




Kafka介绍
kafka是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。
Kafka的架构原理
2.1 基础架构与名词解释
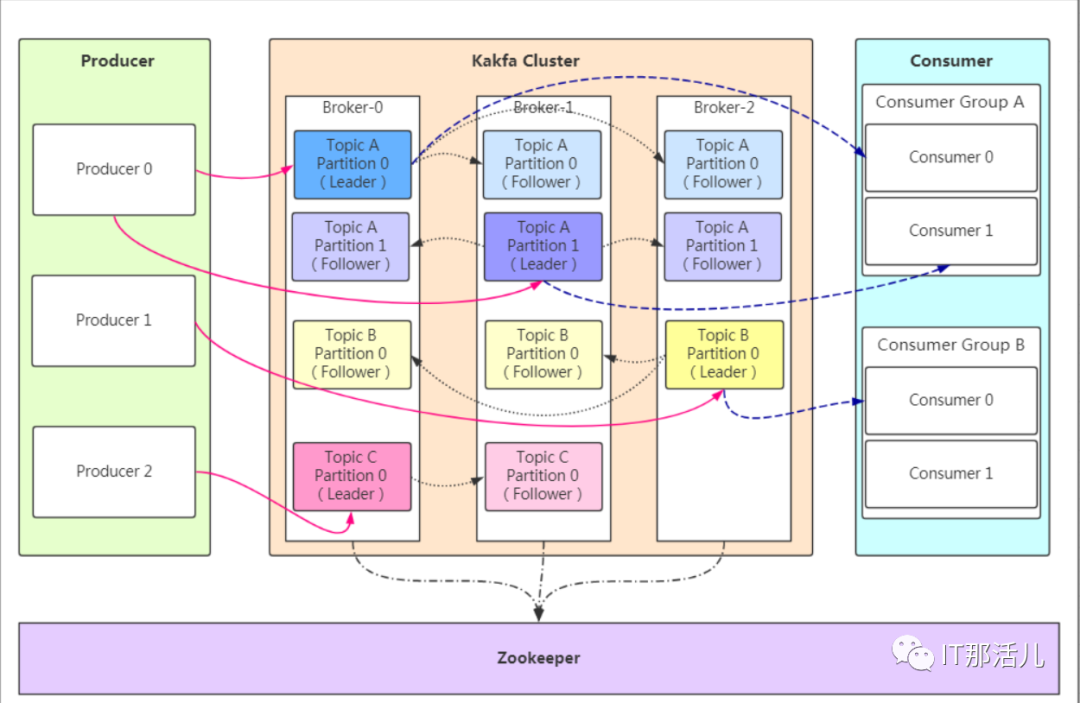
Producer:Producer即生产者,消息的产生者,是消息的入口。 Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等…… Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。 Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹! Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。 Message:每一条发送的消息主体。 Consumer:消费者,即消息的消费方,是消息的出口。 Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量! Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
2.2 工作流程分析
2.2.1 发送数据
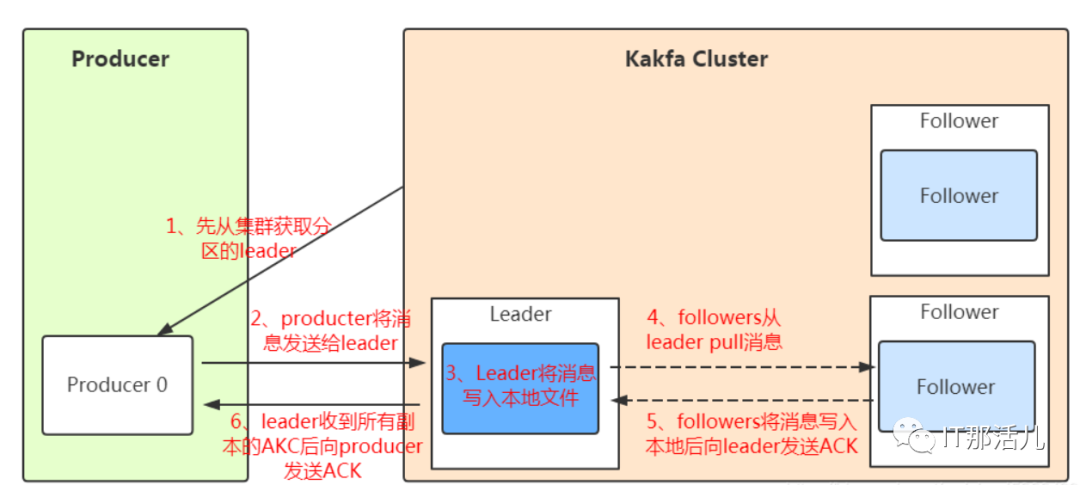
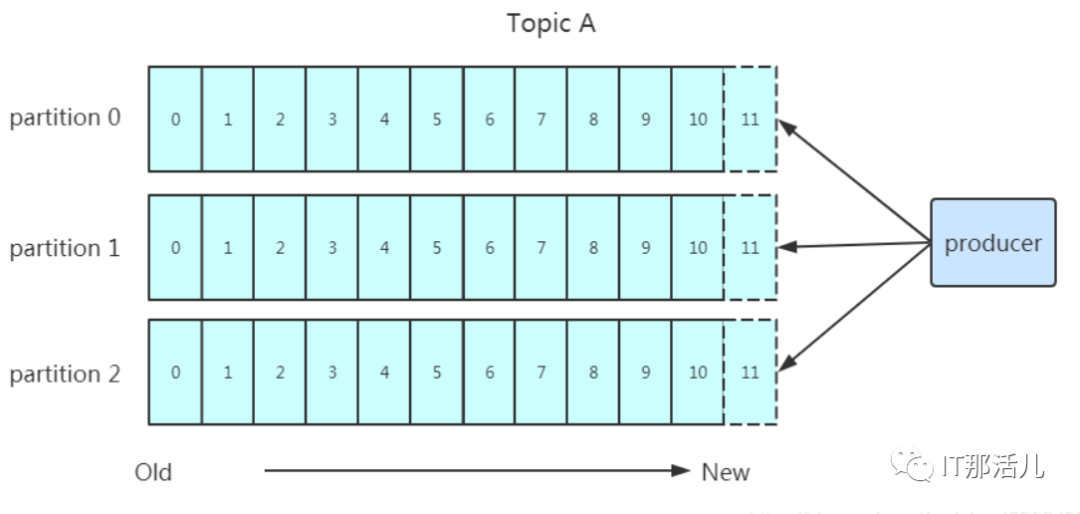
kafka为什么要做分区呢?分区的主要目的是:
方便扩展:因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。 提高并发:以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
通过上图中的通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。 all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
2.2.2 保存数据

log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!
我们重点需要知道的是下面三个:
offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置! 消息大小:消息大小占用4byte,用于描述消息的大小。 消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
基于时间,默认配置是168小时(7天)。 基于大小,默认配置是1073741824。
2.2.3 消费数据
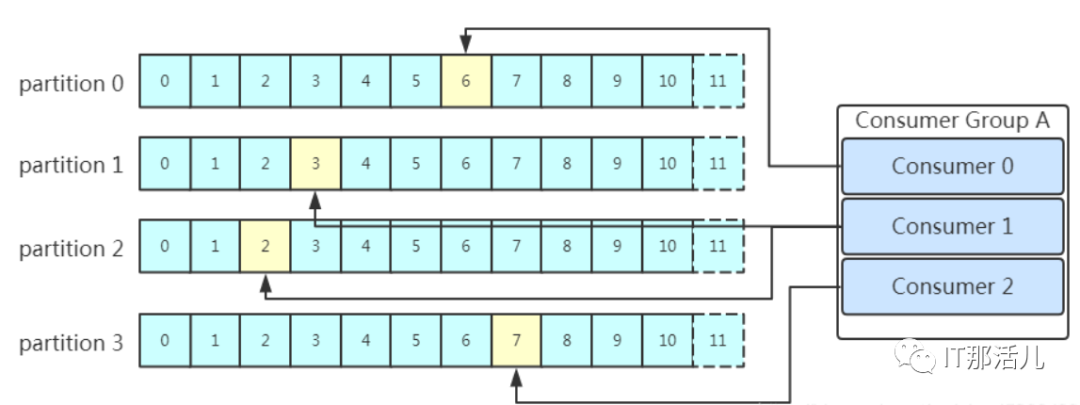
一般消息系统,consumer存在两种消费模型:
push:优势在于消息实时性高。劣势在于没有考虑consumer消费能力和饱和情况,容易导致producer压垮consumer。 pull:优势在可以控制消费速度和消费数量,保证consumer不会出现饱和。劣势在于当没有数据,会出现空轮询,消耗cpu。
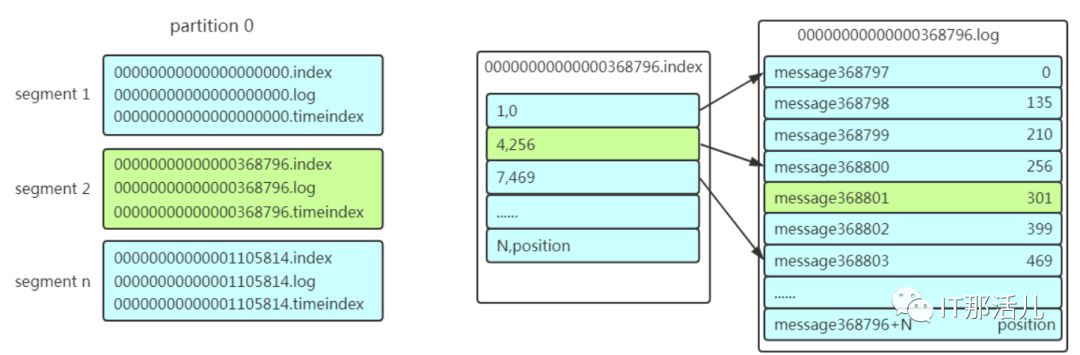
1)先找到offset的368801message所在的segment文件(利用二分法查找),这里找到的就是在第二个segment文件。 2)打开找到的segment中的.index文件(也就是368796.index文件,该文件起始偏移量为368796+1,我们要查找的offset为368801的message在该index内的偏移量为368796+5=368801,所以这里要查找的相对offset为5)。由于该文件采用的是稀疏索引的方式存储着相对offset及对应message物理偏移量的关系,所以直接找相对offset为5的索引找不到,这里同样利用二分法查找相对offset小于或者等于指定的相对offset的索引条目中最大的那个相对offset,所以找到的是相对offset为4的这个索引。 3)根据找到的相对offset为4的索引确定message存储的物理偏移位置为256。打开数据文件,从位置为256的那个地方开始顺序扫描直到找到offset为368801的那条Message。

本文作者:徐 苗(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
