02
mv apache-zookeeper-3.5.6-bin/* ./
rm -rf apache-zookeeper-3.5.6-bin
# 节点三
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz -C /usr/local/zookeeper-cluster/zookeeper03/
cd /usr/local/zookeeper-cluster/zookeeper03
mv apache-zookeeper-3.5.6-bin/* ./
rm -rf apache-zookeeper-3.5.6-bin
2.2.2.3 配置环境变量
# 每个节点都要操作,向/etc/profile添加环境变量,修改完毕后,并执行source /etc/profile使环境变量生效
# 节点一
export ZOOKEEPER HOME=/usr/local/zookeeper-cluster/zookeeper01
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 节点二
export ZOOKEEPER HOME=/usr/local/zookeeper-cluster/zookeeper02
export PATH=$PATH:$ZOOKEEPER_HOME/bin
# 节点三
export ZOOKEEPER HOME=/usr/local/zookeeper-cluster/zookeeper03
export PATH=$PATH:$ZOOKEEPER_HOME/bin
2.2.2.4 修改配置
# 每个节点都需操作
# 节点一
cd /usr/local/zookeeper-cluster/zookeeper01/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改为如下内容
tickTime=2000
initLimit=10
syncLimit=5
# datadir是数据存储目录(如未执行dataLogDir,则日志文件也保存在该目录中)
dataDir=/usr/local/zookeeper-cluster/zookeeper01/data
# dataLogDir是日志文件存储路径
dataLogDir=/usr/local/zookeeper-cluster/zookeeper01/log
# 对客户端提供的端口号
clientPort=2181
server.1=192.168.17.112:2287:3387 #IP地址后端口可以三个节点相同,比如:2888:3888
server.2=192.168.17.113:2288:3388
server.3=192.168.17.136:2289:3389
# 单个客户端与Zookeeper最大并发连接数
maxClientCnxns=60
# 保存的数据快照数量,之外的将会被清除
autopurge.snapRetainCount=3
# 自动触发清除任务时间间隔,小时为单位,默认为0,表示不自动清除
autopurge.purgeInterval=1
# 节点二
cd /usr/local/zookeeper-cluster/zookeeper02/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改为如下内容
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/zookeeper02/data
dataLogDir=/usr/local/zookeeper-cluster/zookeeper02/log
clientPort=2181
server.1=192.168.17.112:2287:3387
server.2=192.168.17.113:2288:3388
server.3=192.168.17.136:2289:3389
# 节点三
cd /usr/local/zookeeper-cluster/zookeeper03/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
# 修改为如下内容
# tickTime是Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,意即每个tickTime时间发送一个心跳
# Zookeeper的客户端和服务端也有和WEB开发里类似的session概念,Zookeeper里最小的session过期时间就是tickTime的两倍
tickTime=2000
# 集群中的follower服务器与leader服务器之间初始连接时容忍的最多心跳数(tickTime的数量)
# 此配置表示允许F连接并同步到L的初始化连接时间,它以tickTime的倍数来表示,当超过设置倍数的tickTime时间则连接失败
# 该参数设定了允许所有F与L进行连接并同步的时间,如果在设定的时间段内,半数以上的F未能完成同步,L便会宣布放弃领导地位,进行另一次的领导选举。如果ZK集群环境数量确实很大,同步数据的时间会边长,因此这种情况下可以适当调大该参数,默认为10
initLimit=10
# leader与follower同步通信时限,集群中的F与L之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
# 此配置表示,L与F之间发送消息,请求和应答时间长度,如果F在设置的时间内不能与L进行通信,则此F将被丢弃
# 该参数设定了允许一个跟随者与一个领导者进行同步的时间,如果在设定时间段内,跟随者未能完成同步,它将会被集群丢弃,所有关联到这个跟随者的客户端将连接到另外一个跟随者
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/zookeeper03/data
dataLogDir=/usr/local/zookeeper-cluster/zookeeper03/log
clientPort=2181
server.1=192.168.17.112:2287:3387
server.2=192.168.17.113:2288:3388
server.3=192.168.17.136:2289:3389
####################################################
①、tickTime:基本事件单元,这个时间是作为Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳;最小的session过期时间为2倍tickTime
②、dataDir:存储内存中数据库快照的位置,除非另有说明,否则指向数据库更新的事务日志。注意:应该谨慎的选择日志存放的位置,使用专用的日志存储设备能够大大提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会很大程度上影像系统性能。
③、client:监听客户端连接的端口。
④、initLimit:允许follower连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
⑤、syncLimit:表示Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
⑥、server.A=B:C:D
A:其中 A 是一个数字,表示这个是服务器的编号,也就是前面myid文件里的值,集群中每台服务器编号需唯一;
B:代表该服务器的 ip 地址;
C:Zookeeper服务器与集群中的leader服务器交换信息的端口;
D:Leader选举时服务器相互通信的端口。
需要修改 dataDir ,在指定的位置处创建好目录。
需要新增 server.A=B:C:D 配置,其中 A 对应下每个节点的 myid 文件号。B是集群的各个IP地址,C:D 是端口配置。
2.2.2.5 启动集群
# 启动节点一
/usr/local/zookeeper-cluster/zookeeper01/bin/zkServer.sh start
# 启动节点二
/usr/local/zookeeper-cluster/zookeeper02/bin/zkServer.sh start
# 启动节点三
/usr/local/zookeeper-cluster/zookeeper03/bin/zkServer.sh start
## 集群启动后,可以看到在每个节点的conf目录下多了一个 zoo.cfg.dynamic.next文件,文件内容如下
server.1=192.168.17.112:2287:3387:participant
server.2=192.168.17.113:2288:3388:participant
server.3=192.168.17.136:2289:3389:participant
version=300000000
2.2.2.6 集群验证
# 使用jps命令查看进程
# 使用zkServer.sh status查看集群各个节点状态
# 节点一
[root@redis-1 conf]# /usr/local/zookeeper-cluster/zookeeper01/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/zookeeper01/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower # 角色为follower
# 节点二
[root@redis-2 conf]# /usr/local/zookeeper-cluster/zookeeper02/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/zookeeper02/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader # 角色为leader
# 节点三
[root@redis-3 ~]# /usr/local/zookeeper-cluster/zookeeper03/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/zookeeper03/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower # 角色为follower
# 测试leader选举
/usr/local/zookeeper-cluster/zookeeper02/bin/zkServer.sh stop
# 然后分别观察其它两个节点角色,发现节点三此时变成了leader
# 然后再测试将节点三停服务,查看节点一状态,显示集群已停,没有leader和follower了
[root@redis-1 conf]# /usr/local/zookeeper-cluster/zookeeper01/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/zookeeper01/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Error contacting service. It is probably not running.
# 当重启节点二后,查看节点一角色已变成了leader
[root@redis-1 conf]# /usr/local/zookeeper-cluster/zookeeper01/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-cluster/zookeeper01/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
2.2.3 Kafka集群部署
2.2.3.1 创建目录
# 节点一
mkdir -p /usr/local/kafka-cluster/kafka01/kafka-logs
# 节点二
mkdir -p /usr/local/kafka-cluster/kafka02/kafka-logs
# 节点三
mkdir -p /usr/local/kafka-cluster/kafka03/kafka-logs
2.2.3.2 下载&解压
下载安装包
# 下载Kafka安装包,然后分发到其它两台服务器
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz
解压安装包
# 节点一
tar -zxvf kafka_2.12-2.4.1.tgz -C /usr/local/kafka-cluster/kafka01
cd /usr/local/kafka-cluster/kafka01
mv kafka_2.12-2.4.1/* ./
rm -rf kafka_2.12-2.4.1
# 节点二
tar -zxvf kafka_2.12-2.4.1.tgz -C /usr/local/kafka-cluster/kafka02
cd /usr/local/kafka-cluster/kafka02
mv kafka_2.12-2.4.1/* ./
rm -rf kafka_2.12-2.4.1
# 节点三
tar -zxvf kafka_2.12-2.4.1.tgz -C /usr/local/kafka-cluster/kafka03
cd /usr/local/kafka-cluster/kafka03
mv kafka_2.12-2.4.1/* ./
rm -rf kafka_2.12-2.4.1
2.2.3.3 拷贝&修改配置
拷贝配置文件
# 节点一
cd /usr/local/kafka-cluster/kafka01/config
cp -p server.properties server-1.properties
# 节点二
cd /usr/local/kafka-cluster/kafka02/config
cp -p server.properties server-2.properties
# 节点三
cd /usr/local/kafka-cluster/kafka03/config
cp -p server.properties server-3.properties
修改配置文件
# 每个节点都需操作
# 节点一修改和添加如下内容
# 每个broker都可以用唯一非负整数id标识,id 必须唯一,此id可作为broker的"名字"
broker.id=1
# Server接受客户端连接的端口,IP配置Kafka所在机器IP即可
listeners=PLAINTEXT://192.168.17.112:9092
# Kafka存放数据的路径,此路径非唯一,可以是多个,路径之间使用逗号分隔;当创建新partition时,会选择在包含最少partition的路径下进行,消息记录存储路径
log.dirs=/usr/local/kafka-cluster/kafka01/kafka-logs
# Zookeeper连接字符串格式为: hostname:port,此处hostname和port分别是Zookeeper集群中某节点host和port
zookeeper.connect=192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
# 是否允许自动创建主题,默认是true
# 一般不建议将此值设置为true,因为该参数会影响Topic的管理与维护
auto.create.topics.enable=false
# 是否允许删除主题
delete.topic.enable=true
# 每个日志文件删除前保存的时间(小时),默认为168小时,该参数默认数据保存时间对所有Topic都一样
# 数据存储的最大时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
# log.retention.bytes和log.retention.hours任意一个达到要求,都会执行删除,会被Topic创建时指定参数覆盖
log.retention.hours=168
# 创建Topic默认分区数,会被创建Topic指定参数覆盖
num.partitions=1
# 自动创建Topic的默认副本数量,建议设置为大于等于2
default.replication.factor=1
# 设置网络请求处理线程数
num.network.threads=10
# 设置磁盘IO请求线程数
num.io.threads=30
# 设置发送buffer字节数
socket.send.buffer.bytes=1024000
# 设置收到buffer字节数
socket.receive.buffer.bytes=1024000
# 设置最大请求字节数
socket.request.max.bytes=1048576000
# 设置Zookeeper连接超时时间
zookeeper.connection.timeout.ms=60000
# 节点二
broker.id=2
listeners=PLAINTEXT://192.168.17.113:9092
log.dirs=/usr/local/kafka-cluster/kafka02/kafka-logs
zookeeper.connect=192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
auto.create.topics.enable=false
delete.topic.enable=true
log.retention.hours=168
num.partitions=1
default.replication.factor=1
# 节点三
broker.id=3
listeners=PLAINTEXT://192.168.17.136:9092
log.dirs=/usr/local/kafka-cluster/kafka03/kafka-logs
zookeeper.connect=192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
auto.create.topics.enable=false
delete.topic.enable=true
log.retention.hours=168
num.partitions=1
default.replication.factor=1
2.2.3.4 启动集群
# 节点一
nohup /usr/local/kafka-cluster/kafka01/bin/kafka-server-start.sh /usr/local/kafka-cluster/kafka01/config/server-1.properties &
# 节点二
nohup /usr/local/kafka-cluster/kafka02/bin/kafka-server-start.sh /usr/local/kafka-cluster/kafka02/config/server-2.properties &
# 节点三
nohup /usr/local/kafka-cluster/kafka03/bin/kafka-server-start.sh /usr/local/kafka-cluster/kafka03/config/server-3.properties &
2.2.3.5 集群测试
# 创建消息
/usr/local/kafka-cluster/kafka01/bin/kafka-topics.sh --create --bootstrap-server 192.168.17.112:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic
# 查看主题消息
[root@redis-1 ~]# /usr/local/kafka-cluster/kafka01/bin/kafka-topics.sh --describe --bootstrap-server 192.168.17.112:9092 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
[root@redis-2 ~]# /usr/local/kafka-cluster/kafka02/bin/kafka-topics.sh --describe --bootstrap-server 192.168.17.112:9092 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
[root@redis-3 ~]# /usr/local/kafka-cluster/kafka03/bin/kafka-topics.sh --describe --bootstrap-server 192.168.17.112:9092 --topic my-replicated-topic
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
====================================
# 集群中创建主题
/usr/local/kafka-cluster/kafka0*/bin/kafka-topics.sh --create --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --replication-factor 3 --partitions 3 --topic topicDemo
# 集群中查看主题
/usr/local/kafka-cluster/kafka0*/bin/kafka-topics.sh --list --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
# 生产者
/usr/local/kafka-cluster/kafka0*/bin/kafka-console-producer.sh --broker-list 192.168.17.112:9092,192.168.17.113:9092,192.168.17.136:9092 --topic topicDemo
# 消费者 表示从 latest 位移位置开始消费该主题的所有分区消息,即仅消费正在写入的消息
/usr/local/kafka-cluster/kafka0*/bin/kafka-console-consumer.sh --bootstrap-server 192.168.17.112:9092,192.168.17.113:9092,192.168.17.136:9092 --topic topicDemo
#从开始位置消费 表示从指定主题中有效的起始位移位置开始消费所有分区的消息
/usr/local/kafka-cluster/kafka0*/bin/kafka-console-consumer.sh --bootstrap-server 192.168.17.112:9092,192.168.17.113:9092,192.168.17.136:9092 --from-beginning --topic topicDemo
# 显示key消费 消费出的消息结果将打印出消息体的 key 和 value
/usr/local/kafka-cluster/kafka0*/bin/kafka-console-consumer.sh --bootstrap-server 192.168.17.112:9092,192.168.17.113:9092,192.168.17.136:9092 --property print.key=true --topic topicDemo
2.2.4 安装并配置Kafka监控工具Kafka Eagle
此处选择安装并配置Kafka Eagle工具用来监控Kafka集群
2.2.4.1 下载Kafka Eagle
本次选择在Centos服务器上使用git命令下载Kafka Eagle源码
[root@redis-1]# cd /usr/local/kafka-cluster/
[root@redis-1 kafka-cluster]# git clone https://github.com/smartloli/kafka-eagle
Cloning into 'kafka-eagle'...
remote: Enumerating objects: 20427, done.
remote: Counting objects: 100% (2518/2518), done.
remote: Compressing objects: 100% (906/906), done.
remote: Total 20427 (delta 873), reused 2373 (delta 818), pack-reused 17909
Receiving objects: 100% (20427/20427), 80.38 MiB | 16.48 MiB/s, done.
Resolving deltas: 100% (7698/7698), done.
===================================Centos 编译安装git===================================
1、安装依赖包
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
2、下载git源码包并解压
cd /usr/local/src
wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.36.0.tar.gz
3、编译并安装
tar -zxvf git-2.36.0.tar.gz
cd git-2.36.0
./configure --prefix=/usr/local/ --with-iconv=/usr/local/libiconv/
make && make install
# 如安装过程报为找到libiconv错误,需先安装libiconv
wget http://ftp.gnu.org/pub/gnu/libiconv/libiconv-xxx.tar.gz
tar -zxvf libiconv-xxx.tar.gz
./configure --prefix=/usr/local/libiconv
make && make install
# libiconv安装成功后重新选择编译安装git
4、查看git版本
ln -s /usr/local/bin/git /usr/bin/git
git --version
2.2.4.2 编译kafka-eagle
Kafka Eagle是采用Java语言开发的,通过Maven构建。
[root@redis-1 kafka-cluster]# cd kafka-eagle/
# 执行编译脚本build.sh
[root@redis-1 kafka-eagle]# ./build.sh
# 如报./build.sh: line 2: mvn: command not found需先安装配置maven
===================================Centos 安装maven===================================
cd /usr/local/src/
wget https://mirrors.cnnic.cn/apache/maven/maven-3/3.8.5/binaries/apache-maven-3.8.5-bin.tar.gz
tar -zxvf apache-maven-3.8.5-bin.tar.gz
# 配置环境变量
vim /etc/profile # 编辑/etc/profile文件,添加如下内容
export MAVEN_HOME=/usr/local/src/apache-maven-3.8.5
export PATH=$MAVEN_HOME/bin:$PATH
# 使配置生效
source /etc/profile
# 查看maven版本
[root@redis-1 apache-maven-3.8.5]# mvn -version
Apache Maven 3.8.5 (3599d3414f046de2324203b78ddcf9b5e4388aa0)
Maven home: /usr/local/src/apache-maven-3.8.5
Java version: 1.8.0_321, vendor: Oracle Corporation, runtime: /opt/module/jdk1.8.0_321/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-957.27.2.el7.x86_64", arch: "amd64", family: "unix"
3 管理主题
Kafka系统中,kafka-topics.sh脚本可用来管理Topic,例如创建主题、查看主题、修改主题、删除主题等。
3.1 创建主题
Kafka系统中有两种方式可用来创建主题,分别是自动创建和手工创建。
-
自动创建
可通过在Kafka配置文件server.properties中设置auto.create.topics.enable=true属性来自动创建主题(默认该属性值为true)。此时,producer向Kafka集群中一个不存在的主题写数据时,会自动创建一个默认分区和默认副本系数的主题。
-
手工创建
可通过kafka-topics.sh脚本手工创建主题
# 手工创建一含有3副本和6分区的主题
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --create --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --replication-factor 3 --partitions 6 --topic ip_login
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic ip_login.
# 查看系统消息存储目录查看刚创建的主题相关信息
[root@redis-1 config]# cd /usr/local/kafka-cluster/kafka01/kafka-logs/
[root@redis-1 kafka-logs]# ls -ld ip_login*
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-0
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-1
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-2
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-3
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-4
drwxr-xr-x 2 root root 4096 May 11 13:39 ip_login-5
# 访问Zookeeper系统
zkCli.sh -server 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
# 执行ls命令查看主题分区数
[zk: 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181(CONNECTED) 0] ls /brokers/topics/ip_login/partitions
[0, 1, 2, 3, 4, 5]
# 使用get命令查看分区元数据信息
[zk: 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181(CONNECTED) 2] get /brokers/topics/ip_login
{"version":2,"partitions":{"2":[2,3,1],"5":[2,1,3],"1":[1,2,3],"4":[1,3,2],"0":[3,1,2],"3":[3,2,1]},"adding_replicas":{},"removing_replicas":{}}
3.2 查看主题
kafka-topics.sh脚本提供了describe和list命令来查看主题信息
- describe命令: 用来查看指定主题或全部主题详细信息
- list命令: 用来展示所有主题名相关信息
- 查看单个主题信息
#查看单个主题信息
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --topic ip_login
Topic: ip_login PartitionCount: 6 ReplicationFactor: 3 Configs:
Topic: ip_login Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: ip_login Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: ip_login Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: ip_login Partition: 3 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: ip_login Partition: 4 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
Topic: ip_login Partition: 5 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
- 查看全部主题信息
# 查看全部主题信息
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
Topic: __consumer_offsets PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600
Topic: __consumer_offsets Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: __consumer_offsets Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: __consumer_offsets Partition: 2 Leader: 3 Replicas: 3 Isr: 3
......
Topic: __consumer_offsets Partition: 49 Leader: 2 Replicas: 2 Isr: 2
Topic: ip_login PartitionCount: 6 ReplicationFactor: 3 Configs:
Topic: ip_login Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: ip_login Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
......
Topic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs:
Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: topicDemo PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: topicDemo Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
Topic: topicDemo Partition: 1 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: topicDemo Partition: 2 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
- 查看所有主题名信息
# 查看所有主题名
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --list --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181
__consumer_offsets
ip_login
my-replicated-topic
topicDemo
-
查看正在同步的主题信息
通过describe结合under-replicated-partitions命令查看处于"under replicated"状态的分区,此状态下的主题可能正在做同步操作,亦有可能发生了异常,则此刻所查看到的主题分区的同步副本列表(ISR)要小于分区副本(AR)。
# 查看正在同步的主题,不指定Topic名称,查看全部主题
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --under-replicated-partitions
# 查看正在同步的主题,指定Topic名称,查看特定主题
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 -topic ip_login --under-replicated-partitions
# 执行查看正在同步的主题命令时,如果linux控制台没有打印任何信息,则说明Kafka集群中的主题没有出现同步操作,如出现 "under replicated" 此时应重点关注,这表示Kafka集群的某个代理节点可能已出现异常或同步速度减慢
-
查看主题中不可用分区
通过describe结合unavailable-partitions命令查看主题中不可用分区信息
# 查看主题中不可用分区
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --unavailable-partitions
# 指定Topic名称,查看特定主题中哪些分区不可用
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 -topic ip_login --unavailable-partitions
# 执行上述命令如未打印任何信息,则表明Kafka集群中不存在分区种不可用的情况。
-
查看主题重写配置
通过describe结合topics-with-overrides命令查看主题被重写了哪些配置。
# 查看主题重写的配置
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 --topics-with-overrides
Topic: __consumer_offsets PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600
# 指定Topic名称,查看特定主题中有哪些配置被重写
[root@redis-1 kafka01]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.17.112:2181,192.168.17.113:2181,192.168.17.136:2181 -topic ip_login --topics-with-overrides
